









ニュース
西川善司の3DGE:「Radeon RX 6000」詳報。高性能の鍵となる「Infinity Cache」と「Smart Access Memory」の仕組みとは
 |
本稿では,発売前に掲載した筆者による解説記事の第2弾として,第1弾の時点では明確になっていなかった詳細についてレポートしたい。
ついにRadeon VIIを超えたハイエンドGPUのNavi 2X
RDNA 2アーキテクチャベースのGPUはNavi 2Xと呼ばれていたが,「Radeon RX 6900 XT」(以下,RX 6900 XT),およびRX 6800シリーズとなるGPUの開発コードネームは,「Navi 21」と呼ばれている。製造プロセスルールは,先代のNavi 1Xこと「Radeon RX 5000」シリーズと同じ台湾TSMCの7nmプロセスだが,AMDは「改良型の7nm」と呼んでいた。従来よりも歩留まりが向上して,より高クロックかつ電力効率が良いプロセッサを製造できるようになった新しい7nmプロセスと,理解していいだろう。
Navi 21の公称ダイサイズは,約519.8mm2で,トランジスタ数は約268億個。GeForce RTX 3090,3080の「GA102」がダイサイズ約628mm2で,トランジスタ数は約280億個なので,Navi 21のほうがやや規模が小さい。PCとの接続インタフェースは,当然ながらPCI Express(以下,PCIe) 4.0に対応する。
以下の画像は,AMDが公開したNavi 21のブロックダイアグラムだ。
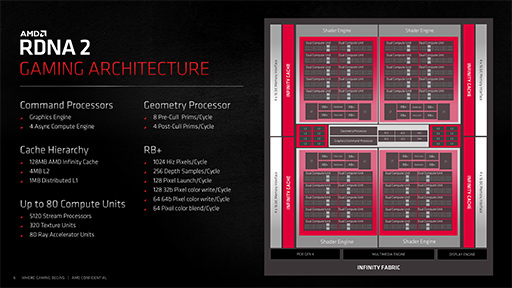 |
参考までに,Navi 1Xのブロックダイアグラムも示しておこう。
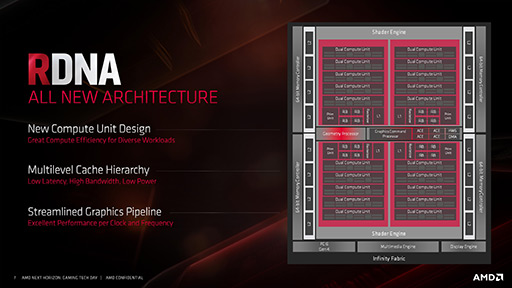 |
パッと見た感じでは,シェーダコアたるCompute Unit(CU)が2倍に増えただけにしか見えないが,実際は細かいところまで改良が加えられている。だが,その詳細に踏み込む前に,公称スペックを整理しておこう。
 |
Navi 1xの上位モデルだった「RX 5700 XT」(以下,
AMDの説明によると,Navi 2Xの論理設計や物理設計については,最新のRyzen系CPU(※Ryzen Desktop 5000シリーズだろう)から技術のフィードバックを行ったことで,7nmプロセスがもたらす恩恵以上の高クロック動作と電力効率を実現できたそうだ。
 |
Navi 1Xで,AMDのGPUアーキテクチャはRDNA系となったわけだが,1基のCUあたり,64基の汎用シェーダプロセッサ(以下,SP)を内包する構成は,RDNA 2となった今回も変わらない。よって総SPは以下のように計算できる。
- RX 6900 XT:64 SP×80 CU=5120 SP
- RX 6800 XT:64 SP×72 CU=4608 SP
- RX 6800:64 SP×60 CU=3840 SP
AMD製GPUでは,1 SPが1クロックで1つの積和算を行える(2FLOPS)ため,ピーク理論性能値はブーストクロック動作時換算で以下のとおりだ。
- RX 6900 XT:5120 SP×2 FLOPS×2250MHz=23.04 TFLOPS
- RX 6800 XT:4608 SP×2 FLOPS×2250MHz=20.74 TFLOPS
- RX 6800:3840 SP×2 FLOPS×2105MHz=16.17 TFLOPS
参考までにRX 5700シリーズや,NVIDIAの競合機となるGeForce RTX 30シリーズの最大理論性能値は以下のとおり。
- RX 5700 XT:9.75 TFLOPS
- RX 5700:7.59 TFLOPS
- GeForce RTX 3090:35.58 TFLOPS
- GeForce RTX 3080:29.77 TFLOPS
- GeForce RTX 3070:20.37 TFLOPS
理論性能値ではRX 5700シリーズの2倍以上に達するが,競合機にはやや及ばないといったところか。ただAMDは,「Navi 2Xには,競合に見合う性能がある」と主張する。この自信が,Navi 2Xの興味深いところだ。その自信がどこから来るのか,Navi 2Xのアーキテクチャを細かく見ていくとしよう。
Shader Engineに大きな変更はなし
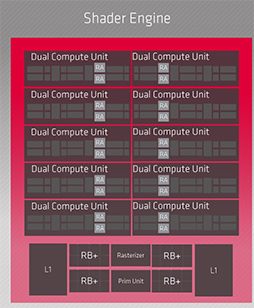 |
RDNA系GPUでは,SEに対して実際の仕事を発注するのがブロックダイアグラム中央にある「Command Processor」ブロックだ。ここには,以下のような機能ユニットがある。
- Hardware Scheduler:どのSEに仕事を割り振るかを決める
- Graphics Command Processor:3Dグラフィックス処理を各SEに発注する
- Geometry Processor:ポリゴン単位(頂点パイプライン)の処理を各SEに発注する
- Asynchronous Compute Engine(以下,ACE):GPGPU的な処理を各SEに発注する
- Direct Memory Access(以下,DMA):データ伝送をGPUコアの動作に対して非同期で行う
 |
ざっと資料を見た感じでは,ここに大きな改良点は見当たらない。ACEは,Polaris(※Radeon RX 400シリーズ)系以降のRadeonでは,ずっと4基のままだ。余談だが,AMD系GPUで最もACEが多いのは,8基を搭載するPlayStation 4のGPUである。初代GCN系のRadeon HD 7000シリーズ(※開発コードネームSouthern Islands)では2基で,これはXbox OneのGPUでも同様だった。AMDは今のところ,「PC向けGPUでは,ACEは4基で十分」と考えているようだ。
なお,Navi 2XのGeometry Processorは,頂点パイプライン上流における早期カリング(※Early CullingまたはPreCulling)処理が1クロックあたり8プリミティブ(≒ポリゴン)可能で,ラスタライザに流し込む前のPost Culling処理は,1クロックあたり4プリミティブが可能とAMDは明らかにしている。ただ,AMDはRX 5700シリーズの値を公開していないので,進化があったのかどうかはよく分からない。
CUはどう進化したのか
レイトレユニットの実力は?
GCNアーキテクチャにおけるCUは,演算実行ユニットがSIMD16※演算器で,これを4基備える実装だった。これがRDNAになると,SIMD32を2基備える形へと変更されたわけだ。しかも,32要素データスレッド「Wave32」を,1クロックで処理できる性能を要する。また,従来の「Wave64」に対しても,CU内にある2基のSIMD32演算器が,Wave64を2セットのWave32として処理するので,これまた1クロックで処理できることとなった。Navi 2XでもこのCUの仕組みは変わっていない。
※1命令で16要素のデータに対して同時に計算できる演算器のこと
またRDNAでは,2基のCUがキャッシュメモリをはじめとした各種リソースを共有して,1基のCUであるかのように動作できるように再構築され,この仕組みを「Work Group Processor」(以下,WGP)と呼ぶようになった。ここもRDNA 2において大きな変化はない。
なお,AMDが公開した資料によっては,WGPを「Dual Compute Unit」(DCU)と表記している部分もある。この手の名称が,文書や図版ごとにコロコロ変わるのはNVIDIAでもよくあるので驚かないように。
 |
Navi 2XのCUにおいて目を引くところは,演算ユニットが対応する数値形式の種類が増えたところだ。とくにAMDがアピールしていたのは,機械学習系や推論処理に有効な4bit整数と,8bit整数に対応したことだった。
ただ,すでにRadeon VIIでも対応済みだったので,まったく新しい要素というわけでもない。
 |
さて,Navi 2XのCUにおける最大の強化点といえば,レイトレーシングユニットに相当する「Ray Accelerator」(以下,RA)を搭載したことだろう。RAの機能自体は,先行しているGeForce RTXシリーズの「RT Core」と変わらない。
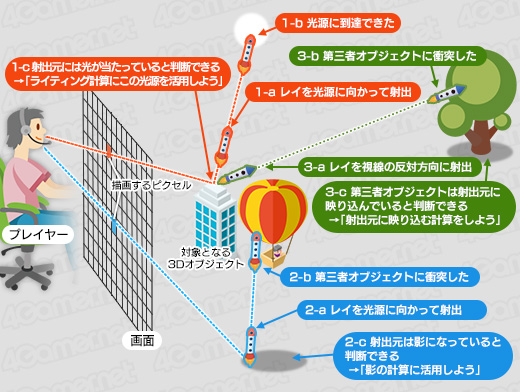 |
今世代のレイトレーシングユニットが担当するタスクには,以下の3点がある。
- 光線(Ray,レイ)の生成処理(Ray Generation)
- 光線を動かす「トラバース」(Traverse,横断)処理
- 光線とポリゴンの衝突判定を行う「インターセクション」(Ray-Triangle Intersection,交差)
これらの中で,一番処理負荷が高いのはインターセクションだ。無数の3Dモデルが存在する3Dシーンに対して放たれた1本の光線が,どの3Dモデルに衝突しているかを判定するには,何の工夫もしないと光線1本ごとにすべての3Dモデルとの総当たり判定をしなければならなくなってしまい,計算量が膨大になってしまう。
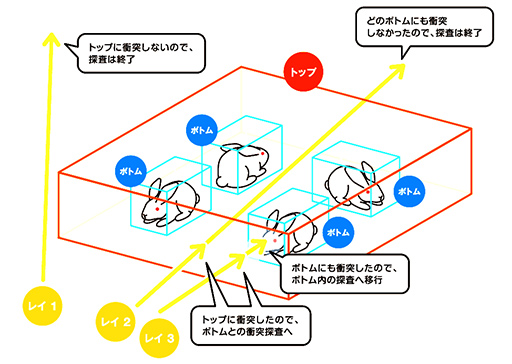
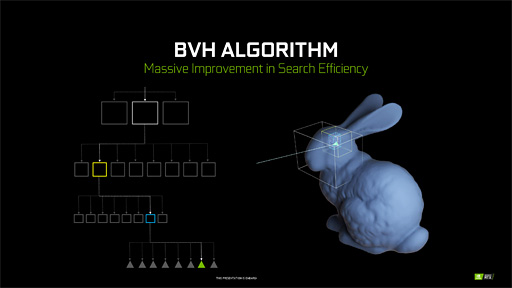
そこで,今どきのリアルタイムレイトレーシングにおける標準的な仕様では,3Dシーン内に存在する各3Dモデルを,3D座標軸に平行,垂直な向きに揃えて3Dモデルをピッタリと囲む直方体「Axis Aligned Bounding Box」(軸平行境界ボックス,以下 AABB)で管理したうえで,AABBを,3Dモデル全体を含むような大きな直方体(トップ)から,細部だけを囲む小さな直方体(ボトム)までを含む階層構造とすることで,光線と衝突していない3Dモデルを高速に排除しながら,高効率に衝突を検出する仕組みを採用している。
なお,リアルタイムレイトレーシングで用いる,階層的な直方体構造体で3Dシーンを管理する仕組みは「Bounding Volume Hierarchy」(以下,BVH)と呼ぶ。
たとえば,ウサギ小屋内にたくさんのウサギがいる状況を例に考えよう。光線がウサギ小屋のAABBに衝突しなければ,当然ながら中のウサギにも光線は当たらないので,ウサギすべてとの衝突判定で無視できるわけだ。一方,ウサギ小屋に衝突しているとしたら,すべてのウサギにおけるAABBとの衝突判定を行う。もし一羽のウサギに光線が当たっていたら,次にウサギを構成するどの部位に衝突しているかを探索するといった手順で,最終的にはどのポリゴンに衝突しているかまでを突き止める。
 |
 |
Navi 2Xでは,CU 1基あたり1基のRAを備えており,1基のRAは,1クロックあたり4つの直方体(=AABB)か,1つの三角形に対する衝突の検出ができるそうだ。
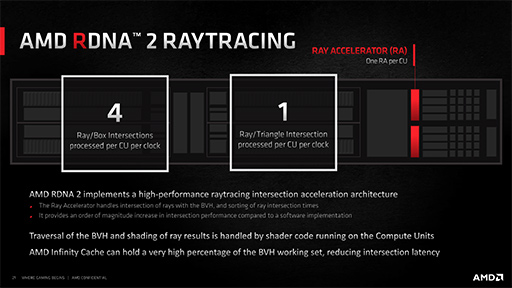 |
これを踏まえて,具体的な理論性能値を簡単に計算してみよう。RX 6900 XTのRA数はCUと同じ80基なので,
- 80 RA×2250MHz=1.8×10の11乗
となり,秒間1800億ポリゴンの衝突を計算できることになる。この値がどの程度すごいのか,今のところよく分からない。NVIDIAは,GeForce RTXシリーズでのレイトレーシング性能指標として「1秒間に生成できる光線数」を挙げているので,RX 6000シリーズとの直接比較ができないのだ。いずれは,業界の標準となる比較の単位を考案してほしいところである。

理論性能値を超えた高性能をもたらす「Infinity Cache」の秘密
結論から言ってしまえば,Navi 2Xの高性能を実現するポイントは,キャッシュシステムにあると言い切って良さそうだ。なにしろ,AMDによる報道関係者向け技術解説セッションでは,最も長い時間をこのパートに割いていたくらいだからだ。
以下に示すスライドは,Navi 2Xのキャッシュ階層図だ。
 |
パッと見わかりにくいかもしれないが,この図は,WGP単位のキャッシュ階層図になっている。もう一度,CUの拡大図を示したうえで説明していこう。
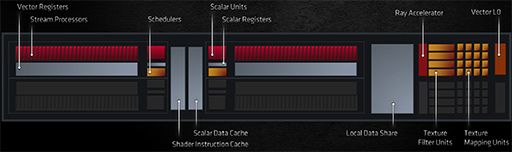 |
WGP内にある2基のCUは,それぞれ個別に並列動作ができて,各CUが容量16KBのL0キャッシュを個別に持っている。他方で,32KBの命令キャッシュ(Instruction Cache)や16KBのデータキャッシュ(K Cache),レンダーバックエンドキャッシュ(※Local Data Cacheを流用)は2つのCUで共有する仕組みだ。
容量128KBのL1キャッシュも,Navi 1Xと同様にSE 1基あたり2つあり,これを5基のWGPで共有する。
容量4MBのL2キャッシュは,L1キャッシュと内容が被らない設計で,主に,Command Processorブロックと各SE間のデータをキャッシュする役割をはたしていた。Navi 1XもNavi 2Xも,ブロックダイアグラム内でL2キャッシュは16個のブロックで描かれているが,これはメモリ1チャンネルあたり256KBのL2キャッシュがあることを表す。このL2キャッシュが16チャンネル分あるので,L2キャッシュは256KB×16ch=4MBとなる。Navi 1Xでは,このL2キャッシュがラストレベルキャッシュ(LLC)だった。
 |
Radeon RX 5000シリーズのGPU規模ならば,これで十分だったようだが,4K解像度で必要な性能を発揮するGPUを構築するにあたっては,不十分になったようだ。単純に演算ユニット(CU)を増量したうえで,それに合わせてキャッシュシステムとグラフィックスメモリを増量しただけでは,これら3つの機能ブロック間でやりとりするデータアクセスのバランスが悪くなると,AMDの開発陣は分析したという。そのためNavi 2Xでは,キャッシュシステムの大幅なテコ入れを行うこととしたのだ。
次のスライドは,Navi 2Xの開発初期に行われた実験結果から引用したグラフだ。横軸はLLCの容量を,縦軸はキャッシュヒット率を表す。
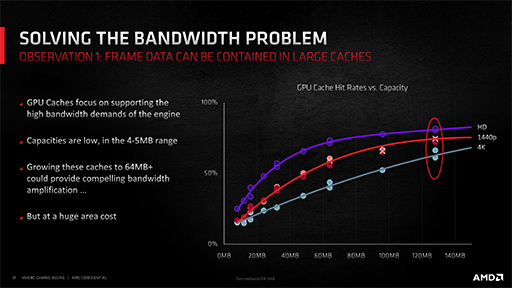 |
横軸左端でデータがプロットされているところは,Navi 1XでのLLC容量4MBを表す。HDと1440p,4Kでは,キャッシュヒット率が25%以下というのが見て取れよう。1440p以下では,GDDR6の性能があればキャッシュヒット率25%以下でも求められる描画性能を満たせるという算段だったのだろう。しかし,4K解像度が当たり前となってくる今後においては,そうもいかない。このアーキテクチャのまま,4K解像度の描画を満足に行えるようにするためには,より高速なメモリ――たとえばHBM(High Bandwidth Memory)やGDDR6Xなど――を使うという選択肢を選ばなければなくなる。しかし,それはグラフィックスカード製品となったときの製品価格に跳ね返るだろう。
先のグラフを見ても分かるように,AMDは,LLCを64MBあたりまで増やすと,1440pまではキャッシュヒット率を50%以上にまで上げられることに気付いた。ただ,50%というヒット率を4K解像度で実現するためには,LLCを120MB以上にまで増量しなければならないことも分かってきた。
ここからは,まさにAMDの思い切った判断になるのだが,より高速なメモリを使うか,あるいはキャッシュメモリを増やすかという二択において,後者の設計方針を選択したのだ。
もう1度グラフを見てもらうと,1440pまでは,LLC容量が100MB以上あってもキャッシュヒット率は60〜70%で飽和気味になっているのに対し,4Kにおいては,容量を上げれば上げるほどキャッシュヒット率が上昇しそうなことが分かるだろう。今後のグラフィックスメモリにおける速度向上と,グラフィックスメモリのコスト,そして製造プロセスの進化とキャッシュメモリ増量にかかるコストのバランスを比較して,AMDは,キャッシュメモリ増量に有望性を感じたということなのかもしれない。
さて,AMDは,こうした実験を経てNavi 2Xに128MBのLLCを搭載する方針を決めた。AMDの実験によれば,実際のゲームタイトルを4Kで動作させたときの128MB LLCのヒット率は約58%だったという。
興味深いのは,Navi 1Xにあった4MBのL2キャッシュも残しつつ,Navi 2Xに128MBのLLCを搭載したことだ。おそらく,L2キャッシュには引き続き,Command Processorと複数のSE間におけるキャッシュメモリとして活躍してもらう狙いがあったのだろう。
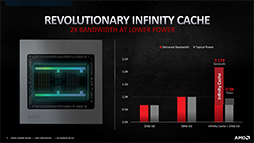 |
Navi 2XにおけるInfinity Cacheの実装は,Navi 1XにおけるL2キャッシュとそっくりである。Navi 2Xでは,1チャンネルあたり16bitのGDDR6メモリインタフェースを16チャンネル分実装しており,1チャンネルごとに8MBのL3キャッシュを組み合わせて8MB×16チャンネル=128MBとしたのが,Infinity Cacheの正体と言ってもいいかもしれない。
実際問題として,128MBものキャッシュメモリをGPUにどう実装するかについては,AMDでは入念な検討を行ったという。128MBといえば,キャッシュメモリとしてはかなりの大容量である。AMDは,大容量LLCの実装にあたって,Zen 2(※Ryzen 3000シリーズ)におけるL3キャッシュの実装技術を応用したと説明している。具体的にどのような技術を用いたのかまでは言及されなかったが,「Zen 2コアのキャッシュメモリ実装で採用して,1mm2あたり1MB以上のL3キャッシュメモリを実装する技術」を応用したそうだ。
なお,実際のZen 2では,32MBのL3キャッシュを27mm2で実装しているとのこと。
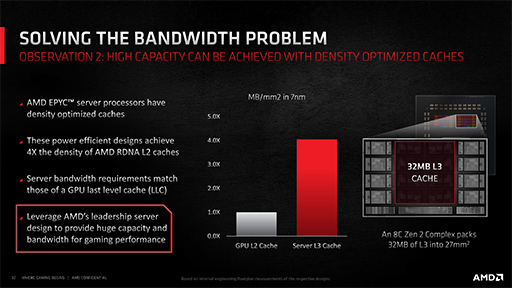 |
AMDによれば「このレベルの集積度を有する論理および物理設計が行えるのは,超先端のCPU設計が行えるプロセッサメーカーに限られる」と豪語しており,これはなかなか含みのあるセリフである(笑)。
いずれにしても,AMDは,Infinity Cacheがもたらした副次的なメリットを4つ挙げている。1つめは「消費電力あたりのメモリバス帯域幅の広さ」だ。Infinity Cacheアクセスの時の消費電力は1.3pj(ピコジュール)で済むのに対して,GDDR6では7〜8pj必要であるという。
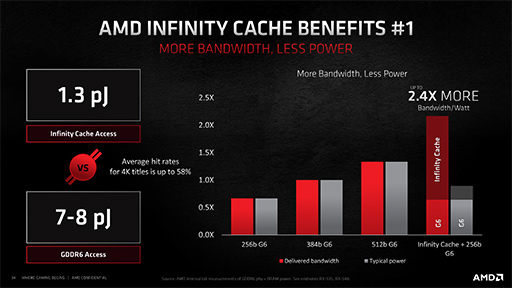 |
上に示したスライドは,赤いグラフがメモリバスの実効帯域幅で,灰色のグラフが消費電力を表している。左から,GDDR6メモリのバス幅が256bit,384bit,512bit,そしてNavi 2Xの256bit+Infinity Cacheを表している。ちなみに,このグラフは384bitを基準値(=1)としており,256bitと512bitのグラフは,それぞれ基準値の0.66倍(256÷384),1.33倍(512÷384)となっているところに注意してほしい。
このグラフによれば,Navi 2Xの256bit+Infinity Cacheシステムにおける消費電力あたりの実効帯域幅は,384bitの2.4倍以上に達しており,それでいて消費電力は8割くらいになったそうだ。
AMDによると,Infinity Cacheは,GPUコアの動作クロックとは独立したクロックにより,最大1.94GHzで駆動するとのこと。前述したようにInfinity Cacheは16チャンネルで構成されており,各チャンネルが1クロックあたり64byteのスループットがあるので,キャッシュがヒットしたときのメモリバス帯域幅は,64byte
前述したようにInfinity Cacheは16チャンネルで構成されており,スライドにもあるとおり,Infinity Cacheのクロック当たりのデータ転送量は1024byteとなっているので,Infinity Cacheのバス帯域幅は,1024byte×1.94GHz=1.81TB/sに達する。さすがはSRAMベースのキャッシュメモリといったところだが,実効帯域幅はキャッシュのヒット率に左右されるので,この値よりはだいぶ低くなるはずだ。
では,実効帯域幅を計算してみよう。今回のNavi 2Xは,全モデルが16GHz相当のGDDR6メモリを採用しているので,Navi 2Xのメモリバス帯域幅は,256bit
 |
最近のゲームグラフィックスは,高解像度での描画時にメモリバス帯域幅がボトルネックになりがちな傾向にあったので,この実効帯域幅があれば,グラフィックス性能向上に大きな効果があったとしても不思議ではない。
さて,Infinity Cache採用による2つめのメリットは,GPUコアの動作クロック上昇に対して,かなりリニアな性能向上を示すというものだ。
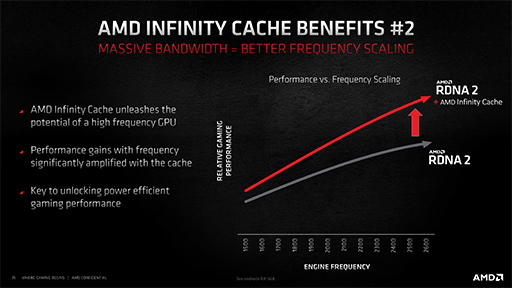 |
GPUは,内部の演算ユニット(=シェーダプロセッサ)がどれほど高速で動作しても,演算結果の最終的な出力先たるグラフィックスメモリとのやりとりがボトルネックになると,実効性能は頭打ちになってしまう。これに対して,最大1.94GHzで動作して,ヒット率約6割のInfinity Cacheがあれば,演算ユニットが必要とするデータを,GDDR6メモリ以上の速さで提供できる。その性能向上率は,演算ユニットの動作クロック上昇率に極めて近くなると,AMDは主張しているわけだ。
Infinity Cache採用による3つめのメリットは,2つめのメリットと関係が深いもので,メモリアクセス時の遅延を劇的に低減できるというものだ。
メモリ性能の指標には,毎秒何byteのデータ伝送をできるかを表すメモリバス帯域幅があるが,ここでは,メモリへアクセス要求をしてから実際にデータが届き始めるまでの遅延時間を考慮していない。大量のデータを一括伝送する場合は,そうした遅延はほとんど無視できるが,少量データをランダムに読み出す場合は,遅延の影響が大きくなるので無視できないものとなる。
メモリアクセスにまつわる遅延時間は,最新のGDDR6メモリでも初期のDDR1メモリとあまり進歩しておらず,十数ns(ナノ秒)は必要だ。これがSRAMベースのInfinity Cacheでは一桁台nsになるので,遅延時間の短縮率は相当なものだ。
AMDによると,16GHzのGDDR6を採用し,Infinity Cacheを組み合わせたRX 6800 XTでは,Infinity Cacheヒット時の遅延時間は,14GHzのGDDR6を採用したRX 5700 XTの遅延時間に対して48%にまで小さくなるとしている。
 |
要は,Infinity Cacheはキャッシュメモリ自体の帯域幅も高いが,遅延も小さくなるので,これを組み合わせたNavi 2Xのメモリバス帯域幅は相当に速いと主張しているのだ。
4つめのメリットは,「Infinity Cacheはレイトレーシング性能にも相当効く」というアピールだ。
 |
「キャッシュメモリの性能が,レイトレーシングに何の関係があるの?」と思うかもしれないが,実際,関係は大いにあるのだ。
レイトレーシングユニットたるRAが担当する,光線の生成処理,トラバース,インターセクションといった各処理は,実際のところ幾何学的な演算負荷はそれほど高くはなく,むしろメモリアクセス負荷のほうが高い。というのも,生成した光線を3Dシーンの中で移動させて衝突を判定する工程は,BVH構造体に対する探索であり,これは事実上,リスト構造の探索処理に似たものだからだ。簡単に言えば,やたらメモリを読みまくる処理なのだ。しかも,隣接する場所から放たれた光線は,似たようなBVH探索を行うことになるので,キャッシュメモリにヒットしやすいと予想できる。
ただ,AMDにとって,レイトレーシングユニットを搭載するGPUはNavi 2Xが初めてなので,Infinity Cacheによって,どのくらい性能向上するのかというデータを示せていない。「ソフトウェア実装したレイトレーシング処理の10倍は高速である」という,あまり参考にならないデータを出してきている。
RX 6800 XTおよびRX 6800のレビューを見る限り,NVIDIAのGeForce RTXシリーズで,同じレイトレーシング系ベンチマークを実行して性能を比較すると,最新のGeForce RTX 3080/3070にはおよばず,前世代にあたるGeForce RTX 2080 Tiにも負けるのが実情だ。つまり,レイトレーシングユニットの性能はNVIDIAに軍配が上がり,Infinity Cacheを持ってしてもその差は覆せないといったところか。
なお,これら4つのメリットだけでなく,「Infinity Cacheは,メモリアクセス頻度に応じて動作クロックを上下することで,消費電力を最適化する機構を備えている」と,AMDはアピールしていた。面白いのは,Infinity Cacheの動作クロック変動は,GPUコアクロックの変動とは独立していることだ。
つまり,GPUコアクロックが低かったとしても,メモリアクセス頻度が高ければInfinity Cacheは高クロックで動作するということだ。間接的にAMDは,Navi 2Xの省電力機構が細かい点まで配慮していることをアピールしているわけだ。
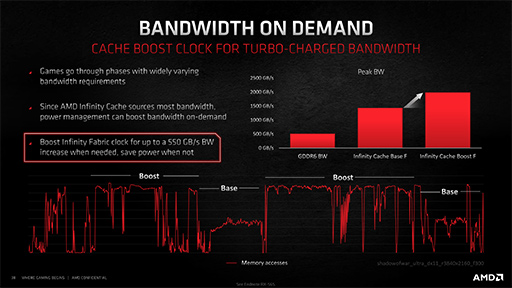 |
気になる実際の性能について,AMDは,RX 6800 XTとRX 5700 XTでゲームタイトルを4K解像度で動作させたときのフレームレートを示している。その結果は,すべてのタイトルで約2倍のフレームレートを記録したそうだ。
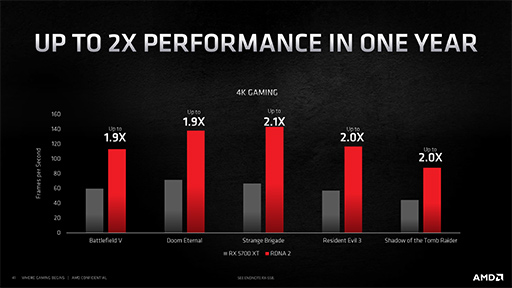 |
CU数(≒シェーダプロセッサ数)が倍になっているので当たり前のように思うかもしれないが,GDDR6のメモリクロックは,RX 5700 XTで14GHz,RX 6800 XTが16GHzと,約14%しか上がっていないのに,2倍の性能向上は立派だ。Navi 2Xの高性能は,Infinity Cacheによって下支えされているといっても過言ではあるまい。
レンダーバックエンドは「RB+」へと進化
Navi 2Xにおけるレンダリングパイプラインの最終工程たるレンダーバックエンド(以下,RB)は,AMDが「ダブルレンダーバックエンド」とアピールしているように,規模が倍増している。この改良型RBを,AMDは「RB+」と称している。
 |
上掲のスライドにあるブロックダイアグラムは,Navi 21のフルスペック版に相当するもので,RB+は計16基を備えている。フルスペック版のNavi 2Xは,実際の製品ではRX 6900 XTだ。
他方でRX 6800 XTは,CU 8基分を無効化しているが,各SEからCUを2基ずつ無効化しているのか,それとも異なる組み合わせになっているのか,AMDは明らかにしていない。いずれにしても,RB+の数は16基で,最上位のRX 6900 XTと変わらない。なお,下位モデルとなるRX 6800は,SE 1基分(=CU 20基)をまるごと無効化したのと同じCU数の60基となるため,RB+も4基分少ない12基となる。
AMDがダブルレンダーバックエンドと呼ぶように,RB+は,1基のRBが処理できる総ピクセル数が倍増したのがポイントだ。最も汎用的に用いられるRGBαの各8bitからなる32bitピクセルは,1基のRB+が1クロックで8ピクセルを処理可能で,Navi 1Xが備えるRBは4ピクセル/クロックなので,ちょうど2倍に当たる。RB+の数が全部で16基あるため,ピクセルスループットは8ピクセル×16基の128ピクセル/クロックだ。この性能は,従来のROP(レンダリング・アウトプット・パイプライン)換算にするとROP 128基分に相当する。
HDRレンダリングで使用するRGBα各16bitピクセルであっても,64ピクセル/クロックで処理できるので,RBの性能は相応に高いと言えよう。
しかも,このRB+,今後の高解像度ゲームグラフィックス描画において最重要の技術的テーマになると言われている「Variable Refresh Rate」(VRS,可変リフレッシュレート)をハードウェアサポートする機能も備えるのが見どころだ。
 |
Microsoftの「DirectX 12 Ultimate」において,VRSは,Tier 1とTier 2という機能レベルが定められている(関連リンク),Tier 1は,描画コール単位のVRS制御に対応しており,Tier 2はそれに加えて,3Dオブジェクト単位や,画面内の任意の場所(ただしタイル単位で指定)といった柔軟な制御にも対応する。
GeForce RTXシリーズは,最上位のTier2に対応するのだが,AMDに確認したところ,「Navi 2XもTier2に対応する」そうだ。GPUメーカー2社の足並みが揃ったことで,ゲーム開発におけるVRSの活用は,それなりに進むと期待できよう。
次に示す2枚のスライドは,「Dirt 5」を例にVRSの活用事例を説明したものだ。1枚めが元の画像で,2枚めがVRSレベルを可視化した画像となる。
 |
 |
赤い部分が最高品位の「1×1」で,黄色が中間品位の「2×1」または「1×2」,緑は最も低負荷で解像度も粗い「2×2」単位のシェーディングが行われている部分を示している。Dirt 5におけるVRS活用は,3Dモデルを構成する各頂点における法線ベクトルの変移がなだらかなところを低品位にしているためか,車体のシェーディングはほとんどが2×2で行われているのが分かるだろう。
Navi 2XのDirectX 12 Ultimate対応
VRSやリアルタイムレイトレーシングだけでなく,AMDは,Navi 2XがDirectX 12 Ultimateに完全対応していると謳っている。
 |
DirectX 12 Ultimateが提供する新しい技術や機能のうち,「Sampler Feedback」についてはNavi 2Xの説明から外れるので,本校末尾で説明することにした。興味ある人は参照してほしい。Navi 2XがSampler Feedbackに対応したことで,GeForce RTXシリーズとの足並みも揃ったので,ゲームにおける活用も期待できそうである。
DirectX 12 Ultimateの隠れた目玉機能である新しい頂点パイプライン「Mesh Shader」に,Navi 2Xが完全対応するのも大きな見どころだ。
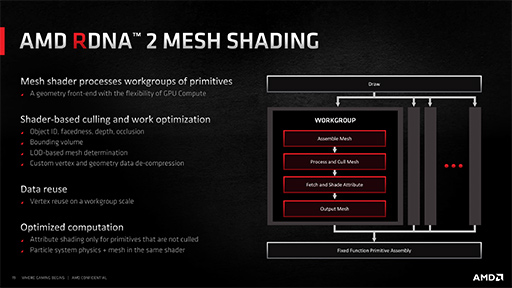 |
1990年代に登場した最初期のDirectXから,現在のDirectX11およびDirectX 12へと至る過程で,頂点パイプラインは,過去の互換性をある程度維持しながらの増改築がたび重なったことで,複雑怪奇なものになってしまった。これを刷新するのがMesh Shaderになる。
詳細は筆者の過去記事に詳しいが,新しい頂点パイプラインの提案は,AMDが「Radeon RX Vega」発表時に「Primitive Shader」を,NVIDIAがGeForce RTX 20シリーズ発表時にMesh Shaderを提唱していたが,AMDが最新GPUでMesh Shader案を採用したことで,事実上,Primitive Shader案は立ち消えることになった。
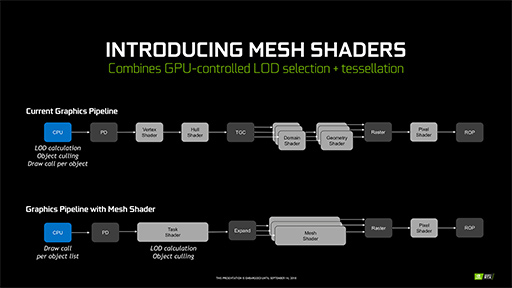 |
新しい頂点パイプラインについてもAMDとNVIDIAで機能サポートの足並みが揃ったということは,ユーザー目線では歓迎したいと思う。この機能も,今後はうまく行けば積極活用がなされるかもしれない。
さて,DirectX 12 Ultimateではほかにも,「DirectStorage」と呼ばれるサブシステムが新設されることを知っている人も多いだろう。
DirectStorageは,PlayStation 5とXbox Series X/Sに採用された「SSDから圧縮されたデータを読み出して,専用ハードウェアで展開したうえで,転送先のアドレス空間にDMA転送する仕組み」のDirectX版に相当するものだ。
NVIDIAは,DirectStorageをGPGPUでアクセラレーションする仕組みとして「RTX IO」を提供することをGeForce RTX 30シリーズと同時に発表した。対するAMDはというと,いまだ実装方法を明らかにはしていないものの「サポートはする」という表明だけはしている。続報に期待したいところだ。
PCIeの制限を飛び越えてCPU〜GPU間のメモリアクセスを高速化するSmart
Navi 2Xの発表時に,ユニークなAMD独自技術として「Smart Access Memory」が発表となった。これは,AMD製CPUのRyzen Desktop 5000(以下,Ryzen 5000)シリーズとRadeon RX 6000シリーズを揃えることで発揮できるシナジー効果であるそうで,アプリケーション側をまったく最適化せずとも,実際のゲームタイトルでフレームレートが2〜13%も向上するという。
 |
実際のゲームプログラムでは,シーン描画が実際に行われる前段階で,ほとんどの3Dモデルデータやテクスチャをグラフィックスメモリ側に読み込んでしまう。そのため,ゲーム進行中のグラフィックスレンダリング工程において,CPUからGPUに大量のデータを受け渡す頻度はそれほど高くはない。にもかかわらず,どうして既存のゲームをそのまま実行するだけで,Smart Access Memoryによって性能が向上するのだろうか。
AMDに問い合わせたところ,「Smart Access Memoryは,そうしたサイズの大きいデータの大量転送時だけでなく,コマンドバッファや,これに付随する定数データの転送でも大きな効果が得られる」という返答だった。そこで,さらに「Smart Access Memoryは,(32bit CPU世代を引きずった)Memory-mapped I/O(以下,MMIO)の制約を取り払うためのもの,という理解でよいか」と聞いたところ「その理解で問題ない」という回答だった。というわけで,情報を整理しよう。
CPUからGPUのグラフィックスメモリにアクセスする場合,PCIeの仕組みを使って行うのだが,GPUにつながるGB級のグラフィックスメモリ空間全域に対して,CPUはリニアなアドレス指定でアクセスできない。現状は,複数のインデックスを駆使して最長で4096byte単位のアクセスしかできないのだ。そのインデックスの組み合わせ自由度は16bit長(0〜65535)となっているため,CPUからは256MB(=4096byte×65536)サイズの範囲しかアクセスできなかった。
 |
たとえるなら,従来はCPU〜GPU間のデータ伝送は,256MBサイズの窓を通してやりとりしていたイメージだ。GPU側は,窓を通して受け取った最大256MBのデータを,自らが管理するグラフィックスメモリ空間上の必要なアドレスにリレー転送を仕かけていた。
