









連載
西川善司の3DGE:GeForce RTX 40完全解説。シェーダの大増量にレイトレーシングの大幅機能強化など見どころのすべてを明らかに
 |
GeForce RTX 40の開発コードネームは「Ada Lovelace」(エイダ・ラブレス,以下 Ada)。NVIDIAは,「GeForce 8800 GTX」以降のGPUに付ける開発コードネームに,物理学者やコンピュータサイエンス研究者の名前を冠している。Adaは,19世紀の数学者であり世界初のコンピュータプログラマ(もちろん機械式計算器だ)として知られるAda Lovelace氏にちなんだものだ。
本稿では,Ada世代のGeForce RTX 40が搭載する新技術や新機能がどのようなものなのか,新機能はどう活用するのかなどについての解説をしよう。
GeForce RTX 40シリーズのGPUダイは3種類存在する
今のところ発表済みのGeForce RTX 40シリーズは,10月12日に発売予定の「GeForce RTX 4090」(関連記事)と,11月に発売予定である「GeForce RTX 4080」のグラフィックスメモリ16GB版と12GB版の3種類がある。
GeForce RTX 4090は別物として,2種類のGeForce RTX 4080は,単にグラフィックスメモリの容量違いかと思うかもしれないが,実はGPUダイ自体が異なっている。上位モデルである16GB版のGPUダイは「AD103」と呼ばれており,12GB版のGPUダイは「AD104」だ。詳細は後述するが,16GB版と12GB版では,スペックや性能も異なる。なお,最上位モデルに相当するGeForce RTX 4090は「AD102」と呼ばれており,上位GPUのほうが型番の数字が小さくなる命名法則はいつもどおりだ。
NVIDIAとしては,末っ子のAD104を「GeForce RTX 4070」としてリリースしたかったのではないかと,筆者は推測している。GeForce RTX 40シリーズが登場したあとも,AmpereアーキテクチャのGeForce RTX 3080やそれ以下のラインナップなどは,しばらく併売していく必要があるからだ。しかし,AD104に4070のナンバーを付けてしまうと,性能や価格面でGeForce RTX 3080の存在が霞んでしまうかもしれない。そのため,「70」の型番を避けたのだろう。
 |
製造プロセスは,すべてTSMCの4Nプロセスで,NVIDIA向けにカスタマイズしたものを採用しているという。先代Ampere系はSamsung Electronics(以下,Samsung)の8nmプロセスだったが,Ada系でTSMCに戻ってきたわけだ。ここ十数年のNVIDIAは,歩留まりの安定化を重んじる方針から,GeForce GPUのハイエンドモデルを製造するのに,最新プロセスの採用をあえて避けていた。しかしAda系で,この慣例を破って最新世代のプロセスを採用してきたことは興味深い。それだけTSMCのプロセス品質を信頼しているのかもしれない。
掲載当初,プロセス技術を4nmと記載していましたが,正しくは4N(※4nmではない)でした。訂正してお詫びいたします
トランジスタ数とダイサイズは,AD102が約763億個で608.5mm2,AD103は約459億個で378.6mm2,AD104が約358億個で294.5mm2とのこと。
ちなみに,GeForce RTX 30世代の最上位GPUコア「GA102」は,トランジスタ数が約280億個で,ダイサイズは628mm2であった。最上位同士のAD102とGA102を比較すると,AD102のほうが,約3%小さいダイサイズなのに対して,約2.7倍のトランジスタを詰め込んでいることになる。
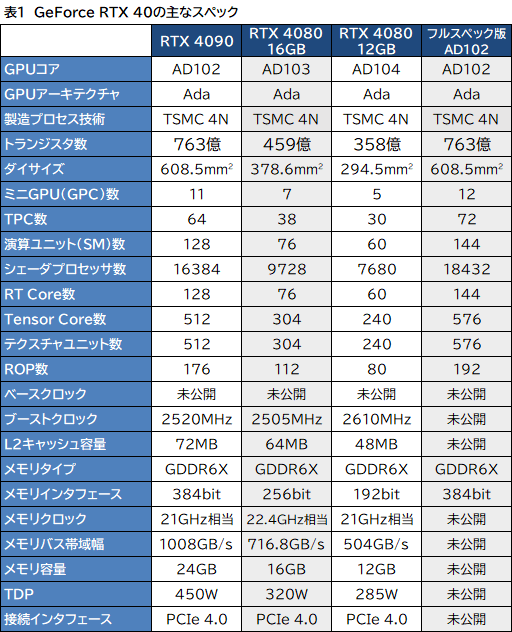
次のスライドは,フルスペック版AD102のブロック図である。
 |
NVIDIAは,GPU「コア」に相当するミニGPUクラスタを「Graphics Processor Cluster」(以下,GPC)と呼んでおり,フルスペック版AD102は,12基のGPCで構成されている。
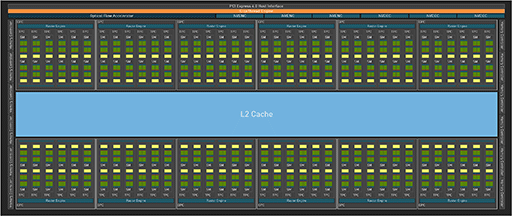
一方で,同じAD102を採用するGeForce RTX 4090では,歩留まり向上のためか,GPCの1つを無効化しており,GPC総数は11基となっている。以下にGeForce RTX 4090のブロック図を示そう。
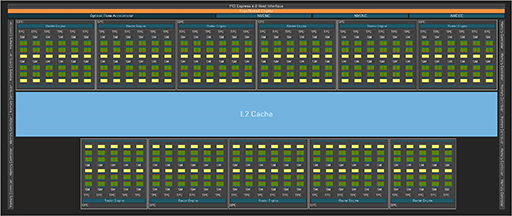 |
 |
そこで,改めてGeForce RTX 4090のブロック図で下側左端と右端のGPCをよく見ると,他のGPCと比べて,SM数が2つずつ少ない10基となっていることに気づくはずだ。これまでのNVIDIA製GPUと同じくAD102でも,歩留まり向上のために,いくつかのSMに不良があっても製品化できるようにと,GPC削減に加えて,一部のGPCはSMを2基削減しているわけだ。
 |
フルスペック版AD102とGeForce RTX 4090のCUDA Core総数は以下のように計算できる。
フルスペック版AD102
- 12 GPC×12 SM×128 CUDA Core=18432
GeForce RTX 4090
- (9 GPC×12 SM+2 GPC×10 SM)×128 CUDA Core=16384
表2は「NVIDIA製GPUにおけるCUDA総数とSM内のCUDA Core数の変遷」をまとめたものになる。
| 世代 | GPU名 | CUDA core総数 | SM 1基あたりのCUDA core数 |
|---|---|---|---|
| Tesla | GT200 | 240 | 8 |
| Fermi | GF100 | 512 | 32 |
| Kepler | GK104 | 1536 | 192 |
| Maxwell | GM200 | 3072 | 128 |
| Pascal | GP102 | 3840 | 128 |
| Volta | GV100 | 5120 | 64 |
| Turing | TU102 | 4608 | 64 |
| Ampere | A100 | 8192 | 64 |
| Ampere | GA102 | 10752 | 128 |
| Ada | AD102 | 18432 | 128 |
AD103やAD104のブロック図は公開されていないが,AD103ベースのGeForce RTX 4080 16GBモデルはGPC 7基で,AD104ベースのGeForce RTX 4080 12GBモデルはGPC 5基であることは明らかになっている。AD103やAD104も同じAda世代なので,SM 1基にCUDA Coreが128基の構成は,AD102と変わらない。
そこで,GPC 5基のGeForce RTX 4080 12GBモデルで,CUDA Core数を求めると,
GeForce RTX 4080 12GBモデル
- 5 GPC×12 SM×128 CUDA Core=7680
となってNVIDIAの公開スペックと一致する。
しかし,GPU 7基のGeForce RTX 4080 16GBモデルは,同じように計算すると,
- 7 GPC×12 SM×128 CUDA Core=10752
となり,公称スペックにある9728基と一致しない。AD102のように,一部のGPCではSMが10基に減っていると仮定して,CUDA Core総数が9728基となるような構成を考えると,
- (3 GPC×12 SM+4 GPC×10 SM)×128 CUDA Core=9728
という組み合わせが見つかる。
いずれにせよ,AD102を見る限り,GeForce RTX 4080シリーズがGPCをフルに有効化しているとは考えにくい。もしかすると,フルスペック版AD104はGPCが6基,同AD103はGPCが8基で,歩留まりが改善されて同じ半導体ダイで製品バリエーションを増やせるようになると,より多くのGPCやSMを有効化した「GeForce RTX 4080 Ti」が投入されるのかもしれない。
各GPUの理論性能値も求めてみよう。
4nmプロセスの恩恵もあって,Ada世代の最大動作クロックは,2.5GHzを超える。そこで,「CUDA Core総数×2 FLOPS(積和算)×動作クロック」で求められる理論性能値は,以下のようになる。
GeForce RTX 4090:ブーストクロック 2520MHz
- 16384 CUDA Core×2 FLOPS×2520MHz≒82.58 TFLOPS
- 9728 CUDA Core×2 FLOPS×2505MHz≒48.74 TFLOPS
- 7680 CUDA Core×2 FLOPS×2610MHz≒40.1 TFLOPS
GeForce RTX 4080シリーズは,GeForce RTX 3080の29.77 TFLOPSに対して,約1.3〜1.6倍もの性能向上を実現しており,これはこれでとても立派なのだが,GeForce RTX 4090に至っては,GeForce RTX 3090の35.58TFLOPSに対して約2.3倍の性能向上と,もはや異常なレベルだ。
余談だが,仮に,フルスペック版のAD102が存在して,GeForce RTX 4090と同じブーストクロックで動作した場合,
AD102:ブーストクロック 2520MHz(仮定)
- 18432 CUDA Core×2 FLOPS×2520MHz≒92.90 TFLOPS
となり,なんと90 TFLOPSを超える。フルスペック版AD102が,本当にこの性能値に到達できるのかは,興味深いところである。
AdaでもSMの構成に大きな変化はなし
ここからはAdaのアーキテクチャについて深く見ていこう。
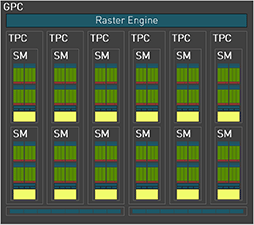
次の画像は,Ada世代とAmpere世代のGPCブロック図だ。
 AdaにおけるGPCのブロック図(再掲) |
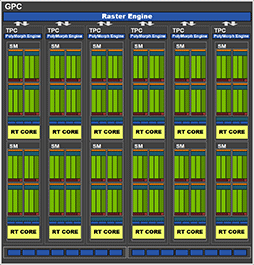 AmpereにおけるGPCのブロック図 |
異なる資料からの引用であるため,描き方に若干違いはあるものの,構成としてはAmpere世代とまったく同一なのが分かる。
ちなみに,図中のTPCとは「Texture Processing Cluster」の略で,テクスチャユニット群を共有するSMやRT Coreなどをまとめたグループの名称である。なお,図には描かれていないが,実際にはテクスチャユニット群だけでなく,ジオメトリエンジン(NVIDIAではPolyMorph Engine)もTPC内にある2基のSMで共有する構造だ。
また,各図の最下段に,何のユニットか記載がない8×2列のマスがあるが,これは「Rendering Output Pipeline」(以下,ROP)ユニットである。ピクセルシェーダから出力されたピクセルデータを,グラフィックスメモリに書き出す処理を行う部分だ。たとえば,実際にピクセルとして書き出すか否かをテストする深度テスト(Depth Test)や,ジャギーを低減させるマルチサンプルアンチエイリアス(MSAA)処理なども,ROPユニットが担当する。
AD102では,GPC 1基あたり16基(8基×2クラスタ)のROPユニットがあるので,フルスペック版AD102ならば192基(12 GPC×16 ROP),GPC 11基構成のGeForce RTX 4090では,176基(11 GPC×16 ROP)のROPユニットがあるわけだ。
続いて,Ada世代とAmpere世代のSMを拡大したブロック図を下に示す。
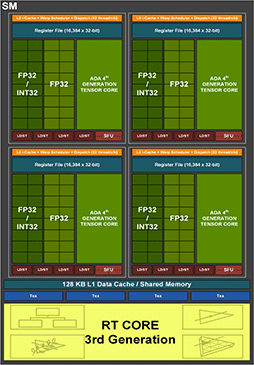
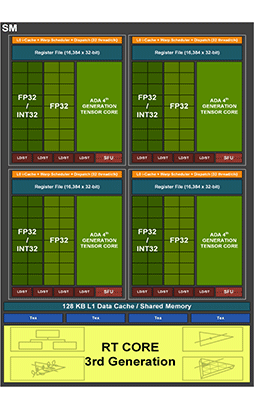 AdaにおけるSMのブロック図(再掲) |
 AmpereにおけるSMのブロック図 |
こちらもパッと見では,Ampere世代の代わり映えがない。AdaでもAmpereと同じく,SM 1基あたり4つのCUDA Coreクラスタがあり,各CUDA Coreクラスタは,16基の32bit浮動小数点(FP32)演算器と,FP32演算器としても32bit整数(INT32)演算器としても使える16基の演算器(FP32/INT32)を備えているのが見てとれよう。
ちなみにINT32演算器は,整数演算以外の論理演算や各種アドレス計算,フロー制御(GPUの場合はPredication処理,いわゆる条件付き実行制御)なども担当する。
図でRT Coreの上にあるテクスチャユニット(Tex)は,各種テクスチャ関連処理を請け負う部分だ。具体的には,読み書きするテクスチャ(テクセル)データの成形処理,MIP-MAPレベルやテクスチャ座標を絡めたテクスチャアドレスの計算などを担当する。
SM全体では128基のCUDA Coreを実装しているが,SM 1基あたりのテクスチャユニットは,4基と少ない。CUDA Coreとテクスチャユニットの比率は32:1で,テクスチャ処理能力よりも演算能力を重視した設計となっていることが分かる。この比率もAmpere世代と同じなので,現行世代のGeForce GPUでは,これがベストバランスとNVIDIAは判断しているのだろう。
各世代のNVIDIA製GPUにおけるSM 1基あたりのCUDA Core数とTPC数の関係を表3にまとめておく。
| GPU名 | CUDA core数 | テクスチャ |
CUDA core数: テクスチャユニット数 |
|---|---|---|---|
| Tesla GT200 | 8 | 8 | 1:1 |
| Fermi GF100 | 32 | 4 | 8:1 |
| Kepler GK104 | 192 | 16 | 12:1 |
| Maxwell GM200 | 128 | 8 | 16:1 |
| Pascal GP102 | 128 | 8 | 16:1 |
| Volta GV100 | 64 | 4 | 16:1 |
| Turing TU102 | 64 | 4 | 16:1 |
| Ampere A100 | 64 | 4 | 16:1 |
| Ampere GA102 | 128 | 4 | 32:1 |
| Ada AD102 | 128 | 4 | 32:1 |
なお,SMのブロック図には描かれていないが,AdaのSMには,64bit倍精度浮動小数点(FP64)の演算器も実装されている。その数は,Ampere世代と同じ「SM 1基あたりFP64演算器は2基という構成だ。つまり,
FP32演算性能:FP64演算性能=64:1
となる。あまり高性能ではないが,NVIDIAが「GeForceブランドのGPUには,高いFP64演算性能は必要ない」と判断しているためだ。実際,NVIDIAが公開した資料にも,「FP64演算機能は,FP64 Tensor コードを含むすべてのFP64命令との互換性を保つために搭載したにすぎない」と書かれている。
ブロック図に戻って,各CUDA Coreクラスタに4つある「LD/ST」は,「ロード/ストア」ユニットのことだ。キャッシュメモリやグラフィックスメモリへの読み書きを司るところになる。一方,「SFU」は,「超越関数」ユニットのこと。三角関数や対数関数,指数関数などによる演算を担当する。
CUDA CoreクラスタにおけるLD/STやSFUの搭載数も,Ampere世代から変わっていない。同様に,L0キャッシュ容量やレジスタファイルの個数(32bit×16384個),L1キャッシュ容量(SM 1基あたり128KB)なども,Ampere世代と同じだ。
レイトレーシング時代のGPUに必要なもの〜それは大容量LLCキャッシュ
こうして見てくると,全体として,Ada世代は,Ampere世代からあまり変化がないように思える。しかし,Ada世代の基本的な構造において,NVIDIAが大きく強化したのは,L2キャッシュだ。
NVIDIAは,AD102のL2キャッシュメモリ容量を96MBに拡大したのだ。Ampere世代のGA102が6MBだったのに比べれば,16倍にも相当する。この特徴は,当時としては大きな容量40MBのL2キャッシュを搭載していた,GPGPU専用GPUとして登場した「GA100」の設計思想に近い。
フルスペック版AD102では,32bitバスのGDDR6Xメモリコントローラを12基搭載しており,各1基ずつに容量8MBのL2キャッシュを接続している。そのため,8MB×12基=96MB」というわけだ。
NVIDIAは,このAD102に巨大なL2キャッシュを搭載したことについて,「一般的なグラフィックス処理系の高速化に貢献できるのはもちろんだが,なにより,レイトレーシングの処理に最大の効果を発揮させるためにこうした」と述べている。
なお,実際のGeForce RTX 40シリーズにおけるL2キャッシュメモリ容量は以下のとおり。
- GeForce RTX 4090:72MB
- GeForce RTX 4080 16GBモデル:64MB
- GeForce RTX 4080 12GBモデル:48MB
いずれにせよ,L2キャッシュにしてはかなりの大容量だ。ただ,GPUへの大容量キャッシュ搭載は,Adaで始まったことではない。AMDは,RDNA 2ベースのRadeon RX 6000シリーズで,L2キャッシュの大容量化に着手した。搭載理由も同じで,基本性能向上とレイトレーシング処理系の高速化である。
たとえば,RDNA 2ベースの最上位モデル「Radeon RX 6900 XT」(以下,RX 6900 XT)では,64bitバス幅のGDDR6メモリコントローラが4基あり,メモリコントローラ1基あたり,容量256KBのL2キャッシュを4基ずつと,容量8MBのL3キャッシュを4基ずつ搭載していた。つまり,RX 6900 XTは,全体で4MBのL2キャッシュ(256KB×4基×4 メモリコントローラ)と,128MB(8MB×4×4 メモリコントローラ)のL3キャッシュを搭載しているわけだ。この大容量L3キャッシュを,AMDは「Infinity Cache」と呼んで,Radeon RX 6000シリーズ登場時に大きくアピールしていた。
 |
一方,NVIDIA製GPUに,RDNA 2世代GPUのような大容量L3キャッシュはないが,LLC(ラストレベルキャッシュ)の大容量化というコンセプトは同じなのだ。
Ada世代は,Ampere世代から引き続いてグラフィックスメモリに「GDDR6X」を採用する。GDDR6Xは,同クロック駆動でGDDR6メモリの2倍というメモリバス帯域幅を実現する高速版GDDR6メモリである。遅延の面では「HBM2」には及ばないが,帯域幅ではHBM2に肉迫する性能を実現するのが特徴だ。
先述したように,AD102は,32bitバス幅のGDDR6Xメモリコントローラを12基搭載しているので,GDDR6Xメモリとは384bit幅(32bitバス×12基)で接続されている。
グラフィックスメモリのメモリチップはMicron Technology製で,同じGDDR6Xメモリを搭載していたGeForce RTX 30シリーズ世代よりも,さらに広帯域のものを採用する。
最大のメモリバス帯域幅を有するのは,最上位のGeForce RTX 4090なのだが,GDDR6Xメモリを最も高速なメモリクロック22.4GHzで駆動するのは,GeForce RTX 4080 16GBモデルだ。これはなかなか興味深い。
なお,各モデルごとのメモリバス帯域幅は以下のとおり。
GeForce RTX 4090
- メモリインタフェース 384bit,384bit×21GHz÷8=1008GB/s
- メモリインタフェース 256bit,256bit×22.4GHz÷8=716.8GB/s
- メモリインタフェース 192bit,192bit×21GHz÷8=504GB/s
最上位のGeForce RTX 4090では,GDDR系メモリで,ほぼ1TB/sというHMBクラスのメモリバス帯域幅を実現したわけで,これもまた,なかなか感慨深い事実である。
Adaにおけるレイトレーシング性能の強化(1)
RT coreの交差判定スループットを2倍に
 |
レイトレーシング処理を高速化するために,Adaでは,レイトレーシング処理系にいくつもの改良を加えた。改良点を理解するためには,「レイトレーシングとは何か」という部分について,基礎を振り返る必要がある。
大ざっぱに言えば,レイトレーシングとは,あるピクセルの色を算定するとき,そのピクセルが受け取っているはずの光の情報を得るために,光線(ray:レイ)を射出してたどる(trace)処理をいう。
GeForce RTX 30のときも使った図だが,レイをロケットに置き換えた概念図をもとに説明してみよう。
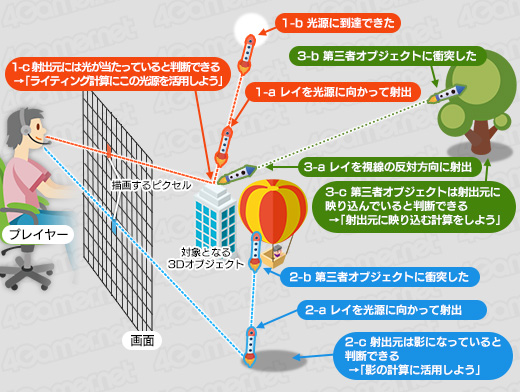 |
この図は,レイトレーシングにおける3種類の典型的な処理を示している。
1つめの処理は,図の上側にある「1-a」〜「1-c」にあたり,あるピクセルに光が当たっているかを調べるものだ。あるピクセルから飛ばしたロケット(=レイ)が光源に到達したら,発射元のピクセルに光が当たっていると判断できるので,プログラマブルシェーダ(CUDA Core)を呼び出して,ピクセルの陰影具合を計算する。
2つめは,図の下側にある「2-a」〜「2-c」で,あるピクセルが影になっているかを調べるものだ。光源に向けて飛ばしたロケットが何かに衝突したのであれば,発射元のピクセルは光源から何かに遮蔽されていることになるので,影になっていると判断できる。そのため,該当のピクセルは暗い色で描くことになるわけだ。
3つめは,図の右側にある「3-a」〜「3-c」で,あるピクセルに何かが映り込んでいないかを調べるものだ。光が当たっていると判断したピクセルから,視線の反対方向にもロケットを飛ばす。もし,ロケット発射元のピクセルがテカテカした金属のように反射しやすい材質で,そのロケットが視線の反対方向で何かと衝突した場合は,発射元のピクセルに衝突した何かが映り込んでいると判断できるという理屈である。
このような仕組みでレイトレーシングの処理は行われるのだが,NVIDIAがRT Coreと呼ぶレイトレーシングユニットが担当するのは,ロケットを打ち出す「レイの生成処理」と,レイを進める「トラバース」(Traverse,推進)処理,そして衝突判定を行う「インターセクション」(Ray-Triangle Intersection,交差)の3種類の処理だ。
なお,実際のライティングやシェーディングの計算は,レイトレーシングにおいてもプログラマブルシェーダが担当する。
RT Coreが担当する処理の中で,とくに負荷が高いのはトラバースとインターセクションだ。そこでAdaでは,2種類の処理における性能を強化する取り組みが行われた。
|
性能の倍化は,RT Core 1基あたりにおけるスループットの話なので,プロセス4nm化の恩恵である動作クロックの引き上げや,SMの増量(=RT Core増量)も加味すれば,GA102に対するAD102のレイトレーシング性能は,2倍以上と言えるだろう。NVIDIAは,GeForce RTX 3090 Tiに対するGeForce RTX 4090のRT Coreの性能上昇率を約2.4倍としている。
ちなみに,RT Coreにおけるインターセクション性能の強化は,Turing世代(GeForce RTX 20世代)からAmpere世代へ移行したときも,スループットが2倍(事実上のユニット数倍増)になっていた。その意味では,Ada世代はTuring世代と比べて,スループットが4倍に増えたことになる。NVIDIA製GPUは,一世代ごとに倍々ゲームでRT Coreを増量しているわけだ。
Adaにおけるレイトレーシング性能の強化(2)
Opacity Micromap Engineの搭載
発射したレイが,ポリゴンに衝突したかどうかを判定するインターセクションで面倒なのは,たとえば「衝突した」と判定しても,「本当にそのポリゴンは存在するのか」を疑ってかかる必要があることだ。
たとえば,レイの衝突したポリゴンに「葉っぱ」のテクスチャが貼られていたとする。ポリゴンは三角形であり,葉っぱのテクスチャは,自由な形状で描かれた図のようなものだ。葉っぱのテクスチャにおける実体部分は,緑色のテクセル(テクスチャを構成するピクセルのこと)で塗られているかもしれないが,それ以外の部分は透明として「実体なし」とするのが一般的だ。
 |
レイがポリゴンに衝突したとき,衝突先がポリゴンに適用された葉っぱテクスチャの実体部分なら,そのレイは「衝突した」と見なせる。しかし,葉っぱテクスチャの透明部分ならば,実体はないのだから,「衝突していない」と判定してレイを素通りさせなければおかしなことになる。
RT Coreは,レイとポリゴンの衝突は判定できるものの,ポリゴンにどんなテクスチャが貼ってあるのかは分からない。テクスチャユニットを子分に従えているプログラマブルシェーダに判別を頼むしかないのだ。とはいえプログラマブルシェーダも,通常のラスタライズ法による描画に動員されていて忙しいので,RT Coreがレイとポリゴンの衝突を検出するたびに,「このポリゴンに貼られているテクスチャを調べて」と依頼しても,すぐには請け負えないことが多々あるのだ。
Microsoftのレイトレーシング技術「DirectX Raytracing」によるレイトレーシング処理系では,対象3Dシーンを構成する各ポリゴンに対して,必要に応じて「透明タグ」(NonOpaqueタグ)を付けて,レイを素通りさせる処理はできる。しかし,透明タグ設定はあくまでもポリゴン単位でしか行えず,ポリゴンに貼り付けたテクスチャに透明要素があるかの情報を,ポリゴンにタグ付けするような仕組みはなかったのだ。
そこでNVIDIAは,RT Coreの衝突判定でプログラマブルシェーダにテクスチャ調査依頼を外注しない仕組みを考案した。それが「Opacity Micromap Engine」だ。
Opacity Micromap Engineとは,レイが衝突した部分が確実に透明なのか,それとも確実に不透明なのか,あるいは分からない(不明)のかを,RT Core自身で解決できる仕組みを提供する。プログラマブルシェーダへの問い合わせを不要にするメカニズムというわけだ。
概念的には,DirectX Raytracingにおけるポリゴンに付ける透明タグを進化させたもの,と考えるのが分かりやすい。
ポリゴンに付ける新しい仕様のタグは,最大4096×4096単位のテクスチャのようなデータ構造で,NVIDIAはこれを「Opacity Micromap」と呼んでいる。テクスチャのようなものと考えると分かりやすい。
一般的な画像テクスチャの場合,1テクセル(テクスチャを構成するピクセル)は赤緑青の色値などを保持するものだが,Opacity Micromapでは,1要素が持てるのはわずか2bitのデータでしかない。この2bitで,透明/不透明/不明を表現するわけである。
レイがポリゴンにヒットすると,RT Coreは,ポリゴンに付いているOpacity Micromapを参照して,レイの衝突部分に対応する透明/不透明/不明の情報を読み出して,その後,レイをどうするかを以下の三択から決める。
- 衝突部分は透明:レイは素通りする
- 衝突部分は不透明:衝突と判定して次の処理に進む
- 衝突部分が不明:従来どおり,プログラマブルシェーダに実際のテクスチャを読みだして精査してもらう
なお,Opacity Micromapは,実際にポリゴンに貼り付けるテクスチャの解像度と一致している必要はない。テクスチャが256×256テクセルであったとき,Opacity Micromapの解像度は,これよりもだいぶ低い,たとえば64×64のような低解像度でもいいそうだ。
NVIDIAは,「Opacity Micromapとは,仮想的なマイクロポリゴン(Virtual Mesh of Micro-Triangles)である」と説明しており,一般的なテクスチャのような「正方形のテクセルで構成するマトリックス」構造ではなく,「三角形で構成されるマトリックス」構造になっている。
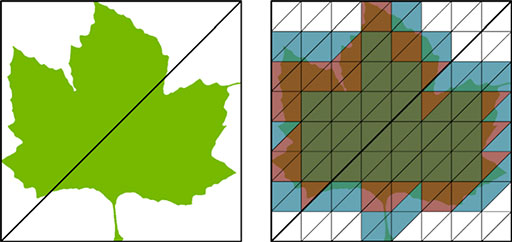 |
レイの衝突部分に対応するOpacity Micromaの位置関係は,幾何学的な演算で算出する。つまり,テクスチャユニットが行う複雑なマルチサンプル演算は不要で,一意的な写像を求めるような,ポイントサンプル的な単純計算で済む理屈だ。もともとが,レイの衝突判定を効率よく行う仕組みなので,複雑な演算は不要なのだ。
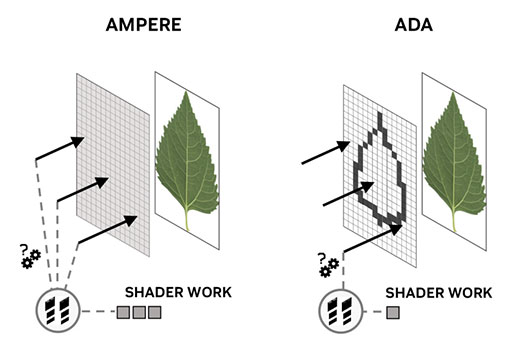 |
Opacity Micromapを活用すれば,各レイがポリゴンと衝突したときに,テクスチャの中身をプログラマブルシェーダに精査してもらう頻度が激減するので,レイのトラバース効率が上がるわけだ。NVIDIA社内のテストでは,シーンによっては,レイのトラバース性能が2倍になったという。
名作アクションゲーム「Portal」のNVIDIA製無料DLC「Portal with RTX」を使った例で,どれくらいの性能向上を実現できたかを,NVIDIAが公開している。
 |
上のシーンにおいて,レイが煙パーティクルに衝突したときに,プログラマブルシェーダに対するテクスチャの精査依頼がどれくらい発生したかをヒートマップで示したものが,次の画像だ。従来の手法で描画した場合が左で,Opacity Micromapを使って描画したのが右である。
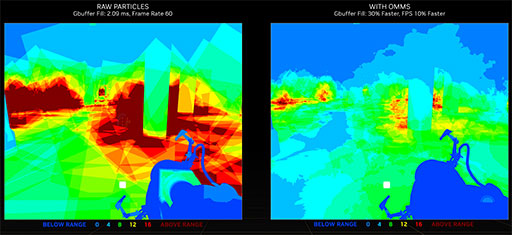 |
Opacity Micromapの仕組みを使えば,プログラマブルシェーダの使用が激減することが明らかだ。Opacity Micromapの活用により,このシーンはフレームレートが10%も向上したそうである。
さて,とても便利そうなOpacity Micromap Engineだが,既存のDirectX Raytracingでは使えないし,既存のゲームを改変せずにそのまま使うこともできない。NVIDIAがMicrosoftと開発を進めているというDirectX Raytracingの対応APIが登場するのを待つか,あるいは,NVIDIAが提供する拡張API(NVAPI Extension)を利用する必要があるとのことだ。
Adaにおけるレイトレーシング性能の強化(3)
Displaced Micro-Mesh Engineの搭載
たとえば,ある3Dシーンにおけるポリゴン数が100倍に増えた場合,レイトレーシングの処理系における負荷は,どのくらい増加するのだろうか。
これに対してNVIDIAは,「レイのトラバース処理とインターセクション処理について言えば,せいぜい2倍程度の増加にすぎない」と答えている。これは,リアルタイムレイトレーシング技術において,3Dシーンを「Bounding Volume Hierarchy」(以下,BVH)と呼ばれる階層型の3Dオブジェクト構造で取り扱っているおかげだ。
BVHを構成する基本要素は,3Dモデル全体を覆うことができる最小体積の直方体(BOX)である。この直方体は,3D座標軸に平行,垂直な向きに揃えられた「Axis Aligned Bounding Box」(以下,AABB)構造になっており,こうした構造体を,リアルタイムレイトレーシング技術においては「Acceleration Structure」(以下,AS)と呼ぶ。
レイを推進(トラバース)させたら,BVHを参照して,3Dモデルがレイと衝突しているかどうかを,この単位直方体(AABB)で判定する。BVHは,直方体の階層構造になっているので,レイと衝突している最下層の直方体までをたどることで,最終的に最下層の直方体に含まれるポリゴンと衝突判定を行えばいいわけだ。
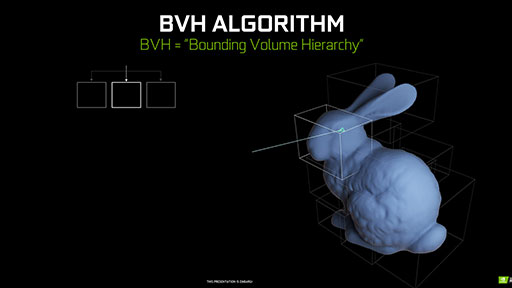 |
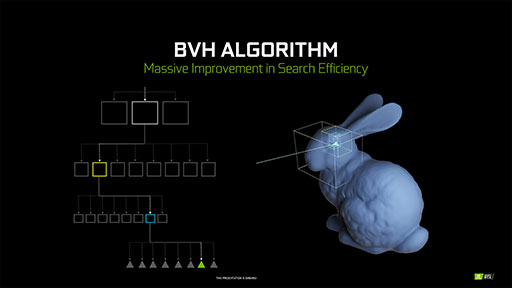 |
3Dシーンのポリゴン数が100倍になると,BVH探索における階層が増えるので,下階層への探索数も増える。しかし,レイのインターセクション処理は,上層の粗い直方体で「衝突してない」と判定できれば素通りできるので,深い階層までBVH探索が及ぶのは「衝突している」と判定されたレイについてだけだ。つまり,3Dシーンのポリゴン数が100倍になっても,レイのトラバース処理時間とインターセクション処理時間は,100倍にはならないのである。
しかしNVIDIAは,BVH構造による処理には問題があると主張する。「3Dシーンの複雑さが増加(≒ポリゴン数が増大)したときに,レイトレーシングの処理系において最も負荷がリニアに増大してしまうのは,BVHの生成や更新時間と,BVHが消費するグラフィックスメモリ容量である」と言うのだ。
そこでNVIDIAは,BVH探索の高速化とBVH容量の省サイズ化を実現したうえで,多ポリゴン3Dシーンにおけるレイの衝突判定を高効率化する仕組みとして,「Displaced Micro-Mesh Engine」をAdaのRT Coreに組み込んだ。
結論から言うと,「変移マイクロメッシュ」(Displaced Micro-Mesh)の仕組みは,Opacity Micromapとよく似ている。
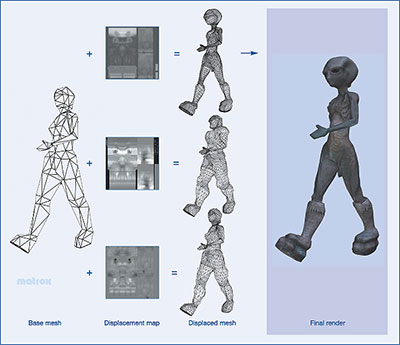
Displaced Micro-Mesh Engineを活用するには,前もって,3Dオブジェクトを構成するポリゴンを,低ポリゴンの3Dモデルと,そのディテール表現に相当する変移マイクロメッシュに分離する。変移マイクロメッシュとは,「ディスプレースメントマッピング」(Displacement Mapping)で扱う「ディスプレースメントマップテクスチャ」の概念とほぼ同じようなものだ。
ディスプレースメントマップテクスチャとは,3Dモデルにおけるディテール表現を,凹凸の変移量としてテクスチャマップにしたものである。
ディスプレースメントマッピングでは,低ポリゴンの3Dモデルを,DirectX 11で登場したポリゴンのプログラマブル分割機構「テッセレーションステージ」で,多ポリゴンに分解(テッセレーション)したうえで,ディスプレースメントマップの凹凸に応じて3Dモデルを凹ませたり盛り上げたりしてディテールを与える。
 |
AdaのDisplaced Micro-Mesh Engineで扱う,変移マイクロメッシュは,事実上はテクスチャのようなものだが,実体としては,微細な三角形からなる凹凸表現だ。先に,Opacity Micromapはテクスチャと似ているが,実際は微小な三角形で構成するマトリックス構造であると述べた。これの凹凸情報版が変移マイクロメッシュなのだ。
変移マイクロメッシュは,低ポリゴンモデルを構成するポリゴンに,1対1で対応するシンプルな構造である。ただ,ディスプレースメントマップのようなUV情報は持たない。ちなみに,凹凸の量(Scalar Displaced Value)を示すフォーマットは,浮動小数点をサポートしておらず,演算負荷の低い「11bitの符号なし正規化整数」(UNORM)で表す。具体的には,表現したい変移マイクロメッシュが含む凹凸量のすべてを「0.0」〜「1.0」の範囲で正規化して,これを「0」〜「2047」(11bit整数)の整数値で表現する。
次に示す図は,変移マイクロメッシュの概念を示すものだ。左の蟹モデルが元データで,右が最終的な描画結果である。左のモデルは,低ポリゴンモデル(左端)から,順に多ポリゴンモデルへ変わることを示す。BVHは低ポリゴンモデルで生成してレイの衝突判定に使うが,変移マイクロメッシュは,多ポリゴンモデルであらかじめ生成しておき,低ポリゴンモデルと対応付けておく。
 |
レイの衝突判定におけるBVH探索は,低ポリゴンモデルからなるBVHに対して行う。レイが,BVH上層の直方体にヒットしたと判定され,最終的に低ポリゴンモデルを構成する1つのポリゴンに当たっていることが分かったとしよう。ここでDisplaced Micro-Mesh Engineは,レイが衝突したポリゴンに対応する変移マイクロメッシュ上の凹凸情報を読み出して,レイが衝突した場所を補正する。すなわち,レイの衝突場所を低ポリゴンモデル上の1ポリゴンから,多ポリゴンモデル上の1ポリゴンへと修正するわけだ。
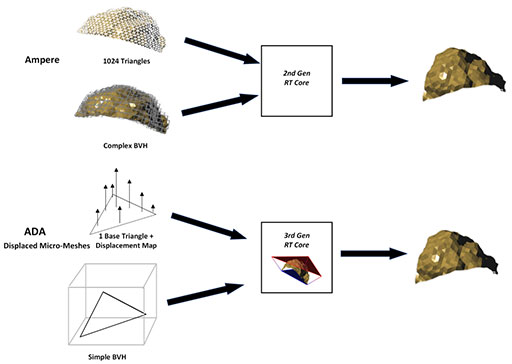 |
ちなみに,変移マイクロメッシュの分解能は,実際に描画する3Dモデルのポリゴン数と一致していなくても構わない。たとえば,間接照明や影生成のように,レイトレーシングによる描画結果にそれほどの正確性は求めない。それっぽい見た目になれば十分という場合,実際に描画する3Dモデルのポリゴン数が10万ポリゴンだったなら,変移マイクロメッシュは1万ポリゴン程度の3Dモデルから生成したものでも構わないという。
こうした工夫により,BVHの生成や更新にかかる時間を短縮したり,BVH容量の削減したりできるだけでなく,レイのトラバース処理や衝突判定処理にかかる時間も相応に削減できるわけだ。
NVIDIAが,Displaced Micro-Mesh Engineを用いた場合と,用いない場合でどれだけ処理性能が向上したかを調べたところ,BVHの生成と更新速度は8〜15倍速くなり,BVHのサイズは6〜20分の1まで小さくできたとのこと。
 |
なお,Displaced Micro-Mesh Engineも,既存のDirectX Raytracingでは使えず,既存ゲームに対して自動で機能するものではない。新しいのDirectX Raytracingの登場を待つか,NVIDIAが提供する拡張API(NVAPI Extension)が必要になる点は,Opacity Micromap Engineと同じだ。
Adaにおけるレイトレーシング性能の強化(4)
Shader Execution Reorderingの搭載
ここまでの改良点は,レイトレーシング処理におけるレイのトラバース処理や,衝突判定処理の高効率化に向けた取り組みだった。
レイトレーシング処理において,ピクセルから放たれたレイが,ポリゴンに衝突すれば(インターセクションが確定すれば),衝突部分の材質に応じたライティング演算だったり,テクスチャマップを絡めたシェーディング処理が必要になる。一方,レイが光源に到達すれば,発射元のピクセルでも同じようなライティングやシェーディングの演算が必要になってくる。そのようなライティングやシェーディング演算を行うのは,RT Coreではなく,プログラマブルシェーダであるCUDA Coreだ。問題なのは,プログラマブルシェーダの使われ方が,レイトレーシング法と従来のラスタライズ法とではまったく異なる点にある。
ラスタライズ法では,ポリゴンがラスタライザによって一塊のピクセルに分解され,そのピクセルがドバっとプログラマブル(ピクセル)シェーダ群に流し込まれる。ラスタライザが分解した一塊のピクセルは,1枚のポリゴンから作られたものだから,同一の材質であることが多い。つまり,各プログラマブルピクセルシェーダが実行するライティングやシェーディングのシェーダプログラムは同一のもので,ほぼ同じテクスチャを参照することになる。その場合,シェーダプログラムの実行効率も,キャッシュメモリの利用効率もすこぶるよくなる。
しかし,レイトレーシングの場合,隣接するピクセル群から発射されたレイも,それぞれの発射角度が違えば,異なる3Dモデルのポリゴンに衝突することになる。放たれたレイが,衝突先のポリゴンで反射することになれば,最終的にレイが衝突するのは,それぞれまったく異なる場所にあるポリゴンとなることも多い。つまり,各レイがライティングやシェーディングのために必要とするシェーダプログラムは,バラバラなものになり得るわけだ。参照するテクスチャもバラバラになれば,キャッシュメモリの利用効率も悪化する。
そもそも,各レイがプログラマブルシェーダにライティングやシェーディングを発注しようにも,別の仕事で忙しくて受注できない場合だってある。
近代的なGPUにおけるプログラマブルシェーダの実行モデルは,「Single Instruction Multiple Threads」(SIMT)と呼ばれる「Single Instruction Multiple Data」(SIMD)の発展形を採用している。この実行モデルでは,同じシェーダプログラムをまとまった複数のスレッド(ピクセル)に対して実行したときに,最大の性能を発揮できる。この実行モデルは,従来のレンダリング手法であるラスタライズ法での活用に最適化したものなので,レイトレーシング法によるプログラマブルシェーダの活用とは相性が悪いのだ。
そこで,NVIDIAがAdaに加えた改良が,「Shader Execution Reordering」(SER)の導入だ。
SERとは,衝突したとみなされたレイが,プログラマブルシェーダに仕事を発注するときに,同一のシェーダプログラムで実行できそうな発注を束にして発注する「発注管理」の役割を果たす。

SERを活用することで,同じシェーダプログラムが別々のプログラマブルシェーダで動く非効率な状態を減らせる。さらに,1つのプログラマブルシェーダで局所性の高いスレッド(たとえば同じ材質)を複数処理できるようになるので,キャッシュの利用効率も向上することになる。
NVIDIAは,SERについて「レイトレーシングパイプラインに,新しいステージを追加したもの」と述べる。CPUの命令実行モデルにおいて,演算器などの各種実行ユニットを高効率に活用するために,命令の「逐次実行」(インオーダー)スタイルから「順不同実行」(アウトオブオーダー実行)へ発展したようなイメージに近い。
以下の図を例に説明しよう。
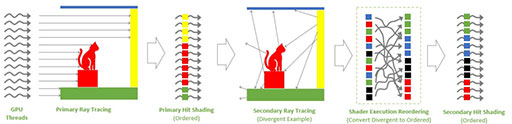 |
図の左側は,すべてのレイが高い局所性を持って3Dシーン内のポリゴンと衝突したときベストケースだ。衝突したレイに対するライティングやシェーディング処理は,それぞれまとまったプログラマブルシェーダに発注できる。一方,中央(Secondary Ray Tracing)は,すべてのレイがあちこちに反射しているため,高いランダム性を持って衝突したときのケースだ。こんな場合でも,SERを使って,近しいライティングやシェーディング処理を行えるよう,各レイの衝突事象を整理して,プログラマブルシェーダに発注すれば効率が上がるわけだ。
ただ,SERも,既存のレイトレーシング対応ゲームで,そのまま自動で利用できるものではない。当然ながら,ゲーム側がAPIを通じてSERに対応させなければ恩恵を受けられないのだ。
ゲームにおけるグラフィックスエンジンは,3Dモデルのどのポリゴンにどんな材質が設定されていて,どのテクスチャを使うかを把握しているので,何かに衝突したレイが,これからプログラマブルシェーダへ発注するであろう処理内容も見当が付く。グラフィックスエンジン側で効果的なSERメカニズムを実装するほうが,SERの仕組みを最大限に生かせるであろうことは,容易に想像がつく。
そのためNVIDIAは,Opacity MicromapやDisplaced Micro-Meshと同様に,Microsoftやそれ以外のグラフイックス関連企業と連携して,DirectX Raytracingでの標準化に向けた協議を進めているとのことだ。
なお,NVIDIAは,ゲーム開発者がSERを活用するにあたって,GPU性能解析ツール「NSight Graphics」を活用して,最適な制御を行うことを奨励している。
実際の効果だが,NVIDIAによると,「Cyberpunk 2077」におけるレイトレーシングモードの最上位設定「Overdrive Tracing」で,SER有効時はSER無効時に対して最大44%の性能向上を実現したそうだ。
 |
実はAmpere世代からあった「Optical Flow Acceleration」とはなにか
NVIDIAは,Adaの説明において,もう1つ,「Optical Flow Accelerator」(以下,OFA)というユニークな機能をアピールしている。
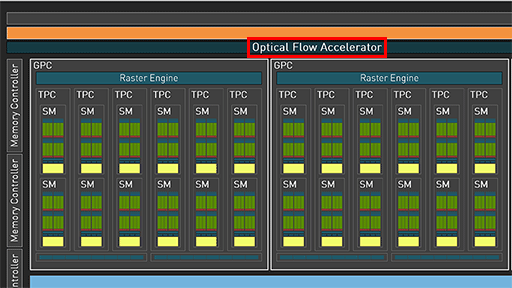 |
実は,このOFA,Adaで追加されたものではなく,Ampere世代GPUにも搭載されていたというから驚きだ。
NVIDIAによると,Ampere世代のGPGPU専用GPU「GA100」や,GeForce RTX 3090/3080シリーズのGPUコアであるGA102も,OFAを搭載していたそうである。調べてみると,たしかにGA100の技術資料にはOFAが明記されていたが,GA102の技術資料には書かれていないので,我々が知らないのも無理はない。
なお,NVIDIAによると,Turing世代のGPUでも,ビデオプロセッサの「NVENC」を特殊モードで使うことにより,OFA的に活用できるそうだ。NVIDIAは,GPU世代ごとに実装形態の異なるOFA相当機能を抽象化して扱えるようにしたライブラリ「NVIDIA Optical Flow SDK」を公開している。
OFAが何をするものかを理解するには,「Optical Flow」という言葉の意味を知っておく必要がある。
Optical Flowを直訳すると,「光学的な」(Optical)「流れ/流動」(Flow)となるが,意訳すれば,映像における光の遷移を解析する技術のことだ。Optical Flowという言葉は,NVIDIAが作ったわけではなく,デジタル画像解析,とくにコンピュータビジョン分野では定番のキーワードである。
Optical Flowが具体的に何をどうする技術なのかと言うと,「コンピュータに2枚以上の画像を与えて比較,解析して,そこから興味深い情報を算出する」技術である。Optical Flowの応用事例は,すでに我々の身の回りにも溢れている。たとえば,ミドルクラス市場向け以上のテレビが搭載する60fps映像を120fps映像に変換して見せる「倍速駆動」機能がそれだ。
60fpsの映像を120fpsに見せるためには,足りない映像フレームを演算で合成しなければならない。合成で作る「補間フレーム」は,過去フレームと現在フレームという2枚の画像に対するOptical Flow解析によって作っている。
また,今どきのVR HMDでは,ゴーグルの前面に組み込んだ複数のカメラによる映像を,VR HMDを装着したユーザー位置を推測するのに活用している。この技術を「インサイドアウト方式」のポジショントラッキング技術と呼ぶが,その基盤にもOptical Flow技術は応用されている。
NVIDIAによると,Ampere世代とAda世代が搭載するOFAは,与えられた2枚の画像から「ピクセル単位の移動ベクトル値」や「視差値」(深度値)を算出できるという。
移動ベクトル値とは,与えられた2枚の画像を「過去フレームと現在フレーム」と仮定して,画像内に存在するオブジェクトがどう動いたかを表す2D平面上における移動方向と移動量を,ピクセル単位に算出したものだ。一方,視差値とは,2枚の画像を,「左右に設置した2台のカメラで同時撮影した画像」と仮定して,2枚の画像内に共通して存在するオブジェクトを見つけ出して,その視差量を算出し,画像の奥行き構造(3D構造,深度値)を推定するものである。
 |
ここからが本題なのだが,NVIDIAは,Ada発表のタイミングで,OFAをAI処理ベースの超解像技術「DLSS」(Deep Learning Super Sampling)の最新版となる「DLSS 3」に活用することを発表した。
DLSSは,深層学習型AI技術により,GPUが描画したゲームグラフィックスに対して超解像処理を行うものだ。初代のDLSS(以下,DLSS 1)は,2018年に登場したTuring世代のGeForce RTX 20シリーズとともに発表となった。上位モデルGPU並みの高品質なグラフィックス表現を高いフレームレートで実現できる機能として,PCゲーマーにも知られた機能だ。
2020年に登場した「DLSS 2.0」(以下,DLSS 2)は,映像品質の向上や解像度とアスペクト比の制限緩和,小さなオブジェクトや動くオブジェクトに起きていた品質低下の低減といった改良が行われた。
そして,Adaに合わせて発表となったDLSS 3は,DLSS 2に対して映像品質の向上を行うだけでなく,先述したテレビが実装している倍速駆動機能と同じような,「補間フレーム技術」を搭載したことが大きな特徴だ。
ほとんどのテレビにおける補間フレーム技術は,「画面外や遮蔽物から飛び出して来たオブジェクト」や「画面外や遮蔽物に隠れるオブジェクト」の動きに対応できておらず,輪郭が振動したり,画面の一部領域にノイズが出たりすることがある。これは,テレビの補間フレーム生成が,過去から現在に向けた1方向のOptical Flowだけを元に処理していることに大きな原因がある。
ちなみに,一部のハイエンドテレビが採用する映像エンジンでは,3フレーム以上(※機種によっては7フレーム以上)をバッファリングして,時間軸における真ん中のフレームを「仮の現在フレーム」とみなして,「過去から現在」と「未来から現在」という2方向のOptical Flowを処理して補間フレームを生成することで,異常な振動やノイズを低減させている。
しかし,2方向のOptical Flowによる処理は,最低でも(バッファリングしたフレーム−1)/2だけ表示が遅延するので,とてもではないがゲームでは使えない。では,どうするか。
ゲームグラフィックスでは,グラフィックスエンジンが3Dシーンに存在するすべてのポリゴンにおける状態(位置や向き)を把握しているので,画面に描画したポリゴンを構成するピクセルの「1フレーム前における位置」と「現在フレームにおける位置」を追跡できる。
実際にゲームグラフィックスでは,追跡結果を,各種ポストエフェクト処理などに役立てるために,GPU上で「ピクセル単位のモーションベクター情報」を毎フレーム生成している。「ベロシティバッファ」などとも呼ばれる,この情報を元に,グラフィックスエンジンは,ブレを演出する「モーションブラー」や,映像のジャギーを低減させる「テンポラルアンチエイリアス」といったポストエフェクト処理を行っている。
であるならば,ゲームグラフィックスにおいても,ハードウェアによるOFAではなく,ベロシティバッファを用いて補間フレーム生成を実現できるのではないか。たしかに理屈ではそうなのだが,これに挑戦した事例はあまり多くない。それには理由がある。

たしかに,ベロシティバッファを活用した補間フレーム生成は,Optical Flowを活用した補間フレーム生成で生じる振動やノイズは発生しにくいが,別の問題がでできてしまう。それは,ライティング結果に対する予期せぬ振動だ。
次のスライドは,Cyberpunk 2077からオートバイが走行しているシーンを切り出したものである。このシーンで,道路の路面ポリゴンは奥側から手前に動いていく。ということは,路面を構成するピクセルの移動方向(&移動量)を表すモーションベクターは,左図にある矢印のように,画面の下方向や外周に向かう動きを示すことになる。
 |
ここで,モーションベクターをベースに補間フレームを生成すると,路面のピクセルがモーションベクター方向に動いた補間フレームが生成されることになるのだが,ここで問題が発生する。なんと「路面に落ちた影ごと動いた補間フレーム」が生成されてしまうのだ。
 |
 |
どれほど速く路面が動いても,影は後ろに動かない。影は,光が何かに遮蔽されて生じるものだから,路面の動きと影の投射は無関係だ。しかし,モーションベクターが表すのは,あくまでポリゴンベースの動きのみ。そのポリゴンに対するライティング結果にどういう意味があるかまでは反映していないので,こうしたことが起こるのである。
そこで役立つのが,Optical Flowだ。光の動きを追跡できるOptical Flowなら,過去フレームと現在フレームを比較したときに「動かない影」を正しく把握できるのではないか。このアイデアにより,ベロシティバッファに加えて,Optical Flowも利用することで,補間フレームを生成する仕組みをNVIDIAは採用した。
 |
こうすると,画面外や遮蔽物から飛び出したり,画面外や遮蔽物に隠れるたりするオブジェクトにも,おおむね正しく適応できて,ライティング結果に対しても矛盾の少ない補間フレームを作れるわけである。これが,DLSS 3における補間フレーム生成(DLSS Frame Generation)の仕組みだ。
次のスライドは,DLSS 3がどのような流れで映像を作るかを表した図である。
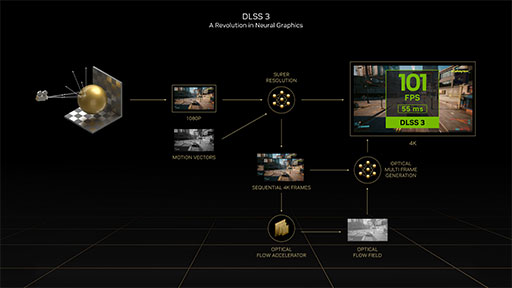 |
ここで話を戻すと,DLSS 3では,Optical Flowを演算するのにOFAを活用している。また,算出した結果の「Optical Flow Field」とベロシティバッファを組み合わせて補間フレームを生成するのは,推論アクセラレータであるTensor Coreを用いたAI処理系の役目だ。
なお,補間フレームは,あくまで算術合成したものなので,プレイヤーによるゲームの操作を反映した映像ではない。つまり,補間フレームの映像は,ゲーム操作とは無関係に作った絵になるわけだ。とはいえ,ゲームを操作してから,その結果を反映した映像が出るまでの遅延時間は,DLSS 3を使わない場合と変わらない。そのため,体感として遅延が大きくなることはないはずだが,このあたりは実際に対応ゲームをプレイしてみないと分からない。
また,DLSS 3は,補間フレーム生成だけでなく,従来のDLSSと同じく超解像処理も行う。DLSS 3の補間フレーム生成でフレームレートが2倍になり,従来のDLSSによる効果でも性能が向上するわけで,「最大でDLSS 2の4倍近い性能を得られる」と,NVIDIAは主張する。
ゲーム映像を4分の1解像度――たとえばフルHD相当――で描画して,これを超解像化によって高解像度化――たとえば4K――する。さらに,補間フレーム生成でフレームレートを倍増するというのが,NVIDIAが想定するDLSS 3適用時の理想的なシナリオだ。このシナリオでは,GPU自体の実質的な描画負荷は,表示するピクセル全体のわずか8分の1で済み,逆に8分の7は,AIや算術処理によって生成したピクセルとなる。
 |
NVIDIAによると,DLSS 3は主要ゲームエンジンへの採用も決まっているそうで,新作ゲームだけでなく,既存のゲームにも採用が進むそうだ。
 |
 |
さて,先にOFAはAmpere世代のGPUから実装されたと述べたが,残念なことに,DLSS 3は,Ampere世代GPUには対応しておらず,Ada世代GPUでしか動作しない。Ampere世代のOFAは,リアルタイムなゲーム映像の補間フレーム生成には性能が足りないというのが理由とのことだった。
また,既存のDLSS 1やDLSS 2に対応したゲームでは,そのままではDLSS 3を利用できず,明確に対応させる必要がある。DLSS対応ゲームをプレイしている人は,この点も注意してほしい。
Tensor CoreはHopperと同世代のものを搭載
|
SMのブロック図で,Tensor Coreを見てみる。Ada世代でもAmpere世代と同じで,Tensor Coreは,32基のCUDA Coreクラスタごとに1基,つまりSM 1基あたり4基を搭載している。ただ,Ada世代のTensor Coreは,Ampere世代よりも新しくなり,2022年3月にNVIDIAが発表したHopper世代のGPGPU専用GPU「GH100」と同じ第4世代へと進化した。
具体的な改良点については,GH100の解説記事を参照してもらうとして,本稿でも軽く触れておく。
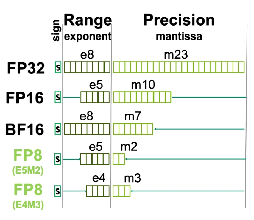 |
第4世代Tensor Coreで,これらのFP8に対応した命令セットを使って演算すると,その結果をTensor Core内部の「Range Analysis」で解析して,E4M3型やE5M2型のFP8に自動変換する「Transformer Engine」が組み込まれている。
Tensor Coreの理論性能値を計算してみよう。ここでは,すべての行列要素に値がある密な(Dense)FP16の理論性能値を求めている。ちなみにNVIDIAは,行列要素の半分にゼロを含む,疎行列(Sparse)の理論性能値も発表しているが,これはFP16性能値の2倍となる。
GeForce RTX 4090
- 512 Tensor Core×2520MHz×128並列×2 FLOPS=330.3T Tensor FLOPS
GeForce RTX 4080 16GBモデル
- 304 Tensor Core×2505MHz×128並列×2 FLOPS=195T Tensor FLOPS
- 240 Tensor Core×2610MHz×128並列×2 FLOPS=160.4T Tensor FLOPS
下位モデルであるGeForce RTX 4080 12GBモデルの160.4T TFLOPSという性能値は,先代で最上位のGeForce RTX 3090 Ti(160T TensorFLOPS)とほぼ一致する。GeForce RTX 40シリーズは,推論アクセラレータ性能の上げ幅にも遠慮がない。
ビデオプロセッサを3基搭載。待望のAV1エンコードにも対応
AD102の全体ブロック図を見ると,右上にビデオエンコーダ(NVENC)とビデオデコーダ(NVDEC)が複数あるのが分かる。GeForce RTX 4090の場合,このうちNVENCが2基,NVDECが1基が有効化されていて,アプリケーションから利用できる。
 |
AD103やAD104ベースのGeForce RTX 4080シリーズでも,NVENC×2,NVDEC×1の構成は同じで,GeForce RTX 40シリーズの上位モデルは,デュアルビデオエンコーダもウリの機能というわけだ。
NVDECは,Ampere世代と同じ第5世代のものだが,NVENCは世代が改まり,第8世代となった。最大の改良点は,「AV1」コーデックのリアルタイムエンコードに対応したことだ。AV1は,H.264と同画質の映像を,約40%ほど低いビットレートまで圧縮できる新世代のコーデックで,ロイヤリティフリーという利点もあってYouTubeなど大手ビデオ配信サービスで採用が進んでいる。
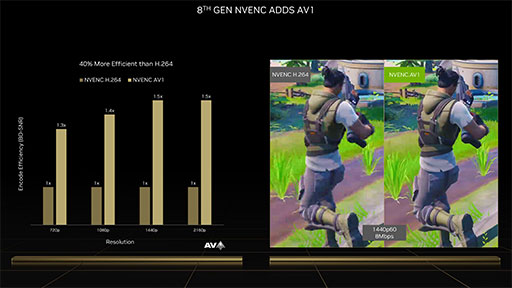 |
AD102のNVENCでは,1基のNVENCで4K解像度で60HzのHDR映像をリアルタイムエンコードでき,2基のNVENCを活用すれば,8K解像度で60HzのHDR映像をリアルタイムエンコードできるという。
 |
ゲーム実況者やYouTuberなどの映像クリエイターは,GPU選びでビデオプロセッサの性能を気にするようになってきている。GeForce RTX 40シリーズのデュアルエンコーダ搭載は,そうしたユーザー層に強く響きそうだ。
ちなみに,昨今の4K/8Kビデオの編集シーンでは,複数の4K/8Kビデオストリームで多段レイヤーを組んで編集するとデコーダへの負荷も高いので,編集時は低解像度のプロキシビデオストリームで代用して作業することも多い。そうしたハイエンドな映像クリエイターからすると,NVDECもデュアルで搭載して欲しかったかもしれない。プロフェッショナル向けGPUで,NVENCやNVDECをトリプル仕様で搭載する製品が登場したら,映像クリエイターに歓迎されそうだ。
多くの新機能と新要素を一度に詰め込んだAda世代GPU
最新の4nmプロセス採用に,100 TFLOPS目前のプログラマブルシェーダ性能,レイトレーシングユニットの大改革に,コンピュータビジョン系技術「Optical Flow」を組み合わせた補間フレーム挿入機能,さらにスパコン用GPUと同世代の推論アクセラレータや,マルチビデオプロセッサ搭載など,ここまで多くの新機能や新技術を一度に詰め込んできたGeForceは珍しい。初レイトレーシング対応のGeForce RTX 20系以来か,CUDAアーキテクチャに移行してGPGPUに対応したGeForce 8800 GTX以来だろうか。GeForce RTX 40に見合う衝撃が思い出せない。
Adaに搭載された新機能の多くは,DirectX側やゲーム側の対応が必要なものも多いが,今後のグラフィックス技術動向を示唆する存在となりそうなだけに,業界の注目度は高い。従来のプログラマブルシェーダ性能も劇的に高まっているので,既存のゲームを実行しても,Ada世代のGPUはシンプルに高い性能を得られるはずだ。円安の影響もあって相対的に価格は高くなっているが,購入できる人は導入して損はないと思う。
ただし,消費電力はめっぽう上がっている。NVIDIAによると,GeForce RTX 4080系でも最低700W以上,GeForce RTX 4090では最低850Wを推奨するとのこと。CPUもハイエンド系で組み合わせるのであれば1000W級が欲しくなる。既存のPCに導入しようと考えている人は,電源ユニットに十分な出力があるかの確認は忘れずに。
- 関連タイトル:
 GeForce RTX 40
GeForce RTX 40
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー