











連載
西川善司連載 / 2009年,本格始動するGPGPUの世界・後編〜GPGPUのプラットフォーム動向

前編では,「GPGPU」という概念が起こった経緯や,それがPCゲームにも無関係なものではなさそうだということが,何となく分かってもらえたと思う。
後編となる今回は,GPGPUを実現するプラットフォームの現状,そして動向を整理してみたい。

最初期のGPGPUでは,「GPGPUのための開発プラットフォーム」が用意されていなかった。そのため,GPUを3Dグラフィックス処理以外で使うに当たっても,DirectXなりOpenGLなりといった,標準的な3DグラフィックスAPIとその関連ライブラリを“普通に”利用し,グラフィックスを描画するプロセスを活用しなければならなかったのだ。
具体的には,
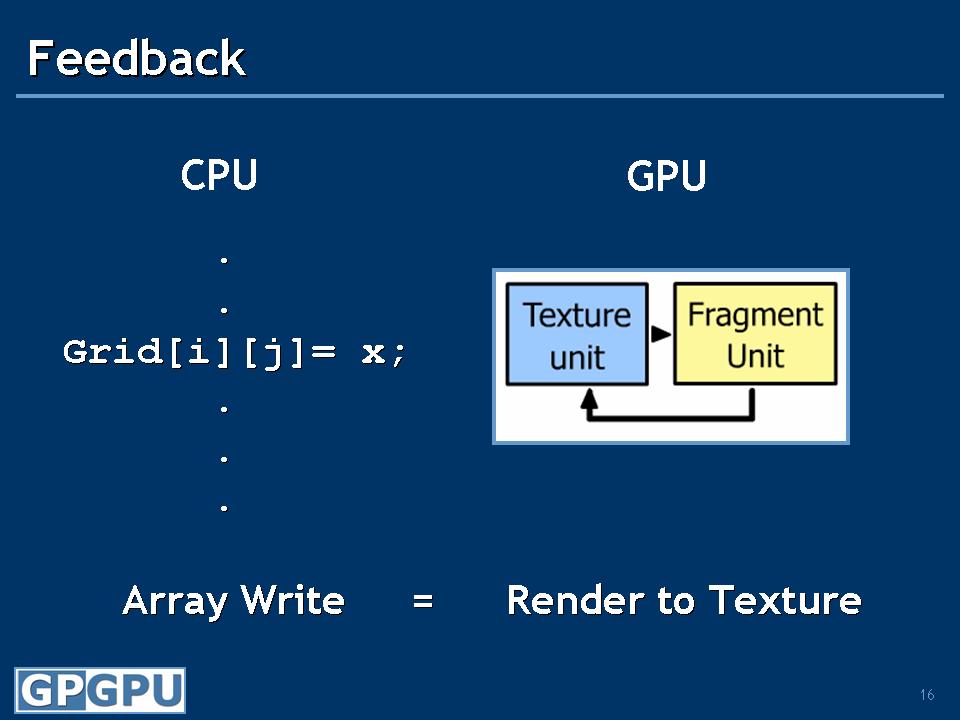
- 処理したい入力データをテクスチャに入れ込む
- シェーダプログラムで演算を実行する
- 演算結果をフレームバッファ(=レンダーターゲットへ出力する

最初期のGPGPUは汎用処理をグラフィックス処理と偽装してGPUに処理させる形態だった
といった流れで,言ってしまえば,「汎用計算を『3Dグラフィックス処理である』とだましてGPUに処理させる」イメージ。データをGPGPUで処理するための決まった手段がなかったので,GPUに,テクスチャとして扱わせたというわけである。
「GPUが取り扱うテクスチャ」というと,通常は画像がイメージされるが,これを“データ形態”として捉えた場合には,格子(Grid)状に展開されたデータ列と見なすことができる。つまり,行列代数の計算や画像分析処理,または波動力学や流体力学のような,2次元のグリッドデータ形式で処理しやすい物理シミュレーションなどが適していることになる。音声データのような1次元的なデータストリームも,2次元的なグリッドデータとして格納してやることで,GPGPU向きの処理系にすることは可能だった。

OpenGLで入力テクスチャと出力バッファの解像度を一致させる“おまじない”の一例
なお,言うまでもないことだが,当時のGPUは3Dグラフィックス描画に特化したアーキテクチャが採用されていた。これは取りも直さず,3Dグラフィックスにおいて,視点位置や視線方向,描画するオブジェクトとの相対的な位置関係でテクスチャが拡大縮小されることを意味するが,画像データではなく数値データとしてテクスチャに格納された“GPGPU用データ”にとって,このような拡大縮小処理の介入は邪魔以外のなにものでもない。よって最初期のGPGPUでは,入力データ(テクスチャ)と出力データ(フレームバッファ)の対応が1対1の関係になるよう設定して,拡大縮小処理が入ってこないようにするための,“おまじない”的な定番コードが必要とされていた。

CPUとGPUの違い
ただ,この「GPUに偽装3Dグラフィックス処理をさせてGPGPUをさせる手法」には欠点というか,限界があった。
その理由は大きく分けて二つある。一つは,CPUと違って,GPUには明らかにされない部分が多く,どのようにプログラムすると最大のパフォーマンスが得られるのかが分かりにくかったという点だ。一例を挙げると,NVIDIAの「GeForce FX」では,ブロックダイアグラムすら公開されず,使えるはずの機能が使えなかったり,さらには理論性能とほど遠い性能しか出なかったりしたことで,開発者達の頭を相当悩ませた。ソフトウェア制作において最適化というのは重要なテーマなのだが,ブラックボックスが当たり前のGPUではこれが難しかったのだ。

CPUプログラムとGPUプログラムの違い
データ間の相互依存性に配慮した処理は,最初期のGPGPUだと難しかった
もう一つは,GPGPUソフトウェアの設計&実装の手法が,CPUのそれと,かなり異なったものだったという点である。
大量なデータに対して処理を行うことを考えてみよう。CPUの場合,プログラムカーネルをFORループで括ってデータインデックスを動かし,処理対象のデータを一つ一つ切り換えるように実行させる。
これに対して最初期のGPGPUでは,シェーダユニットにプログラムカーネルを置いて,ここにデータを与えてやると,そのデータサイズに合わせて,自動的にプログラムカーネルへデータ入力が実行されるようになっていたのだ。GPUというその“生まれ”ゆえの特性から,プログラムカーネルは入力データを書き換えられず,処理結果は入力データとは別の領域に格納され,なおかつプログラムカーネルは,直前の処理結果であっても,「今取り扱っているデータ」以外の参照を行えない。そのためGPGPUでは,一つ一つのデータ処理を行うに当たって,ほかのデータとの依存関係に配慮した特別な処理を,CPU用ソフトウェアと同じように盛り込むのが難しかった(※マルチパスで実装すれば,不可能ではない)。
これらのことから最初期のGPGPUでは,「特定のGPUに向けて最適化したGPGPUソフトウェアは,別の世代のGPUや,別のメーカー製GPUで動作させるのが難しい」「CPU用のソフトウェアを,GPGPUへ単純に移植することはできない」という,二つの問題と向き合う必要があったのだった。
プログラマビリティが向上して高性能化したGPUで汎用プログラムが動かせる可能性は芽生えたものの,それを行うには,使う側に並ならぬ工夫と努力が求められていた,というわけである。

そんなGPGPU環境を改善すべく,まず取り組まれたのが,GPGPU向けの新言語開発だった。要するに,アルゴリズム(※問題を解決するための手順や手法。ここでは「GPGPU処理」とほぼ同義)をグラフィックスプログラムに偽装するテクニックが面倒だったから,ここをなんとかしようという動きが出てきたのだ。

Shの概要。後にRapidmindへと進化する
初期のGPGPU言語としては「Sh」「Scout」「BrookGPU」といったものが挙げられる。
Sh(シー)はウォータールー大学によって開発されたGPGPU言語で,C言語をオブジェクト指向プログラミング言語へと改良した「C++」のライブラリの形で形成されているのが特徴だ。C++のモジュール性,型,コンストラクタが利用可能で,GPGPU用途だけでなく,シェーダプログラムの設計にも利用できる。
メモリ管理を自動的に行う支援システムもあり,テクスチャやフレームバッファといった概念を意識せずにGPGPUプログラミングが行えた。
なお,Shの開発チームはその後,Shを「RapidMind」として商用化し,現在に至る。最新版のRapidMindでは,GPUに留まらず,IntelやAMDのマルチコアCPU,Cellプロセッサへの対応を果たしている。


基本はC++だが,「C++に対してSh拡張された命令」として「Sh」で始まる命令群があるSh(左)。このサンプルコードは,右に示したようなパーティクルアニメーションを実行するためのものだ
RapidMindで開発された,1万6000羽からなる鶏の群衆シミュレーション
![]()
続いてScoutは,並列コンピュータメーカーのThinking Machines(※当時。1999年,Oracleに買収された)が,並列コンピュータプログラミング用に開発した言語「C*」(シーアスター,“データ並列計算用のC言語”ということで,“+”よりも一段上のイメージとなる“*”がつけられたのだと思われる)をベースとするもの。Los Alamos National Laboratory(ロスアラモス研究所)のPatrick McCormick氏らが,データ解析とその可視化を目的として開発したGPGPU言語だ。
どういう計算を行うかを「with」で指定する命令形態が特徴的で,2005年10月にはオープンソース化された。


C*をベースとするScout(左)。右はそのサンプルコードと実行画面だ。ストリームデータを解析して可視化するのに適したGPGPU言語として登場した

BrookGPUのサンプルコード。FORループでカーネルを駆動する必要のない,ストリームプロセッサらしいプログラミングモデルを採用する。ストリームデータ間の依存関係を持つことはできない
最後にBrookだが,スタンフォード大学で開発されたこれも,やはりC言語をベースに,ストリームデータを取り扱えるように拡張を施したような言語だ。
ストリームとは,大量のデータを1か所に溜め込んでから処理するのではなく,端から流しながら処理する方式を指す。データを流れ(ストリーム)として捉えて入出力を行うことは多くのプログラミング言語で行われているのだが,流れてくるデータを逐次,演算処理できるようにしたのがストリーム処理言語である。
Brookにおいて,ストリームデータは「<>」で定義することができ,ストリームデータの大きさ(=長さ)が異なる物同士の計算のつじつま合わせも行ってくれる。また「BrookGPU」としてGPUへの移植が行われ,現状ではそちらが主流となっているため,あたかもGPUをストリーミングプロセッサのように扱えるようになるのが特徴だ。
なおBrookは,その後,当時のATI Technologiesによって仕様拡張が行われて「Brook+」となり,現在に至るまで,AMD製GPU向けGPGPUプログラミング言語の標準的な位置付けとなった。

学術分野の研究者達の手によって,小規模ながらも様々な実践的なBrookベースのソフトウェアが登場した。左は「ストリームデータの大きさが違っても自動的に補間される」仕組み。通常のC言語だと,forの二重ループを掛けて,さらにインデックス変数の帳尻を合わせるようにプログラムしなければならないが,Brookでは,この工程自体が不要で,自動的に行われる
……ここに来て少し難しい話になったが,ポイントは,いずれもC言語をベースにしているという点である。
GPGPUという概念自体が新しいものということを踏まえて普通に考えれば,GPGPUに適した言語を設計すべきだろう。しかし,まったく新しいプログラミング言語は,文法を理解するのが大変で,可読性や頒布性も低くなる。そこで,初期のGPGPU言語は,最も普及していたプログラミング言語である,C言語をベースにした。C言語の“上”に,ベクトルデータやストリームデータを簡単に取り扱えるような,拡張概念を導入したわけだ。
より具体的に言い換えるなら,「CPU向けのC言語だと,一つの命令で取り扱える入力データと出力データは1個ずつが基本。これに対して初期のGPGPUプログラミング言語では,データを塊(かたまり)とし,まとめて入出力できるように拡張された」ことになる。
これら初期のGPGPUプログラミング言語達は,GPGPU環境を大きく改善はした。ただ,制作されたGPGPUソフトウェアは動作対象GPUの仕様に強く依存してしまっていたため,開発した環境と同等のシステムでしか動作しないようなケースが多く,GPGPUソフトウェアを多くのユーザーで共有するのが難しかった。
“次なるGPGPU時代”に求められたのは,標準的なプラットフォームの登場なのであった。


2006年,NVIDIAは自社ハードウェアでの動作を保証するGPGPUプラットフォーム「CUDA」を発表した
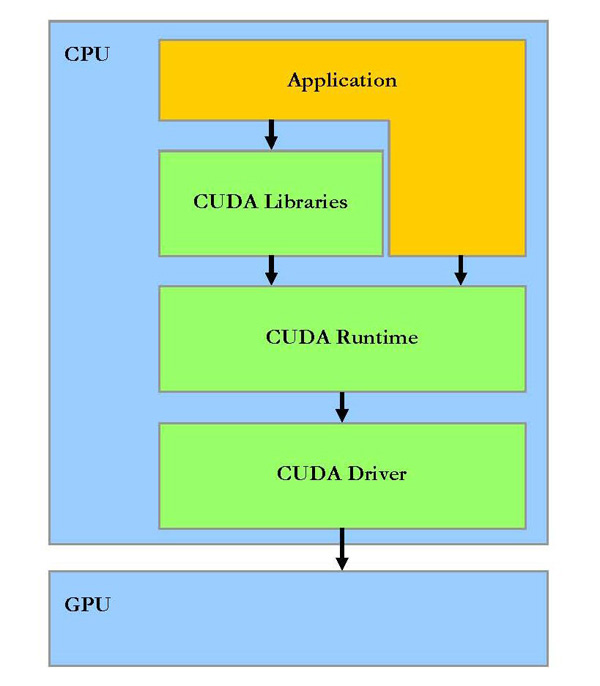
CUDAの実装概念図。アプリケーションはランタイムの中間コード化され,最終的なGPUネイティブなCUDAソフトウェアの実行マネージメントはドライバが行う
こうした業界の要望にいち早く呼応したのは,GPUメーカー巨頭の1社,NVIDIAである。
2006年11月,「GeForce 8800 GTX」の発表に合わせる形で,NVIDIAは,GeForce 8以降の同社製GPUでシームレスかつスケーラブルな動作/実行を保証するGPGPUプラットフォーム「CUDA」(Compute Unified Device Architecture)を正式発表したのだ。
CUDAを一言でまとめるなら,「NVIDIA製GPUを汎用ベクトルプロセッサとして活用するための,ハードウェアとソフトウェアによるトータル,かつロイヤリティフリーな環境」といったところ。ここでいう「ハードウェア」にはGeForce 8世代以降のGeForceと,ワークステーション用GPUであるQuadro,GPGPU専用プロセッサであるTeslaが含まれる。次に「ソフトウェア」だが,これはプログラミング言語「CUDA C compiler」(CUDA Cコンパイラ)を中核とした開発環境と,
GeForce/Quadro/TeslaをCUDAプロセッサとして利用するためのドライバソフトを指す。
CUDA C compilerはその名のとおり,C言語をベースとしつつ,ベクトル型の編集を扱えるように,“変数の型”が拡張されている。先ほど紹介した三つのGPGPUプログラミング言語と同様に,頂点やピクセルの都合,テクスチャの参照様式といった3Dグラフィックス的な概念から解放されているため,“おまじない”コードは不要。ごくごく普通に変数や配列を宣言し,C言語でプログラミングが行えるようになっている。

GeForce 8シリーズ以降において,シェーダユニット「Streaming Processor」(SP)は8基1グループとしてまとめられる。さらに,8SPで共有される16kBの「Local Memory」(LM,共有メモリ)と「Instruction Unit」(IU,命令デコードユニット)と組み合わせた構成は,「Streaming Multi-Processor」(SM)として,処理系の一単位とされている
また,これらは「ロイヤリティフリー」なので,開発者は,開発したCUDAベースのGPGPUソフトウェア(以下,CUDAソフトウェア)を,自由に扱うことができる。利用料がかからないということで,NVIDIAの競合他社――AMDやIntel――が自分達のハードウェアでCUDAソフトウェアを実行させる仕組みを構築すること自体にNVIDIAは干渉しない。しかしオープンソースではないため,実質的にはほぼNVIDIA製ハードウェア用ということになる。
というわけで,事実上の“NVIDIA製ハードウェア縛り”は存在するわけだが,開発者からすると,ターゲットとなるハードウェア(=GPU)の仕様を理解していなくてもいいというのは,CUDAが持つ最大のメリットとなる。しかも,CUDAソフトウェアのパフォーマンスは,GPUの世代やモデルに応じてスケーラブルとなるため,開発者もプログラム側も,「動作対象となるGPUがGeForce 8800 GTXなのか,『GeForce GTX 295』なのか,はたまた『GeForce 9100M G』グラフィックス機能統合型チップセットなのか」といったことを気にする必要がない。
●CUDAの尖兵となるNVIDIA PhysX
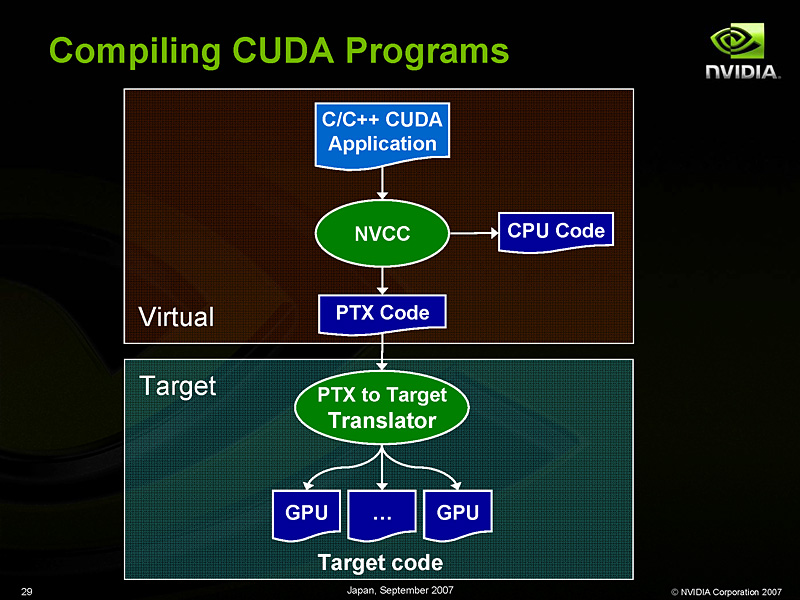
CUDAソフトウェアのコンパイルフロー。PTXはCUDAドライバ側のネイティブコードトランスレータにより,そこで初めてネイティブなGPU命令コードに変換されて実行される
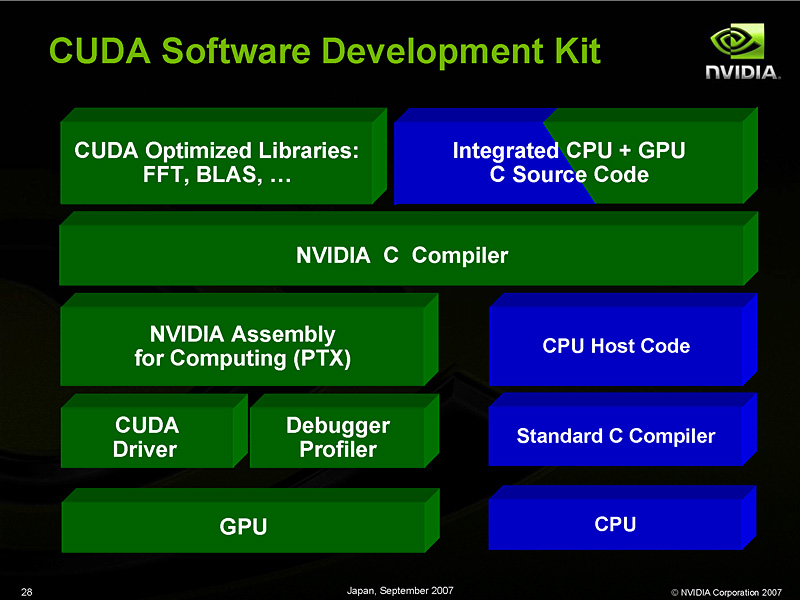
CUDAのソフトウェアスタック図
CUDAでは,標準ライブラリとして,線形代数ライブラリのBLAS,高速フーリエ変換(FFT)といったものが用意される。Cコンパイラで生成された実行オブジェクトは,CUDAドライバでマネージメントされつつ実行される仕様だ。
このとき,CコンパイラはネイティブなGPU命令コードを吐き出すのではなく,「PTX」と呼ばれる中間命令コードで出力される。そして,このPTXコードは,CUDAドライバを通じて,動作させるターゲットGPUの構成や世代に適したネイティブコードに変換されて実行されるようになっている。将来的に新しいGPUが登場したときには,CUDAドライバの更新によって,その「新しいGPU」に対応したPTX→ネイティブコードトランスレータ(Native Code Translator)が用意され,互換性が維持されるというわけ。
CUDAドライバとネイティブコードトランスレータは,「GPUコアが何基稼働していて、何基のStreaming Multi-ProcessorでGPUカーネルコードを実行できるのか」を吟味して動作する。これが,GPUの世代,あるいはGPUの同時稼働数が異なっても,CUDAプログラムの実行互換性が維持される仕組みの根幹技術である。
CUDA発表当時に公開されたデモ映像(煙の挙動を,CUDAにより実装した流体物理シミュレーションで制御している)
![]()
ところで,CUDAドライバはDirectX用やOpenGL用グラフィックスドライバとは別の,独立したドライバソフトウェアとなるが,グラフィックスドライバとは協調して動作できる。つまり,GeForceシリーズのGPUを1基のみ搭載したPCで,3DグラフィックスのレンダリングとCUDAソフトウェアの実行を同時に行えるということだ。もちろん,限られたSMを両者が奪い合うので,それぞれのパフォーマンスは削がれることになるが。
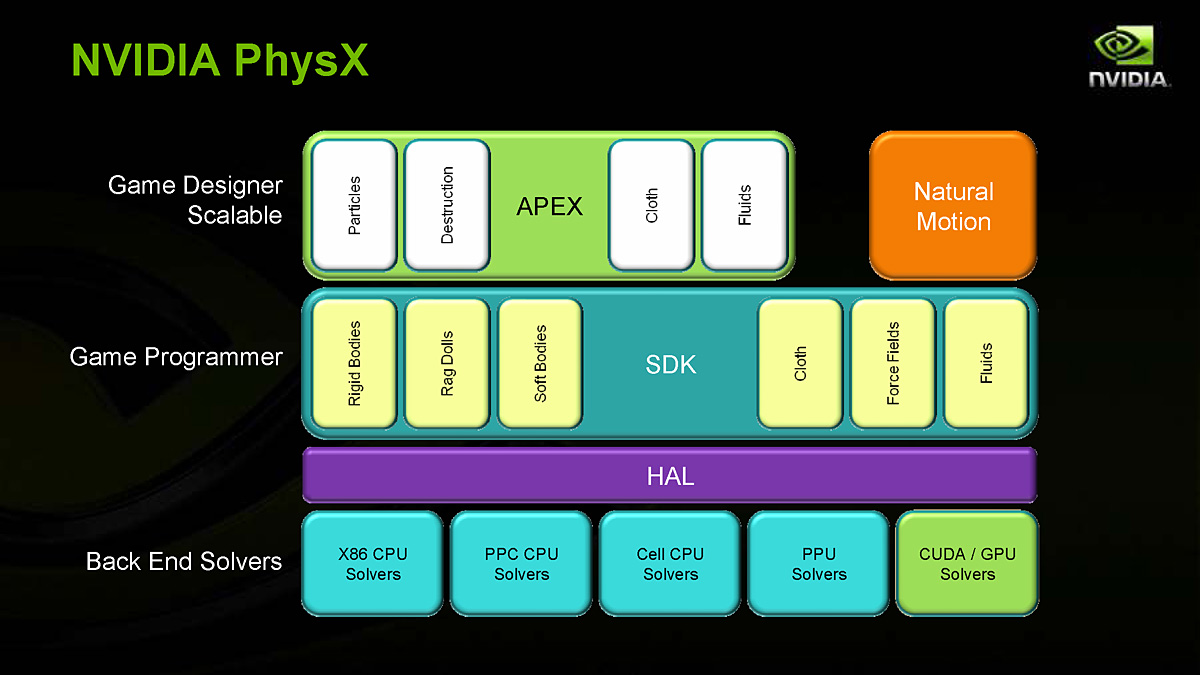
PhysXのソフトウェアスタック図。PhysX用CUDA Solver(CUDAソルバ,右下)の開発によって,PhysXはGeForceによるアクセラレーションが可能となった。ちなみに「APEX」は「Applied PhysX Extension」の略で,PhysX SDK内の物理プリミティブを組み合わせて,複雑な物理イベントをオーサリングしたりする仕組みのこと。NaturalMotionは,モーション生成ミドルウェアの「euphoria」をAPEXでも実装している
この同時実行の例としてPCゲーマーに最も身近な存在といえるのが,「NVIDIA PhysX」(旧称:AGEIA PhysX,以下PhysX)である。NVIDIAは,物理シミュレーションミドルウェア開発元のAGEIA Technologiesを2008年2月に買収。2008年のうちに,ゲーム業界で広く活用されてきた物理シミュレーションライブラリ(≒ミドルウェア)であるPhysXを,CUDAで実装することに成功している。
これにより,PhysXベースの物理シミュレーションをゲームに採用したとき,GeForceを利用したハードウェアアクセラレーションがしやすくなった。すでに,商用タイトルとして「Mirror's Edge」が登場しているのは,4Gamerでも2009年1月21日の記事,同22日の記事でお伝えしているので,ご存じの人も多いだろう。
また,Release 180世代のGeForce Driverでは,世代やモデルの異なる複数のGeForceを搭載した環境で,片方をPhysXアクセラレーション専用に割り当てる機能,「SLI PhysX」が正式に採用された。これにより,GeForce 8以降のGPUを搭載したグラフィックスカードで,使い古したものが手元にあれば,それをPhysX専用に割り当て,新しく購入したGeForce搭載グラフィックスカードは3Dグラフィックス処理に専任させるような使い方ができるようになっている。
NVIDIAにとってPhysXは,PCゲーマーにCUDAの有効性を認知させる尖兵的存在となっており,今後の展開が期待される。

対するもう一つの巨大GPUメーカー,AMDだが,少なくともCUDAが立ち上がったタイミングにおいては,(NVIDIAほどには)GPGPUへ積極的に対応していく姿勢を見せていなかった。どちらかというと,3Dグラフィックス用途に注力した製品展開を行っていたように見受けられる。
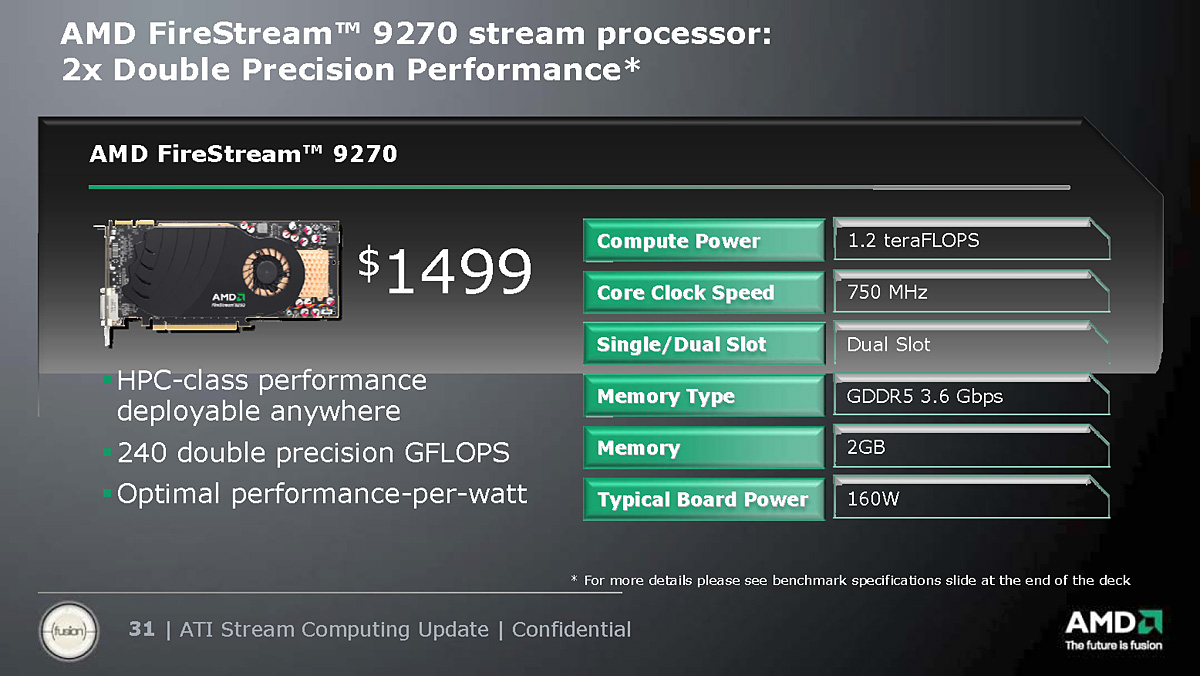
2009年2月時点におけるFireStreamシリーズの最新・最上位製品は2008年11月に発表された「FireStream 9270」。FireStream 9250との違いは,GDDR5メモリを採用した点にある
そんなAMDのGPGPU製品群にあって,最初に業界内外の注目を集めたのは,2007年11月に発売された「FireStream 9170」だった。これは「ATI Radeon HD 3800」(RV670)ベースの製品で,GPUベースのHPCプラットフォームとしては,世界で初めて倍精度64bit浮動小数点(FP64)演算に対応した製品である。続いて2008年6月には,「ATI Radeon HD 4800」(RV770)をベースとし,やはりFP64をサポートした「FireStream 9250」をリリースしている。
ベースとなるGPUを示したように,FireStreamは,同世代のATI Radeon製品と同じGPUコアを採用しているが,「ATI Stream」という,いわば“GPGPUモード”で動作し,ATI Radeon製品では無効なFP64演算機能が有効化されるなどのアドバンテージを持っていた。
CPUメーカーでもあるAMDとしては,GPUを「高性能な汎用プロセッサ」として使えるGPGPUソリューションを民生向けに積極転用することは,自社CPU製品の首を絞めかねない可能性を孕(はら)んでいると感じていたのかもしれない。だが結果として,「一般ユーザー向けGPGPU環境の整備」に,NVIDIAと比べてAMDが消極的だったのは事実だ。
ただ,この流れは2008年後半に一変する。PhysXに始まり,ビデオデータのトランスコードなど,GeForceを利用したGPGPUアクセラレーション技術が具体性を帯びてきたことで,危機感を感じた……のかどうかは分からないが,2008年12月,ついにAMDは民生向けGPGPUプラットフォームの提供へと舵を切った。それが,ATI Radeonにおける「ATI Stream」のサポートである。これにより,それまでFireStreamでしか利用できなかったGPGPUモードが,ATI Radeonからも利用できるようになった。
なお,現時点でATI Streamを利用できる一般ユーザー向けGPUは,ATI Radeon HD 4000シリーズの一部に限られるが,AMDは,いずれATI Radeon HD 3000シリーズもサポート対象に加えると予告している。
●CUDAとよく似た実装のATI Stream
ATI Streamの実装は,CUDAとよく似ている。
ハードウェアとしてのGPUを抽象化する層を挟み,上層に,高級言語のプログラミング言語やミドルウェアやライブラリを置く構造だ。物理シミュレーションに代表される,高度なリソースマネージメントとハイパフォーマンスが必要なライブラリやミドルウェアにおいては,AMD製GPUのネイティブコードであるCTM(Close To Metal)相当で実装されるが,一般的なGPGPUソフトウェア開発者は,高級言語を使って開発することになる。

ATI Streamでは,GPUハードウェアのネイティブな命令セットを抽象化するCAL(Compute Abstraction Layer)を持ち,ここがドライバ部分に含まれることになる
開発言語は,本稿の前半で触れたように,ほかのGPGPUプログラミング言語と同様,C言語をストリームデータ処理のために拡張し,新たな関数を追加したような仕様のBrook+が標準として提供される。Brook+ベースのGPGPUソフトウェアは,このBrook+コンパイラによって中間言語コードであるCALコードに変換され,ドライバに含まれるCALランタイムが,これをGPUネイティブコードに変換して実行する流れになっており,CUDAと本当によく似ている印象だ。
ATI Stream対応の一般ユーザー向けアプリケーションとして,ATI Avivo Video Encoderが無償提供されている
民生向けの一般アプリケーションへの対応はまだまだこれからということで,現状では,ドライバスイート「ATI Catalyst」に付属する形で配布されるフリーのトランスコードソフト「ATI Avivo Video Converter」を除くと,Cyberlink製ビデオ編集ソフトウェアスイート「PowerDirector 7」,ArcSoft製ソフトウェアメディアプレーヤー「TotalMedia Theatre」などがラインナップされているに留まり,“ATI Stream対応ゲームタイトル”の具体的なアナウンスは聞こえてきていない。
2008年夏の時点で,AMDは物理シミュレーションミドルウェアのメーカーで,Intel傘下のHavokと,AMD製CPUやGPUでで物理エンジンをアクセラレートするプロジェクトについて発表しているが,これもいつの間にか「具体的な内容は話せない。正式発表時期も未定」と,トーンダウンしてやや不透明になってきている。
ハードウェア的なポテンシャルという点で,ATI StreamがCUDAに大きく劣っている部分はない。それだけに,GPGPUソフトウェアを開発してくれるソフトウェアデベロッパを,AMDがどれだけ支援できるかが,ATI Streamのカギとなるだろう。
Havok FX(当時)のコンセプトムービー
かつて,Havok(=Havok Physics)をATI Radeonでアクセラレートする「Havok FX」のコンセプトが紹介されたが,日の目を見ることはなかった。今度こそ,ATI StreamベースでHavokの実装を期待したいところだが……
![]()

「GPGPUのような『斬新だが混沌とした概念』の標準化に当たっては,ハードウェアメーカーの事情と,ソフトウェア開発者の意見とをまとめてうまくバランスを取り,かつ強いリーダーシップを発揮できる勢力が統括すべきだ」という意見は,GPGPUが立ち上がった頃からあった。そして,「強いリーダーシップを発揮できる勢力」の筆頭に挙げられてきたのが,Microsoftである。
ただ,Microsoftにもさまざまな事情があったようで,GPGPUをプログラミング言語の観点から研究をして「Visual Studio」のような開発ソフトウェアに統合しようとする動きがあったかと思えば,長きに亘(わた)わたって熟成が進められてきたマルチメディアコンポーネント「DirectX」に統合させようとする動きもあったりして,優柔不断というか,フットワークが非常に重かったのだ。

Microsoftは,Direct3DをGPGPUに対応させるという選択をした
ちなみに前者は,「Microsoft Accelerator」というプロジェクトになった。これは.NET環境でC#を使ってGPGPUプログラミングを行えるようにしようとするものだったが,2007年夏を最後に,アップデートが途絶えている。
一方,2008年に,突如として具体的な話が浮上してきたのが,後者,DirectXに統合させる動きである。その名も「DirectX Compute Shader」。日本法人であるマイクロソフトの資料では,「DirectX演算シェーダ」とあるので,これが和名となるようだ。
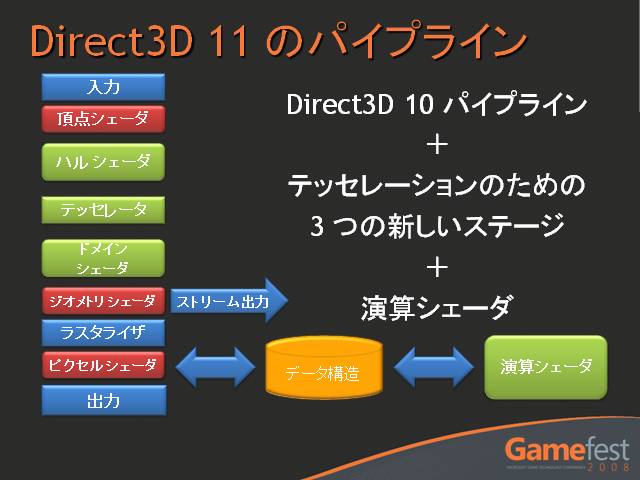

実装的な視点に立つと,「Direct3DにGPGPU関連APIの追加を行い,シェーダプログラミング言語(HLSL)をGPGPUに対応させた」のがDirectX Compute Shaderということになる
DirectX Compute Shaderは,3Dグラフィックスのレンダリングを司るDirect3Dに統合される形で実装され,Direct3D上のリソース(※テクスチャ,レンダーターゲットなど)はすべて透過的に取り扱える。つまり,3Dグラフィックスと関係の深い処理や,映像処理に特化したGPGPU処理を実装するのに,DirectX Compute Shaderは向いていることになる。
あくまで「Direct3DをGPGPUに対応させた」というスタイルなので,基本的な実行メカニズムは,
- GPGPU用プログラムをDirectX Compute Shaderプログラムとして実装し,
- これをGPUのシェーダユニットで走らせ,
- 処理させたいデータをDirect3Dに入力して結果を得る
といった流れ。それでも,SPMD(Single Program,Multiple Data)のプログラミングモデルの実装に向いているのは確かなので,例えば群集シミュレーションのAI,大局的な物理シミュレーション処理,3Dグラフィックスのポストプロセスなどには向いているはずだ。
総じて,ゲーム向けGPGPUとしては必要十分なポテンシャルがある印象。おそらく,ビデオのトランスコード処理アクセラレーションにも対応させることができるだろう。
“DirectX縛り”があるため,CUDAやATI Streamほどにはソフトウェア設計の自由度がなく,汎用性もやや限定される。しかしその代わり,Direct3Dのリソースを透過的に取り扱えるというメリットがある。ここが重要なポイントだ。
それは,この仕組みにより,Direct3Dでレンダリングした3Dグラフィックスの後処理をDirectX Compute Shaderで行ったり,あるいはDirectX Compute Shaderで行ったシミュレーション結果をDirect3Dのレンダリング素材として利用したりすることができるからである。もちろん,3Dグラフィックス処理とGPGPU処理の双方で取り扱うデータを共有しているので,面倒なバッファ間のデータ転送は不要。そのため,「3Dグラフィックスパイプラインで用いているアニメーション処理適用済みの3Dモデルを,DirectX Compute Shaderで実装している物理シミュレーションの衝突判定用に流用したりする」なんてことが可能となる。


DirectX Compute Shaderは,3Dグラフィックスレンダリングパイプラインの拡張目的にも使える
また,「3Dグラフィックス処理の新しいメカニズムの実装にも,DirectX Compute Shaderが活用できるのではないか」,という期待もなされている。
その筆頭事例に挙げられているのが,「A-Buffer」の実装だ。A-Bufferとは,映画向けCGなど,オフラインレンダリングの世界ではすでに実用化されている技術で,半透明オブジェクトの描画に当たって順不同実行を容認する仕組みのこと。かねてからGPUへの実装が検討されていたが,専用ハードウェアロジックではなく,DirectX Compute Shaderの活用により,GPGPUソフトウェアの形で実装できるのではないかという,議論がなされてきている。
DirectX Compute Shaderを使えば,3Dグラフィックスとしてレンダリングした複数の映像フレームを,適応型の処理によって1フレームに合成するといったことも実現できるからだ。
DirectX Compute Shaderは,現状のリアルタイム3Dグラフィックスレンダリングパイプラインを拡張する意味合いの目的でも,期待されているのである。

WinHEC 2008で,DirectX Compute ShaderをDirectX 10世代のGPUで利用できるようにするとMicrosoftは発表した
DirectX 11は,2009年に登場する見込みであり,対応GPUも2009年中に出てくると予想されている。Windows 7だけでなく,Windows Vistaにも提供され,さらにDirectX 10世代のハードウェアでも,DirectX Compute Shaderを利用できる仕組み(=リファイン版DirectX 10)が提供される予定だ。つまり,2009年(の後半)以降,DirectX Compute Shaderは,多くのPCユーザーが利用できるようになる見込みなのである。
NVIDIA,AMD両GPUメーカーもDirectX Compute Shaderへの対応姿勢を見せているため,GeForceやATI Radeonといった区別なく,DirectX Compute ShaderベースのGPGPU動作はサポートされることになる。単一のGPGPUソフトウェアを,メーカー不問のGPU環境下で透過的に動作できるようになるのだ。ゲーム向けGPGPUソリューションは「NVIDIAかAMDか」の踏み絵を迫られていたが,DirectX Compute Shaderによって,ゲームデベロッパが一気に対応姿勢を見せてくることを期待できる。

DirectXはWindowsのマルチメディアコンポーネントAPIであり,動作する環境は,Windows,あるいはMicrosoftのプラットフォームに限定される。そのため,DirectX Compute Shaderが動作する環境も,Microsoftのプラットフォームのみとなる。
しかし,GPGPUという概念自体はもっと一般的なものである。そのため,特定のハードウェア/ソフトウェアメーカーの影響を受けず,かつ,移植性の高い規格の登場も望まれてきた。
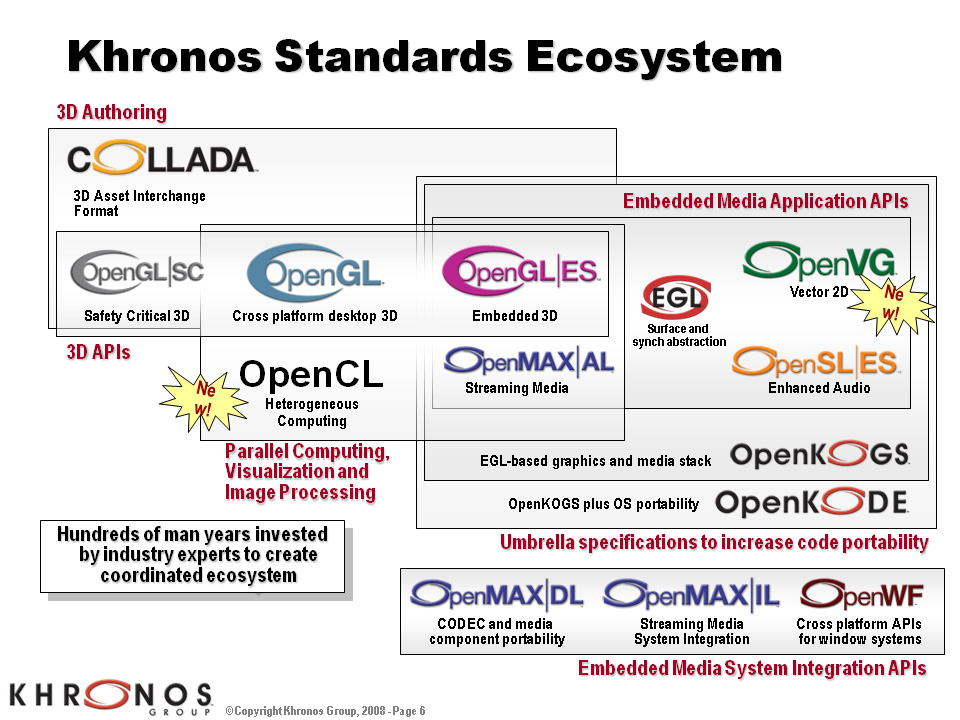
Khronos Groupが規格策定しているオープン仕様なAPI群(上)。オープン仕様&ロイヤリティフリーで,なおかつ特定の企業(の製品)の都合に制限されないGPGPUプラットフォームとして,新たに登場したのがOpenCLだ(下)
これを受けて,2008年夏,コンピュータ関連企業の業界団体にして,標準プログラミングAPI策定を行っているKhronos Groupによって発表されたのが,「OpenCL」(Open Computing Language)だ。
Khronos Groupは,オープン仕様な3DグラフィックスAPIである「OpenGL」の規格策定も行っている。そのため,OpenCLについて,「Direct3DにおけるDirectX Compute Shaderのようなもの?」というイメージを抱くかもしれないが,コンセプトや実現様式が微妙に違う。
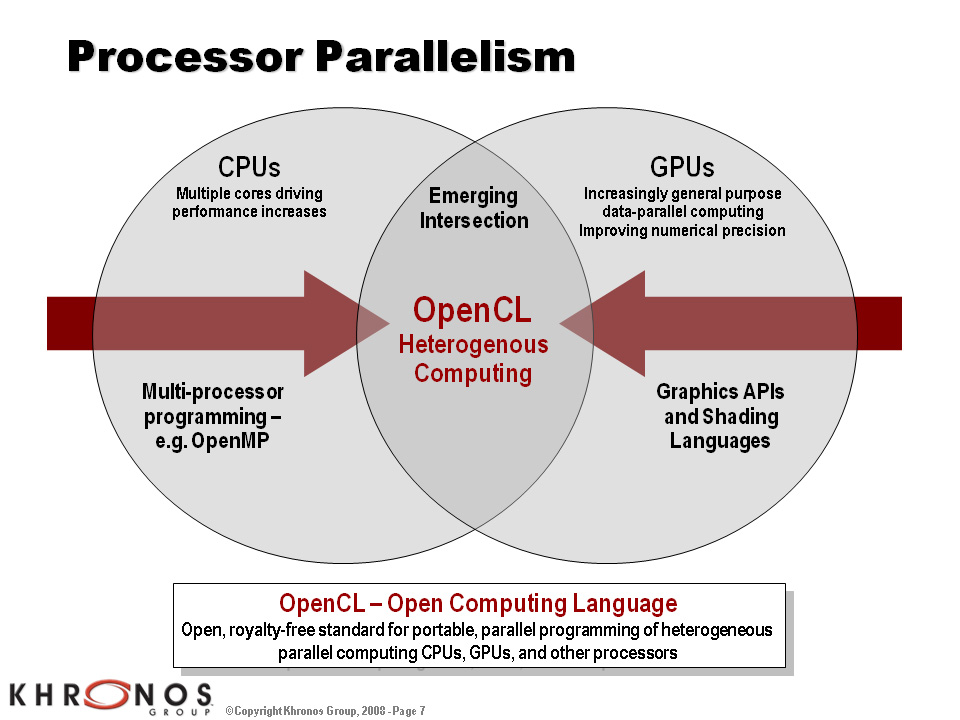
最大の違いは,OpenCLが,GPUだけを対象としているわけではないということだ。x86プロセッサやCellプロセッサといったCPU,あるいはDSP(Digital Signal Processor)のようなメディアプロセッサなどのプログラミングに対応するコンセプトを持っており,GPUに特化したDirectX Compute Shaderとは似て非なるものだといえる。

OpenCLのプログラミング言語もC言語がベース。ストリームデータやベクトルデータを扱えるよう,C言語に拡張を加えたものとなる
プログラミング言語はC言語ベースで,CUDAやBrook+のような,並列プログラミング向けの仕様拡張が成されている。まだ仕様が確定してない部分もあるが,2009年1月時点において,基本言語部分はISO C99(※ISO/IEC 9899:1999 - Programming Language C,C言語の基本仕様)のサブセットとなり,業務用や学術用途で使われることを想定して,IEEE 754(※浮動小数点数に関する表現と演算を規定した規格)準拠の,厳格な浮動小数点精度が規定される。
コンパイラが生成する命令コードは抽象化された中間コードになり,実行はGPU(≒ハードウェア)ごとに設計されたOpenCLドライバがネイティヴコードを吐き出して実行する仕組みだ。これはCUDAやATI Streamなどと同じだといえる。
OpenCLの拡張型C言語には,便利な関数等を収録したライブラリが提供されるが,物理シミュレーションや映像エンコーディングのような特定用途のための高機能関数やミドルウェア的なAPIは提供されない。あくまでOpenCLはGPGPU向けのプログラミング環境であるため,策定される規格は基本的でローレベルなものに留まるようだ。

プラットフォームAPIとランタイムAPIを効果的に利用すれば,CPUとGPU,DSPが混在する環境において,最大のパフォーマンスを発揮できるのが,OpenCLの特徴
前述したように,OpenCLは,GPUだけではなくCPUやDSPにも対応するため,プログラムの実行のさせ方も特徴的で,OpenCLの「Platform Layer API」にて,「どのOpenCLプログラムをどのプロセッサで実行させるか」を割り当てられるようになっている。
例えばマルチコアCPUとGPUを両方搭載するようなシステムでは,それぞれに異なるOpenCLプログラムを実行させたり,あるいはCPUとマルチコアGPUに同一プログラムを実行させて並列度を上げ,さらなるパフォーマンス向上を狙ったりといったことも可能だ。
さらにOpenCLでは「Runtime API」で,各OpenCLプログラムの実行制御や処理結果の制御も行える。OpenCLは,それ自体がGPGPUコンポーネントAPIになっているという感じで,DirectX Compute Shaderというよりは,構成自体がCUDAやATI Streamに近い印象である。
ただし,DirectX Compute Shader的な部分もある。それは,OpenCLが,3DグラフィックスAPIのOpenGLと同時に,協調動作できる点だ。

OpenCLとOpenGLとの同時協調動作のサポート
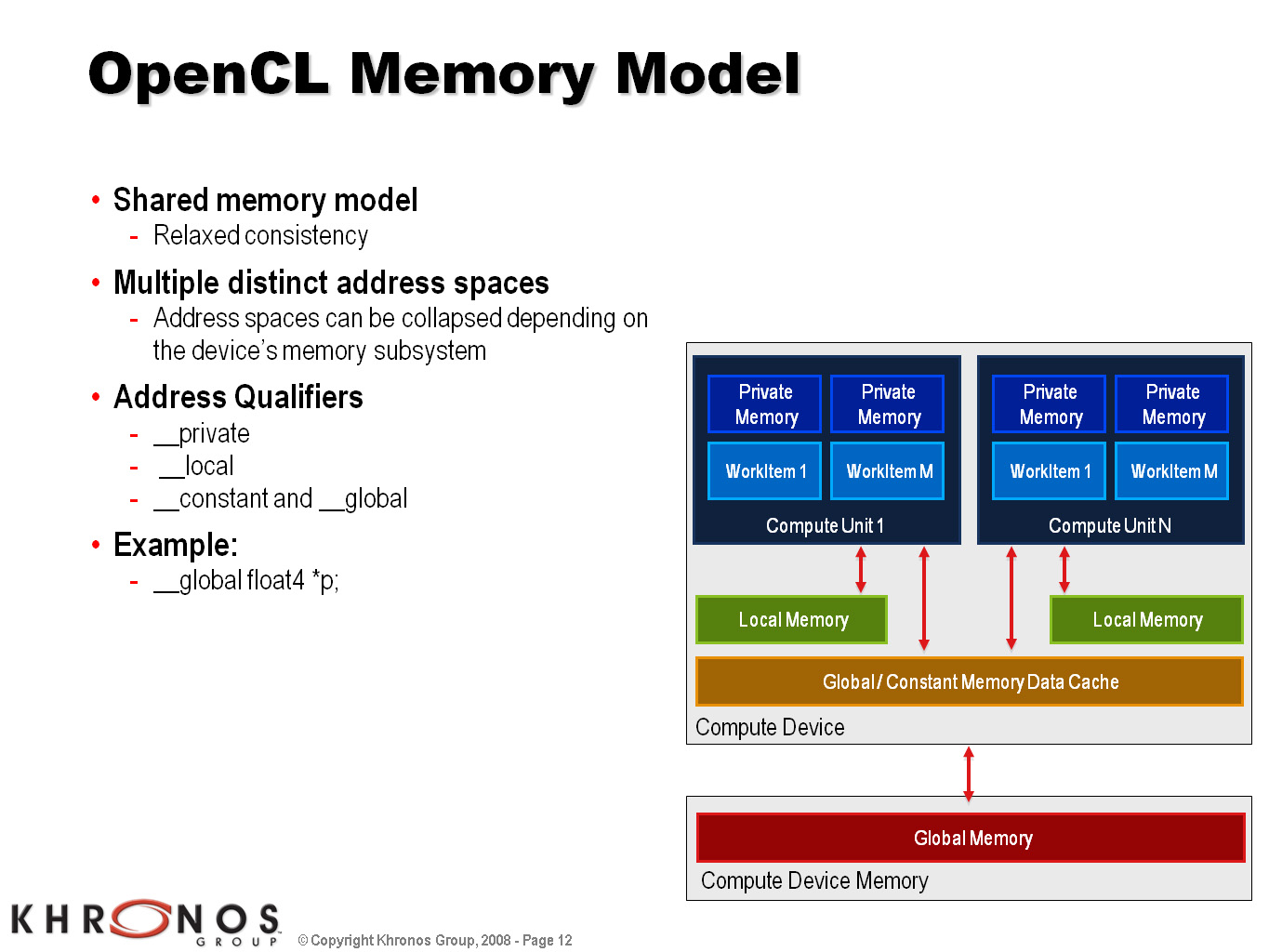
OpenCLのメモリモデル。各演算ユニットはプライベートなローカルメモリ領域を持ち,基本的にはここで処理をこなし,ほかの演算ユニットとの共有メモリを介して同調を取る。まるで,GPUやLarrabeeのブロックダイアグラムを見ているようだ
DirectX Compute ShaderはDirect3Dに統合されているのに対して,OpenCLはその実装上,OpenGLから独立している。しかし,OpenGLとOpenCLを結ぶInter-API(内通API)が実装されており,OpenGLとOpenCLはお互いにリソースを共有できる設計となっているのだ。
具体的にはテクスチャ,レンダーターゲットの各種バッファなどを共有でき,OpenGLからOpenCL向けの各種オブジェクトの生成も行える。よって,「OpenCLで実行したシミュレーション結果」の頂点データやテクスチャデータを,OpenGLにて3Dグラフィックス描画に利用したり,あるいはOpenGLの描画結果をOpenCLでポストプロセス処理したりできるわけである。統合されていないOpenGLとOpenCLが,あたかも統合されているかのように,両者を統括的に扱えるという点では,DirectX Compute Shaderとよく似ている。
もともとOpenCLはApple主導で提唱が行われた経緯があるのだが,AppleとしてはこのOpenCLを,2009年内にリリース予定となっている次期Mac OS,「Mac OS X Snow Leopard」に実装させたい思惑がある。実のところ,OpenCLはその提唱がなされたばかりであり,仕様の確定は2009年中頃とスケジュールされているのだが,Mac OS X Snow Leopardの登場は2009年6月と噂されているので,OpenCLの仕様確定も,このあたりになるのではないだろうか。

OpenCL規格の策定に参加している企業の一覧。OpenCLの提唱は最初Appleによって行われた。ここには記載されていないが,ソニー・コンピュータエンタテインメント(SCE)も参加している

将来的に,組み込み機器向け「OpenGL/ES」,あるいはメディア処理のための基本演算ライブラリAPI「OpenMAX」との連携を図れるようにする計画があることも発表されている

他勢力に先行してGPGPUへの対応を進めてきただけのことはあって,現時点におけるアプリケーションの対応度という点では,NVIDIAのCUDAが一番だ。とくにPCゲーマー的な観点からすると,一世代前のGeForce搭載グラフィックスカードを,そのままPhysXアクセラレータとして継続利用できる魅力は大きい。今後,PhysX対応タイトルの数を順調に拡充できれば,一般ユーザー向けGPGPUプラットフォームとして,しばらくの間,競合を圧倒し続けるだろう。
対するAMDの,「ATI StreamによるATI Radeonサポート」は,CUDAに対するカウンターパンチの意味合いが強く,一般ユーザーに向けたアプリケーションのアピールがまだまだ弱い。少なくとも,PCゲーマーにATI Streamの優位性を訴えるには,ATI StreamベースのHavokアクセラレーション実装が不可欠と思われる。
やや妄想じみた話をすると,GeForceでPhysX,ATI RadeonでHavokのアクセラレーションができるようになれば,「GeForceとATI Radeonを1台のシステムに両方搭載し,ゲームタイトルごとに3Dグラフィックス描画と物理シミュレーションのアクセラレーションを切り替える」なんて話だって出てくるかもしれない。
ただ,本音を言えば,プロセッサメーカーによる“縛り”のないGPGPUプラットフォームこそが理想なのも確かだ。その点で,DirectX Compute ShaderやOpenCLの動向は,最重要視していかなければならない。
これらにはNVIDIAとAMDの両社とも対応を明言しているので,特定メーカーの動向に引きずられたくない多くのアプリケーションベンダーは,この二つの登場を待ちわびている状況だ。
OpenCLはMacintoshや組み込み機器での活用がメインとなる見込みなので,Windows環境下では,やはりDirectX Compute Shaderが本命ということになる。
DirectX Compute ShaderにもDirectXという“縛り”はある。CUDAやATI Streamといった,ピュアなGPGPUプラットフォームと比較すれば自由度は落ちるが,それでも,Windows環境標準というのは大きな強みで,強力な勢力となるはずだ。
したがって,長期的にはGeForceかATI Radeonかといった“踏み絵”なしに,GPGPUの恩恵を受けられる未来が見えているわけだが,一方でNVIDIAやAMDの立場からすると,自社のGPGPUプラットフォームをいかに訴求していくかが,競合に打ち勝つためのポイントになってくる。
GPGPUベースの物理シミュレーションなり,動画エンコードのパフォーマンスなりで,「DirectX Compute Shaderで実装するよりも,うちのGPGPUプラットフォームで実装するほうがパフォーマンスは高くなる」といったアピールは,いずれ必ず行われることになるだろう。
- 関連タイトル:
 CUDA
CUDA
- 関連タイトル:PhysX
- 関連タイトル:AMD Stream(旧称:ATI Stream)
- この記事のURL:
キーワード
- HARDWARE:CUDA
- HARDWARE
- GPU
- GeForce
- NVIDIA
- AMD
- Radeon
- HARDWARE:AMD Stream(旧称:ATI Stream)
- ライター:西川善司
- HARDWARE:PhysX
- 西川善司の3Dゲームエクスタシー
- 連載
Copyright(C)2008 NVIDIA Corporation
(C)2009 Advanced Micro Devices, Inc.