これがSmart Access Memoryを活用することで,この256MBの窓枠を取り払うことが可能となり,CPU側からGPU管理化のグラフィックスメモリ空間にデータを直送できるようになるので,256MB単位でのリレー配送も不要になる。つまり,CPUから見て任意のアドレスに直送できるし,GPU側から見れば,窓から出てきたデータを目的のアドレスに転送する手間も不要になって,データ伝送が高効率化されるというわけだ。
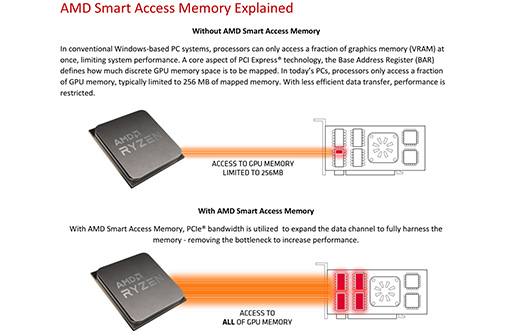 |
では,なぜ最適化が不要で,既存のゲームでも性能向上が得られるのか。CPUからGPUに何かデータを送る場合,データサイズの大小を問わず,片っ端からSmart Access Memoryを利用するためだ。ゲーム起動直後に行われる大量のテクスチャや3Dモデルデータの転送はいわずもがな,ゲーム開始以降に行う描画コマンドバッファやその付随データの伝送にもSmart Access Memoryが空気のように利用されるため,効果が得られるというわけだ。
どうして,そんなことが可能なのか。AMDにSmart Access Memoryの動作メカニズムについて確認してみたところ「Smart Access Memoryは,GPUのドライバソフトレベルでの対応となるため,DirectX 12や11,OpenGL,Vulkanのすべてで動作できる。APIの種類には依存しない」ということだった。
つまり,GPUに最も近いソフトウェア層であるドライバソフトが,データ伝送に関わるすべての処理でSmart Access Memoryを使うため,描画コマンドからテクスチャ,3Dモデルデータなど何から何まで,あらゆるデータ転送においてSmart Access Memoryによる転送を行える。そのため,ゲーム側の最適化は不要で,APIの種類にも依存しないというわけだ。ただ,「Smart Access Memoryの効果は,ゲームの設計やAPIによるオーバーヘッドの大小に依存する」と,AMD側はつけ加えている。
なお,PCIeの256MB上限を事実上撤廃するSmart Access Memoryの仕組みは,AMDの独自技術ではなく「PCIeの仕様に含まれているのでは?」という指摘があり,AMD側もそうであることを間接的に認めている(関連リンク)。しかし,256MB上限を超えるには,PCIeの仕組みにおける「Base Address Register」(BAR)の変更を許容して,4GB(32bit)というMMIOの制約を取り払う必要があるため,対応マザーボードと対応チップセットドライバがなければ実現できない。そのため現状では,利用できるCPUとGPU,マザーボードの組み合わせが極めて限られるので,現状ではAMDの独自技術と言えなくもないわけである。
ただ,こうしたAMDの独自技術アピールを,目ざといNVIDIAが黙ってただ見ているわけもなく,さっそく「NVIDIAがSmart Access Memoryと同等の機能実現に動き出した」という話も出てきた(関連リンク)。これが本当なら,最終的にはRyzen 5000シリーズとAMD 500チップセットにNVIDIA GPUを組み合わせても,Smart Access Memoryが利用できるようになるかもしれないわけで,ユーザーにとっては面白いことになる。今後の動向に注目したい。
HDMI 2.1対応と強化されたMedia Engine
最後に,Navi 2Xの細かい機能についても簡単に説明しよう。
まずはHDMI 2.1への対応だ。HDMI 2.0のサポートがNVIDIAに対して2年も遅れたAMDだったが(関連記事),最新のHDMI 2.1については,競合にさほど遅れることなく,Navi 2Xで対応を果たした。
Navi 2Xが搭載するHDMI 2.1出力は,AMD独自のディスプレイ同期技術「FreeSync」がベースになったとも言われる技術「Variable Refresh Rate」(VRR,4K/144Hz,8K/60Hzまで)にも対応しているほか,さらには非可逆圧縮技術「DSC」(Display Stream Compression)にも対応。DSCの高圧縮モードは,今後提供するファームウェアのアップデートで対応するともAMDは発表しており,最終的には8K解像度での120Hz表示にも対応するというから驚きだ。
GPUに統合されたビデオ処理エンジンである「Radeon Media Engine」は,Navi 2Xにおいて,最大8K解像度の「AV1」コーデックによるリアルタイムデコードに対応した。「HEVC」(H.265)であれば,なんと8K解像度のリアルタイムエンコードに対応するという(※ただし24fpsまで)。また,H.264エンコードについては,時間方向に対して順方向および逆方向の双方向参照にも対応した「Bフレーム」(Bi-directional Predicted Frame)に対応したそうで,同一ビットレート時の画質が,既存のRadeonより進化したことも嬉しい。
ちなみに,このBフレームサポートは,NVIDIAがNVENCでGeForce RTXシリーズからサポートを開始したものなので,Navi 2Xでの対応は必至だったのだろう。
 |
「理論性能値を超えた性能を引き出す」ための鍵となっていたInfinity Cacheの謎もおおむね仕組みを理解できたうえ,最新の機能に対する対応状況も,競合であるGeForce RTX 30シリーズと見劣りしないこともわかった。とくに,リアルタイムレイトレーシングとVRS,Sampler FeedbackをはじめとしたDirectX 12 Ultimateへの対応で,AMDとNVIDIAの足並みが完全に揃っていることが,なんとも喜ばしい。ここまで足並みが揃ったことは過去にもないくらいの珍しいことだ。
その意味では,どちらのGPUを選ぶかについては,じっくりと性能および価格のバランスを見て,気に入ったものを選べば大きな失敗はないだろう。定番のGeForce RTX 30とIntel製CPUで組み合わせるのもよし,今回,技術的な背景もある程度はクリアになったSmart Access Memoryの効果に期待して,CPUとGPUをAMDで揃えるのも悪くないはずだ。
Sampler Feedbackの活用事例
DirectX 12におけるSampler Feedbackは,10月に掲載したNavi 2X解説記事内で,「テクスチャユニットがMIP-MAP(低解像度版テクスチャ)のどれにアクセスしたかを記録して,テクスチャ座標系でのシェーディングに活用する」と説明したが,一体何がどう便利なのか分かりにくいし,ほかに解説している記事もあまりないようなので,少し詳しく説明したい。
現状,Sampler Feedbackの代表的な活用ケースは,2つあると考えられる。
1つは,オープンワールドゲームのように,はるか遠方までの超広範囲を描画するようなゲームグラフィックスにおいて,描画に用いるテクスチャの必要な部分だけをストレージなどから読み込ませるような使い方だ。
遠方の岩や草木に適用するテクスチャマップは,データ量の多いMIP-MAPの4096×4096テクセル解像度におけるテクスチャではなく,もっと解像度が低い,たとえば16×16テクセル解像度程度のMIP-MAPをストレージから読み出せばいいはずだ。これはデータの読み込み効率(≒速度)にも貢献するし,グラフィックスメモリの使用量節約にも貢献する。
スライドの「Advanced streaming」が上述の活用例で,「Texture space rendering」は,以下で説明する活用例だ
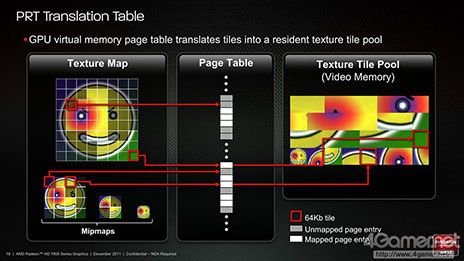
ちなみに,このアイデアの根源としては,かつてid SoftwareのJohn Carmack(ジョン・カーマック)氏が提唱した,グラフィックスメモリをテクスチャキャッシュの拡張エリアとして利用する「Mega Texture」が元になっている。
このMega Texture的な発想を,AMDは,Radeon HD 7000シリーズで「Partially Resident Textures」(PRT)として,ハードウェアクセラレーションできるような拡張を行った。その直後となる2013年に,Microsoftが発表した「DirectX 11.2」では,PRTが「Tiled Resources」機能として標準化されたという経緯がある。
PRTは,DirectX 11.2で「Tiled Resources」機能として標準化された
活用ケースの2つめは,最近,重要度を増していると言われる「Texture Space Shading」(TSS)だ。
3Dゲームグラフィックスにおいてよくあるのが,時間方向にチラチラと揺れる陰影が生じる現象だ。最近では,HDRレンダリングが珍しくなりつつあるが,とくに高輝度ハイライトで明滅が気になることは多い。この現象は,ワールド座標系に存在する3Dオブジェクト群をカメラ座標系に変換したうえで,画面座標系に投射してピクセル化(ラスタライズ)する過程で,画面上において1ピクセル未満の存在となる描画対象が,時間方向に「ある瞬間はピクセル化されるが,別のタイミングではピクセル化されない」ことで起きてしまう。
そこで「カメラがあまり動いていないときや,3Dオブジェクトがそれほど動いていないときは,ライティング処理やテクスチャリングを用いた各種陰影処理をテクスチャ座標系で済ませちゃった方がよくない?」とか,「カメラと3Dオブジェクトの距離とは無関係に,常に一定品質のライティング処理や各種陰影処理をテクスチャ座標系で行おうよ」という発想の元に生まれたのがTSSだ。ちなみに,前者は描画性能を重視する場合のTSSで,後者は映像品質重視で用いるTSSだ。
TSSとは,これから行うべきフレームのライティングや陰影処理を,その時点におけるカメラ位置やラスタライズ処理とは切り離し,テクスチャの場所基準(テクスチャ座標系)で行うものだ。Sampler Feedbackは,以前のレンダリングでどのテクスチャを参照したかを記憶しておけるので,TSSを行うときにこの情報を利用するわけだ。
具体的なレンダリングパスは,以下のようになる。
- 1パスめ:カメラ座標系変換なし,ラスタライズ処理なしで,直接テクスチャ座標系のライティングや陰影処理(※つまりTSS)を行う。結果は適当なワークバッファ(テクスチャ)に出力
・2パスめ:カメラ座標系変換とラスタライズ処理を行うが,ライティングや陰影処理は1パスめのワークバッファから読み出すだけ。このときに,ライティング結果や陰影処理結果を記録してあるテクスチャは,テクスチャユニットからテクスチャフィルタリング付きで読み出されるので,前述したような明滅現象は低減される。なお,TSSが行われていない部分は,普通の描画をすることもあり。
なお,1パスめは毎フレームではなく,適当なタイミング(≒必要に応じて)で行うようにすれば,GPU負荷を減らせる副次メリットもある。あるいは,重要度の低い3Dオブジェクトに対してTSSを適用するというアイデアもあるだろう。VRSが解像度方向に適材適所のレンダリングを行うテクニックだとすれば,TSSは,時間方向やオブジェクト単位に適材適所のレンダリングを行うテクニックだといえなくもない。
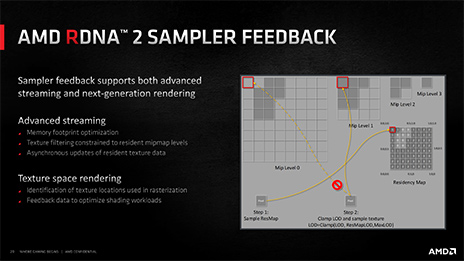
- 関連タイトル:
 Radeon RX 6000
Radeon RX 6000 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー