










イベント
「big.LITTLE」+Mali,ARMが目指す2012年のコンピュートサブシステムとは
 |
4Gamerでもいくつかの記事で報じてきたが,ARMはプロセッサコアIPCortexとともに,GPUコアIPとしてMaliを強く推している。セッションのタイトルにある2012年のコンピュートサブシステムにおいてもMaliが重要な位置を占めるが,なぜARMがそのような方向性を持つに至ったかが分かる内容も含まれていたので,そのあたりを中心にまとめてみたい。
”Elba”プロジェクトを通じて将来の方向性を研究
本セッションを担当したのは,英ARMのKeith Clarke氏だ。
ご存じのようにARMはSoCメーカーに対してプロセッサなどのIP(知的所有権)を提供している企業で,自社でLSI製品の製造を手がけているわけではない。しかし,当然ながら研究開発の段階で,さまざまなLSIを試作し評価を行っている。
Clarke氏は,ARMがコンピュータシステムのアーキテクチャや設計の方法論を創り上げていくために実行した“Elba(エルバ)”と呼ばれるプロジェクトを紹介したいと切り出した。
 |
Elbaは実際のSoCを試作して,そのソフトウェアやハードウェアに関する研究を行うことで,将来の方向性を探ろうという趣旨のプロジェクトだそうで,実際に製作されたテスト用のSoCは,次のスライドのような構成を持つものだという。
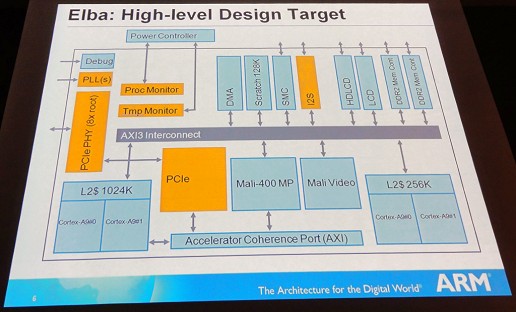 |
このElbaのSoCで特徴的なのは,2コアのCortex-A9のクラスタが2つあるということだ。これは「右側が高パフォーマンスのCortex-A9クラスタ,左側は低消費電力のCortex-A9クラスタ」(Clarke氏)だそうで,NIVIDIAのTegra 3が行っているvSMPと同じことをやっている。Cortex-A15世代で計画されているbig.LITTLEプロセッシング(高性能なCortex-A15コアと低消費電力のCortex-A7コアを組み合わせて高性能と低消費電力を両立させる設計)は,これを発展させたものになっているようだ。
Clarke氏によると,このテストチップは今年の初め頃に完成し,以来さまざまなソフトウェアなどの実装,研究を行ってきたという。それを通じて「非常に多くの知見を得ることができた」と語る。
一例としてClarke氏が挙げたのが,懐かしき「Quake III Arena」の実装と,そのベンチマーク結果である。テストチップはフルHD環境で平均67.8fpsというフレームレートを得たと動画を示しながら紹介してくれた。
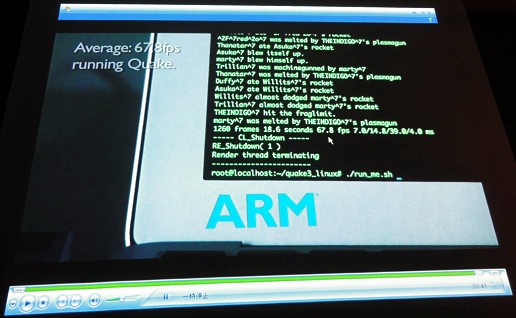 |
PC基準でいうと67.8fpsというのは,正直「がっかりレベル」ではあるが,モバイル3D環境でフルHDということを考えるとたいしたものだということなのだろう。
それはともかくとして,このテストチップの成果の一つがbig.LITTLEプロセッシングの効用であったとClarke氏は説明する。
 |
もう一つ,実装上の成果として,パワーマネジメントを移管することの有効性も確認されたと紹介していた。Cortex-M3コアを用いた「OSのパワーマネジメントをパワーマネジメントブロックに移管することで,OSからシステム効率のモニタリングが可能になる」(Clarke氏)としていた。こうしたこともElbaのテストチップを通して研究されたのだろう。
 |
GPUコンピューティングに最適なコヒーレンシを保つシステム
さらに,Clarke氏が強調するのがGPUコンピューティングだ。ARMのMali GPUはI/Oコヒーレンシ(一貫性)を保つバスでCPUと接続されており「GPUからCPUのキャッシュをスヌープ(覗き見)し,データの一貫性を保つことができる。このようなシステムはGPUコンピューティングに最適である」(Clarke氏)と説明する。
 |
これは,PCのGPUと対比すると分かりやすい。PCのGPUはローカルなグラフィックスメモリを持ち,これはCPUのメインメモリとは物理的に分かれている。最近ではAMD Fusionのように,CPUとGPUが統合されたチップも出てきているが,現状では,CPUとGPUのコヒーレンシは完全ではない。
このようなシステムでは,GPUのローカルメモリとCPUの物理メモリとの間でのデータのやり取りが発生し,そのオーバーヘッドがかさんでくるため,プログラミング上でさまざまな工夫が必要になる。
一方,ARMのモバイルアーキテクチャでは,CPUとGPUはもともと同じ物理メモリを共有し,ARMのMaliではCPUのキャッシュを含めてメモリのデータに一貫性が保てるために,CPUとGPUの間のデータのやり取りは原則的には不要になる。そのため極めて効率的なGPUコンピューティングが可能になる,というわけである。
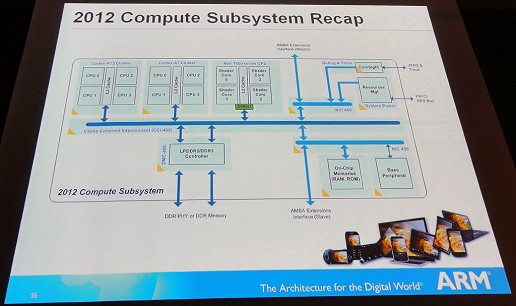 |
もう1点,注目しておきたいのは,ARMが考える“2012年のコンピュートサブシステム”にはMaliがデフォルトで組み込まれているということだ。ARM系では,Imagination TechnologiesのPowerVRや,NVIDIAのTegra/ULP GeForceといったサードパーティのGPUが存在する。しかし,Clarke氏は「すでに2012年のコンピュートサブシステムの準備はでき,開発を進めることが可能になっている。ぜひ開発を進めてほしい」と会場に呼びかけて講演を締めていた。このことが象徴するように,ARMは,GPUコンピューティング込みのエコシステムを築こうとしているようだ。
したがって,サードパーティのGPUがARMのプラットフォームで生き抜くためには,Mali以上のメリットを提供する必要が出てくる。各社とも,どのような展開をしてくるのかに注目したい。
- 関連タイトル:
 Cortex-A
Cortex-A
- 関連タイトル:Mali,Immortalis
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー