











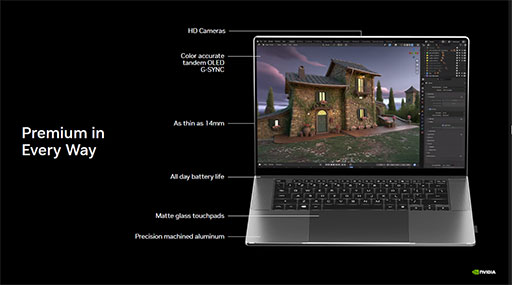
数ある発表のなかで,最も多くの関心が寄せられているのが,Windows PC向けSoC(System on a chip)である「NVIDIA RTX Spark」(以下,RTX Spark)だろう。
本稿では,ゲーマー向けにRTX Sparkの解説と技術的な考察を行う。
 |
RTX Sparkとは何か。DGX Sparkとの違いは?
 |
NVIDIAでSparkといえば,2025年に「パーソナルAIスーパーコンピュータ」という触れ込みで発表された「NVIDIA DGX Spark」(以下,DGX Spark)を連想する人も多いだろう。
DGX Sparkは,小さな弁当箱サイズのコンパクトな筐体を採用しており,AI向けに最適化されたPCである。
 |
RTX SparkとDGX Sparkの大きな違いは,用途とそれに関連するソフトウェアの取り扱いだ。 DGX Sparkは,AI向けPCであり,ソフトウェアの動作が保証されていたのは,AI関連のものがメインである。具体的には,NVIDIAのAIソフトウェア開発キット「TensorRT」を動かすことを目的としたハードウェアと言っていいだろう。
それに対してRTX Sparkでは,DGX Sparkと同じAI用途に加えて,コンテンツ制作やゲームといったGeForce向けの用途における性能を,とくに大きくアピールしている。
RTX Sparkは,Windows PCへの搭載を前提としており,NVIDIAはMicrosoftと密接に協力し,WindowsでエージェントAIを使うための取り組みも行う。この点でほかのArm版Windowsを搭載したPCとは立ち位置が異なる。
Qualcommの「Snapdragon」シリーズを搭載したWindows PC,とくに薄型ノートPCでは長時間のバッテリー駆動などを訴求しているが,PCの使い方は既存のPCとそれほど大きく変わらないと感じる人が多いだろう。
これに対して,RTX Spark搭載PCは,小型であることや長時間のバッテリー駆動というハードウェア面に加えて,AIと対話しながら仕事ができるPCであるというポイントを打ち出している。
 |
 |
たとえば,撮影した写真を編集する場合を考えよう。
従来のPCであれば,ユーザーがマウスやキーボード,タッチパッドを使って画像編集ソフトを操作する。
エージェントAIに最適化したPCでは,文字や音声でAIと対話すると,AIがソフトを操作して,画像を編集してくれるわけだ。
 |
これは画像編集に限った話ではない。
基調講演後に行われたブリーフィングで,「RTX Sparkに自分の代わりにゲームをプレイしてくれるエージェントAIを開発して走らせられるか」という,冗談のような質問をしてみた。
するとNVIDIAからは,「今のところ,そうしたAIエージェントは存在しないが,技術的には不可能ではない。できたら楽しそうだ。AIエージェントのプレイヤーが格闘ゲームで,人間の有名プレイヤーと対決する様子を私も見てみたいね」という,とてもマジメな答えが返ってきた。
もしかすると,RPGにおける経験値稼ぎや高難度のボス戦をAIにプレイしてもらうなんて使い方もありうる。それはそれで物議をかもしそうだが,新しいゲームとの付き合い方が生まれるかもしれない。
 |
RTX Sparkのチップは,DGX SparkのGB10と同じ?
ここからは,RTX Sparkのスペックを詳しく見ていこう。
実はRTX SparkとDGX Sparkに搭載するSoCである「GB10 Grace Blackwell Superchip」(以下,GB10)のスペックは,かなり共通している。
それぞれのスペックをまとめたのが,以下の表だ。
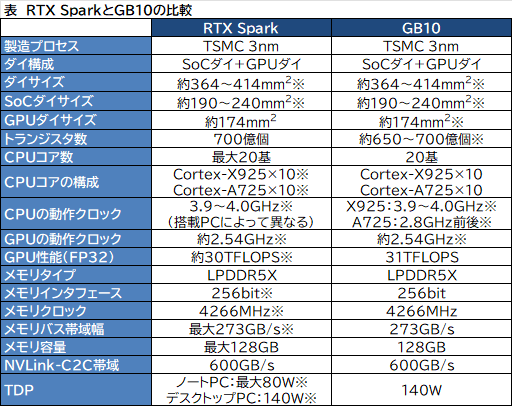 |
CPUのコア数は同じ最大20コア構成で,GB10の場合は,高性能コアのArm Cortex-X925と高効率コアのCortex-A725をそれぞれ10コアずつ備える。命令セットは「Armv9.2-A」に対応し,AI関連の拡張命令セットはBF16,I8MM,SVE,SVE2,FP16,DotProd,SIMD,FP16FML,SVE2BITPERMをサポートする。
GPUは,最大6144基のCUDAコアを持つ「Blackwell」アーキテクチャベースのGPUを統合する。NVIDIAによると,「4bit浮動小数点数」(FP4)での量子化において,最大1PFLOPもの演算性能を備えるという。
 |
CPUとGPUが共通してアクセスできるユニファイドメモリの容量は最大128GBで,LPDDR5X-8533に対応する。メモリバス帯域幅は273GB/sだ。
RTX Sparkの発表時に,メモリバス帯域幅が600GB/sという情報もあったが,おそらくこれは間違いだ。
確かに基調講演で,フアン氏が600GB/sというセリフを連呼していたが,メモリバス帯域幅が600GB/sとは言っていない。600GB/sとして強調されていたのは,CPUとGPUをつなぐインターコネクト技術「NVLINK-C2C」の帯域である。
プレゼンテーションで流れた映像でも,NVLINK-C2Cを紹介する部分に「600GB/s GPU to CPU」と記載されていた。
これについてはあとでもう少し詳しく解説したい。
 |
なお,RTX SparkのCPUコア数やCUDAコア数,ユニファイドメモリの容量には,いずれも「最大」との表記がされているので,さまざまなバリエーションがありそうだ。
たとえば,ユニファイドメモリをLPDDR5X-7500に,あるいはメモリバス幅を192bitに抑えたモデルもあるかもしれない。
RTX Sparkは,PC向けとしてかなり大きなチップに
ここからは,RTX SparkとGB10が同じチップだと仮定して,アーキテクチャについて考えたい。
RTX Spark(とGB10)は,CPUを含んだSoCダイとGPUを含んだGPUダイの端を接続して1チップとして構成している。NVIDIAは,このチップ間接続技術をNVLink-C2Cと呼ぶ。「C2C」はChip-to-Chipの略だ。
 |
フアン氏が600GB/sと強調していたのは,このNVLink-C2Cの帯域幅になる。ちなみに,この600GB/sという数値もNVLink-C2Cの上りと下りの帯域幅を合わせたものとして考えられる。
何故かというと,RTX Sparkのメモリバス帯域幅が273GB/sなので,上りと下りの同時データ伝送をちょうどカバーできるからだ。
RTX Sparkの製造プロセスは,TSMCの3nmプロセスとのこと。SoCダイとGPUダイの接続には,TSMCのパッケージング技術である「CoWoS-R」を利用していると思われる。
GB10については,2025年8月に行われた半導体関連学会「Hot Chips 2025」で紹介されている。ここではSoCダイがS-Die,GPUダイがG-Dieと呼ばれていた。
それぞれのダイサイズは明らかになっていないものの,GB10の実測値からS-Dieが約200mm2,G-Dieは約170mm2程度で,総面積が370mm2+α程度と推察されている。
「PlayStation 5 Pro」のSoCが約280mm2くらいなので,これと比べるとだいぶ大きい。
NVIDIAは明らかにしていないが,有志による分析によると,GB10の総トランジスタ数は650億〜700億とのこと。RTX Sparkの紹介動画では,トランジスタ数を「70billion」(700億)とはっきり言っているので,この推定は当たっているようだ。
 |
デスクトップPC向けGPU「GeForce RTX 4090」(4nm製造プロセス)のトランジスタ数が763億,Apple製SoC「Apple M2 Max」(5nm製造プロセス)が670億くらいなので,大体の規模感は分かるだろうか。
RTX Sparkにおける動作クロックは,搭載するノートPCや小型PCによって異なるという。ただ,RTX Sparkの演算性能が,FP4で最大1PFLOPSという公称値をヒントにGPUの動作クロックは逆算できそうだ。
NVIDIAは理論性能値をアピールするときに,数値が高く出やすい疎行列(Sparse)の性能を示すことがほとんどだ。そのため,ここではSparse FP4時の性能を最大1PFLOPSと仮定しよう。
Blackwell世代のGPUは,1つの「Streaming Multiprocessor」(以下,SM)あたり,128基のCUDAコアを備えている。RTX SparkのGPUにはCUDAコアが6144基あるので,SM数は次のようになる。
- 6144CUDAコア÷128CUDAコア=48SM
また,Blackwell世代のGPUは,1基のSMにおいて,クロック当たり8192 OPSの疎行列演算性能があるという。ここからGPUの動作クロックを計算したのが以下のとおり。
- 1,000,000,000,000,000÷(8192 OPS×48SM)≒2.54GHz
つまり,RTX SparkにおけるGPUの最大動作クロックは約2.54GHzということになる。
動作クロックをもとにして,GPUの32bit浮動小数点数(FP32)演算性能を求めると約30TFLOPSとなり,GB10の31TFLOPSにかなり近づいた。また,単体GPUと比べると「GeForce RTX 5070」の30.9TFLOPSに並ぶ性能となる。
だからといって,「RTX SparkのGPU性能は,GeForce RTX 5070に匹敵する」と決めつけるには早い。これについては,続く性能面の考察であらためて触れたい。
RTX SparkのAI処理性能は?
RTX Sparkは,エージェントAIに最適化されたSoCだ。
基調講演では,ローカル環境でエージェントを使用するときに,1200億(120B)パラメータの大規模言語モデル(Large Language Model,以下 LLM)を最大100万トークンのコンテキスト長(AIモデルが1回に処理できる情報量)で実行できるとの説明があった。
 |
DGX Sparkは,最大2000億(200B)パラメータのAIモデルによる推論処理や,最大700億(70B)パラメータのAIモデルに対するファインチューニング(再学習と調整)が可能だという。さらに2つのDGX Sparkを接続して,最大4050億(405B)パラメータのAIモデルにも対応するそうだ。
出てくる数値だけ見ると,差があるように感じる。ただ,これは性能差ではなく,用途が違うので性能の見せ方が異なると考えたほうがいい。
DGX Sparkの「最大2000億パラメータの推論」は,AI開発PCとして動作できる推論モデルの上限をアピールする。
これに対し,RTX Sparkの「最大1200億パラメータLLM」は,LLMというところがポイントで,最大100万トークンのコンテキスト長でモデルを動かせるという表現をしている。これはWindows PCでローカルエージェントを実行したときの上限を示しているのだ。
DGX Sparkで,200BパラメータのAIモデルが動かせるのに,RTX Sparkだと,120BパラメータのLLMが動かせる。パラメータ数の違いでRTX Sparkの方が劣るように見えてしまうが,そういうことではない。
LLM系AIモデルでは,過去の会話や入力テキストの処理結果である「Key」と「Value」を一時保存し,回答を生成するときの再計算を省略させるために使う「KV Cache」(Key-Value Cache)を設定する。
最大100万トークンのコンテキスト長を保持する場合,KV Cacheは数十GBに達する。その分メモリが使われてしまい,メインメモリ容量128GBのPCでLLMを動作させると,120Bパラメータ程度が上限になるというわけだ。
つまり,DGX Sparkは主にAI開発PCとしての性能,RTX SparkはAIを使用するPCとしての性能を示しているだけで,実質的な性能は変わらないと考えていいだろう。
RTX Sparkでゲームは動作するのか
ゲーマーにとって重要なのは,RTX Sparkを搭載したPCでどのくらいゲームがプレイできるかということだ。これに対して,NVIDIAは「既存のWindows向けゲームはRTX Sparkでも動作する」と明言した。
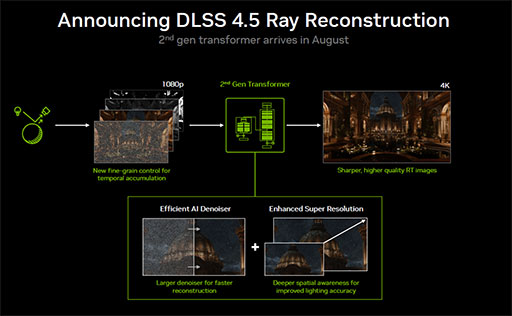
NVIDIAは,RTX Sparkに対して,以下の機能を完璧な互換性を持って提供するという。
- DLSS 4.5
- 6倍マルチフレーム生成
- NVIDIA Reflex
- RTXレイトレーシング機能全般
- レイ再構成技術(Ray Reconstruction)
 |
 |
 |
つまり,NVIDIA独自のゲーム支援技術のすべてがRTX Sparkで動作するのだ。これはRTX Sparkの登場に向けて,サポートを強化した結果と言えるだろう。
また,RTX SparkはArm系CPUを搭載しているので,x86やx64ベースにおける互換性を気にしている人も多いと思う。
これについては,x86やx64向けのアプリを変換してArm搭載Windows PCで動作させる「Prism」を利用することになる。ブリーフィングでもNVIDIAは,「Prism経由でほぼどんなゲームもRTX Spark上で動く見込み」と説明していた。
MicrosoftもRTX Spark向けにPrismの最適化を行っているそうだ。
つまり,GPU側はDirectX/DLSSをネイティブに動作可能で,CPU側はPrismでArm64へ動的変換するということになる。
x86/x64系CPUを搭載したPCと同じ条件で実行されるわけではないが,NVIDIA側は,RTX Sparkに対するゲームPCとしての可能性について,不自然なくらい自信を見せている。
 |
RTX Spark搭載PCが登場する2026年秋までに,なにか隠し球があるのかもしれない。「Nintendo Switch 2」の上級機として,RTX Sparkを搭載した「Switch 2 Pro」が登場したら,それはそれでセンセーショナルで面白いのだが,さすがにそれはないだろう(笑)。
では,ゲームにおける性能はどのくらいなのだろうか。基調講演では,DLSSを活用することで,解像度2560×1440ドットにおいて,大作ゲームを100fps以上のフレームレートでプレイできるとのアピールもあった。
 |
RTX SparkのGPUには,GeForce RTX 5070に並ぶ30TFLOPSの性能があるのだから,GeForce RTX 5070を搭載したPCと同等のゲーム体験が提供されるのかというとそんな単純な話ではない。
GeForce RTX 5070は,672GB/sのメモリバス帯域幅を持つ。メモリインタフェースは192bitだが,グラフィックスメモリに高帯域なGDDR7メモリを採用することで,RTX Sparkの273GB/sと比べて,2倍以上のメモリバス帯域幅を実現している。
とくにゲームにおいて,メモリバス帯域幅は大きな影響を及ぼす。
GPUは理論性能値がいくら高くても,メモリの性能が低いと十分な実力を発揮できない。メモリバス帯域幅の影響が表れやすい4K解像度のゲームプレイやパストレーシングを含むレイトレーシングで,性能が制限される。
ただ,単体GPUと比べるとメモリバス帯域幅は狭いかもしれないが,CPUで考えると話が変わる。
たとえば,一般的なPC向けメモリの場合,DDR5-5600をデュアルチャネルで構築した場合,メモリバス帯域幅はおよそ90GB/sだ。これと比べると,RTX Sparkは2倍以上のメモリバス帯域幅を持つことになる。
CPUプログラムは,命令をメインメモリから読み出して実行しているので,メモリバス幅が2倍になれば,プログラムをより高速に実行できる。
これによって,プレイヤーが操作してから,その結果が画面に表示されるまでのゲームループをより速く繰り返すことができるのだ。
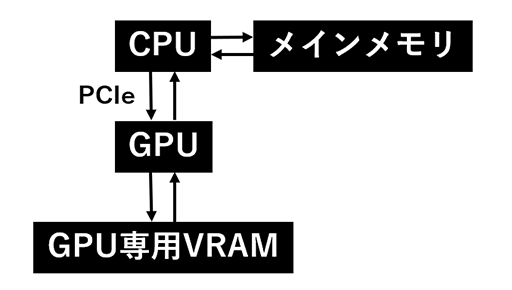
さらにもう1つ,RTX Sparkには,一般的なPCにはない恩恵がある。CPUとGPUが高速なインタフェースで接続され,ユニファイドメモリにアクセスできる点だ。
図で表すと以下のようになる。
 |
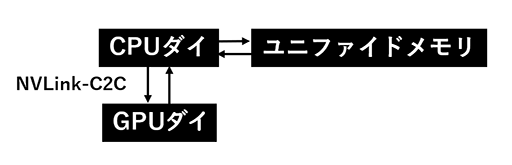 |
RTX Sparkは,ゲーム機のアーキテクチャとよく似た構成になっているのだ。これはCPUとGPUの協調処理が劇的に行いやすいことを意味する。
GPUにおけるメモリ帯域幅の差を覆せるほどではないが,それなりに高いグラフィックスの性能を実現できると筆者は考えている。
RTX Spark搭載PCで気になるのは価格
RTX Sparkは,これまでの,Arm系CPUを搭載したWindows PCへのイメージを大きく変えてしまいそうな存在だ。
「ゲームもできて,AIも動かせるなら欲しい」と考え始めた人もいるだろう。RTX Sparkを搭載したノートPCや小型PCも数多くラインナップされている。RTX Spark搭載PCはかなり面白そうな製品だが,問題は価格がどうなるかだ。
 |
 |
DGX Sparkは,サードパーティが販売する互換製品も含めると70万円台からという価格感だ。これを踏まえると,スペックを抑えた製品でも40万円以上,DGX Sparkと同じ仕様では安く見積もってやはり70万円くらいだろうか。
メモリやストレージの価格高騰がさらに長引き,製品価格に反映されるかもしれない。2026年秋にどういう価格で登場するのかが気になるところだ。
 |