











イベント
西川善司の3DGE:GTC 2016の基調講演でNVIDIA CEOが語った5つのテーマと,そこから見えるNVIDIAの現状と将来
 |
そこで本講では,GTC 2016基調講演でHuang氏が語った5つのテーマごとに,それぞれの概要を説明しながら,NVIDIAの戦略を考察してみたい。
 |
開発者を支援するNVIDIAの技術サポート
最初のテーマは,NVIDIAのハードウェアを利用する開発者に向けて,同社が提供しているソフトウェアソリューションについてだ。Huang氏はこうしたソフトウェア群のことを,「NVIDIA SDK」と呼んでいる。
開発者向けソフトウェアの充実は,NVIDIAが競合他社よりも秀でている点のひとつで,早くから力を入れていた要素である。かつてのプロセッサメーカーは,ハードウェアを開発製造して販売することに注力するのが一般的で,その他のサービスといえば,ドライバーやツール類を適当なタイミングでアップデートしたり,開発者向けの情報ページやカンファレンスを通じて情報を提供する程度であった。
NVIDIAは,そうした要素だけでなく,早い時期からゲームエンジンメーカーや有力ゲームスタジオに接近して,業界が必要とする技術の収集を行い,GPU開発における性能チューニングに反映したり,NVIDIA製GPUを効果的に使うためのテクニックを広く提供したりという活動を行っていた。NVIDIA製GPUが,初代XboxやPlayStation 3に採用されたことが,こうした活動の追い風となったといってもいい。
そして現在,NVIDIAのゲームグラフィックス関連技術は,「GameWorks」としてまとめられ,業界内では実用的なグラフィックス技術の教科書的存在になりつつある。
 |
盛り上がりを見せている仮想現実(以下,VR)エコシステムについては,VRコンテンツ開発者向け支援ライブラリとして「VRWorks」を提供。こちらも「Unreal Engine 4」(以下,UE4)や「Unity」といった著名なゲームエンジンに採用されるといった実績を築きつつある状況だ(関連記事)。
 |
プロフェッショナルグラフィックス業界向けにNVIDIAは,「DesignWorks」を投入している。GameWorksが,主にゲーム開発者向けのライブラリであるように,DesignWorksは,ワークステーション向けGPUであるQuadro向けの業務用グラフィックスソフトウェアを開発する開発者に向けたものだ。
とくに,DesignWorksにはレイトレーシング関連の技術が多く含まれている。リモートレンダリングにも対応したクラウドレンダリングソリューションの「Iray」や,グラフィックワークステーション単体でGPUによるレイトレーシングが可能なプログラマブルレイトレーシングエンジン「OptiX」,これらレイトレーシングエンジン向けの材質表現言語「MDL」(Material Definition Language)といったものが,そうした技術の一例といえよう。
 |
科学技術計算分野向けに提供するSDKは,「ComputeWorks」と呼ばれている。これは,NVIDIAのGPUコンピューティング向け開発環境である「CUDA」に関連した技術支援ライブラリ群のことだ。
CUDAは,GTC 2016で発表となったPascalアーキテクチャベースのGPUに対応する最新版の「CUDA 8」が,2016年6月に登場予定であるなど(関連記事),精力的なアップデートを続けている。
 |
NVIDIAが近年力を入れている自動運転技術に向けた技術支援ライブラリとして登場したのが,「DriveWorks」だ。
GTC 2016の展示会場で,DriveWorksのデモを見た限りでは,自動運転に必要なカメラ画像や各種センサー情報から対象物を知覚して認識する処理系「コンピュータビジョン」をライブラリ化したもののようで,DriveWorks自体が,直接自動運転を実現するわけではないらしい。
 |
ちなみに,DriveWorksに含まれるコンピュータビジョン技術は,かなり高度なもので,カメラ映像から3D地図を構築するライブラリなどは,地形の測定用途や災害救助用途など,自動運転以外にも多彩な応用が利きそうで,価値が高いものとなりそうだ。
5つの“Works”を説明したHuang氏は,最後にWorksのつかないNVIDIA SDKとして,「JetPack」を紹介した。
これは,組み込み向けSoC「Tegra」を搭載する開発キットであるJetsonシリーズ向けの開発支援ライブラリである。ComputeWorksやDriveWorksをTegraで動作するようにまとめたサブセット版といったもので,DriveWorksで開発した自動運転技術を実験するといった用途にも使えるという。
 |
Huang氏は,「我々の強みは,ウルトラハイエンド(※TeslaやGeForce)から組み込み向け(※Tegra)まで,すべて同じCUDAベースのGPUで構成しているところにある。ワークステーションクラスのプラットフォームで開発した機械学習システムを,組み込み向けプラットフォームでも走らせることができるのは,NVIDIAのシステムだけ」と強調していた。ようするに,NVIDIAのシステムを使えば,基礎実験をPCやスーパーコンピュータ上で行い,その成果を最適化したランタイムをJetsonで走らせるといった具合に,製品に近い現実的な環境での実験が行えますよというわけだ。
この「一貫したアーキテクチャプラットフォームを持つ」というメッセージを,Huang氏は基調講演の中でたびたび繰り返していた。
VRの本命はプロ用途にあり?
Huang氏の講演における5大テーマの2つめは「VR」。それも,ゲームのような一般消費者向けのそれではなく,ビジネスやプロフェッショナル用途のVRへの対応だ。
VRに対する注目は,一般消費者の間にも高いのだが,製品としての広がりは,しばらくの間,先進的なユーザーに留まるという見方もある。理由は単純で,「Rift」や「Vive」といったVR対応ヘッドマウントディスプレイ(以下,HMD)は,600〜800ドル(税,送料別)と高価なうえ,ハイスペックのPCまで必要とするからだ。
 |
 |
一般消費者向けVR分野には,VRWorksやGeForceの提供という形で支援していくのと同じように,NVIDIAは,プロ向けVRに向けても,GPUとソフトウェア技術を提供することをHuang氏はアピールしたのである。
具体的なソリューションとしてHuang氏が説明したのは,「Iray VR」だ。
繰り返しになるが,Irayとは,NVIDIAが提供するクラウド対応のレイトレーシングエンジンである。Iray VRは,それをVRに対応させたものというと,イメージしやすいだろうか。しかし,レイトレーシングの仕組みやメカニズムを知る人は,「VR対応レイトレーサーなんてできるのか?」と思うかもしれない。
結論からいうと,Iray VRはリアルタイムなレイトレーシングを行うわけではなく,事前に行ったレイトレーシングの結果をもとに,リアルタイムレンダリングを行うものである。HMDを被ったユーザーの視点移動に連動した映像を表示することはできるが,その映像に映し出されたものは,いっさい動かない。これは,レイトレーシングエンジンであるIrayを,リアルタイム性が要求されるVRに対応させるうえで,妥協を強いられたポイントなのである。
 |
Iray VRでは,事前に構築した静的なシーンに対して,数百ものポイントにライトプローブ(※観測点)を設置して,そこにやってくる全方位の光を収集するのだという。言うまでもないかもしれないが,光の収集にはレイトレーシングを利用する。イメージ的には,全方位環境マップのようなものをレイトレーシングで生成するといったところか。Huang氏は講演の中で,「その解像度は4Kである」と述べていたが,とにかく,それを数百か所分だけ計算するのだ。
ちなみに,観測点は自動的に置かれるのか,エンジニアやアーティストが手動で設定するのかは説明がなかった。
膨大な数の4K全方位光情報マップ(以下,光情報マップ)は,Quadro M6000のグラフィックスメモリに置かれる。なぜQuadro M6000かといえば,1枚のグラフィックスカードで24GBという,現時点で最大容量のグラフィックスメモリを搭載するからだ。この光情報マップは,VRコンテンツを実行するときに,すべてオンメモリになければならないのである
VR HMDでこのコンテンツを実行するときには,まず,視点位置から顔の向いている方向に向けて,そのシーンのデプスレンダリングを行う。ここでいうデプスレンダリングとは,シーンの奥行き値(Z値)をフレームバッファに描画することで,その結果は,視点からシーン内に存在するオブジェクトまでの距離をピクセル単位の白黒濃淡表現で描いたものとなる。黒いほど視点に近く,白いほど遠くになるという仕組みだ。
さて,このままではただの白黒映像なので,光情報マップを使って画面座標系のライティングをリアルタイムで行う。これをリアルタイムで処理するために,光情報マップはオンメモリに置く必要があるのだ。また,光情報マップはプリレンダリングで生成するので,シーン内で描かれるものを動かせない。
こうして,「静的なシーンに限定されるが,極めてフォトリアルなVR体験」をIray VRで実現できるというわけだ。レイトレーシングは光情報マップの生成時にしか使われず,VRコンテンツの実行時には,普通のリアルタイムレンダリングパイプラインしか活用していない点が,注目すべきポイントといえよう。
 |
こうしたVRコンテンツが役に立つ用途の1つが,デザインレビューだ。
たとえば,建築物であれば,実際にその建物を建てたら,外観や内部はどのように見えるかとか,窓の配置による違いや,照明の種類を変えたときの光具合といったものを,VR HMDで体験することで,現実に近い形で評価できるのである。
自動車のデザインも例に挙げられていた。フェンダー位置から立って見下ろしたときに,ボディの外装デザインに一貫性があるように見えるかとか,ステアリングとシフトレバーの位置関係は適切か,着座位置からの見晴らしはどうかの評価などに利用できる。
シーン内オブジェクトが動き回る必要はないが,非常に正確なライティングが必要なコンテンツで,そうしたシーンを自在に見て回れるVR環境を構築することが,これからのプロフェッショナル向けVRに求められており,それを実現するソリューションがIray VRであると,NVIDIAはアピールしているわけだ。
 |
 |
 |
GP100は機械学習と科学技術計算にフォーカスして生まれたGPU
講演で3つめのテーマは,新GPUの「Tesla P100」だ。開発コードネーム「GP100」として知られるPascal世代のGPUコアを採用したTesla P100の詳細は,NVIDIAによる技術解説セッションをもとにした解説記事を掲載済みなので,詳細はそちらを参照してもらうとして,本稿では後段の理解に必要な要素を説明しよう。
 |
GP100には,機械学習型AIを効率よく実行するために重要な改良として,半精度浮動小数点(FP16)演算の効率化している。
たとえば,「Convolutional Neural Network」(畳み込みニューラルネットワーク,以下,CNN)と呼ばれる機械学習の方式では,大量のデータを畳み込み(Convolution)演算で反復的に処理し,その結果を蓄積することでAIは学習していく。この畳み込み演算は,大量のデータに対して積和算を行うことに等しいので,機械学習型AIにGPUが活用されるようになったという背景がある。
 |
さて,こうした機械学習で取り扱うデータには,画像や音声,各種センサーのデータといったものが使われるのだが,これらのデータサイズは,16bitのFP16で十分という場合が多い。そこでGP100では,単精度浮動小数点(FP32)演算器でFP16を2セット同時に処理できる機能を導入して,機械学習の効率を大きく高めているのだ。
ちなみに,FP32の演算器でFP16を2セット同時に処理する機能は,SoC(System-on-a-Chip)の「Tegra X1」で導入されたものである。
GP100とGM200のスペック(表)や演算性能を比較すると,CUDA Core数が16%増えたことと,動作クロックが1.33倍になったことにより,FP32の演算能力は7TFLOPSから10.6TFLOPSへと,1.5倍ほど向上した。これだけでも大きな向上ではあるが,FP16は新機能の効果もあって,7TFLOPSから21.2TFLOPSと,約3倍もの性能強化を実現したとのことだ。
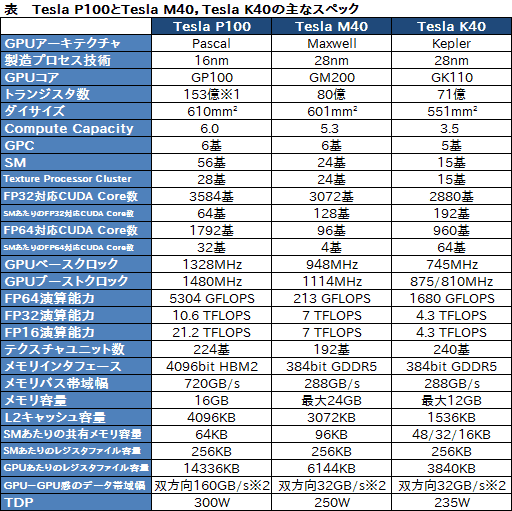 |
今回の基調講演の中では,機械学習型AIに関わるFP16の改良のみを説明していたが,実のところGP100は,倍精度浮動小数点(FP64)演算器を搭載したことで,FP64の演算性能も大きく向上している。この特徴は,科学技術計算や構造解析,各種シミュレーションといった伝統的なHigh Performance Computing(HPC)用途で威力を発揮することになるだろう。
NVLinkでRNN学習が加速する
4つめのテーマとなったのは,「Deep Learning Supercomputer」(深層学習向けスーパーコンピュータ)こと,「DGX-1」の発表であった。
DGX-1は,Tesla P100を8基とXeonを2基搭載する4Uサイズのラックマウントサーバーである。サイズは444(W)×866(D)×131(H)mmとのことで,なかなか巨大なシステムだ。価格は1台で12万9000ドル(約1400万円)となっている。
 |
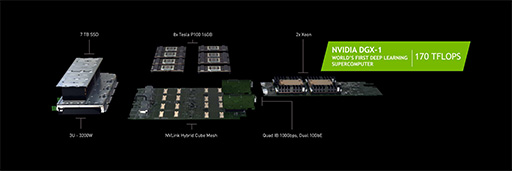 |
Tesla P100の相互接続には,GP100が備えるプロセッサ間接続用インタフェースの「NVLink」を使用する。1基のGP100が備えるNVLinkは,4プロセッサまでの相互接続に対応し,4基のTesla P100を1つのクラスタとして扱う。8基のTesla P100を搭載したDGX-1では,2クラスタの構成となる。
 |
 |
Huang氏は,機械学習用途におけるNVLinkの有効性について説明した。
音声や文章のような一次元データを取り扱うのに有効な機械学習型AIの形態に,「Recurrent Neural Network」(RNN)と呼ばれるものがある。
たとえば英語の場合,「I」(私)のあとには「am」や「was」が続く確率が高いが,もし,「I」の前に「When」があれば,「When I」となるので,「am」ではなく「was」へ続く可能性が高い。このように,データ同士の相関性を学習して動作するAIが,RNN型AIである。言語認識や翻訳,作文といった用途には,RNNが適しているそうだ。
こうした一次元データの学習には,認識モデルを並列実行する「Model Parallel」型処理と,複数の一次元データを並列で学習させる「Data Parallel」型処理という二通りのやり方がある。複数のGPU同士がNVLinkで高速に相互接続され,GPU内に大容量のキャッシュメモリを備えるGP100であれば,より複雑で大規模なRNNを効率よく学習させて,AIを構築できるというのが,NVIDIAの主張というわけだ。
 |
講演では言及されなかったが,NVLinkは,リアルタイムグラフィックス用途にも有効な技術である。NVLinkを持たないIntelやAMDのCPUとは接続できないが,GP100同士の接続には利用できるので,1枚のカード上に2基のGPUを搭載した「GeForce GTX TITAN Z」(GK110×2)のような製品に利用できるはずだ。
今までのデュアルGPU搭載カードでは,GPU間の接続にPCI-Expressを利用していたが,GP100なら,双方向で最大160GB/sという高速な専用バスで接続できるのだから,SLIの効果が向上すると期待できる。
余談気味になるが,グラフィックスカード2枚をPCI-Expressスロットに挿す2-way SLIでは,2つのGPU間にPCI-Expressバスが入るため,NVLinkは使えない。仮定の話だが,現行のSLIブリッジを刷新してNVLinkベースの技術でカード同士を直結する手段が用意されれば,GP100搭載グラフィックスカードを2枚による2-way SLIでも,NVLinkの恩恵が受けられるかもしれない。
自動運転はホビーの領域まで降りてくるのか?
5つめのテーマは,機械学習と並んでNVIDIAが精力的に取り組んでいる自動運転の話題だ。この分野における主役は,Pascal世代のGPUを搭載する自動運転技術の開発用プラットフォーム「Drive PX2」である。
 |
冒頭の「5つのWorks」でも触れたが,「NVIDIAアーキテクチャであれば,機械学習の基礎実験から,構築した学習データによる実車での訓練までを,一貫したソフトウェア環境,ハードウェアプラットフォームで行える」と,Huang氏は繰り返したうえで,自動運転技術の最新動向を説明した。
 |
Huang氏の話で,とくに興味深かったのは,NVIDIA自身がDrive PX2を使用して,「DAVENET」と呼ぶ自動運転プログラムを開発しているというものだ。自動運転技術の開発支援ライブラリであるDriveWorksには,さまざまな機能モジュールが含まれているわけだが,自前の自動運転実験でそれらの開発を行っているということらしい。

自動運転の話題で注目すべきは,Huang氏が用いた「HD(High Definition) Mapping」(高解像度マッピング)というキーワードだ。
自動運転では,各種センサーやカメラなどで車載AIが周囲を認識し,その状況に応じて車を運転する。だが,目的地に向かって走るには,それだけでなく,カーナビゲーションシステム(以下,カーナビ)によるルートガイド機能も不可欠だ。
カーナビは,GPSを使った自車の位置計測と,地図データの照合を組み合わせるものだが,GPS電波を受信できない場合や,入り組んだインターチェンジでの移動では,上から見下ろした二次元の地図データだけでは,適切なルート選択が難しくなることもある。自動運転でもそれは同様だ。
そうであるなら,自動車視点の高精度な3D地図データを,自動運転車自体に構築させて,自動運転制御で参考とするデータとして役立てようというのが,HD Mappingの基本的なアイデアである(関連リンク)。
 |
現在のカーナビメーカーは,交通量を計測するために,ユーザー車両の走行状況をクラウドサーバーに送信し,詳細な渋滞情報を把握する「交通量プローブシステム」を運用している。このようなシステムをリアルタイムの3D計測データ取得にまで拡張するのが,HD Mappingともいえよう。
HD Mappingによるリアルタイム地図は,GPSの位置情報が取得できない状況や,二次元地図ではルートに沿った走行が難しい状況に対応するために役立つだけではない。ルートのかなり先にある落下物の存在や,道に空いた穴,突然起きた車線減少について事前に把握することもできる。つまり,自動運転車が持つカメラやセンサーによるリアルタイムの状況把握能力を,地形データで補佐することにも役立つのだ。
 |
自動運転の話題では,ゲームファンも興味が湧きそうな話が飛び出した。それは,Drive PX2を搭載した自動運転車で行うレース「Roborace」を開催するという予告である(関連リンク)。
Roboraceは,F1などを主催する国際自動車連盟(FIA)が企画しているもので,自動運転車だけが参戦できる「Formula E」カテゴリのレースになるという。車両は共通化して,搭載コンピュータもNVIDIAのDrive PX2に統一。参加10チームは2台の車をレースに参加させて,自動運転AIの運転能力だけでライバルチームと戦うわけだ。
 |
当然ながら,Roborace自体は豊富な予算を投入できる大企業と科学者といった,プロ同士の対決になるだろう。しかし,こうしたレースをスケールダウンしたものは,いずれ,ホビーの世界にも降りてくる。ラジコンカーのレースを自動運転で行うような遊びが,きっと生まれてくるはずだ。
PCで動くゲームエンジンベースのシミュレータでAIをトレーニングして,そのAIを実機のラジコンに組み込んでレースに挑む。そんなバーチャルとリアルのクロスオーバーで楽しめる遊びが実現すれば,かなり面白いことになりそうだ。
NVIDIAの戦略は何も変わっていない
「NVIDIAは時代に適合するために戦略を変えている」とする分析もあるが,今回の講演を俯瞰すると,根幹となるNVIDIAの戦略は,実のところ,あまり変わっていないと筆者は考える。
最近でこそ,あまり言わなくなったが,2000年初頭くらいまでHuang氏は,「すべての電子機器にGPUを搭載することが夢だ」と語っていた。その夢を実現するために,NVIDIAはいろいろなアクションを起こし,中には失敗したものもあったとはいえ,それをしのぐほどの成功を収めて,現在に至ったわけだ。
その現在の姿が,初期のNVIDIAが見せた「リアルタイムグラフィックス性能追求主義」ともいえる姿勢とは,あまりにも違う印象を受けるので「NVIDIAは変わった」と思われるのではないだろうか。
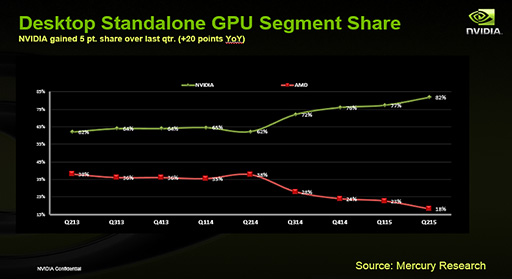
現在,デスクトップPC向け単体GPUにおける市場シェアは,NVIDIAが約8割で,AMDは2割という状況だ。PCゲーム用のグラフィックスカードはもちろん,ワークステーション用途のGPUでも,いまやライバルに圧勝している状況なのだ。
 |
であれば,現在,注力すべきなのは新分野である。そのNVIDIAが,新規開拓を目指して乗り出していったのが組み込みとGPGPUというわけだ。前者には,今のところ上手くいっているとは言い難いがTegraシリーズを,後者にはTeslaシリーズを投入していることは,4Gamer読者であれば周知の通りである。
幸運な偶然か,それともHuang氏の読み通りなのか。現在は,Teslaが機械学習用途で大きな広がりを見せ始め,Tegra的要素とTesla的要素の両方が求められる自動運転技術が急速な発展を続けている状況だ。TeslaとTegraを搭載したハイブリッド製品であるDrive PX2は,ある意味,現在のNVIDIAを象徴する製品といえるかもしれない。
研究所レベルで使うような大きなハイエンド向け製品から組み込み向けの小さな製品まで,一貫したアーキテクチャのGPUを搭載することに成功したNVIDIA。次はどの分野にGPUを搭載するのだろうか。
- 関連タイトル:
 GeForce GTX 10
GeForce GTX 10 - 関連タイトル:NVIDIA RTX,Quadro,Tesla

- この記事のURL:
キーワード
- 西川善司の3Dゲームエクスタシー
- HARDWARE:GeForce GTX 10
- GPU
- GeForce
- NVIDIA
- HARDWARE:NVIDIA RTX,Quadro,Tesla
- HARDWARE
- イベント
- ライター:西川善司
- GTC 2016
- GPU Technology Conference
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー