









ニュース
AMD,SoCになった新世代APU「Temash」「Kabini」を正式発表。Jaguar+GCNとなったそのアーキテクチャを丸裸にする
 |
ラインナップと主立った製品概要は下記のとおりとなる。
●Temash
- A6-1450:Radeon HD 8250,8W TDP
【CPU】1.0GHz(最大1.4GHz),4C4T,2MB L2
【GPU】128基,300MHz(最大400MHz)
【MC】DDR3L-1066 - A4-1250:Radeon HD 8210,9W TDP
【CPU】1.0GHz,2C2T,1MB L2
【GPU】128基,300MHz
【MC】DDR3L-1333 - A4-1200:Radeon HD 8180,3.9W TDP
【CPU】1.0GHz,2C2T,1MB L2
【GPU】128基,225MHz
【MC】DDR3L-1066
●Kabini
- A6-5200:Radeon HD 8400,25W TDP
【CPU】2.0GHz,4C4T,2MB L2
【GPU】128基,600MHz
【MC】DDR3L-1600 - A4-5000:Radeon HD 8330,15W TDP
【CPU】1.5GHz,4C4T,2MB L2
【GPU】128基,500MHz
【MC】DDR3L-1600 - E2-3000:Radeon HD 8280,15W TDP
【CPU】1.65GHz,2C2T,1MB L2
【GPU】128基,450MHz
【MC】DDR3L-1600 - E1-2500:Radeon HD 8240,15W TDP
【CPU】1.4GHz,2C2T,1MB L2
【GPU】128基,400MHz
【MC】DDR3L-1333 - E1-2100:Radeon HD 8210,9W TDP
【CPU】1.0GHz,2C2T,1MB L2
【GPU】128基,300MHz
【MC】DDR3L-1333
※APU名に続けて記載したのは統合型GPUのブランド名とプロセッサレベルのTDP(Thermal Design Power,熱設計消費電力)。その下では【CPU】の項目にCPUスペックを動作クロック,コア&スレッド数,共有ラストレベルキャッシュとその容量を,【GPU】の項目にシェーダプロセッサ数と動作クロックを,【MC】の項目にメモリコントローラのスペックをそれぞれ記載している。
AMDは,発表に先立つ5月上旬,事前技術説明会「AMD TECH DAY MAY 2013」をカナダのトロント市で開催した。今回はその内容を基に,AMDの新しいAPUを紹介していきたい。
28nm技術で製造される新世代APUの位置づけ
 |
統合されるCPUコアは「Jaguar」(ジャガーもしくはジャギュア)アーキテクチャを採用したもので,GPUコアのほうはRadeon HD 7900〜7700シリーズと同じく「Graphics Core Next」(以下,GCN)アーキテクチャのものだ。ついにAPUの搭載するGPUコアが(規模はともかくとして)世代的に単体GPUへ追いついたわけである。
順に見ていくと,まずTemashは,13インチ以下のタブレット端末や,タブレット端末としてもノートPCとしても利用できるPC用のAPU SoCだ。Radeon HD 8000シリーズの型番が与えられたGPUコアを統合することで,高いゲーム性能やマルチメディア性能を持つという。
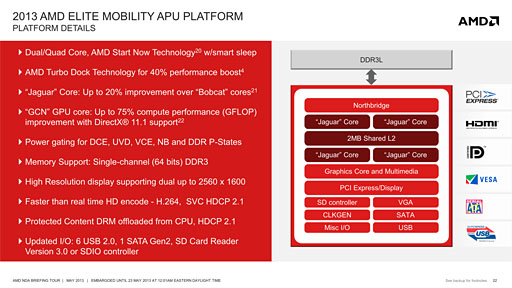 |
冒頭で紹介したとおり,Temashではデュアルコア版,正確には2コア分を動かなくさせたバージョンも提供されるが,AMDの位置づけとしては「このクラスでは世界初となる,リアルなクアッドコアを統合したx86 SoC」だ。競合となるIntelに対して,時間的には半年以上のリードがあるとAMDはアピールしている。
なお,Temashの性能は,Clover Trailコアを採用するAtomプロセッサから,ノートPC向けPentiumプロセッサまでに対抗できるとのことだった。
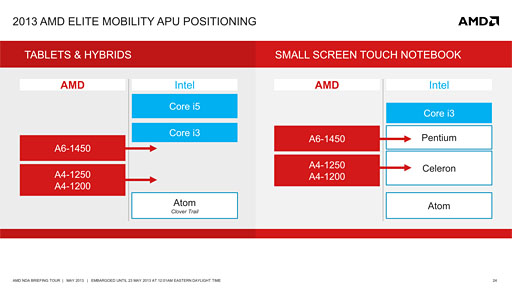 |
 |
最上位モデルのA6では,IntelのノートPC向けCore i3プロセッサと競合する性能が得られているとのことだ。
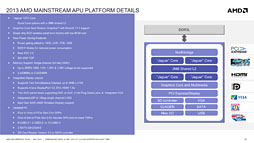 Kabiniのブロック図。Temashとまったく同じである |
 Kabiniと競合製品の位置づけ。ちょうどTemashより一段階上になるイメージ |
TemashとKabiniに採用されたJaguarアーキテクチャ
 |
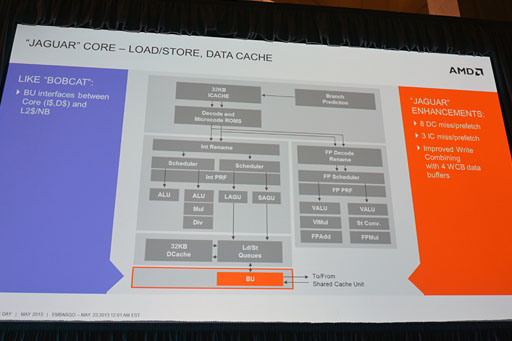
Macri氏によれば,Jaguarアーキテクチャにおいて,浮動小数点演算性能は従来のエントリー市場向けAPUのCPUアーキテクチャである「Bobcat」(ボブキャット)比で大幅に高められたとのこと。一例として,4つの32bit単精度浮動小数点数の積算と和算を同時実行できるようになったこと,1つの64bit倍精度浮動小数点積算と2つの64bit倍精度浮動小数点加算の同時実行ができるようになったことが報告されている。
ロード/ストア実行部とデータキャッシュ部は,整数演算実行部のOut-of-Order(アウトオブオーダ―)実行を高効率化したのに合わせた拡張を施してあるとMacri氏。ただ,Jaguarコアでも,データキャッシュサイズはBobcatコアと同じ32KBのままだ。
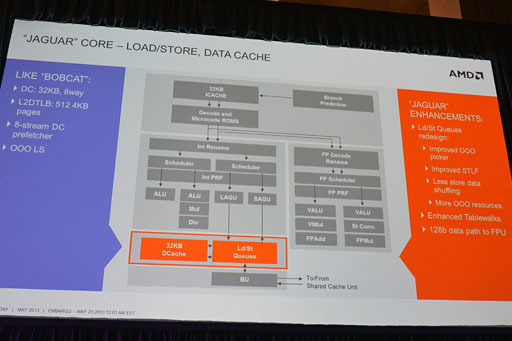 |
なお,バスユニットについては,「Jaguarコアでは,Write Combining(WC)におけるバッファを増量することで性能を向上させた」という説明があった。ちなみにWrite Combiningというのは,小さな単位のメモリアクセスをある程度溜めてからまとめて行うメモリバス処理を指す。
 |
「L2キャッシュの仕組みは完全な新設計になった」とMacri氏。
Bobcatアーキテクチャでは,L2キャッシュをCPUコアごとに容量512KBを持っていたのに対し,Jaguarアーキテクチャは(最大)4基のCPUコア全体で容量2MBのL2キャッシュを共有する設計に変更された。2MB÷(CPUコア×4)=512KBなので数字上は変更がないようにも見えるが,そうではないとMacri氏は言う。
Jaguarで,4基のCPUコアがL2キャッシュを共有する設計にしたのは,各CPUコアで実行されている“最も重いスレッド”の命令やデータがL2キャッシュ上に載りやすくさせるためというのだ。
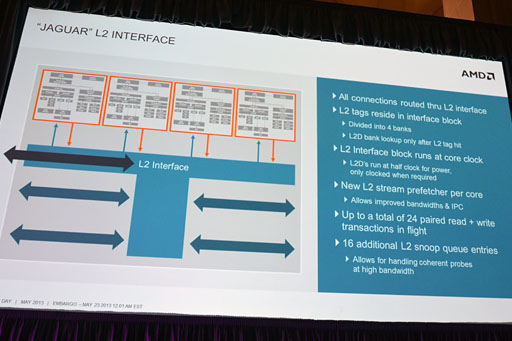 |
また,各CPUコアとL2キャッシュを結ぶL2キャッシュバスが,コアクロックスピードと同クロックで駆動されるようになった。各CPUコアからのメモリアクセスは,このL2キャッシュバスを経由し,CPUコアクロックのフル(最大)スピードでアドレスタグへのタグチェックへと向かう。
その後,タグヒットがあればキャッシュのストレージ部へ実アクセスが行われるが,キャッシュストレージ自体はコアクロックの半分で駆動されているという。これは,「すべてをフルスピードにしなかったのは,発熱量や消費電力,性能のバランスに配慮したため」(Macri氏)とのことである。
ただ,キャッシュストレージ部は4バンク構成になっており,それぞれのバンクに対して並列アクセスができるようになっている。
この「フルスピードで動作するタグチェックとハーフスピード動作の4バンク構成」により,各CPUコアが専用のL2キャッシュを持つBobcatアーキテクチャよりも,キャッシュメモリ利用効率がよくなり,ひいては電力効率が良くなるというのがAMDの主張だ。
 |
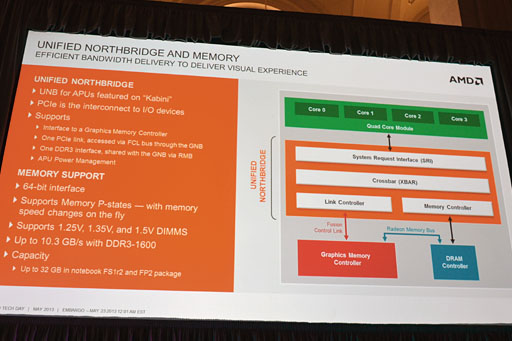
Macri氏は,統合されるノースブリッジおよびサウスブリッジ機能部分の解説も行った。
メモリコントローラ周りは(Bobcatアーキテクチャを採用する)「Zacate」もしくは「Ontario」コアと同じ。64bit幅のシングルチャネルDDR3システムになっている。もっとも,帯域幅は拡張され,10.3GB/sのメモリバス帯域幅を実現したDDR3-1600対応となった。DIMM電圧は標準的な1.5Vのほかに,DDR3Lの1.35V,DDR3Uの1.25Vをサポートし,最大容量は32GBだ。
メモリに対してもP-State(※付加状況に応じた駆動クロックと電圧の制御)がサポートされるのも特徴といえるだろう。
 |
I/O関連ではUSB 3.0が2ポート,USB 2.0が8ポートまでの対応となり,Serial ATA 6Gbpsも2ポート対応。ディスプレイ出力ではDisplayPortやHDMIに対応するほか,ディスプレイパネルへの直結インタフェースであるEmbedded DisplayPort(eDP)もサポートされる。なお,eDPは従来のLVDS方式に比べて配線量と消費電力を劇的に減らせるメリットがある。
PCI Express 2.0の汎用ポート(GPP)が4レーン提供され,システムデザインによってはここにMXM 3.0ベースのGPUモジュールを組み入れることも可能だ。
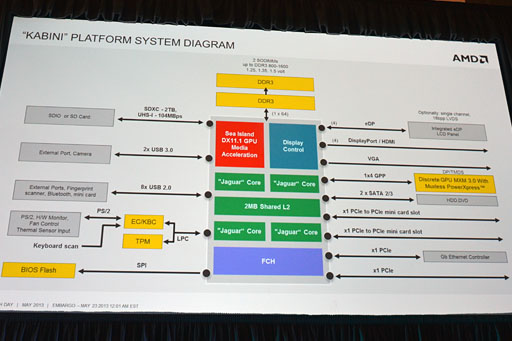 |
APUが持つ独特なバスシステムについての解説も行われたが,こちらも先代ZacateやOntarioからの大きな変更はないようだ。
「Onion」とも呼ばれる「Fusion Control Link」(以下,FCL)と,「Garlic」とも呼ばれる「Graphics Memory Bus」(旧称」Radeon Memory Bus)はTemashとKabiniにも引き続き実装されている。
FCLは,上り下り128bitのメモリバスで,GPUがCPU管轄下のメモリ空間にアクセスするときや,CPUがGPU管轄下のグラフィックスメモリにアクセスするときに利用されるバスだ。
APUにおいて,データの実体は単一のメインメモリ(=DDR3メモリ)に格納されるわけだが,「GPUがCPU管轄下のメモリにアクセスしようとした場合,CPU側キャッシュメモリ上の内容がまだメインメモリに反映されていない状況」というのは起こり得る。そうした不整合を回避しつつ(=キャッシュスヌープを行いつつ)問題のないメモリアクセスを実現するのがこのFCLになる。
Graphics Memory Busは,上り下り256bitのメモリバスで,CPU側キャッシュメモリにある内容との整合性を無視したアクセスが行われる。GPUからのアクセス速度を最優先にしたメモリバスシステムで,主にレンダリング結果の書き出しやテクスチャアクセス用途に使用されるバスだ。
 |
ついにAPUがGCNを採用。GPGPUポテンシャルはハイエンドGPUをしのぐ!?
 |
本稿の序盤で触れたように,TemashとKabiniコアのGPUコアは,APUとしては初めてGCNアーキテクチャベースのGPUコアを搭載する。
GCNアーキテクチャとは,Radeon HD 7900〜7700シリーズ(Southern Islands)のために開発されたAMDの新世代グラフィックスコアエンジンで,ベクトルデータを分解してスカラ演算器(的)に実行するものだ。
 |
 |
 |
ちなみに,NVIDIAはGeForce 8000シリーズの時点でGPGPU重視の方向性へ舵を切った関係で,一足早くコアアーキテクチャをスカラアーキテクチャに変更済みである。
さて,TemashおよびKabiniに搭載されるGPUがGCNアーキテクチャベースとなったことで,AMDのAPUは,DirectX 11.1世代のグラフィックス処理能力を持つこととなった。OpenGLでいえばOpenGL 4.3世代だ。
……といっても,APUに組み込まれるGPUコアなので,単体グラフィックスカードに搭載されるGCNベースGPUと比べると,演算実行部「GCN Compute Unit」の数はわずか2つと,規模は非常に小さなものとなっている。レンダーバックエンド(Rendering Output Pipeline,ROP)も1基のみだ。
GCNアーキテクチャでは,GCN CUあたり,16-wayのSIMDユニットを4基持つ。要するにシェーダプロセッサを64基(16×4)搭載しているので,TemashおよびKabiniのシェーダプロセッサ数は128基(64×2)ということになる。
冒頭で示したとおり,TemashおよびKabiniで,この「GCN Compute Unitを2基搭載」というスペックは動かない。そして,GPUコアの最大動作クロックはKabiniのA6-5200で600MHzだ。GCNベースのシェーダプロセッサは1クロックあたり1個の積和算処理が可能なので2 FLOPS。ゆえに,128(シェーダプロセッサ)×600MHz×2 FLOPSという計算式から,153.6 GFLOPSという総合演算性能が導き出せる。
専用GPUと比較すると仕様が限定的に見えるTemashおよびKabiniのGPUコアだが,専用GPUから劇的に強化されている部分もある。それが「Asynchronous Compute Engine」(以下,ACE)だ。
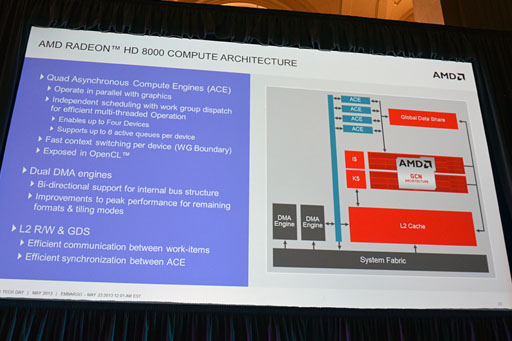 |
ACEとは,一言で言ってしまえば,「GPGPU用にGPUを活用するためのフロントエンド部分」。ACEは,「Radeon HD 7970 GHz Edition」のような単体GPUでも2基止まりなのに対し,TemashとKabiniでは倍の4基が搭載されているのである。
現在のWindows環境下におけるDirectXソフトウェア実行モデル(=ドライバのデザイン)では,専用GPUでも,TemashおよびKabini世代のAPUでも,グラフィックスレンダリングタスクとGPGPUタスクの混在(同時)実行は行えない。しかしハードウェア的にはそれが可能になっているのだ。「DirectXではなく,OpenCLの拡張仕様を用いることで,この『グラフィックスレンダリングとGPGPU処理の同時実行』は可能」ともMantor氏は説明している。
また,各ACEは最大で8個(TemashおよびKabiniの場合は合計32個)のGPGPUタスクをキューイング(=スケジューリング)できるという。
ここからは筆者の推測になるが,PlayStation 4のAPUは最大で64個のGPGPUタスクキューイングに対応しているので,逆算すれば,PlayStation 4のAPUに統合されるGPUコアのACEは,TemashやKabiniの2倍となる8基用意される計算になる。
 |
| Miracastのデモ。写真手前のノートPCからMiracast伝送された映像を,奥側のMiracast対応の液晶テレビが表示している。左がKabiniベースの試作機,右が競合他社製品。Kabiniベースの試作機は66ms程度の遅延なのに対し,競合他社製品では167msの遅延が出ている |
 |
| VCEやUVDの映像エンジンは固定機能の形で提供される |
ディスプレイ出力部は他画面出力に対応し,2画面出力時は最高で4K2K解像度をサポートするようになった。しかも,DisplayPortでだけでなく,HDMIでも4K2K出力が可能となっている(※ただし垂直リフレッシュレート30Hzまでという制限つき)。
ワイヤレスディスプレイ出力は,IEEE 802.11nベースのMiracast方式に対応。最近は日本でも,シャープの「AQUOS MX」をはじめとしたMiracast対応テレビ製品も登場しつつあるので,利便性が向上しそうだ。
固定機能ユニットとして,リアルタイムビデオデコーダ(Universal Video Decoder,UVD)とリアルタイムビデオエンコーダ(Video Codec Engine,VCE)を搭載するのは従来同様。UVDはH.264とVC-1,MPEG-2,DivXなどの幅広いコーデックに対応する。VCEのほうは,対応コーデックがH.264に限定されるものの,1080p解像度の映像を60Hz以上のスループットでエンコードする能力が与えられている。
ユニークな発熱&電力制御機能
 |
TemashおよびKabiniコアでは,CPUとGPUが隣接してレイアウトされているが,これはあえて行われたデザインなのだそうだ。
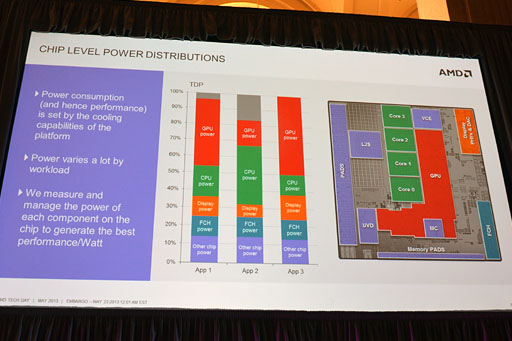 |
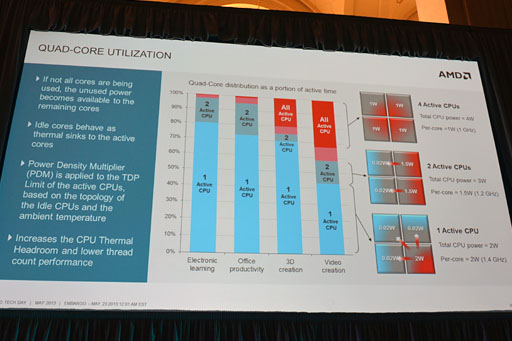
現在,PCシステムで実行されるアプリケーションは多様化しており,あるアプリケーションではCPUを酷使し,別のアプリケーションではGPUを酷使する。ゲームのように両方酷使するアプリケーションはまれであり,むしろどちらかを酷使するほうが多いとのことだ。となると,CPUあるいはGPUのどちらかが大きく発熱することになる。
そうした状況下において,TemashおよびKabiniでは,CPUとGPUが隣接レイアウトを採用していることを逆手に取り,負荷の高いプロセッサ側の熱を低負荷のプロセッサのほうへ移動させる形での熱分散をさせるようになっているとのことである。
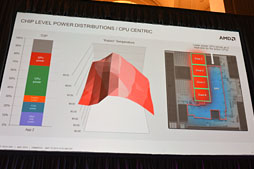 |
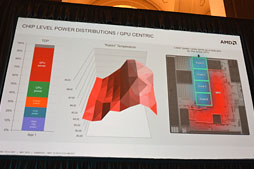 |
Naffziger氏いわく,これこそが「低負荷プロセッサ側をヒートシンクとして活用するアイデア」。そして,4コアJaguarベースのモデルにおいてはさらにアグレッシブな制御を行うとされた。単一のCPUコアだけが高負荷だった場合は,低負荷なCPUの動作クロックを下げて発熱量を下げてやり,高負荷CPU側の熱量を導くのだ。
さらに,低クロック駆動しているCPUコア側では熱容量的な余裕が生まれるので,低クロック化したCPU側の電力予算と熱容量予算を,高い負荷のかかっているCPUに分け与えてやる制御も同時に実行される。つまり,高負荷CPUをベースクロックよりも高いクロックで駆動する制御を行うのだ。
 |
 |
Turbo Dockでは,バッテリー駆動するタブレット型端末を,Turbo Dock技術に準拠する,強力な冷却システムを持つドックと接続してACアダプター駆動させたときに,CPUコアクロックを引き上げる。タブレット端末ということでピンときた人もいるだろうが,これはTemash向けの技術で,Kabini並みのTDPを許容することにより,性能を大幅に向上させるのだという。
 |
「新ジャンルのクライアントデバイス」に向けられるAMDのAPU戦略
 |
| Lisa Su氏(Senior Vice President and General Manager,AMD Business Units, AMD) |
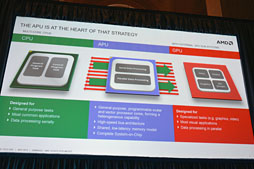 |
| CPUとGPUを統合させた新しいプロセッサのスタイル。それがAPUだとSu氏 |
逐次処理の高効率実行が追求されるシリアルタスク性能はCPUコアで,並列処理の高効率実行が求められるパラレルタスク実行はGPUコアで。異なる処理に向けて異なるプロセッサを用意し,それらを1つに集約したものがAPUであり,そのAPUはAMDにしか提供できないソリューションであるというメッセージを,SU氏は強く訴える。
続いてSu氏は「競合が発表したx64がもともと我々のAMD64だったように,競合は,今回も我々の後追いをしている」と述べ,IntelがCPUの統合型グラフィックス機能強化を図っていることを引き合いに出しつつ,AMDとIntelでは,ダイの中で占めるGPU機能ブロックの面積比率が異なる違う点を指摘した。
いわく,3月に発表された「Richland」コアのAMD A-Series APUだと,プロセッサ全体に対してGPUが42%の面積を占めるのに対して,Intelでは「Ivy Bridge」で27%,「Haswell」でも31%に留まるとのこと。各種メディア処理をはじめとしたビジュアルコンピューティング,データ並列コンピューティングといった用途には,今後ますますGPUが重要になっていくと予測されているだけに,「大きなGPU占有面積」は,その「心意気の現れ」ということなのだろう。
 |
そして,組み込み機器向けのSoCにAPUソリューションを引き続き展開していくという戦略もあらためて解説された。
2011年から提供が始まった組み込み市場向けAPUでは,2013年4月発表の「Embedded G-Series SOC」(以下,G-Series SOC)で,いち早くJaguarベースのCPUコアとGCNベースのGPUコアを搭載してきた。PlayStation 4に採用されるAPUは,このG-Series SOCに近いものとなるわけだが,実際Su氏も,この組み込み向けAPUの大型契約事例として,PlayStation 4を引き合いに出している。
 |
 |
 |
 |
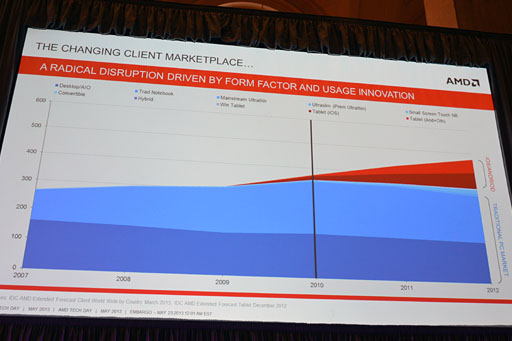
クライアントPCなどに代表されるクライアントデバイスの市場は元来,ハイスペックなデスクトップPCとさまざまな性能のノートPCとで半分ずつを分け合う形だった。しかし,2009年以降,iOSデバイスが急速に立ち上がり,2010年以降はそれ以上の速度でAndroidデバイスが台頭してきた。Lensing氏はそんな市場シェアの推移グラフを示しながら,「こういったタブレット製品の勢いは,伝統的なデスクトップPCとノートPCの市場を浸食しているように見える。しかしそうではなく,むしろ実際には新ジャンルの市場を誕生させている」と述べる。
 |
 |
 |
スイートスポット戦略を続けることにより,PC向けのプロセッサやSoC市場において,今後もAMDは高い存在感を持ち続けられるというのが,Lensing氏の見通しとなる。
 |
HSAの実現に向けた大きな一歩となるTemash&Kabini
Fusion計画として始まった,AMDによるCPUとGPUの統合計画は,今回のTemashおよびKabiniの登場によってCPUコアとGPUコアが両方とも最新世代のものへと変更されたことで,さらに1段階進化したといえる。
 |
「ひとまずの完成形」と見なされるのは,やはりHSA(Heterogeneous System Architecture)が実際に動き出してからということになるだろう。
HSAとは,CPUとGPUが統合的に双方のメモリ空間を利用できるソフトウェアアーキテクチャのことだ。前述のとおり,TemashやKabiniやそれ以前のAPUにもOnionやGarlicのバスシステムがあるため,実現できているようにも思えるが,まだ(ドライバ)ソフトウェアとハードウェア側の連携制御の仕組みが完成していない。
 |
このHSA×hUMAの仕組みは,2013年中に登場予定のKaveriで実現されることが明らかになっているので,「ひとまずの完成形」まで,あと一歩のところまで来たわけである。
 |
ちなみに,TemashとKabiniにおいても,ハードウェア的にはHSA×hUMA仕様が搭載済みであるという予測もされており,その場合,Kaveriが発表される2013年後半以降に有効化される可能性はあるだろう。
このあたりは,2013年11月に予定されている開発者向け会議「AMD Developer Summit 2013」にて明らかにされるものと思われる。
なお4Gamerでは,Kabini「A4-5000」搭載の評価機を入手し,さっそくベンチマークテストを実行している。新世代のエントリークラスノートPC向けAPUに「3Dゲームが動くこと」を期待できるのかが気になる人は,ぜひチェックしてほしい。
- 関連タイトル:
 AMD A-Series,AMD E-Series,Athlon,Sempron(Temash,Kabini)
AMD A-Series,AMD E-Series,Athlon,Sempron(Temash,Kabini) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー