











レビュー
ついに登場したTrinity,第2世代APUの実力を探る
A10-4600M
(Comalプラットフォーム評価機)
 |
発表当初のラインナップは以下のとおりで,最下位モデルとなるA4は,2012年中の市場投入予定とされている。
●発表時点におけるノートPC向け新世代A-Seriesのラインナップ
- A10-4600M:Radeon HD 7660G(384コア,497〜686MHz),2 Piledriver Module(L2 2MB×2,2.3〜3.2GHz),TDP 35W
- A8-4500M:Radeon HD 7640G(256コア,497〜655MHz),2 Piledriver Module(L2 2MB×2,1.9〜2.8GHz),TDP 35W
- A6-4400M:Radeon HD 7520G(192コア,497〜686MHz),1 Piledriver Module(L2 1MB×1,2.7〜3.2GHz),TDP 35W
- A10-4665M:Radeon HD 7620G(384コア,360〜497MHz),2 Piledriver Module(L2 2MB×2,2.0〜2.8GHz),TDP 25W
- A6-4455M:Radeon HD 7500G(256コア,327〜424MHz),1 Piledriver Module(L2 2MB×1,2.1〜2.6GHz),TDP 17W
 |
Northern IslandsとPiledriverを統合したTrinity
ハードウェアビデオエンコーダの統合もトピックに
以下,便宜的に,新世代A-SeriesをTrinity,従来世代A-SeriesをLlanoと,開発コードネームで書き分けることにするが,Trinityには多くの新機軸が盛り込まれているので,まずは概要を一気に説明してみたい。
 |
 |
 |
そんなTrinityの製品概要をまとめてあるのが下のスライドだ。
 |
今回は,4Gamer的に最も気になるGPUブロックから見ていくことにするが,従来製品たるLlanoでは,製品型番でいうとATI Radeon HD 5600&5500シリーズに相当する「Redwood」コア,つまりはEvergreen世代のコアが統合されていた(関連記事)。これに対してTrinityでは,より新しいNorthern Islands世代のコアを統合するというのが大きなポイントになっている。
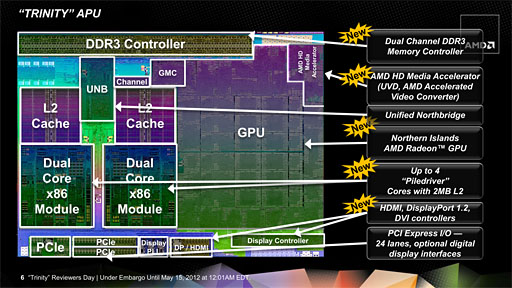 |
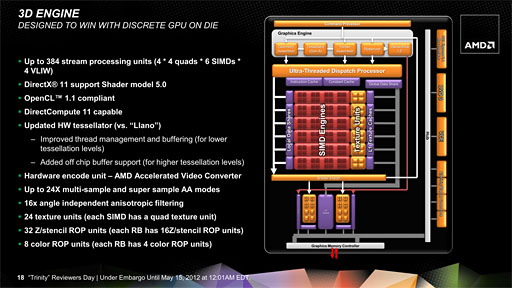
また,ただNorthern Islands世代へ移行しただけでなく,「VLIW4」(Very Long Instruction Words)エンジンを採用してきたというのも,TrinityのGPUコアにおける大きな特徴だ。
簡単に歴史を振り返っておくと,AMDは,ATI Radeon HD 2000シリーズ以降,ATI Radeon HD 5000シリーズまで一貫して,32bitスカラ演算器(=シェーダプロセッサ)×4と,倍精度演算や超越関数に対応する「T-Unit」の“4+1”構成をベースとし,これを16基束ねてSIMDプロセッサ「SIMD Engine」とする「VLIW5」エンジンを採用してきた。
この流れが変わったのはRadeon HD 6900シリーズで,同シリーズでは,T-Unitの役割を4基のシェーダプロセッサへ割り振って,よりシンプルなVLIW4エンジンとすることで,命令発行やスケジューリングの負荷を低減しようという試みがなされている(関連記事)。このVLIW4エンジンは最新の「Graphics Core Next」アーキテクチャにも採用されているので,記憶に新しいという人も多いだろう。
 |
ただ,実のところ,Radeon HD 6000シリーズでVLIW4エンジンが採用されたのは最上位モデルたるRadeon HD 6900シリーズだけ。Radeon HD 6800シリーズ以下ではVLIW5が採用されていたのだ。もちろん,Radeon HD 6900クラスのハイエンドGPUコアをそのまま統合できるわけではないから,それよりも小さなNorthern IslandsコアをVLIW4ベースで統合してきたTrinityのGPUコアは,従来のRadeon HD 6000シリーズとは異なる構成になっているわけである。
シェーダプロセッサ(以下,SP)のことを最近「Radeon Core」と呼んでいるAMDは,TrinityのGPUコアで採用されるSPを「Radeon Core 2.0」と呼び,GPUブランド名もRadeon HD 6000ではなくRadeon HD 7000Gシリーズとしているが,確かにそれだけの意味があるとはいえそうだ。
なお,Trinityで統合されるSP数は最大384基。SIMD Engineは4(VLIW4エンジン)×16=64基で構成されるため,SIMD Engine数は6基となる。「Northern Islands世代で6基のSIMD Engineを搭載」という意味においては,VLIW5エンジンで480基のSPを統合するRadeon HD 6600&6500シリーズに近い存在ということになるだろう。
 |
組み合わせられるCPUコアは,Bulldozerアーキテクチャの第2世代モデル「Piledriver」(パイルドライバー)。従来のLlanoがAthlon X2&X4やPhenomシリーズで採用されてきた,いわゆるStarsコア――K10アーキテクチャの改良版で,K10.5とも呼ばれる――を採用していたのに対し,Trinityでは,Bulldozerアーキテクチャの最新世代へと移行を果たしたわけだ。
Bulldozerアーキテクチャでは,2基の整数演算ユニットが1基の浮動小数点演算ユニットを共有する形で「Bulldozer Module」(以下,Bulldozerモジュール)を構成するが,Piledriverでもこの仕様は踏襲される。Trinityでは最大2基の「Piledriver Module」(以下,Piledriverモジュール)を搭載できるので,AMDのCPUコア数計算規則に従うなら,クアッドCPUコア仕様が可能ということになる。
Bulldozerアーキテクチャを採用するプロセッサとしては,先行してAMD FX(以下,FX)シリーズが市場投入されているが,それと比較すると,コアアーキテクチャが新しくなった一方で,FXシリーズだとモジュール間で共有されるL3キャッシュがTrinityでは省略されているのが重要な変更点といえそうだ。Trinityのキャッシュは,モジュールごとに用意されるL2までとなる。
 |
さて,FXプロセッサのテストを通じて明らかになったとおり,Bulldozerアーキテクチャは,クロックあたりの性能だと競合製品はおろか,Starsコアにも及ばない。コア数と動作クロックで性能を稼ぐ設計になっている。なので,Trinityで統合される2基のモジュールでは動作クロックがより重要となり,いきおい,負荷状況に応じた自動クロックアップ機能「AMD Turbo CORE Technology」(以下,Turbo CORE)の重要性が増すことになる。
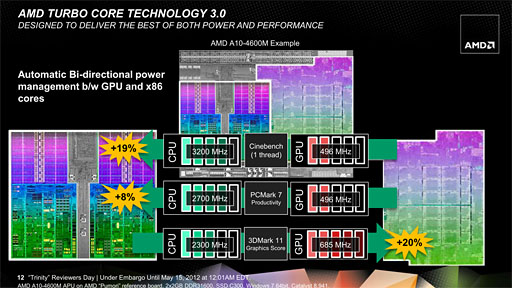
そこでAMDは,Trinityで,Turbo COREを第3世代の「Turbo CORE 3.0」へと進化させてきた。
振り返ってみると,Llanoで採用されている第1世代Turbo COREは,GPUブロックのTDP余剰分をCPUブロックへ渡すことで,最大2 CPUコアのクロック引き上げを可能にするものだった。また,FXの第2世代Turbo COREは,負荷状況に応じて,全体の半分のコアだけ引き上げたり,全部のコアを引き上げたりするものだったが,Trinityの第3世代Turbo COREでは,GPUクロックの動的な制御が行われるようになったのである。AMDいわく,GPU負荷が高いときにはCPUのクロックを抑え,その分の余裕をGPUクロックの引き上げに充て,逆にCPU性能が必要とされるときにはGPUクロックを抑えてCPUクロックを引き上げるとのことだ。
Intelの第2&第3世代Coreプロセッサにおける「Intel Turbo Boost Technology」(以下,Turbo Boost)と同じような制御ができるようになったと言えるかもしれない。
 |
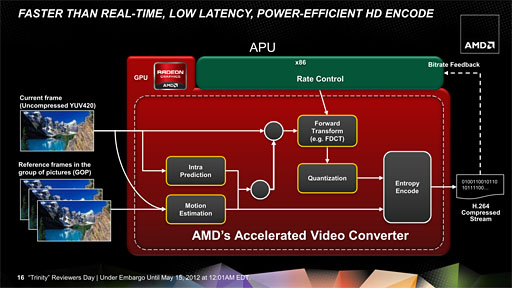
もう1つ,Trinityの性能を語るうえで重要なポイントとなるのが,「AMD HD Media Accelerator」と呼ばれる固定機能だ。
ここ数年,AMDのGPUが「UVD」(Universal Video Decoder)という固定機能を搭載し,ビデオデコード面での各種アクセラレーションを提供してきたことは,Radeonユーザーなら体験的に知っているだろうが,今回のAMD HD Media Acceleratorは,「UVD 3」によるビデオのデコードだけでなく,エンコードまで行えるようになっているのが大きな特徴である。
AMD HD Media Acceleratorでは「Accelerated Video Converter」と呼ばれるエンコーダが用意されており,H.264やMPEG-2,VC-1の圧縮に関わる処理がハードウェア化されている。AMDによれば,従来的なソフトウェアエンコードに比べると3倍以上の性能を実現しているとのことだ。
 |
AMDのTrinity評価機はDell製か
DT向けLlanoやFX+Radeon,Ivy Bridgeと比較
 |
今回筆者のところへ届いたのは,AMDの企業ロゴなどが入ったリファレンス機で,試作機扱いとなっている。Trinityベースのメインストリーム(=エントリー〜ミドルクラス)市場向けプラットフォーム「Comal」(コマル)が採用されているとのことだ。
 |
 |
 |
 |
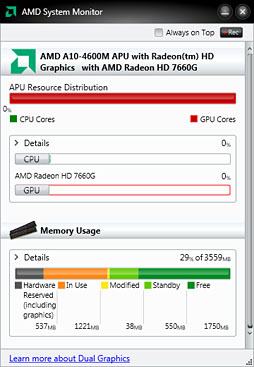 |
冒頭でも紹介したとおり,A10-4600Mは,384基のStream Processor(Radeon Coreともいう。以下 SP)を集積し,最大動作クロックが686MHzで,「Radeon HD 7660G」(以下,HD 7660G)というブランド名の与えられたGPUブロックと,ベースクロック2.3GHz,Turbo CORE時の最大動作クロック3.2GHzというPiledriverモジュール×2ベースのCPUブロックとを統合してきたAPUだ。チップセットは,開発コードネーム「Hudson M3」とされてきた「AMD A70M」が組み合わされている。
メインメモリはPC3-12800 DDR3 SDRAM 2GB×2で,採用される液晶パネルは14インチワイド(※資料にインチ数が明記されていないため実測),解像度1366×768ドットだ。
なお,グラフィックスおよびチップセットドライバは,プリインストールされていたものをそのまま利用した。ドライババージョンは「AMD 8.945 RC2 Win7 Vista March29/2012」なので,「Catalyst 12.2 Preview」か,それに近いバージョンがベースだろう。
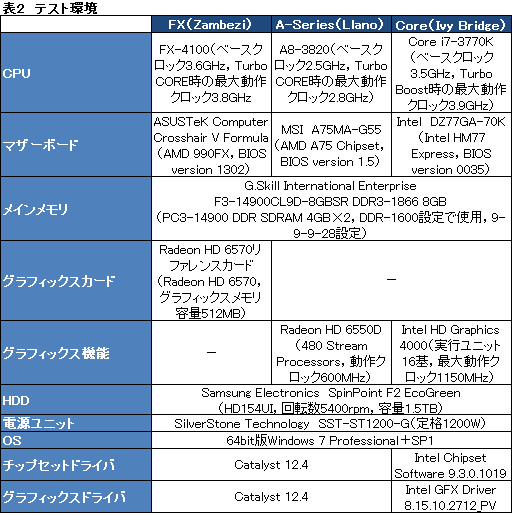
そのほか主なスペックは表1にまとめたとおり。なお,いかにも評価機らしく,BIOSの細かな設定変更はできなかったため,こういった部分は標準構成のままとなる。
 |
そんなA10-4600M評価機の比較対象だが,今回は,デスクトップPC向けのLlanoやCPUを用意することにした。ノートPC同士で比較しようにも,プロセッサ以外のスペックを揃えたりはできないのなら,いっそのこと,馴染みのあるAPUやCPUと比較してみようというわけである。
比較対象を具体的に挙げておこう。まずLlanoは「A8-3820」を選んだ。
- 統合されるGPUが400 SP仕様の「Radeon HD 6550D」(以下,HD 6550D)で,SP数がA10-4600Mで統合されるHD 7660Gの384基に近い
- CPUコアが4基なので,AMDの数え方に従えばCPUコア数がA10-4600Mと揃う
- CPUが第1世代Turbo COREをサポートし,定格2.5GHzに対して最大2.8GHz動作するようになっており,A10-4600Mの第3世代Turbo COREと比較できる
というのがその理由である。ちなみにHD 6550Dの動作クロックは600MHz固定。TDPは65Wとなっている。
さらに,BulldozerアーキテクチャのCPUから,2基のBulldozerモジュールを搭載する「FX-4100」(定格3.6GHz,Turbo CORE時最大3.8GHz)も用意。これを,「Radeon HD 6570」(以下,HD 6570)と組み合わせた。Bulldozerモジュールの数を揃え,同時に,SIMD Engineを6基搭載して480基のSPを集積する,Northern Islands世代のGPUを用意することで,A10-4600Mとなるべく条件を揃えたというわけである。
また,先頃リリースされた「Core i7-3770K」(以下,i7-3770K)も,統合型グラフィックス機能「Intel HD Graphics 4000」を比較対象とすべく用意してみた。CPUコアを比較しても意味はないが,グラフィックス性能であれば勝負になるのではないかというのが選択の理由だ。
そのほかテスト環境は表2のとおり。今回は3Dグラフィックス性能と基礎検証を順に行っていくが,ハードウェア構成自体はここで紹介したものを共通して用いる。
 |
3Dグラフィックス性能の検証方法は基本的に4Gamerのベンチマークレギュレーション12.1準拠。ただし,テストスケジュールや,レギュレーションが主に単体グラフィックスカードの検証用に用意されているという事情を鑑みて,「S.T.A.L.K.E.R.: Call of Pripyat」と「Sid Meier's Civilization V」を省略する一方,「Battlefield 3」(以下,BF3)と「DiRT 3」では,ベンチマークレギュレーションで規定する設定よりもさらにグラフィックス設定を落とした「特別設定」でもテストを行うことにした。
具体的に述べると,BF3の場合はオプションの「ビデオ」から,「映像品質」を「中」とし,さらに「アンチエイリアシングポスト」を「オフ」,「異方性フィルタリング」を「1x」とした。DiRT 3では,オプションの「GRAPHICS OPTIONS」にある「DETAIL」からプリセットを「MIDDLE」とし,「MULTISAMPLING」を「OFF」としている。
解像度設定は,評価機のネイティブ解像度である1366×768ドットのほか,1280×720&1600×900ドットを選択。評価機から1600×900ドット出力を行うときはHDMI出力を行っている。
なお,A8-3820では1600×900ドット出力を行えなかったため,同解像度のスコアがN/Aとなる点はあらかじめお断りしておきたい。
基礎検証にあたってのテスト方法は,結果を示すところで適宜紹介する。
テストに先立ってTurbo COREの挙動を確認
電源設定は「バランス」が最適か
テストに先立って,第3世代Turbo CORE周りの挙動を確認しておきたい。
前提となる話をすると,Bulldozerアーキテクチャを採用するFXプロセッサには,「Core C6 State」と呼ばれる独自の省電力機能が備わっており,本機能を使うと,Windows側の電源設定にかかわらず,アイドル時のCPUコアクロックが1.4GHzにまで落ちるようになる(関連記事)。
この点,PiledriverベースのA10-4600Mだとどうか。結論から先に言うと,Core C6 Stateは備わっているが,その挙動はFXと異なるようだ。
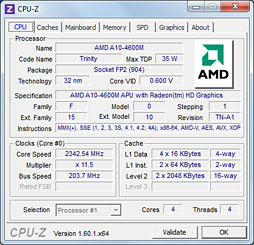 |
原稿執筆時点でTrinity関連の詳細な技術資料は公開されていないため,今回はTrinity対応が謳われるCPUID製ツール「CPU-Z」(Version 1.60.1)を使ってクロックの変化を見ることにしたが,Core C6 Stateを有効にしたうえで,「電源オプション」を「バランス」にすると,アイドル時のCPUコアクロックは1.4GHz前後にまで落ちる。それに対し,「高パフォーマンス」にすると2.7GHz前後でクロックが固定されるのだ。
なぜこういう挙動になるのかは,AMDから資料が公開されないとなんともいえないのだが,いずれにせよ,「電源オプション」を「高パフォーマンス」に指定すると,アイドル時かどうかに関わらず,定格の2.3GHzよりも400MHz程度高いところへ張り付く。400MHz高いというあたりからすると,「高パフォーマンス」を選択すると,Turbo COREにおける「All Core Turbo」が常時有効になっている可能性が考えられる。
この挙動が評価機のみの現象なのか,ノートPC向けTrinityで共通のものなのかは不明だが,「高パフォーマンス」を選択した場合は,CPUクロックが高止まりするため,第3世代Turbo COREの挙動に影響が出る(≒GPUクロックが上がりにくくなる可能性がある)ので,この点は注意が必要だと思われる。
そこで今回,3Dグラフィックス性能検証のすべてと基礎検証の大部分で,電源オプションの設定は「バランス」と「高パフォーマンス」の2とおりを試してみることにした。CPUクロックが高めに制御されるとき,性能にどういった変化が生じるかを見てみようというわけだ。
ちなみに,これはTurbo Boostに対応したIntel製CPUでも同じだが,Core C6 StateとTurbo COREを有効にしたA10-4600MのCPUコアクロックを追ってみると,激しく上下に動いていることが確認できている。ベースクロックとされる2.3GHzとはいったい何なのかと思えるほどだ。
少なくとも,Core C6 StateとTurbo COREを有効にした状態で,A10-4600Mの動作クロックが2.3GHzに落ち着いたりすることはなかった。このようなクロック制御法が現在のトレンドになったということだろう。
なお,比較対象のシステムでは,Turbo COREおよびTurbo Boostや有効化。また,より高いベンチマークスコアが得られると判明している電源オプション「高パフォーマンス」で固定している。
3D性能は「A8-3820+α」程度
3Dオンラインゲームならプレイできるレベル
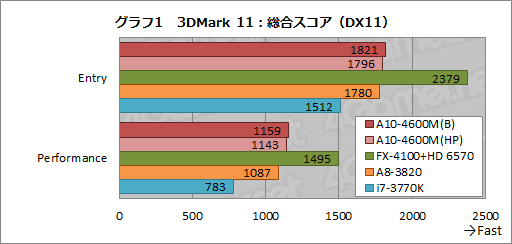
前置きが長くなったが,まずは「3DMark 11」の「Entry」および「Performance」から見ていくことにしよう。
グラフ1は総合スコアをまとめたものだが,ここではA10-4600Mに関して注目すべき点が2つある。1つは,電源オプションを「バランス」にしたA10-4600M(以下,A10-4600M(B))のほうが,同「高パフォーマンス」(以下,A10-4600M(HP))よりもスコアが約1%高いこと。もう1つは,電源オプションを「バランス」にしたA10-4600MのベンチマークスコアがA8-3820よりも2〜7%程度高いことだ。ここからは,GPUクロックの制御に電源オプションが影響を与えている可能性と,TrinityとLlanoでは描画負荷が高くなると後者が有利になる可能性を窺えよう。
なお,A10-4600M(B)のスコアは,FX-4100+HD 6570比で77〜78%程度,i7-3770K比で120〜140%程度となっている。
 |
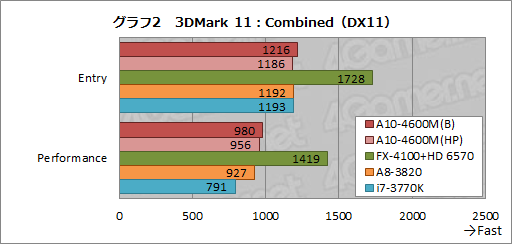
3DMark 11の個別テスト結果を見ていったとき,電源オプション設定によるスコアの違いが大きかったのは,グラフ2に示した「Combined Test」だった。
Combined Testでは,GPUとCPUの両方を使って物理シミュレーションを行うことになるのだが,ここではEntryとPerformanceのプリセットに共通して,A10-4600M(B)のほうがA10-4600M(HP)よりも約3%スコアが高い。GPUとCPUの両方を使うテストでスコアのギャップが大きいというのは,「高パフォーマンス設定」がGPUクロックに負の影響を与えるという見方を補強するものと述べてよさそうだ。
 |
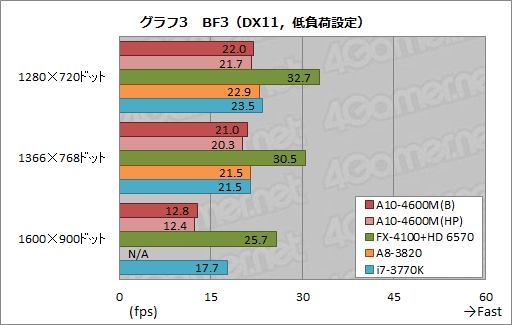
グラフ3はBF3における「低負荷設定」のスコアだが,A10-4600MとA8-3820のスコアはほぼ横並び。一方,i7-3770Kはかなり健闘しており,解像度1600×900ドットでA10-4600Mを上回るフレームレートを残したことは特筆すべきだろう。高解像度では共有L3キャッシュをグラフィックスメモリとして利用できるIvy Bridgeの優位性が出ているといえるかもしれない。
もっとも,FX-4100+HD 6570を除いて,ゲームをプレイできるレベルにないフレームレートなのも確かだが。
 |
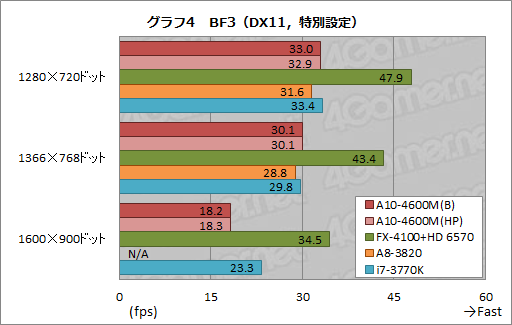
というわけで,グラフィックス設定のプリセットを下げた特別設定のスコアを見てみると,A8-4600MとA8-3820,i7-3770Kは,1366×768ドットまでの解像度で,レギュレーション12.1で規定する合格点たる35fpsに若干届かないところで落ち着いた(グラフ4)。実際にプレイしてみても,「快適ではないが遊べなくもない」という印象だ。
面白いのは,低負荷設定で存在したA10-4600M(B)とA10-4600M(HP)のスコア差がほぼなくなっていること。グラフィックス描画負荷が下がったことで,負荷がCPU寄りになったためかもしれない。
 |
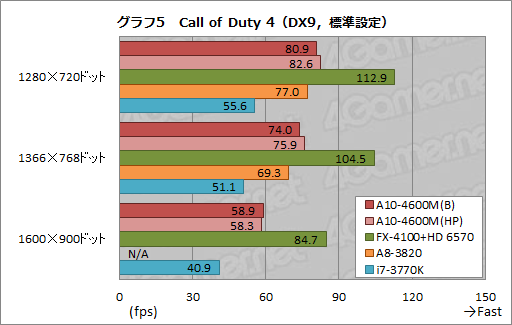
グラフ5は,DirectX 9世代の“軽い”ゲームを代表して採用している「Call of Duty 4: Modern Warfare」(以下,Call of Duty 4)の平均フレームレートをまとめたものである。
絶対スコアで見ていくと,A8-4600Mは解像度1366×768ドットで平均60fpsを10fps以上上回ってきているので,いわゆるオンライン専用FPSをプレイするのに十分な3D性能はは確保できていると述べていいだろう。また,3Dオンラインゲームの多くは1600×900ドットでもまったく問題なくプレイできるはずだ。
スコアで面白いのは,1366×768ドットまででA8-4600M(HP)のほうがA8-4600(B)よりも高いスコアを示すのに対し,1600×900ドットでは逆転が生じていること。描画負荷が低いだけに,低解像度ではCPU性能がスコアを左右しやすくなり,「高パフォーマンス」設定が優位になったということなのだろう。
なお,A8-3820とのスコア差が5〜7%に広がっているのもなかなか興味深いところである。
 |
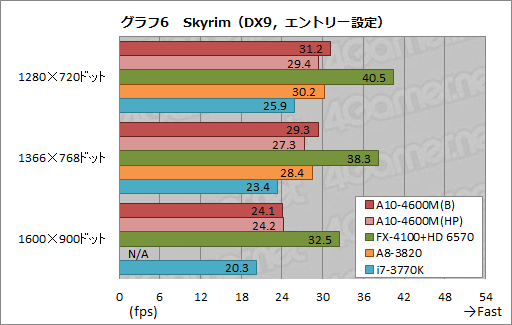
次にグラフ6は,「エントリー設定」で実行した「The Elder Scrolls V: Skyrim」(以下,Skyrim)のテスト結果である。
ここでは,1366×768ドットまでの解像度で,A10-4600M(B)がA10-4600(HP)に対して6〜7%程度も高いスコアを示している点に注目したい。1600×900ドットなら,よりGPU性能が要求されるようになるはずなので,ここで両者のスコア差がなくなるのは正直謎なのだが,このあたりはドライバ最適化の問題かもしれない。
もう1つ,Skyrimでは,A8-3820がA10-4600M(HP)を3〜4%程度上回っているのも目を引くところだ。A10-4600MのGPUコアクロックは最大686MHzで,A8-3820の600MHzより高く,GPUコアが原因とはあまり考えにくいので,メモリ周りに何らかの違いが生じているのかもしれない。
なお,A8-4600MとFX-4100+HD 6570およびi7-3770Kの力関係は,3DMark 11とよく似ている。
 |
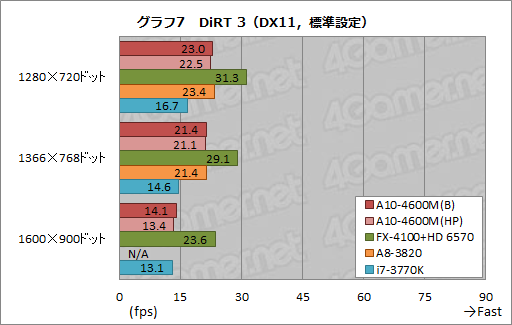
DiRT 3を「標準設定」で実行したときのテスト結果がグラフ7だ。標準設定では負荷が高すぎるため,フレームレート下限の13fps台がちらほらと出てきてしまっているが,そんななかでも傾向自体は3DMark 11と同じだということが分かる。A10-4600M(HP)が13fps台を示した1600×900ドットを除くと,A10-4600M(B)のスコアはA10-4600M(HP)より1〜2%程度高い。
 |
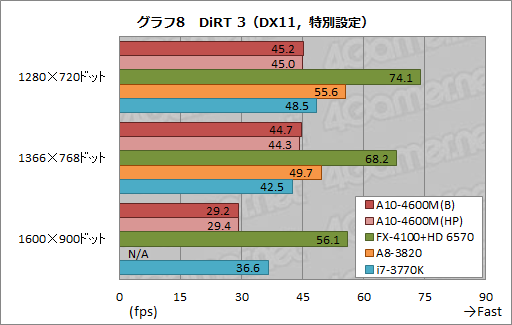
同じくDiRT 3から,グラフィックス設定のプリセットをMIDDLEまで落とした特別設定のテスト結果がグラフ8となるが,ここではA8-3820のスコアがA10-4600M(B)を11〜23%も上回り,i7-3770Kですら1280×720ドットでA10-4600M(B)より7%高かった。
……というより,全体として,A10-4600Mがグラフィックス描画負荷低減の恩恵を受けていない印象で,ここまでの結果と比べても明らかに不自然だ。Trinityに向けたグラフィックスドライバの最適化が,まだ十全でないと見るのが,ここでは正解であるように思われる。
 |
以上,ここまでをざっくりまとめてみると,「A10-4600Mの3D性能は,A8-3820とほぼ同じか,若干高め」ということになりそうである。
A10-4600Mの電源オプション設定は,「バランス」を選択したほうが総合的にはいいだろう。バランス設定だと,CPUクロック優先にならないため,GPUクロックが上がり,フレームレートが高めに出る傾向にあるからだ。
ただ,TDPの枠内で動作クロックを変動させる機能ということもあって,どちらを選んでも消費電力自体に大きな違いはない気配である。
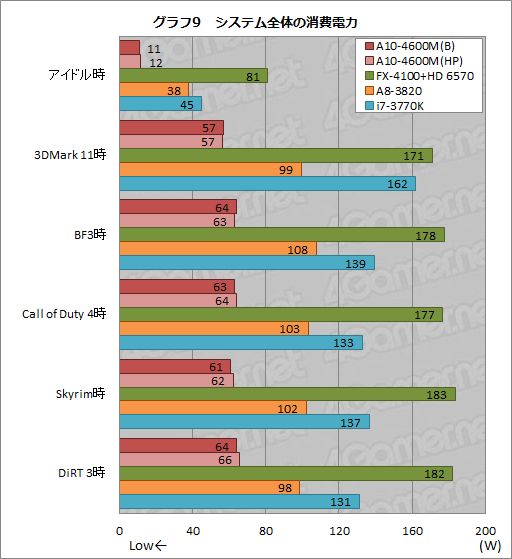
今回は,ログの取得が可能なワットチェッカー「Watts up? PRO」を利用し,OSの起動後30分間放置した時点を「アイドル時」,アプリケーションを実行したとき最も高い消費電力値が記録された時点をそれぞれの実行時として,スコアをまとめてみることにした。アイドル時には,ディスプレイ出力が無効化されないよう設定し,また,ノートPCのテストではバッテリーパックを取り外しているが,その結果を示したのがグラフ9で,ご覧のとおり,A10-4600M(B)とA10-4600M(HP)とで,システム全体の消費電力に違いはほとんどない。いずれもノートPC全体で65W以下に収まるような設計になっていると述べていいだろう。
絶対値で見ると,ノートPC向けAPUということで,さすがにA10-4600Mのスコアは優秀。この消費電力でA8-3820相当の3D性能を持っているというのは高く評価していいように思われる。
 |
Llanoとは特性が異なるTrinityのGPU
倍精度浮動小数点演算性能の向上を確認
さて,予告していたとおり,ここからはベンチマークレギュレーションを離れ,基礎的なテストからTrinityの特性を探っていくことにしたい。
まずはGPUからとなるが,ここでは,Llano,そしてNorthern Islads世代の単体GPUとの違いに焦点を当てるため,i7-3770Kをテスト対象から外した。また,GPU性能を見る観点から,A10-4600Mでは2とおりの電源オプションでテストを実行する。
というわけでグラフ10は,「Sandra 2012」(SP3,Version 18.45)で用意される「Video Rendering」のテスト結果だ。「Video」とあるので勘違いしやすいが,これはシェーダによるシンプルなレンダリング性能を見るテストで,GPUの特性が出やすい特徴がある。
そして,単精度浮動小数点数の演算を用いる「Native Float Shaders」では,A10-4600MがA8-3820はもちろん,FX-4100+HD 6570をも上回る性能を示してきた。
FX-4100+HD 6570のスコアを上回ってきたというのは少々驚きでもあるのだが,シンプルなレンダリング性能は,Trinity世代でかなり高められていると見ていいだろう。
倍精度浮動小数点数を用いる「Native Double Shaders」でも,A10-4600Mのスコアが最も高かった。AMDはTrinity世代のGPUで倍精度浮動小数点演算の性能を向上させたとアピールしているが,確かにそのとおりの結果が出ているわけだ。
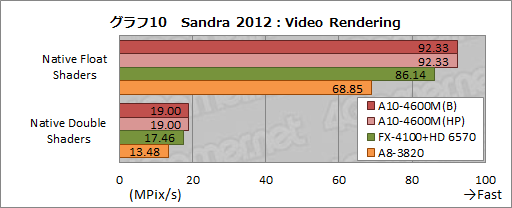 |
実のところ,倍精度浮動小数点数の演算性能がコンシューマ分野の3D性能に与える影響は大きくない。たとえば次世代WindowsたるWindows 8のDirect3Dでは16bit低精度浮動小数点数がサポートされるなど,コンシューマ向けGPUはむしろ,精度の低い演算の性能を上げるべき状況にあるとも言える。
そうしたなかで,あえて倍精度の演算性能を上げてきたというのは,AMDの戦略がゆえだろう。APUに統合されるGPUブロックが,CPUブロックと並んで,汎用アプリケーションで大きな役割を担うというのが,AMDの期待するシナリオだ。だからこそ,汎用アプリケーションでは利用する機会も増える倍精度の浮動小数点演算性能を上げてきた,というわけなのである。
……話を戻そう。グラフ11は,Sandra 2012における「Video Transcode」のスコアをまとめたものだ。ビデオのトランスコードを行う本テストでは,A10-4600Mが他を圧倒する。
この理由は明快で,前述のとおり,TrinityでH.264やVC-1に対応するハードウェアエンコーダを搭載してきた影響だ。
ちなみに,同じような固定機能「Intel Quick Sync Video」を搭載するi7-3770Kだと約5MB/sなので,それと比べるとA10-4600Mは控えめな性能といったところだが,従来製品から大幅な改善があったのもまた間違いないところである。
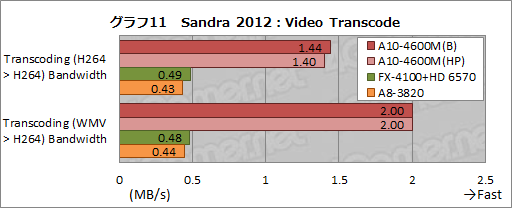 |
Sandra 2012のグラフィックスメモリ性能テスト「Video Memory Bandwidth」。その結果がグラフ12だ。
GPU管轄下にあるグラフィックスメモリ間の転送レートを見る「Internal Memory Bandwidth」だと,専用のグラフィックスメモリチップを用意するHD 6570のスコアが飛び抜けている。
今回用いたHD 6570リファレンスカードは4GHz相当で動作するGDDR5メモリが組み合わされているので,UMAでメインメモリの一部をグラフィックスメモリとして用いるA10-4600MやA8-3820を圧倒するのは当然といったところだ。
UMAベースの製品で比較すると,A10-4600M(B)がA8-3820よりも12〜14%高いスコアを示した。同じデュアルチャネルDDR3-1600メモリアクセスとはいえ,UMAだけにメモリアクセス面における改善の余地はあまりないと思われるだけに,1割以上の帯域幅改善があったことは注目してよさそうである。
一方,メインメモリ→GPU間の帯域幅を見る「Interface Transfer Bandwidth」だと,PCI Express経由となるHD 6570もスコアを落とす。PCI Express接続のグラフィックスカードは、どの機種でもPCI Expressの帯域幅で頭打ちになるため、5GB/s前後に落ち着くのだが,果たしてHD 6570もそうなったわけだ。
CPUかDMAを用いたメインメモリ間のデータ転送となるA10-4600MとA8-3820の間に大きな違いはないものの,Trinityで若干の改善があることも,スコアからは見て取れよう。
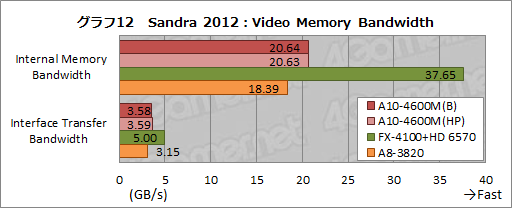 |
グラフ13は,OpenCLによるGPUの演算性能を見る「GP Processing」の結果だが,単精度浮動小数点演算を用いる「Native Float Shaders」のスコアがおかしく思える。グラフ10に示したVideo RenderingのNative Float ShadersではA10-4600MがA8-3820を上回るスコアを示していたのに対し,ここでは逆転されたどころか,大差を付けられているからだ。
こういう結果になってしまっているのは,おそらくGP ProcessingがA10-4600Mの弱点を付いた――OpenCLの演算では,コードが演算器の構成に最適化されないと,一気に性能を落とすことがある――か,OpenCLのコンパイラに問題があるかのいずれかだろう。
一方,倍精度浮動小数点演算を用いる「Emulated/Native Double Shaders」では順当に,A10-4600MがA8-3820比161%というスコアを示した。
ちなみに「Emulated/Native」というのは,エミュレートかネイティブのどちらかを使うという意味で,倍精度浮動小数点数の演算をネイティブサポートしていないA8-3820ではEmulated,A10-4600MとHD 6570ではNativeになるのをテスト時に確認できている。
つまり,Llanoに集積されたGPUは単精度のみで,倍精度は(ハードウェアレベルでは)サポートされていないが,Trinity世代では倍精度の演算をハードウェアでサポートしている可能性があるということだ。「可能性がある」に留めたのは,OpenCLからネイティブに見えるだけで,内部的にはエミュレートという可能性も否定はできないためである。
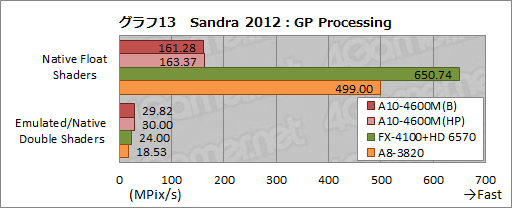 |
グラフ14はやはりSandra 2012から,OpenCLによる暗号化のテストを行う「GP Cryptographic」の結果だ。整数演算が主体となるので,GPUの整数演算性能を見るテストと考えていい。
このテストでもA10-4600Mは順当に高い成績を示しており,とくに,SHA2アルゴリズムを用いたハッシュの計算を行う「Hasing Bandwidth SHA2-256 GPGPU」でA8-3820に対してて2倍弱と,非常に高いスコアを叩き出しているのは特筆してよさそうだ。おそらくは,Sandra 2012で使われているアルゴリズムがTrinityに向いたものなのだろうと思われる。
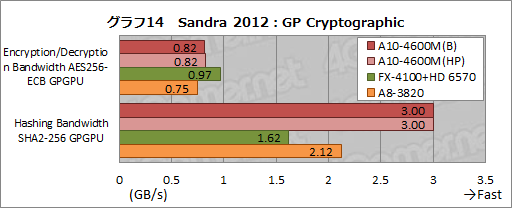 |
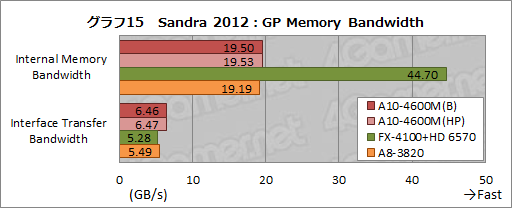
OpenCLを用いたグラフィックスメモリバス帯域幅テストである「GP Memory Bandwidth」の結果をまとめたものがグラフ15となる。GPUによるグラフィックスメモリ間の転送レートを見る「Internal Memory Bandwidth」の結果は,グラフ12に示したVideo Memory Bandwidthの結果をほぼ踏襲したもので,これは納得のスコアといったところだろう。
一方,CPU→GPUのメモリバス帯域幅を見る「Internal Memory Bandwidth」では,A10-4600MがFX-4100+HD 6570やA8-3820と比べて高いスコアを記録した。その理由は定かでないが,Video Memory Bandwidthでも改善の痕跡が見られた以上,メモリ周りに何らかの改良が行われ,その結果が出ていると見るのが妥当と思われる。
 |
 |
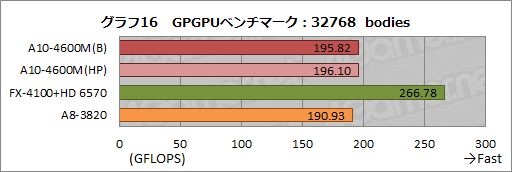
1つめは,GPGPU分野のアプリケーション開発を手がけるAOCプランニングが公開している「GPGPUベンチマーク」(Version 1.0.1)だ。
GPGPUベンチマークは,多体問題を解くパフォーマンスを調べるテストである。多体問題はGPUの単精度浮動少数点演算性能が“剥き出し”になりやすいことが知られているので,GPUの演算性能を見るのには適した問題といえる。
今回は,「-benchamrk」オプションで実行できるベンチマークモードを使い,「-n=32768」オプションで,物体数を,処理時間がさほど長くなく,かつ比較しやすい32768体として実行してみた。
その結果がグラフ16だ。A10-4600Mは対A8-3820で「やや高い」程度のスコアを残し,HD 6570がそんなA10-4600Mを置き去りにするという結果になっている。Sandra 2012のGP Processingはスコアが異常だったが,GPGPUベンチマークの結果を見る限り,Trinity世代のGPUコアは,Llanoのそれと比べて,単精度浮動小数点演算性能がわずかに改善されていると見るのがよさそうだ。
 |
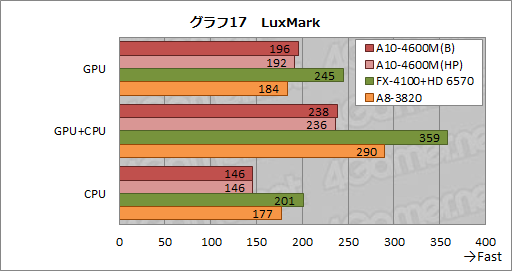
2つめは,OpenCLをサポートするレイトレーシングエンジン「LuxRender」に,サンプルデータとスクリプトをセットにしてベンチマークツールに仕立てた「LuxMark」(Version 2.0)だ。
LuxMarkはレイ(Ray,光線)の計算速度を見るもので,GPUのみ,GPU+CPU,CPUのみという3つの方法でテストを行えるのが大きな特徴となっている。
そんなLuxMarkのテスト結果がグラフ17だ。GPUのみを使ったときの結果はGPGPUベンチマークをほぼ踏襲する形になっており,これは納得できる結果と言えそうである。
GPU+CPUでは,A10-4600Mに対してA8-3820が有意に高いスコアを記録しているが,おそらくこれは,デスクトップPC向けAPUであるA8-3820ではTDP面での余裕が大きく,CPUクロックを上げやすいのと,そもそもクロックあたりのCPUコア性能ではLlanoのほうが高いのとが理由だろう。
実際,CPUのみを用いたときのテスト結果では,A8-3820のスコアがA10-4600Mを約21%上回った。FX-4100はそれよりさらに上のレベルにあるが,これはTurbo COREにより最大3.8GHzで動作するという高いクロックが影響したために違いない。
また,GPUの基本性能を見る段落に入ってからは,違いがほとんどなかったためにA10-4600M(B)とA10-4600M(HP)の差異についてまったく触れてこなかったが,演算にCPUを絡められるLuxMarkでは,CPUが絡んできたことで,電源オプションの違いがスコアに現れている点にも注目しておきたい。
スコア差はわずかだが,LuxMarkのテスト結果はほとんど揺らがないので,この違いは,電源オプションによるGPU&CPUコアクロック制御の違いがもたらしたものと断じてよさそうだ。やはり,バランス設定のほうが良い結果を残すようである。
 |
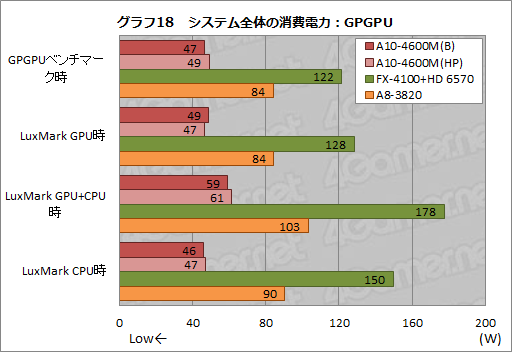
グラフ18は,GPGPUベンチマークとLuxMarkをそれぞれ実行したときに最も高い消費電力値を示した時点を各実行時として,3D性能検証の段と同じようにシステム全体の消費電力値を計測した結果となる。
A10-4600Mのスコアは,GPUコアのみを駆動させたときに50W弱程度,CPUのみを駆動させたときにも50W弱程度。両方を動かしたときでも60W程度に収まるよう設計されているようだ。GPUとCPUの両方を動かした場合,消費電力は単純計算で100W程度に達しても不思議はないのだが,そうならないよう60W台に上限が設定されている気配が,3D性能の段と同じく,ここでも確認できたことになる。
 |
以上,GPU関連の基礎的なテストを行ってきたが,「A10-4600Mのシェーダは,単精度の演算性能だとLlanoよりやや高速な程度で,倍精度の演算性能なら1.5倍程度高速」と述べてよさそうだ。AMDはTrinityにおいて,OpenCLアクセラレーションに対応したアプリケーションの存在をアピールポイントに挙げているが,その背景には倍精度演算性能の向上があると見ていいだろう。
アーキテクチャの大きな変更が原因なのか,一部のテストでは性能が発揮できなかったりもするが,これはドライバや,ドライバに同梱されるOpenCLコンパイラの改善で修正される可能性もあるので,まだ最終的な決断は早いと思われる。
Bulldozerアーキテクチャらしい特性を示すPiledriver
前世代からの劇的な進化は認められない
GPUに続いては,CPUである。
チェックする必要があるのは,そもそもLlanoのStarsコアから何が変わったかと,Bulldozerアーキテクチャにどういった改良が入ったかという2点だ。AMDはPiledriverについて「IPC(Instructions Per Clock,クロック当たりの命令発行数)が向上していると発表しているので,FXプロセッサとの違いも重要なチェック項目ということになる。
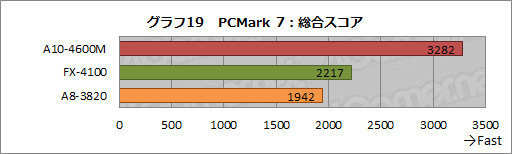
まずは,ざっくりと性能を比較するためにPC総合ベンチマークテスト「PCMark 7」(Version 1.0.4)のスコアをチェックしてみよう。
グラフ19は,テストに用いた全プラットフォームでTurbo COREを有効化し,電源オプションをA10-4600Mで「バランス」,FX-4100とA8-3820では「高パフォーマンス」としてPCMark 7を実行した結果だ。ご覧のとおり,A10-4600Mが他を圧倒してしまうのだが,これにはいろいろと事情がある。
 |
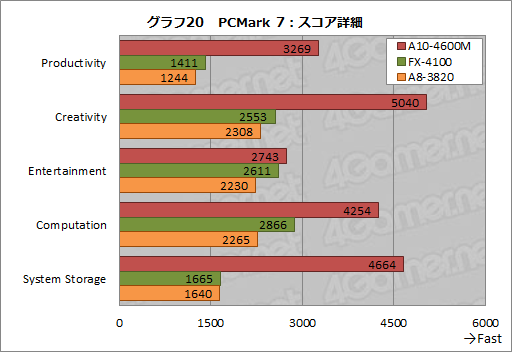
では,事情とは何だろうか。スコアの詳細をまとめたのがグラフ20で,これを見ると,主に3D性能の比較となる「Entertainment」を除き,すべての項目でA10-4600Mが非常に高いスコアを示しているのが分かる。
その理由だが,まず「Productivity」に関していうと,答えは明確だ。評価機がSamsung Electronics製のSSDをシステムドライブとして採用しており,そのため,ストレージ関連のテストでA10-4600Mがデスクトップ機を圧倒するのである。これは「System Storage」のスコアからも明らかだろう。
「Creativity」と「Computation」では,ビデオのトランスコードがテストに含まれる。そのため,Sandra 2012を用いたテストで明らかになったビデオエンコ―ド用固定機能の性能がA10-4600Mのスコアを大きく引き上げたというわけである。
 |
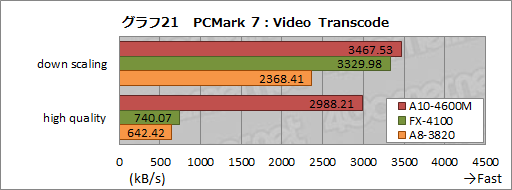
ビデオトランスコードについて,もう少し細かく見てみよう。グラフ21はComputationに含まれるトランスコードテスト「Video Transcode」の結果をグラフ化したものだ。
2つのテスト条件ではいずれもA10-4600Mがトップスコアを示しているが,とくに,720pビデオのトランスコードを行う「high quality」では,FX-4100に対して約4倍,A8-3820に対して約4.7倍という大差を付けており,これが“効いた”可能性が高い。
 |
ちなみにA10-4600Mでは,電源オプションを「高パフォーマンス」にしたスコアも取得してみたが,総合スコアは3261で,やはり「バランス」と比べると多少下がった。PCMark 7で対象となっている一般的なWindowsアプリケーションを利用するにあたっても,電源オプションは「バランス」にしておいたほうがいいようだ。
……というわけで,いろいろな事情からスコアが跳ね上がるA10-4600Mだが,「だからPCMark 7のスコアは無意味」かというとそういうわけでもない。ハードウェアエンコーダは,使う人にとっては非常に便利であり,その性能の高さはユーザーの使い勝手の向上につながるからだ。
だが,CPU性能の違いがPCMark 7では分かりづらいのもまた確かなところであり,そこは,ほかのテストで明らかにすべきだろう。今回は,「AIDA64」(Version 2.30.1938」とSandra 2012を用いて,CPUコアやメモリ周りのテストを行ってみたいと思う。
テストにあたっては,3製品の違いをよりはっきりさせるため,クロックを揃えることにした。A10-4600MでBIOSからCore C6 StateとTurbo COREを無効化すると,ベースクロックである2.3GHzに動作クロックが固定されたので,FX-4100とA8-3820でもベースクロックを2.3GHzとし,さらにCore C6 StateとTurbo COREをも無効化した次第である。
さて,まずはCPUの演算性能だが,今回はAIDA64を用いて検証してみる。というのもSandra 2012は,CPUがサポートする命令セットを自動的に判断して切り替えてしまうためだ。
Sandra 2012は内部でどのような処理を行っているか詳しく分からないため、命令セットが切り替わったスコアに果たして同列で比較していいものか判断しづらい。その点AIDA64の場合は,使う命令セットこそ変わるものの,テストにどのようなアルゴリズムを使用しているかが公開されているので,同列で比較しても問題ないだろうと考えた次第である。
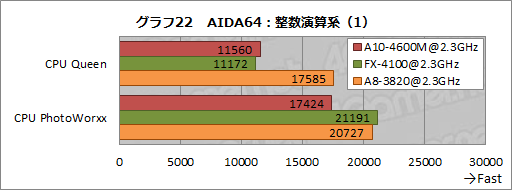
グラフ22は,そんなAIDA64の整数演算系テストから,「CPU Queen」「CPU PhotoWorxx」の結果を抜き出してグラフ化したものだ。
CPU Queenは,整数演算を駆使する古典的な問題「N-Queen問題」(※碁盤目状となるn×nのボードに,縦横斜めに移動できるチェスのクイーンn個を互いに攻撃できないよう配置するパターンがいくつあるかを求める問題)に関するテストだが,ここではA10-4600MとFX-4100が同程度のスコアを示し,Starsコアを採用するA8-3820がトップを取る結果になった。
一方,「CPU PhtoWorxx」だと,FX-4100がトップで,同じBulldozerアーキテクチャのA10-4600Mは振るわない。CPU PhotoWorxxは整数演算を用いたイメージ加工のアプリケーションで,マルチスレッドが効くとされる。となればコア間のデータのやり取りも多いはずで,FX-4100に搭載される8MBの共有L3キャッシュが奏功したと見るべきだろう。同じCPUアーキテクチャでも,L3キャッシュが省略されている分,A10-4600Mのスコアはやや低いところに落ち着いたと見てよさそうだ。
 |
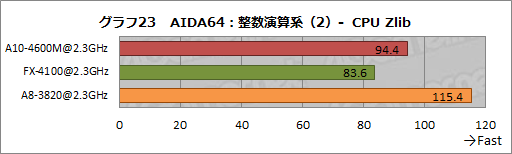
データ圧縮を行うテスト「CPU Zlib」では,FX-4100よりもA10-4600Mのほうが若干高いスコアを記録するが(グラフ23),その理由は何ともいえないところ。評価機に搭載されるSSDが招いた結果かもしれないし,AMDが言う「IPCの向上」が威力を発揮した可能性もあるが,構成が異なり過ぎているため,この違いから何かを言うのは難しい。
A8-3820のスコアが頭1つ抜けているのは,Starsコアの整数演算性能が高いからだろう。
 |
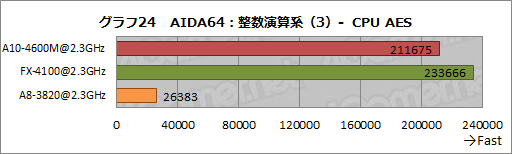
グラフ24,25は,AIDA64に含まれる暗号化関連のテストをまとめたものだ。
AES暗号化のテストとなる「CPU AES」は,Bulldozerアーキテクチャでハードウェアアクセラレーションが利用可能になったため,A10-4600MとFX-4100が揃ってA8-3820を圧倒した。
なお,本来なら,システムストレージにSSDを搭載するA10-4600MのスコアがFX-4100を上回ってもいいはずだが,逆になった理由は分からない。Trinity世代で何らかの手が入り,AESアクセラレーションの性能がやや低下したという可能性はある。
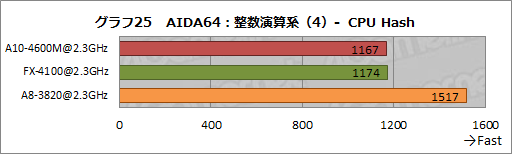
一方,代表的なHashアルゴリズム「SHA1」の処理性能を見る「CPU Hash」だと,A10-4600MとFX-4100のスコアがほぼ同じで,A8-3820がそれを上回るという,CPUコア性能を踏襲した結果になっている。
 |
 |
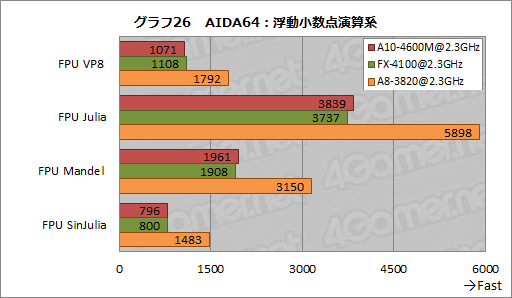
AIDA64における浮動小数点演算のテスト結果をまとめたグラフ26だと,A10-4600MとFX-4100のスコアは誤差範囲内でほぼ横並び。CPUコアの浮動小数点演算の性能にはほとんど手が入れられていないか,手が入っていても構成が異なる2つのマシン同士では差が分からない程度と見ていいだろう。
ここでも,K10系のA8-3820が頭1つ抜けたスコアを残している。
 |
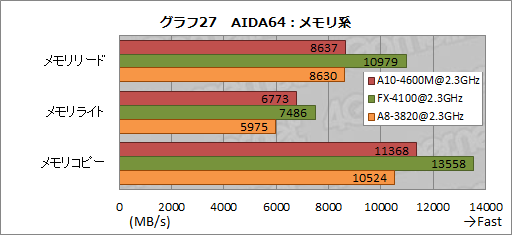
グラフ27は,AIDA64のメモリテスト結果だ。今回,メモリコントローラの設定は(ノートPCのレイテンシを設定できなかったとはいえ)DDR3-1600設定で揃っており,その意味で違いはないはずだが,FX-4100と比べるとA10-4600Mのスコアは低めである。
メモリライトとメモリコピーでA8-3820からスコアが向上しているため,APUとしてのメモリコントローラに改善が入ったとも取れるし,FX-4100と同じメモリコントローラだが,省電力化のために動作速度が抑えられ,A8-3820とあまり変わらない結果になったとも取れるところで,こうなった結果は何とも言えない。
ここは,デスクトップPC向けTrinityの登場を待って再テストする必要がありそうだ。
 |
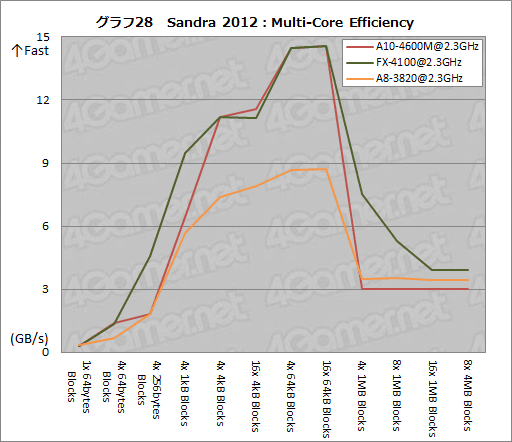
続いてグラフ28は,Sandra 2012から,CPUコア間の転送速度を見る「Multi-Core Efficiency」のテスト結果である。
A10-4600MとFX-4100を比較すると,4×1kB Blocks以下と,4×1MB Blocks以上とで,後者のスコアがやや高いが,これはおそらく,モジュール間で共有するL3キャッシュの効果が出ているためだろう。グラフは相似形だが,L3キャッシュを搭載しないA10-4600Mでは,4×1MB Blocks以上でスコアの変化が急峻になっている。
ただ,Starsコアとは明らかに効率が異なるとも見て取れる。A10-4600MではBulldozerアーキテクチャらしい特性を持っていると述べていい。
 |
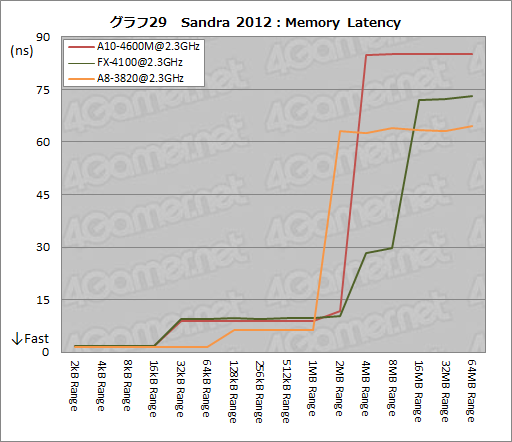
メモリおよびキャッシュのレイテンシを見る,Sandra 2012の「Memory Latency」。その結果をまとめたものがグラフ29で,ここでは,A10-4600Mにおいて,キャシュが効く2MB以内の領域でFX-4100よりもレイテンシが若干低くなっている点に注目したい。
AMDは,Piledriverアーキテクチャの改良点として「L1キャッシュのTLB(Translation Lookaside Buffer)大容量化」を挙げている。TLBはメモリアドレスの変換に利用され,TLBの大容量化でミスヒットが減れば,レイテンシは全般に低減するだろう。Memory Latencyの結果はそれが現れたものかもしれない。
一方,キャッシュから外れる領域では,メモリレイテンシの設定がデスクトップのそれよりやや大きいA10-4600Mが不利になる。これは致し方ないだろう。
なお,FX-4100と同じメモリモジュールを利用しているA8-3820でも,キャッシュから外れる4MB Range以上の領域で低いレイテンシを記録しているが,この理由は分からない。
 |
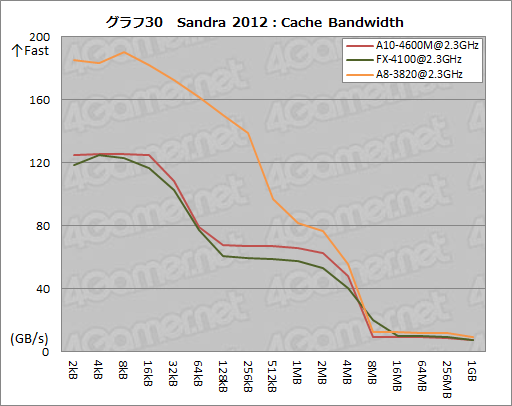
グラフ30は,Sandra 2012から,キャッシュの帯域幅を見る「Cache Bandwidth」の結果である。
ここでは,キャッシュがヒットする2MB以下の範囲でA10-4600MがFX-4100よりもわずかに高い帯域幅を示している。上で「PiledriverアーキテクチャではTLBの大容量化が図られた」と述べたが,ここでもその効果が出ている可能性はある。
もっとも,A8-3820はさらに高い帯域幅を示しているので,なかなか悩ましいところではあるが。
 |
以上,CPUの基礎テストを見てきたが,SSDの影響が排除しきれなかったり,メモリモジュールを共通化できていなかったりといった事情により,厳密な意味での横並び比較は難しい。
ただ,そのなかでも1つ言えるのは,「Piledriverモジュールの特性は,FXプロセッサで採用されるBulldozerモジュールと大きく変わらないか,変わっていたとしても劇的ではない」ということだ。TLB大容量化の影響で,とくにキャッシュ周りのパフォーマンスが上がっている形跡はあり,そのことがAMDのいう「IPCの向上」に多少なりとも寄与するものとは思われるものの,その効果は極めてわずかであり,過度な期待はしないほうがよさそうだというのが筆者の結論である。
4840mAhのバッテリーで
2時間半はゲームがプレイ可能か
試用したのがAMDの評価機で,そのままの形で市場に出るかどうかは疑わしいということもあり,ノートPCとしての使い勝手についてはほとんど触れてこなかったが,バッテリー駆動時間を調べているので,その結果を最後に掲載しておきたい。
 |
- Entertainment:3Dアプリケーションの実行とビデオ再生を交互に行い続ける
- Productivity:ワープロソフトによる文書編集とWebブラウジングを交互に行い続ける
- Balanced:ワープロソフトによる文書編集,Webブラウジング,3Dアプリケーションの実行,動画再生を交互に続ける
テストに用いられているモジュールは,PCMark 7と基本的には同じもの。バッテリー運用を考えればどれも負荷の高いワークロードだが,今日(こんにち)的なアプリケーションが揃っているともいえるだろう。
PowerMarkは基本的にノートPCメーカー向けのアプリケーションなので,テスト条件として気温や湿度などが指定されており,また,液晶パネルの輝度はキャリブレーションを行うことが推奨されていたりもする。ただ,温度や湿度はともかく,液晶パネルの輝度をキャリブレートするには光度計が必要で,さすがに筆者も所有していないので,今回は「電源オプション『バランス』設定のデフォルト」輝度を用いることにした。
ちなみに,試用機のバッテリ容量は4840mAhだった。UltrabookクラスのノートPCで良くかける程度の容量である。
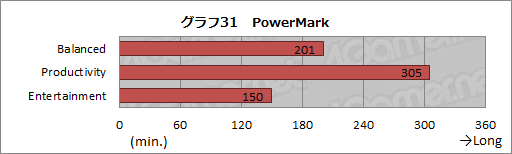
その結果をまとめたのがグラフ31で,最も長く保ったProductivityで5時間程度,Balancedでは3時間20分のバッテリー駆動が可能だった。Entertainmentだと2時間30分程度にまで短くなるが,これはバッテリー容量を考えるに「まあまあ」と言っていいのではなかろうか。
 |
多くの3Dオンラインゲームをプレイできる実力
安価なゲーマー向けノートPCの登場に期待
 |
CPU性能は,Piledriverをもってしても,Bullzoderからそれほどは変わっていないようで,Intel製CPUと比べると非力さが否めない。だが,ビデオエンコード&デコ―ド用固定機能や,OpenCLアクセラレーションが効くアプリケーションのプッシュなどを見る限り,AMDは,GPUや固定機能によって,CPUの非力さを補おうとしているようだ。
GPUとCPUとが互いに補う姿こそがAPU,そしてFusionの理想でもあるわけで,その方向に前進しているとは言えるかもしれない。本音を言えば,それでももうちょっとCPU性能はなんとかしてほしいところだが。
ゲーマーとして期待したいのは,安価かつ3DオンラインゲームがプレイできるノートPCが登場してくることだろう。Llanoの時代,少なくとも国内市場にそういうノートPCはほとんど登場しなかったが,Trinityではどうなるだろうか。
- 関連タイトル:
 AMD A-Series(Trinity,Richland)
AMD A-Series(Trinity,Richland) - この記事のURL:
(C)2012 Advanced Micro Devices, Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー