









ニュース
GLOBALFOUNDRIESとTSMCをどう使うのか。まもなく到来する「APU時代」のAMDロードマップを整理する
 |
しかし,45nmプロセス世代を境として,かつてPentium 4〜D時代にIntelを苦しめたリーク電流の問題が再び深刻化,新素材の採用や製造工程の最適化などが必要となり,半導体プロセスの進化はややスローダウンしている。AMDとNVIDIAが,直近のGPU製品で,2世代続けてTSMCの40nmプロセスを採用せざるを得なかったのも,ファウンドリ(Foundry,半導体製造廠)におけるプロセス技術移行のペースが鈍化しているためだ。
今後も,プロセス技術の進化は2年〜2年半か,それ以上のサイクルになると見られており,ファブレス半導体メーカーは,半導体製造戦略を見直さざるを得ない状況に置かれている。
それは,GLOBALFOUNDRIESの分離によってファブレスメーカーに戻り,CPUに最適化されたプロセスを持つGLOBALFOUNDRIESでCPUを,単体GPUの製造では圧倒的なシェアを持つTSMC(Taiwan Semiconductor Manufacturing Company)でGPUをと,ファウンドリを使い分けているAMDにとっても同様である。というのも,GLOBALFOUNDRIESとTSMCがいずれも,32nmプロセス世代への移行で苦戦を強いられているからだ。
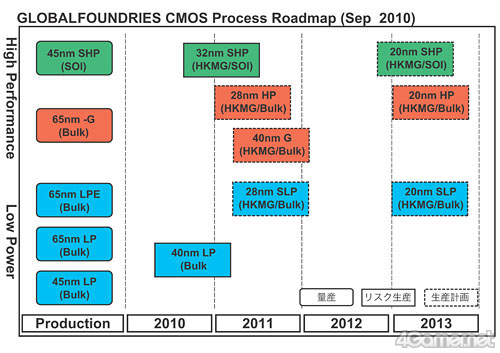
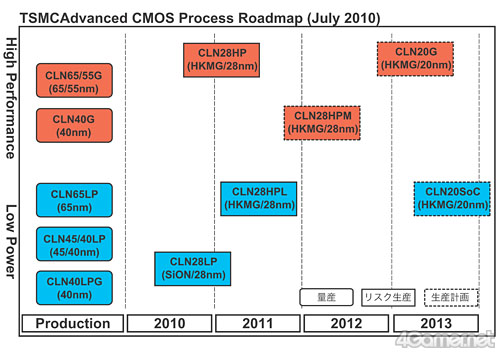
その背景にあるのは,「半導体製造プロセスの微細化に伴って,これまでトランジスタのゲート絶縁膜に採用されてきた二酸化ケイ素(SiO2)では,膜の厚さが薄くなりすぎてリーク電流が増えてしまう」という問題。そこでGLOBALFOUNDRIESとTSMCの両社は,32nmプロセス世代から,半導体ゲート電極の絶縁膜に,高誘電率かつ十分な厚さを実現できるHigh-k素材を採用すべく,開発を進めてきた。当初,2010年中に32nm/28nmプロセスへの移行を計画していた両社が,スケジュールの大幅な後ろ倒しを余儀なくされたのは,このHigh-kメタルゲートの採用に手こずったからだ。
ただ,45nmプロセスでHigh-kメタルゲートを採用済みのIntelに対抗するため,プロセスの進化を加速させる必要もある。そこでGLOBALFOUNDRIESは,当初計画していた32nmバルクプロセスなどの開発をキャンセルし,その先のハーフノード世代となる28nmプロセスの開発に注力。さらに,次のメジャープロセスとなる22nmプロセスもスキップし,ハーフノードたる20nmプロセスを採用することで,Intelとの差を詰める意向だ。そして,TSMCも,28nmプロセス以降で,GLOBALFOUNDRIESと同じ“ハーフノード戦略”を採ることを明らかにしている。
 |
 |
 |
 |
もっとも,APUやGPUの製造で,AMDがGLOBALFOUNDRIESとTSMCの2社を柔軟に選択できるようになるには,もう少し時間がかかりそうである。
というのは,両ファウンドリで,High-kメタルゲートの採用スタンスが異なり,半導体設計を共用できないからだ。
IntelがHigh-kメタルゲートの採用で他社に先行できたのは,高熱に弱いHigh-k絶縁膜を製造工程の最後のほうで積層する手法「Gate-Last」を考案できたことが大きい。TSMCが採用するのも,このGate-Lastである。
ただし,Gate-Last方式には,「トランジスタを生成するうえで非常に複雑な処理が必要となり,製造コストも跳ね上がる」という弱点がある。そこでGLOBALFOUNDRIESは,IBMやSamsung Electronicsとともに,従来の半導体製造手法と同じく,絶縁膜たるHigh-kメタルゲートを最初の段階で積層する「Gate-First」方式を採用した。従来どおりのトランジスタ製造工程を踏襲しつつも,半導体のレイヤーを積層していくうえで2000℃の高温にさらされるHigh-kメタルゲートに,別の素材による保護膜層を加えることで,より低コストでHigh-k素材の持つ高い絶縁性を維持できるようにしているのである。
一口に「28nmプロセス」といっても,GLOBALFOUNDRIESとTSMCでは,半導体の設計図ともいえるマスクの構成が大きく異なるわけだ。
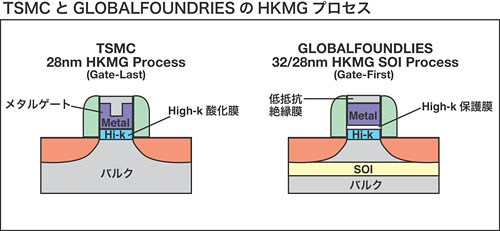 |
| TSMCとGLOBALFOUNDRIESにおけるHKMGプロセスの違い。TSMCはIntelと同じGate-Last方式を採用するのに対し,一方のGLOBALFOUNDRIESはGate-First方式を採用するため,半導体の設計図とも言えるマスクは,両社のプロセスに合わせて作らねばならない |
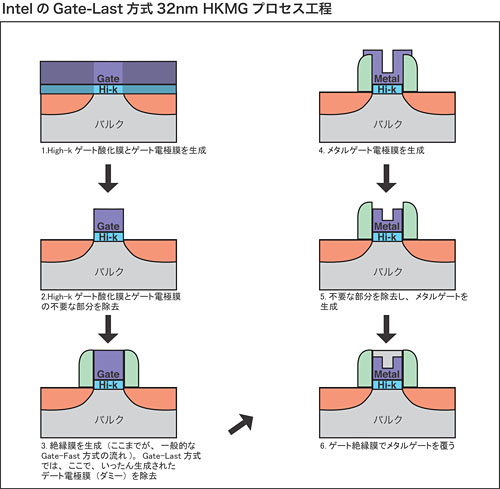 |
| Intelが採用しているGate-Last方式の32nm HKMGプロセス工程イメージ。TSMCが採用しているのもこれと同様の手法だ。一方のGLOBALFOUNDRIESは,従来の半導体製造プロセスと同じ,本図の前段階のみでHKMGを生成するGate-First方式を採用する |
そこでAMDは当面の間,CPUの製造でGLOBALFOUNDRIES,GPUの製造でTSMCをそれぞれ優先的に使うという,従来の手法を踏襲。そのうえで,APUやGPUの製造を徐々に両社へ広げることで,Akrout氏の言う「柔軟な」製造体制を築き上げようとしている。
AMDが,最初のAPU製品「Zacate」(ザカテ,開発コードネーム)や「Ontario」(オンタリオ,同)でTSMCの40nmプロセスを採用したのは,新しい半導体製造計画のなかで,40nmプロセス世代によるGPUの製造で実績のあるTSMCを優先した結果の一つといえよう。
同様に,高性能のCPU&APUの製造に当たって,もともとCPUの製造向けとして立ち上がっているGLOBALFOUNDRIESの優位性が揺らぐことはしばらくないと見られており,TSMCでのAPU製造は,省電力性能が優先されるエントリー向けモデルや,小型の組み込み向けモデルに限られそうである。
以上,石橋を叩いて渡っている印象を受けるAMDの製品製造計画だが,32&28nmプロセス世代におけるHigh-kメタルゲートの採用で半導体ベンダーが苦労していた歴史は,22&20nmプロセス世代でも繰り返される可能性がある。22&20nmプロセス世代では,半導体の設計図であるマスクの露光にEUV(Extreme UV:極端紫外線)などの新方式を採用する必要があるため,従来までのような,2年サイクルでのプロセス移行が確実になされるかは,蓋を開けてみるまで分からない。
そのため,「今後も,PCベンダーの製品サイクルに合わせ,毎年,高性能な新製品を投入し続けるためには,GLOBALFOUNDRIESとTSMC,2社とのパートナー関係を強化し,最先端プロセスをいち早く採用できる半導体製造体勢を築くことが不可欠だ」と,Akrout氏は説明している。
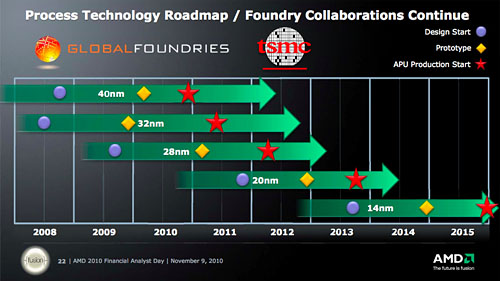
GLOBALFOUNDRIESとTSMCを使い分ける
AMDのCPU・GPU&APUロードマップ
ここからは,2010年11月に米国カリフォルニア州サニーベール市で開催された投資家向け会議「AMD Financial Analyst Day 2010」(以下,Analyst Day 2010)で公開された,AMDの最新ロードマップを,GLOBALFOUNDRIESとTSMCのプロセスロードマップと合わせて見ていこう。以下,とくに説明していない場合,製品名はすべて開発コードネームとなる。
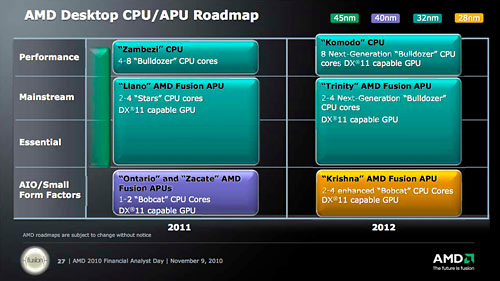 |
| Analyst Day 2010で公開されたデスクトップPC向けCPU&APUロードマップ。2012年には「Mainstream」市場向けAPUもBulldozerコアベースに移行するが,製造プロセスはLlanoと変わらない |
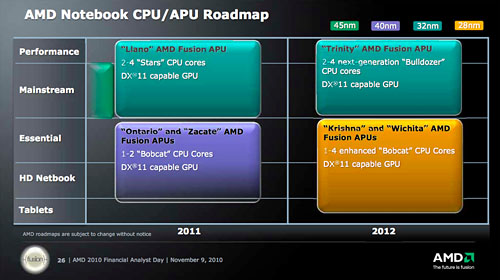 |
| 同じくこちらはモバイルCPU&APUロードマップ。Zacate&Ontario後継製品では,28nm HKMGプロセスをいち早く採用する計画だ |
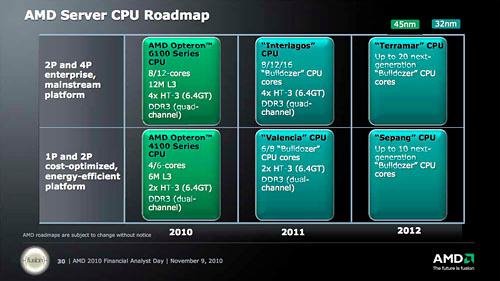 |
| サーバー向けCPUロードマップ。こちらは,2012年でも32nm HKMG SOIプロセスを採用する |
さて,AMDは,同社がメインストリームと位置づけるミドルクラス市場向けのAPU,「Llano」(ラノもしくはリャノ)の製造に,GLOBALFOUNDRIESが「32nm SHP」と呼ぶ,Gate-First方式のHi-kメタルゲートを採用した32nm HKMG SOIプロセス(HKMG:High-K Metal Gate)を用いる。
 |
 |
また,BulldozerコアベースのデスクトップPC市場向けハイエンドCPU「Zambezi」(ザンベジ)でも,Llanoと同じGLOBALFOUNDRIESの32nm HKMG SOIプロセスが採用される見込み。さらにAMDは,2012年の市場投入を予定している“拡張版”Bulldozerコアでも,32nm HKMG SOIプロセスを採用する計画だ。
同社でサーバー向け製品の技術を統括するCTO職にあるDon Newell氏は,この“拡張版”Bulldozerコアを「省電力性能を向上させ,低価格化を実現させる」コアと位置づけており,同コアを採用したミドルクラス市場向けAPUで,Llanoの後継となる「Trinity」(トリニティ)や,Zambezi後継の「Komodo」(コモド)では,低価格化も図られると説明している。
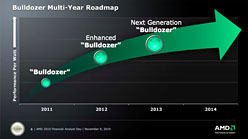 |
| Bulldozerコアは,消費電力あたりの性能向上に注力して進化させていくのがAMDの計画。2012年には,より廉価で高性能な拡張版BulldozerコアをTrinityなどに採用する予定だ |
 |
| Joe Macri氏(Corporate Vice President and Client Division CTO, AMD) |
一方,上でTSMCの40nmプロセスを採用すると紹介したZacateとOntarioだが,その後継で,28nmプロセスの採用が明らかになっている「Wichita」(ウィキタ)と「Krishna」(クリシュナ)でも,GLOBALFOUNDRIESの「28nm HP」プロセスが採用される見込み。AMDはこれにより,消費電力を維持したまま,クアッドコア化を実現する計画だ。
AMDでFusion担当CTOを務めるJoe Macri氏は,「最初のAPUとなるBobcatコアでTSMCの40nmプロセスを採用したのは,低消費電力性能の追求と,『チップの密度』を重視したため。Llanoではパフォーマンスを重視してGLOBALFOUNDRIESの32nm HKMG SOIプロセスを採用した」と説明する。
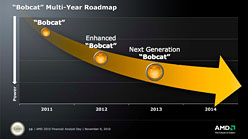 |
また,この点について,AMDに近い半導体業界関係者が,「AMDがBobcatコア最初の製品でTSMCを選んだのは,GPUコアの統合にかかるリスクを分散する意味も大きい」と指摘している点も押さえておきたい。
つまり,ZacateやOntrarioで,Llanoと同じGLOBALFOUNDRIESの32nm HKMG SOIプロセスを採用した場合,GLOBALFOUNDRIESにとってそれは,
- 初めての32nm HKMG SOIプロセス製品
- 初めてのGPUコア
- 初めてのCPU&GPUコア統合
という,二重・三重のリスクが生じることになる。そのため,AMDは,
- ZacateとOntarioでは,GPU製品の製造に長けたTSMCの40nmプロセスで,新アーキテクチャの小型CPUコアを組み合わせる
- Llanoでは,CPUの製造に長けたGLOBALFOUNDRIESで,現行のStarコア(=K10アーキテクチャ)をシュリンクしつつ,GPUを統合する
ことにして,半導体製造にかかるリスクを分散したわけである。
もっとも,Llanoの投入は当初の予定だと2011年第1四半期中だったので,2010年末時点の公式ロードマップにある「2011年半ば」というのが,遅れた結果なのは確かだ。この遅れは,半導体プロセスがらみの要因が大きいとされている。
なお,序盤で「当面はTSMC」と紹介したGPUの製造だが,28nmプロセスの製造でGLOBALFOUNDRIESに先行しているのもさることながら,「長年,高性能グラフィックスチップの製造を手がけてきたTSMCのほうが,ハイエンドグラフィックスチップの開発パートナーに向いている」(AMD関係者)という点が大きいようで,少なくともハイエンド品に関して言うと,「当面」の期間は,比較的長めになりそうだ。
ただ,APUの存在を考えると,すべてのGPU製品がTSMCで製造されるというのは考えにくい。AMDの関係者が「APUのGPUコアとなるエントリー製品を,GLOBALFOUNDRIESで製造する可能性はゼロではない」といった表現を行っていること,そして,ATI Technologies時代に,「ATI Radeon X1300」を,TSMCだけでなくUMC(United Microelectronics Corporation)でも製造していたことからすると,比較的早いタイミングから,APUに採用するGPUのベースとなる28nmプロセス世代のエントリー製品をGLOBALFOUNDRIESが製造する可能性も低くはなさそうである。
APUの進化を支えるのは高速バス技術
PCI Express 3.0対応も視野に
Analyst Day 2010で,AMDのRick Bergman上級副社長(Senior Vice President and General Manager, AMD)は,2011年以降のFusion戦略において,「最高のAPUを毎年供給すべく,省電力性能の向上や,最先端のグラフィックス機能や性能の実装を続けていく」とアピールしていたが,AMDはこれに合わせて,APU開発における具体的なポイントも明らかにしている。
 |
 グラフィックスコアやUVDユニットをCPUと統合することにより,より高速かつ低レイテンシのメモリアクセスを可能にするのもAPUのメリットとされる |
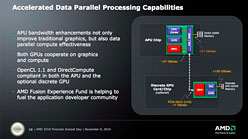 APUでは,単体グラフィックスカードと連係することにより,並列処理性能の引き上げも,今後は可能になるとされている |
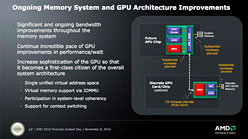 |
次にメモリ帯域幅だが,Joe Macri氏によれば,「TSV」(Through Silicon Via:半導体に小さな坑をあけ,そこに電極を通すことでプロセッサやGPUとメモリチップを立体統合する技術)を含め,「APUやGPUへのメモリ統合も視野に入れている」とのことで,さらなる“Fusion”で,機能や性能を向上させることを目指しているようだ。
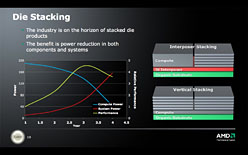 AMDは,半導体製造プロセスの進化だけでなく,複数のダイを1つにまとめるダイ・スタッキングも積極的に研究中 |
 TSMCが開発を進めているTSV技術。AMDは同技術をAPUやGPUに利用することを検討しているという |
AMDは,次世代GPUとなる「Southern Islands」(サザンアイランド)シリーズにおいて,Caymanで採用されたVLIW4アーキテクチャをベースに,28nmプロセスを採用することでさらなる高性能化とPCI Express 3.0対応を果たすと言われている。また,AMDに近いOEM関係者は,「AMDは,TrinityでPCI Express 3.0対応を果たす計画」とも明かしており,Moore氏が示す将来像は,決して遠くない将来の話だと言えそうである。
……ファブレス企業となったAMDにとって,CPUやGPUのロードマップに合わせたファウンドリの整備を進めるのは難しく,あくまでも,パートナーであるGLOBALFOUNDRIESとTSMCのプロセス移行計画を慎重に判断しつつ,製品開発していく必要がある。そのため,とくに半導体製造における要素技術が大きく変わらざるを得ない22nmプロセス以降,いまのペースでCPUやGPUをリフレッシュしていくためには,AMDのいう「柔軟」な製造体制へ,一刻も早く転換できるかどうかがカギとなるだろう。
- 関連タイトル:
 AMD FX(Zambezi)
AMD FX(Zambezi) - 関連タイトル:AMD E-Series,AMD C-Series
- この記事のURL:
キーワード
- HARDWARE:AMD FX(Zambezi)
- HARDWARE
- CPU
- AMD
- HARDWARE:AMD E-Series,AMD C-Series
- ニュース
- 業界動向
- ライター:本間 文
- GPU
(C)2011 Advanced Micro Devices, Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー