














ニュース
AMD,次期主力APU「Kaveri」で対応する新技術「hUMA」を発表。CPUとGPUが同じメモリ空間を共有可能に
 |
発表に先立って,同社はアジア太平洋地域の報道関係者向け電話会議を開催したので,今回はその内容を基に,hUMAのポイントをまとめてみたい。
なお,電話会議でhUMAの解説を担当したのは,AMDのコーポレートフェローであるPhil Rogers(フィル・ロジャース)氏だ。
HSA,hUMAって何だろう?
〜次世代APU「Kaveri」のカギとなる技術
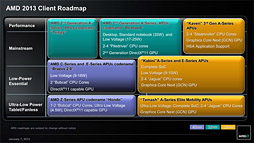 |
HSAというのは,AMDの次世代主力APU「Kaveri」(カヴェリ,開発コードネーム)で採用される予定になっているフレームワーク(=ソフトウェアのプログラミングを容易にするための仕組み)のことだ。
GPUを汎用演算に応用するGPUコンピューティングにおいて主流なのは,CPU側のコードとGPU側のコードを別々に書いて実行するという考え方だ。プログラム言語もCPUとGPUでは別々で,CPU側だとC/C++やJava,各種スクリプトなど,多種多様な言語が用いられるのに対し,GPU側では,NVIDIAが推進する「CUDA」や,業界団体Khronos Groupが策定している「OpenCL」,あるいはMicrosoftがDirectXに組み込んでいる「DirectCompute」がメジャーどころとなっている。
CUDAとOpenCL,DirectComputeはいずれもC/C++ベースではあるのだが,若干の拡張が入っており,CPU側で使われているC/C++とは少し異なる。その点についてRogers氏は「現在,プログラマーがGPUの性能を引き出すのは,かなり難しい。GPUの能力を使うにあたって,新しい言語や新しい技術を学ばなければならないからだ」と述べていた。
 |
| HSA陣営。ARMやImagination Technologies,Qualcomm,Mediatekなど,AMD以外はいずれもARMアーキテクチャと関わりの強い企業の名が並ぶ。「NVIDIAを除くARM陣営」と言っても通じてしまいそうだ |
 |
| AMDによるUMAの説明 |
AMDはHSAを広げるべく,HSA Foundationという団体を立ち上げ,HSAの業界標準化を目指している最中だったりもする。
そして,ここからが本題。HSA対応ハードウェア側のキーテクノロジーとして今回発表されたのが,本稿の主役でもあるhUMAだ。
Rogers氏は,「CPUとGPUが同じデータ,同じメモリ空間を相互に共有できることが重要になる」と,hUMA開発の意図を述べている。
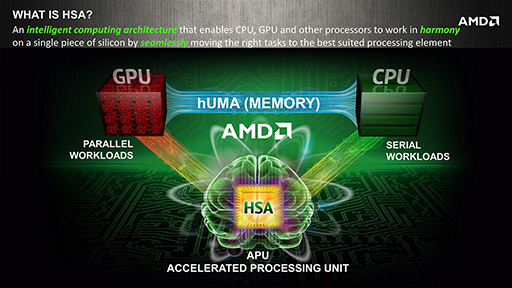 |
hUMAというのはAMDによる造語だが,その基になっている「UMA」は聞いたことがある人も多いだろう。複数のプロセッサが物理的に単一のメモリ空間を共有する場合は「Unified Memory Architecture」,複数のプロセッサが論理的に単一のメモリ空間を共有する場合は「Uniform Memory Access」というが,今回のhUMAは,後者のUniform Memory Accessに「heterogeneous」(ヘテロジニアス,異種間の)という単語をくっつけたものになる。
 |
あらためて述べるまでもないが,ここでいうheterogeneousとはCPUとGPUによる異種混合のこと。なので,hUMAはCPUとGPUがソフトウェア的にメモリ空間を共有するという意味である。AMDは以前から,「HSAをサポートするプロセッサでは,CPUとGPUがソフトウェア的にメモリ空間を共有する」と,ことあるごとに繰り返していたのだが,今回の発表は言ってしまえば,それにhUMAという名前がついたことのお披露目という理解でいいと思う。
ちなみに現行のAPUや,IntelのCoreプロセッサでは,GPUコアがCPUコアと単一のシリコン上に集積されていて,物理的には単一のメモリ空間を共有しているように見えるが,実際にはいくつかの理由で,両者はメモリ空間を共有していない。Rogers氏の言葉を借りるなら,現行のAPUやCoreプロセッサは,CPUコアとGPUコアとが論理的にそれぞれ異なるローカルメモリを持つアーキテクチャなので,hUMAではなく「NUMA」(Non-Uniform Memory Access)だ。
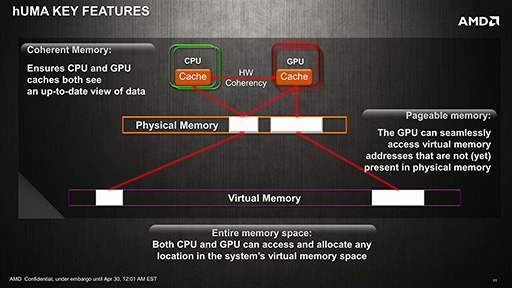
話を戻すと,HSAをサポートする次世代APUで実現されるhUMAでは,現行世代のAPUにある,いくつかの“NUMA的な”制限が取り除かれることになる。具体的には,
- CPUとGPUがアクセスするメモリ内のデータの一貫性が保たれるようになる
- GPUがページフォルトを扱えるようになる
- GPUがメモリ空間の全域にアクセスできるようになる
のである。
 |
1.の「CPUとGPUがアクセスするメモリ内のデータの一貫性が保たれるようになる」はそのものズバリで,CPUとGPUとの間でキャッシュの一貫性(coherency,コヒーレンシ)を保つ仕組みが組み込まれるという意味になる。
2.の「GPUがページフォルトを扱えるようになる」というのは少し説明が必要だろう。
今日(こんにち)のOSでは,デマンドページング(demand paging)という方法で,OSがアプリケーションのメモリ空間を管理している。アプリケーションは,「仮想メモリ空間」上で動作するようになっており,デマンドページングでは,必要に応じて,OSがページ(page)という単位で仮想メモリ空間を物理メモリアドレスに割り当てる。
そして,アプリケーションが「物理メモリページが割り当てられていない仮想メモリアドレス」にアクセスすると,ページフォルト(page fault)が発生する。ページフォルトが発生すると,OSはその情報を受け取って,空いている物理メモリページを,仮想メモリ空間の「ページフォルトが発生したアドレス」に割り当てるのだ。それによって,アプリケーションは処理を続行できるという仕組みである。
OSが物理メモリアドレスをページ単位で管理し,アプリケーションの仮想メモリ空間に,要求(デマンド)に応じて適宜割り当てることによって,アプリケーションは物理メモリ容量を気にする必要がなくなる。つまり,「PCそれぞれにメインメモリがどの程度搭載されていて,空き容量がどれくらい残っているか」という面倒なやりとりから解放されるのだ。また,OSが空いている物理メモリページを管理して割り当てることで,メモリの虫食い状態が起こらなくなるなど,多くの利点があり,結果,デマンドページングは今日のOSを支える柱の機能になっている。
要するに,CPUとGPUとが協調して動作していくにあたっては,GPU側がページの割り当てられていないメモリアドレスにアクセスしたらページフォルトが発生する(ような)仕組みが必要なのだ。CPUとGPUとが同じ仮想メモリ空間で処理を行っていくうえで必須の仕組みに,hUMAは対応するのである。
最後に3.の「GPUがメモリ空間の全域にアクセスできるようになる」だが,これは1.と同じく,そのままの意味だ。1つだけ補足しておくと,ここでいう「メモリ空間」というのは仮想メモリ空間のこと。つまり,3.を実現するには,GPUとCPUのメモリマネージメントユニット(Memory Management Unit,MMU)の協調動作が必要ということになる。
 |
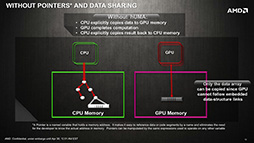
では,hUMAを導入することで,APUでは何が実現できるようになるのだろうか。Rogers氏が挙げていたのは,CPUとGPU間でデータのコピーが不要になる点だ。
「CPUでは連結リスト(linked list)のような複雑なデータ構造が使われるが,従来のシステムでは,GPU側からそれにアクセスできないため,GPU側からそのデータを使おうと思ったら,データをコピーするしかない。しかしhUMAのシステムなら,GPUが連結リストのポインタを共有し,複雑なデータをそのまま扱えるようになる」(Rogers氏)。
 |
 |
Kaveriに関する何らかの発表は11月か
いよいよ動き出すHSA,早い段階での成果に期待
Rogers氏はhUMAのメリットが「hUMAによってプログラマーは非常に容易にGPUのプログラミングが可能になり,PythonやJava,C++といった,ポピュラーなプログラミング言語が使える」点にあると強調していた。そして,冒頭でも紹介したように,それが可能になるのは,次世代主力APU,Kaveriからだ。
 |
 |
 |
ただし,電話会議の最後にRogers氏が「11月に開発者会議『AMD Developer Summit 2013』を開催する」と宣言したのは,注目に値しそうだ。「APU13」とも呼ばれるこのイベントでは,HSAが主要なテーマになるとのことなので,ここで,Kaveriに関する詳細な情報が明らかとなる可能性はある。正式発表されるかは何とも言えないが,2013年中のリリースが予定されるKaveriが動く状態で披露される,くらいのことは大いにあり得るだろう。
また,Kaveri以外でも,HSA Foundationから何らかのまとまった成果物が出てくるのではないかという期待も持てる。
ところで4Gamer的には,APUの採用が確定しているPlayStation 4(以下,PS4)で,HSAがサポートされるのかという点が気になるところだろう。今回はPS4についての言及はなかったものの,PS4ではGPUコンピューティングが目玉のひとつであることを考えると,同等の機能を持っていても不思議ではない。
とはいえ,ソニー・コンピュータエンタテインメント(以下,SCE)は,HSA Foundationのメンバーではあるものの,「Supporter」という,いわば末席に名を連ねているだけなので,HSAをサポートするかどうか,現時点では何とも言えない状況だ。11月のAPU13にSCEが登場するかどうかについても,注目しておくといいかもしれない。
- 関連タイトル:
 AMD A-Series(Kaveri)
AMD A-Series(Kaveri) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー