










連載
西川善司連載 / GeForce GTX 400アーキテクチャ徹底解説(前)

2010年が明けてすぐの1月上旬,NVIDIAは,DirectX 11世代の次世代GPUを,「GF100」という開発コードネームで発表した。その後,SNSを通じて,製品名が「GeForce GTX 480」「GeForce GTX 470」になるとか,北米時間3月26日に発表されるとかいった情報が少しずつ公開され,読者の期待度も高まってきている頃合いだと思うが,今回は,そんなGeForce GTX 400シリーズが持つ,アーキテクチャの詳細に,前後編の2回で迫ってみることにしよう。

まずは,GeForce GTX 400シリーズの基本事項を整理してみたい。「難しい話は苦手」という人も,本段落を読んでもらえれば,ざっくりと理解した気になれるはずだ。

今月中にも正式発表される予定のGF100ことGeForce GTX 480&470だが,今なお,動作デモは厳重に管理された環境でしか行われておらず,動作クロックなど,性能を推し量るのに必要な情報は出てきていない
GPU(Graphics Processing Unit)はもともと,3Dグラフィックスを描画するための専用ハードウェア,すなわち,3Dグラフィックスで同時多発的に発生する,頂点の座標変換や,ピクセルの陰影処理などにおけるベクトル計算を,CPUよりも高速に処理するためのプロセッサ「3Dグラフィックスアクセラレータ」として誕生している。
初期のGPUは,3Dグラフィックス処理において頻発する,典型的なベクトル計算に特化したハードウェア設計がなされた。そのため,「比較的シンプルなベクトル演算器を複数個実装する」形態からスタートしている。その後,3Dグラフィックスの表現力の強化が望まれるにつれ,シンプルなベクトル演算器だった演算コアは,より高度なソフトウェアを実行できるような,汎用プロセッサ的な機能を備え始めていく。また,演算コアの数自体も,製造プロセス世代が新しくなるにつれ,増加の一途を辿っていった。
そして,“GPUの汎用プロセッサ化”に,決定的な影響を与えたのが,プログラマブルシェーダ(Programmable Shader)だ。GPUの各演算コアにおけるプログラマビリティの向上は,プログラマブルシェーダ仕様(Shader Model,以下SM)バージョンアップの歴史に相当すると述べても,過言ではない。
さて,GeForce GTX 400シリーズは,2009年11月に発表されたGPGPU製品「Tesla 20-Series」の,コンシューマ向けバージョンという位置づけになる。従来,NVIDIAのGPUというのは,GeForceが先に発表され,その業務用製品(Quadro)やGPGPU製品(Tesla)がGeForceに続いてリリースされる流れだったのだが,GPGPU製品を同社の柱として位置づけたいNVIDIAにとって,力の入れ方は変わってきたということなのだろう。
GeForce GTX 400とTelsa 20-Seriesで共通して採用されるGPUアーキテクチャには「Fermi」(フェルミ,英語読みすれば「ファーミ」)という名が与えられているが,イタリア生まれのノーベル物理学賞受賞者,Enrico Fermi(エンリコ・フェルミ)氏の名字から取られたもの。GF100という開発コードネームは「『GeForce』ファミリーで『Fermi』アーキテクチャを採用した第『1』世代」を表している。
ちなみに,GeForce GTX 200シリーズが「GT200」という開発コードネームで呼ばれていたことを憶えている読者も多いと思うが,あちらは「『GeForce』ファミリーで『Tesla』アーキテクチャを採用した第『2』世代」の意だったりする(※Teslaアーキテクチャの第1世代は「G80」だが,実は,途中まで「GT100」として開発が進められていた)。
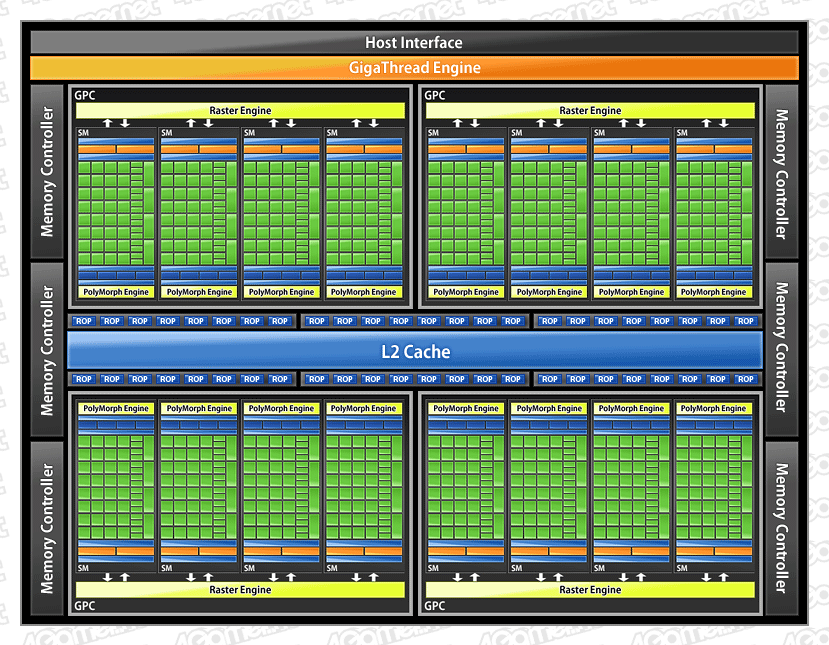
GF100(≒GeForce GTX 480)の全体ブロックダイアグラム
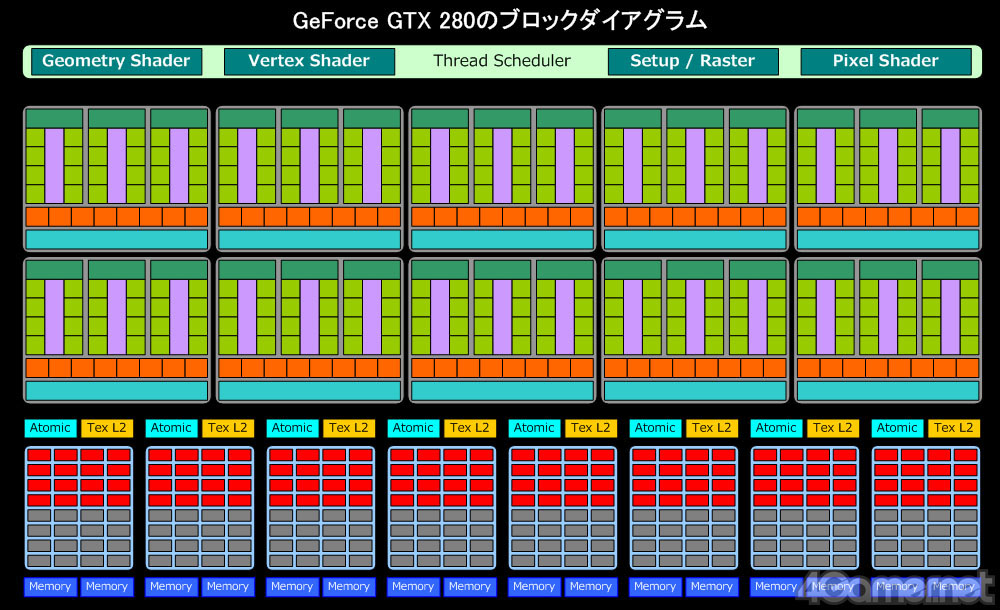
(参考)GT200こと「GeForce GTX 280」のブロックダイアグラム
以前「Streaming Processor」あるいは「Processor Core」と呼ばれていた汎用シェーダユニットについて,NVIDIAは最近,「CUDA Core」と呼ぶようになっているが,そんなCUDA Coreの数は512基。GT200(≒GeForce GTX 280)の240基と比べて,2倍以上という演算能力を獲得することとなった。
またGF100では,このCUDA Coreの管理階層構造がGT200から変更されている。
具体的には,GT200だと8基のCUDA Coreで1基の「Streaming Multi-Processor」(以下,SM)を構成する構造だったが,GF100ではこれが,32基のCUDA Coreで1SMを構成する構造に改められたのだ。
Fermiアーキテクチャの第一報で,筆者は「GT200では,3基のSMで『Thread Processor Cluster』(以下,TPC)を構成していたが,Fermiではこの階層構造がなくなったようだ」とレポートしていた。だが,FermiベースのTeslaはともかく,FermiベースのGeForceでは,GT200におけるTPCに相当する階層がちゃんとあった。
それが「Graphics Processing Cluster」(以下,GPC)だ。
GF100では,4基のSMで1基のGPCを構成し,GF100全体としては4基のGPCによる集合体として構成される。つまり,32 CUDA Core×4SM×4GPC=512 CUDA Core というわけである。
ところで,このGPCという階層は,長きに亘(わた)るGeForceの歴史において,かなり革命的であり,同時に,アーキテクチャ革新においてキモとなる部分になっている。というのもここには,「内部スレッド管理方法が再編されました」以上の意味合いが込められているからだ。

GF100のダイイメージ
GF100で,GPCは4基のSM,つまり128基のCUDA Coreで構成され,16基のテクスチャユニットが組み合わされるが,それだけに留まらない。詳細は後述するが,ポリゴンを画面上のピクセルに対応づけるラスタライザや,DirectX 11の新機能であるテッセレーション用となるエンジン「PolyMorph Engine」(ポリモーフエンジン,詳細は後編で)なども,GPC単位で共通して与えられている。4基のGPCに,機能面の差異はない。
GPCが単体GPUとして動作するのに足りていない部分があるとすれば,メモリ出力周り――ROP(Rendering Output Pipeline,またはRaster Output Processor)の部分だけだ。GF100で,各GPCからの出力は,4基のGPCで共有されたROPシステムとメモリインタフェースを介してメモリへ書き出される仕様である。
ちなみに,IntelやAMDのマルチコアCPUでも,メモリインタフェースは複数のコアで共有されるのが普通だ。その理論でいけば,GF100を「クアッドコアGPU」であると紹介してもまったく差し支えない。実際,NVIDIAも,GPCを説明するのに「ミニGPU」という表現を用いていたりする。
なお,GT200世代では,大枠で,TCPの多寡によって製品バリエーションが規定されており,例えば,GeForce GTX 280から,TPC×1(=24SP)を削減したものが「GeForce GTX 260」だった。その点,GF100では,GPCの数とSMの数,二段構えでバリエーションが展開される可能性がある。
1GPC当たりのSM数を削減するとして,特定のGPCだけSMを削減するのか,全GPCから同じ数だけ引いていくのかは分からないが,GF100系は,スケーラビリティのある設計になっていると言えそうだ。
以上,前世代比で大胆な規模拡大が行われたGF100だが,見かけ上,GT200よりスペックが落ちた部分もある。それはグラフィックスメモリインタフェースだ。GT200では512bitだったのに対し,GF100では384bitになっているのである。

2010年3月上旬にドイツで開催されたCeBIT 2010。その会場で展示されたGIGABYTE TECHNOLOGY製GeForce GTX 480カードの製品ボックスには,搭載グラフィックスメモリ容量が1536MBと記載されていた。1536は384の倍数である
ただ,この分は,GT200で採用していたGDDR3から,GDDR5へと,採用するメモリ技術をアップデートすることで補う。GDDR5では,GDDR3比で2倍のデータレートが得られるため,(実効帯域幅という観点では,一概にどちらが優秀とは言い切れないものの)仮に512bit接続のGDDR3と384bit接続のGDDR5を同一の動作クロックで比較した場合,384×2÷512=1.5 となり,後者のほうが広いメモリバス帯域幅を得られる。だから問題ないというのが,NVIDIAの考えなのだ。
GF100が搭載するメモリコントローラは6基。それぞれが64bitコントローラとなっていて,GPCとクロスバー接続される。
また,各メモリコントローラは容量768KBのL2キャッシュと接続されているが,この768KBというのは,GT200で用意されていた256KBの3倍。ただ,それよりも注目べきは,GF100で,L2キャッシュがライトバックに対応したという点である。要するに,GPCから出力されたデータは,まずL2キャッシュに書き出され,その後,メモリバスの空きタイミングなどを見計らって,システム側がバックグラウンドで自動的に,キャッシュシステムの内容をグラフィックスメモリへ書き出してくれるのだ。
L2キャッシュに載っているデータがメモリアクセス対象となる場合には,グラフィックスメモリへのアクセスを省略して,L2キャッシュへのアクセスを返すだけでよく,実質,L2キャッシュへのアクセスだけで“メモリアクセス”を終了できる。GT200時代,L2はTPCからのリードオンリーキャッシュだったので,ここは大きな革新点だといえよう。

GF100の全体ブロックダイアグラムを再掲。図でL2キャッシュを囲むようにROPパーティションが6基用意され,それぞれに8基のROPユニットが含まれる
ROPパーティションは従来のGeForceと同様,メモリコントローラの個数とペアとなっており,GF100では6基。各ROPパーティションには8基のROPユニットが内包されるので,合計では 8×6=48 ROPユニット ということになる。GT200だと32基,G80だと24基だったので,今回の増量は比較的多めだが,GF100では,上で紹介したライトバックキャッシュの効果が大きく,“プラス16 ROPユニット”以上のパフォーマンス向上が得られるだろうとNVIDIAは予測している。
ただ,気になる最終の動作クロックや価格は,現時点では非公開。これは3月26日と予告されている正式発表を待つ必要がありそうだ。

以上,現時点で明らかになっているGF100の概要は押さえてもらえたと思うが,ここからは,アーキテクチャを掘り下げていこう。
というわけで,ここからは視点をGPCに移す。GPCを起点として,よりミクロな方向へ,GF100アーキテクチャの深みに向かって探索していくことにする。
下に示したのは,GPC単体をクローズアップしたブロックダイアグラムだ。
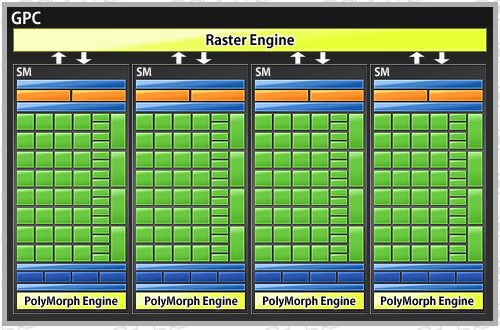
GPCのクローズアップ図。4基のSMを内包し,さらにRaster Engineまでを含むというのが,GT200にはない,GF100ならではの特徴である

GeForce GTX 280のブロックダイアグラム再掲。図で一番上にあるのがGigaThread Engineだ。「Raster」という項目が含まれる点に注目
先ほど簡単に説明したが,各GPCには,「Raster Engine」(ラスタエンジン)と呼ばれるエンジンユニットが1基ずつ搭載されている。
今までのGPUだと,Raster Engineは,上層の汎用シェーダコア――GT200でいえばTPC――の外,全体ブロックダイアグラムで言うなら「GigaThread Engine」側にあった。これが,GF100ではGPC側,すなわち汎用シェーダコア側に内包されるようになったわけだ。
従来,GPU全体で抱えるRaster Engineは1基。これをすべてのシェーダコアで共用していたわけだが,これで成り立っていたのは,ポリゴンを画面上のピクセルに対応づけるラスタライズ処理自体が定型化していて,専用ハードウェアで十分こなすことができたから。
ところが,DirectX 10時代から,このアーキテクチャに,ところどころ限界が見え始めた。DirectX 10でジオメトリシェーダ(Geometry Shader)が誕生したことによって,点と線分,三角形といったプリミティブ(Primitive,3Dグラフィックスの基本要素)の増減が可能になり,とくに「増」,GPU内の処理において,ポリゴン数が爆発的に増える頻度が高まってきたのである。
そして,DirectX 11世代で新設されたテッセレーションステージは,ポリゴンをプログラマブルに自動分割する仕組みなので,これまた,ポリゴン数をGPU内で爆発的に増やす機能を持っており,いきおい,ラスタライズ処理の負荷はさらに高まると予測される。
ラスタライズ処理のパフォーマンスアップを実現するには,Raster Engineをより強力なものにするのが直接的な対処法となるが,単一のRaster Engineを一点強化的にパワーアップするのは,プロセッサの設計的見地において効率的とは言いがたい。汎用シェーダコア数が多くなれば,それだけRaster Engineにも強力さが求められるが,エントリークラスのGPUなら,それほど強力である必要もないからだ。
それなら,Raster Engineを汎用シェーダコア(=GPC)側に入れてしまえば,GPC単位でRaster Engineの数が増減し,スケーラビリティを確保できる。それがGF100の実装なのである。

ちなみに,GPC内でジオメトリシェーダあるいはテッセレーションが多用されてポリゴンが増大した場合は,そのポリゴンをラスタライズする必要があるが,生成されたピクセルタスク群をGPC内で処理しきれない場合は,一度GigaThread Engine側に戻し,別スレッドの形で別GPCに発行することもあるという。つまり,あるGPC内で生成されたポリゴンを複数のGPCで手分けしてラスタライズしてレンダリングに取りかかることもあるということだ。
また,あるポリゴンの面積がものすごく大きく,ラスタライズしたところ,GPC内で賄えきれない数のピクセルタスクとなった場合も,一度,GF100のGigaThread Engine側に戻し,それらを別スレッドの形で別のGPCに発行することもあるという。
ミニGPUといわれるGPCだが,完全独立のGPUコアとして動作しているのではなく,いわゆるSLIなどよりも,深いレベルで互いに連係動作するのである。
1GPC当たりのSM数は前述のとおり4基。各SMはRaster Engineと双方向接続されている。前述したGigaThread Engine側に処理が戻るのは,いわば高負荷なケースであり,理想的なケースでは「頂点次元の各種処理→ラスタライズ処理→ピクセル次元の陰影処理」を1基のGPC内で実行できる。具体的に例示するなら,ジオメトリシェーダもテッセレーションステージもないDirectX 9世代のアプリケーションを動作させるに当たって,このマルチGPU構造は,並列動作コアとして効果的に働くということだ。

Raster Engineについて,もう少し詳しく見てみることにしよう。
GF100のRaster Engineは「Edge Setup」(エッジセットアップ),「Rasterizer」(ラスタライザ),「Z-Cull」(Z-カル),計3ユニットからなっている。

GF100のRaster Engine
Edge Setupは,あるポリゴン(※実際には点,線分,ポリゴンなどのプリミティブ。本稿では分かりやすくするためポリゴンと表現している)における各頂点の「画面上の座標」を求めると同時に,論理的に描画が不要なポリゴンであるかどうかを判断し,もしそうならば処理をスキップするユニットである。例えば,穴のない,閉じた3Dモデル上にあるポリゴンの場合,その面が視線方向を向いていない場合,「隠面」となるため描画を行う必要がなくなる。そのとき,いわゆる隠面消去を行うのが,このユニットだ。
Rasterizerユニットは,Edge Setupから受け継いだ「画面上の座標に変換した頂点」から,そのポリゴンが画面上のどのピクセルに対応づけられるかを計算して,ピクセルタスクを生成する仕事を担当する。
もちろんここで,Z値ピクセルの割り当ても同時に算出されるが,当該レンダリングにおいて,アンチエイリアシングが有効だった場合は,後段のMSAA(Multi-Sampling Anti-Aliasing)やCSAA(Coverage Sampling Anti-Aliasing)に配慮したZ値ピクセルの割り当ても行われる。例えば4x MSAAならば,4倍解像度のZ値ピクセルの割り当てが行われるわけだ。
なお,GF100が搭載するRasterizerユニットは1基が1クロックあたり8個のピクセルタスクを生成する能力があるという。

GF100用のテクニカルデモ「Supersonic Sled」より
最後のZ-Cullユニットは,Rasterizerユニットで算出されたZ値ピクセル群と,「ちょうど対応した描画先フレームバッファにある,Zバッファ内のZ値ピクセル群」とを比較して,ピクセル描画の可否判定を行う。ここで行う描画可否判定は,早期Zカリング(Early Z Culling)と呼ばれるもので,実際にピクセルを描画するときに行われるZ値可否判定(Z-Test)とは別モノである点に注意してほしい。
では,早期Zカリングとは何なのか。簡単に言えば,「明らかに描く必要のないピクセルを,早期に排除してしまおう」というプロセスで,4×4ピクセルのようなまとまったブロック(≒タイル)単位でのZ値可否判定を行うものだ。Rasterizerユニットから算出されたZ値ピクセル群の最小&最大値と,描画先フレームバッファ側のZバッファ内にある,対応するZ値ピクセル群の最小&最大値とを比較することで処理が進んでいく。
「どのみち最終描画時にZ値可否判定をやるのに,なぜ早期Zカリングなんてことをやるのか。二度手間ではないか」という疑問が出てくるのはごもっとも。この二度手間をあえてやるのは,「ピクセルシェーダの無駄な稼動を回避するため」だ。
ピクセルシェーダプログラムは年々,高度に複雑化してきていて,GPU側の“本心”としては,「なるべくピクセルシェーダに負荷をかけたくない」というのがある。一方,最終描画時のZ値可否判定は,ピクセルシェーダ処理を終えてからのものなので,ここで描画不要の判定が下されると,そこまでのピクセルシェーダの仕事がまったくのムダになってしまう。
そこで,ピクセルシェーダへ仕事を発注する前に,明らかに描画不要なピクセルの塊(≒ブロック,タイル)を排除する仕組みが組み込まれたのだ。

少し横道にそれた。戻って,視点をSMへ向けてみることにしよう。下に示したのは,SM単体にクローズアップしたブロック図である。

SMのクローズアップ
1基のGPCは4基のSMで構成されるが,4基のSMそれぞれは,32基のCUDA Coreを搭載する。
一つ一つのCUDA Coreはスカラプロセッサであり,1基の32bit浮動小数点(FP32)スカラ演算器と32bit整数(Int32)スカラ演算器で構成されている。
各CUDA Core内のFP32スカラ演算器は,Int32スカラ演算器と並列に動作でき,その演算精度もIEEE 754-2008準拠となった。ちなみにIEEE 754-2008とは,浮動小数点演算における“誤差の丸め方”の規定,演算エラー発生時の例外処理の仕組みなどを,近代のコンピューティング環境に合わせて規定した規格だ。
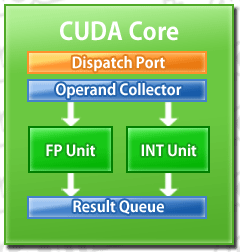
CUDA Coreのクローズアップ。図中「FP Unit」がFP32スカラ演算器,「INT Unit」がInt32演算器だ
GT200にあった,1SM当たり1基の64bit浮動小数点(FP64)スカラ演算器は,GF100では削除された。ただし,GF100ではCUDA Core内のFP32スカラ演算器で2クロックかけて(≒ループして)FP64演算をこなせるようになっている。専用演算器がなくなった代わりに,CUDA Coreの数で“力押し”できるようになったことで,総合的なFP64演算ポテンシャルは高められたことになる。
また,Int32演算器自体,GT200からリファインが施されており,64bit整数演算対応や,より高度な二進論理演算命令の追加などが行われている。二進論理演算関連では,ビットリバース,ビットカウント,ビットインサート,ビットフィールド取り出しなどが追加されており,汎用プログラミングにおいて必要な命令群はほぼすべてサポートされるようになった。
また,FP32とFP64両対応のFused Multiply Add(以下,FMA)命令に対応するのもGF100におけるCUDA Coreの大きな改良点となっている。
FMAとは,厳格な精度規定がなされた積和算手法のことだ。これまでは,例えば32bitの積和演算「A+B×C」において,B×Cの演算結果が32bit幅を超えた場合に,32bitに“丸めて”から最後のAを足していたのだが,FMAでは,内部の演算は高精度で行っておき,最後の和算のあとに1回だけ丸めを行って,誤差を最小限にする。
これは,従来の演算規格だったIEEE 754-1985から,新しいIEEE 754-2008規格へ準拠するにあたって求められている仕様変更で,基本的にはHPC(High Performance Computing)向けに実装された機能だ。3Dグラフィックス処理においても正確な頂点座標計算結果が得られるため,隣接するポリゴンが微妙にオーバーラップするような描画ケースにおいて,より正確な描画ができるようになると,NVIDIAはアピールしている。
各CUDA Coreが64bitアドレッシングに対応したことも,地味ながら大きな拡張ポイントだ。これも,主にGPGPU向けの拡張だと見られるが,この拡張によって,大規模なデータ空間を取り扱えるようになったのは大きい。演算精度の64bit拡張と相まって,プログラミング自由度という観点から,もはやCPUベースプログラミングとの格差はほとんどなくなったといっていいだろう。

演算器周りでは,1SMあたり4基の「Special Function Unit」(超越関数ユニット,以下 SFU)が実装されている点も,見逃すわけにはいかない。
SFUは三角関数,指数,対数,平方根,逆数などの高度関数演算を担当する演算器だが,これまでのGeForceで,「Interpolater」(インタポレータ,以下 補間ユニット)が担当していた各種補間演算も,GF100のSFUでは担当するようになった。
この「補間ユニットが担当していた処理系を汎用シェーダコア側へ持ってきた」のは,GF100が初めてではなく,2009年秋に発表されたATI Radeon HD 5000シリーズも同じ。AMDとNVIDIAの両社が,このタイミングでアーキテクチャ変更を行った直接的な理由は,DirectX 11におけるプログラマブルシェーダの新機能「Programmable Interpolation of Input」をサポートするためだろうが,ほかにも理由がある。
このあたりは,筆者の連載バックナンバー「ATI Radeon HD 5800徹底分析(2)〜理にかなったスペック強化」内,「消えたInterpolators」の段落で詳しく述べているので,詳細はそちらを参照してほしいが,ここでも簡単に述べておこう。
補間ユニットはテクスチャアドレスの補間計算を行うが,テクスチャヘビーなシェーダプログラムが動作したときに,単一の補間ユニットでは処理しきれず,ここがボトルネックになることがあった。それに対し,GF100のSFUはSM当たり4基だから,GPU全体で64基。補間ユニットのタスクをSFUで肩代わりすると,実質的な処理分散ができることになるというわけだ。
さて,SFUはそれこそ補間ユニットの代わりといった,“他”目的用途で活用される一面があるため,SM内で,CUDA Coreなどから完全に独立して動作できる仕様になっているという。
ちなみにSFUは,1基で1クロック当たり1スレッドの1個の基本命令を実行できるポテンシャルがあるので,単純な処理であれば,32スレッド(=1Warp)の実行は,32スレッド÷4SFU=8 の,8クロックで行える計算になる。

各SMは二つのWarp(※1Warp=32スレッド)の処理が行えるようになった
こうしたCUDA Core,SFU,そして後述する「Load/Store Unit」(ロード/ストアユニット,以下日本語表記)へ,実際の仕事発注を行うのが「Instruction Dispatch Unit」(命令発行ユニット,同)で,そのマネジメントを行うのが「Warp Scheduler」(ワープスケジューラ,同)になる。
GF100では,1SM当たりのCUDA Core数がGT200の8基から32基へと4倍に増加したことに合わせ,命令発行部分が並列化されており,GF100ならではの特徴の一つになっている。付け加えるなら,1SM当たり2Warp――1Warpはひとかたまりの32スレッド――の実行スケジューリングを行えるようになっている。
並列化された二つの命令発行ユニットに「同時発行できる命令の組み合わせ制限」はとくになく,整数演算命令同士,浮動小数点演算命令同士,あるいは整数演算命令と浮動小数点演算命令,ロード命令,ストア命令,SFU命令から,どの二つでもOK。ただし,64bit精度を取り扱う命令に限っては,同時発行がサポートされない。

……ここまで,あえて説明もないままに「スレッド」という言葉を用いてきたが,「GPUのスレッド」というものをイメージしにくい人も多いだろう。本連載でスレッドについて語ったことはなかったので,この機会に触れておこう。
「Dark Void」より。ピクセルシェーダに限定して話をすると,描画されるピクセルの一つ一つがGPUにおける1スレッドだ
(C)CAPCOM ENTERTAINMENT, INC,2010 All Right Reserved.
さて,CPUにおけるスレッドは「プログラム実行の単位」だが,データ駆動型プロセッサであるGPUにおいては,1データが1スレッドに相当する。単一のプログラムが,複数のデータ(=スレッド)に対して実行されるのである。
分かりやすくするため,ピクセルシェーダに限定して話を進めてみると,1スレッドは1ピクセルに相当する。先ほど,一つのWarpが32スレッドだと述べたが,これは要するに32ピクセルをひとまとめにしたものを指しており,GeForce(≒CUDA)アーキテクチャでは,ある一つのピクセルシェーダプログラムを,この32ピクセル(=1Warp)に対して個別に適用してやるというイメージになる。

2基の命令発行ユニットがCUDA CoreとSFUを分け合うイメージ
GF100では,1SMが2Warp処理を行え,各ワープスケジューラは,当該Warp(=32ピクセル)に対して適用するピクセルシェーダプログラムの1命令を取り出して実行を仕掛ける。
各命令発行ユニットは,それ自体が取り扱うWarp(=32ピクセル)に対し,命令実行を発動するために,CUDA Core,SFU,ロード/ストアユニットなどといった各種実行ユニットを起用することになるわけだが,一つ一つの命令発行ユニットが自由にできるのは,SM内の半分――16基のCUDA Coreと2基のSFUになる。換言すれば,2基の命令発行ユニットは,SM内に32基あるCUDA Coreと4基のSFUを“仲良く半分こ”しているというわけだ。
一方,16基のロード/ストアユニットは“半分こ”はされず,2基の命令発行ユニットですべてを共有し,使いこなす仕様となっている。メモリアクセスはプロセッサから見ると膨大な処理時間を要するため,このような設計になっているのだろう。
といったところで前編はここまで。後編となる次回は,GF100のメモリ階層システム,ジオメトリエンジンなどを題材に,さらなる深みへ潜っていく予定だ。乞うご期待。
- 関連タイトル:
 GeForce GTX 400
GeForce GTX 400 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation
