











連載
西川善司連載 / 「ATI Radeon HD 5800」徹底分析(2)〜理にかなったスペック強化

世界初のDirectX 11対応GPU,「ATI Radeon HD 5800」(以下,HD 5800)シリーズを掘り下げていく記事の第2回をお届けする。今回と次回は,HD 5800シリーズのGPUアーキテクチャ詳細を,じっくり見ていくことにしたい。


「(HD 4800シリーズと比べて)トランジスタ数とパフォーマンスは2倍に,そして最大消費電力は20%増に抑えることができた」と,Eric Demers氏(Chief Technology Officer for Graphics, AMD)

HD 5800シリーズの開発目標
AMDでグラフィックス部門の最高技術責任者を務めるEric Demers(エリック・デメル)氏は,HD 5800の開発に当たって課せられた目標について,「第一に,『DirectX 11仕様の完全実装』があった」としながらも,「同時に,既存のアプリケーション――DirectX 9/10.0/10.1対応アプリケーションにおけるパフォーマンス向上についても力を入れた」と述懐している。
開発目標性能としては,「『ATI Radeon HD 4800』(以下,HD 4800)シリーズとほぼ同程度の消費電力で,2倍の演算性能」を設定。歴代のATI Radeonシリーズも,完全なる世代交代に当たっては「前世代と同じ消費電力で,2倍の性能」という目標が設定されてきたが,この流れは変わっていないというわけだ。
開発プロジェクトは3年前からスタートしており,本社がある北米地域はもちろん,中国やインド支社のスタッフも合わせ,総勢数百名が開発に従事したとのこと。HD 5800シリーズのアーキテクチャは,「TeraScale Graphics Engine」と命名されてデビューしたHD 4800シリーズをベースとした「Terascale 2」と呼ばれているが,その名称からしても,タイミングからしても,基本的にはHD 4800シリーズのコアに続けて開発が行われていたものと考えられる。

それではここから本格的に,コアアーキテクチャであるTeraScale 2の詳細を見ていくことにしよう。
以下の話は,とくに断りのない限り,発表時点の最上位モデルである「ATI Radeon HD 5870」(以下,HD 5870)について語っていく。解説は,HD 5800というシリーズ全体に及んでいる場合と,HD 5870という製品に限定している場合とがあり,これを書き分けている点には注意してほしい。
さて,HD 5870のブロックダイアグラムは以下のとおりとなる。
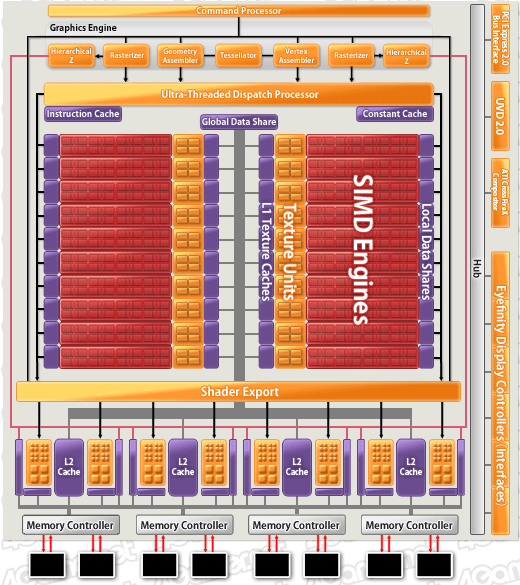
HD 5870のブロックダイアグラム
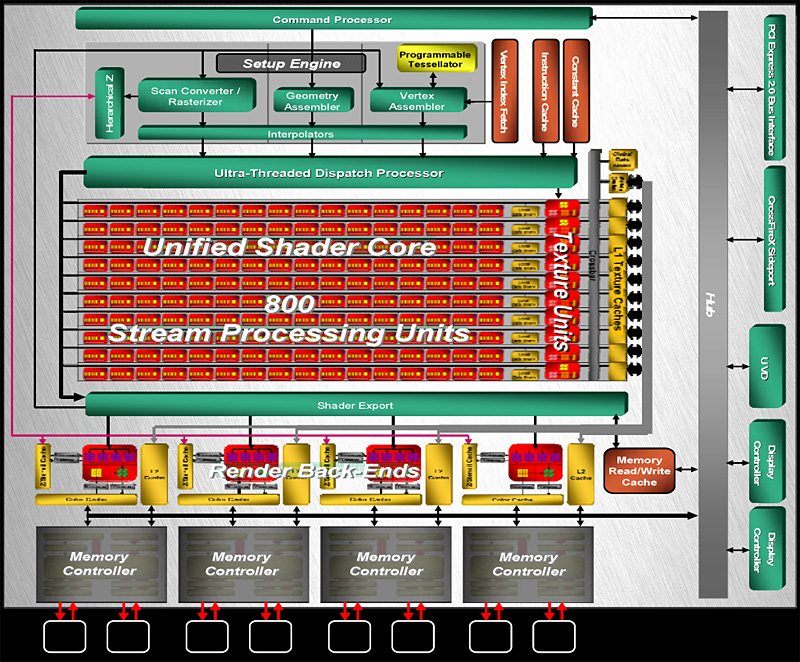
(参考)HD 4870のブロックダイアグラム
ブロックダイアグラムの解説に先立って,ATI Radeon HD 5000シリーズにおけるアーキテクチャ用語の定義を明確にしておこう。
ATI Radeon HDにおける最小の演算ユニットは,以前「Stream Processor」(ストリームプロセッサ)と呼ばれていたが,HD 5800のアーキテクチャに関連したスライドだと,「Stream Core」(ストリームコア)あるいは「Streaming Processing Unit」(ストリームプロセッシングユニット)となっている。AMD社内の技術者も,何人かはStream Coreと呼んでいたので,今後,Stream Processorという表記は,次第に使われなくなっていくのかもしれない。
本稿では便宜的にSPと略称するが,SPは32bitの浮動小数点(FP32)スカラプロセッサ。このSPを5基一組とし,分岐ユニット,汎用レジスタ群を合わせたものを,従来のATI Radeon HDでは「SIMD Unit」(SIMD:Single Instruction Multiple Data)と呼んでいた。DirectX 9世代のGPU考え方でいうと,このSIMD Unitが1基のシェーダユニットというイメージだ。
HD 5800シリーズでは,このSIMD Unitが,「Thread Processor」(スレッドプロセッサ)と名を変えている。さらに,SIMD Unit 16基を一組として構成されるものは,従来のATI Radeon HDだと「SIMD Core」と呼ばれていたが,これもHD 5800シリーズでは「SIMD Engine」と,呼び名が変わっている。
まとめると,
ATI Radeon HD 2000/3000/4000シリーズ
- 1 SIMD Unit= 5 Stream Processor
- 1 SIMD Core= 16 SIMD Unit
ATI Radeon HD 5000シリーズ
- 1 Thread Processor=5 Stream Core(Streaming Processing Unit)
- 1 SIMD Engine=16 Thread Processor
ということになる。
呼び名が微妙に変わってややこしいが,基本的な編成構造は「ATI Radeon HD 2000」シリーズから共通だ。
HD 5870の公称性能値が2.72TFLOPSであるというのは第1回で紹介したが,これは,1基のSPが1クロックでFP32の積和算(=2FLOPS)をこなせるから,1600SP×2FLOPS×850MHz=2,720,000FLOPSという見積もりから来ている。

HD 5870とHD 4870のスペックを比較した表。演算性能を左右するスペックが大幅に強化されているのが分かる。一方,メモリバス帯域幅の拡大は1.33倍に留まった
第1回でもHD 4800シリーズとのスペック比較は行っているが,あらためて右に示したHD 5870とHD 4870の比較表を見てみると,メモリバス帯域幅は1.33倍と,それほど大きく向上してはいないことに気づく。
これは,グラフィックスメモリバスが,HD 4800シリーズと変わらない,256bitインタフェースのままであることに起因している。もっとはっきり書くと,性能向上分の33%は,採用しているGDDR5メモリチップの動作クロック向上分でしかないのだ(※HD 4870は実クロック900MHzのGDDR5,HD 5870は同1200MHz)。
この部分は,HD 5000世代のボトルネックとなり得るわけだが,この点についてDemers氏は,「キャッシュシステムの増強によって対応する」と述べ,問題にはならないと自信をのぞかせていた。なお,そのキャッシュシステムについては第3回で述べる。

先ほど示したブロックダイアグラムの一番上を抜き出したのが下の図になる。
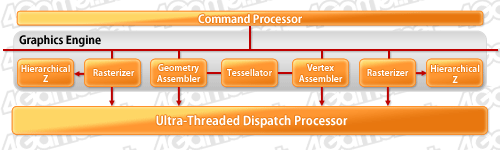
ブロックダイアグラムの最上部を抜き出したもの
(参考)HD 4870のGraphics Engine部
このブロックは,HD 5870が搭載する大量のSP群を3Dグラフィックス用途に起用する根幹ブロックで,「Graphics Engine」(グラフィックスエンジン)と命名されている部分だ。
右に示したHD 4870のGraphics Engine部とよく似た印象だが,実は,地味ながら大きな変革が施されている。
HD 5870の全体ブロックダイアグラムを再掲

こちらは「ATI Radeon HD 5770」のブロックダイアグラム。HD 5870の下位モデルとして,SIMD Engine数が半減しているが,それに伴って,ラスタライザも1基に減っている
第一に,「Rasterizer」(ラスタライザ,以下日本語表記)が“デュアル化”されたことが挙げられよう。ラスタライザは,頂点単位の情報だったポリゴンデータから,「実際のレンダリング目的となる,実体を伴うピクセルタスク」を生成するユニットだ。
なぜここがデュアル化されたのか。もちろん「効率を2倍に上げるため」なのだが,アーキテクチャの成り行きから,自ずと2倍化したという風にも考察できる。
先ほど示した全体ブロックダイアグラムを,右にもう一度示してみるが,これを見てその理由がピンときただろうか。
HD 5870は,HD 4870相当の800SP(10 SIMD Engine)が二組あるような構成になっているのが分かるだろう。HD 5870では,コアクロックをそれほど引き上げることなく,HD 4870比でSP数を2倍に増やしたが,これらをちゃんと活用するには,“仕事の発注元”たるラスタライザを倍に増やす必要があったのだ。
ラスタライズのデュアル化に伴い,「Hierarchical Z-Buffer」(階層型Zバッファ,以下日本語表記)ユニットも倍化されている。
なお,階層型Zバッファは,ラスタライザで発注されたピクセルタスクのうち,「見えていないピクセル」や「画面外のピクセル」などなど,明らかに描画する必要がないピクセルを早期に破棄する「Early Z-Culling」(早期Zカリング)を効率よく行うために利用されるものだ。
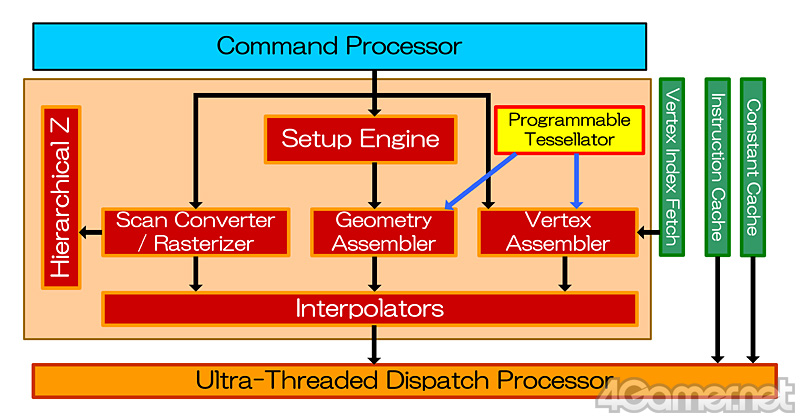
テッセレーションを担当する「Tessellator」(テッセレータ,以下日本語表記)について,AMDはHD 5800シリーズが搭載するものを「第6世代」と位置づけている。
旧ATI Technologies時代にRadeon 8000シリーズで採用した「TruForm」でN-Patch法によるテッセレーション機能を実装後,Xbox 360(=Xenon),ATI Radeon HD 2000/3000/4000シリーズとテッセレータ機能のアップデートを重ねてきたので,今回のHD 5800シリーズで6世代めというわけだ。
やや余談気味に続けると,Radeon 9000/X/X1000シリーズでは,ハードウェアテッセレータの搭載が省略され,Radeon 8000に対する互換性維持のためにソフトウェアエミュレーションのサポートが行われていた。だから,このあたりは“世代数”にカウントされていないのである。
さて,HD 4000シリーズ以前と互換性が保証されているという,このHD 5800シリーズのテッセレータ。ブロックダイアグラム上だと,HD 4800シリーズと代わり映えしないが,実際には,DirectX 11(厳密にはDirect3D 11,以下同)のレンダリングパイプラインを構成する「Hull Shader」(ハルシェーダ,以下日本語表記)と「Domain Shader」(ドメインシェーダ,同)からコントロールされる機能が新たに搭載されている。
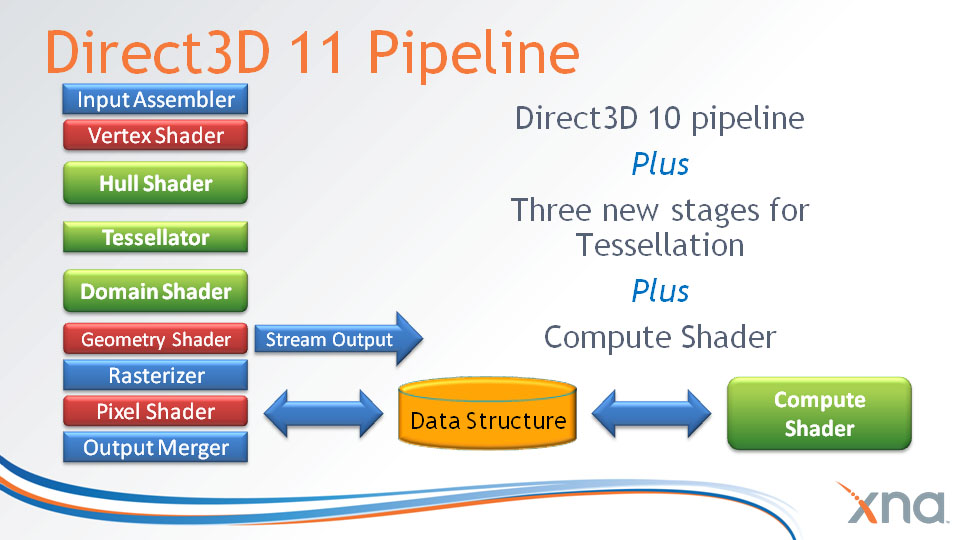
DirectX 11(=Direct3D 11)のレンダリングパイプライン。緑のマスがテッセレーションステージだが,このうち,ハルシェーダとドメインシェーダはプログラマブルシェーダだ。テッセレータのみが固定機能シェーダユニットとなる
テッセレータがSIMD Engine側でなく,Graphics Engine部に,しかも1基しか用意されていないのは,テッセレーションの処理自体が単純なデータムーブに終始しており,1基でも十分にこと足りるためだ。テッセレーションステージの前処理に当たるハルシェーダ,そして後処理に相当するドメインシェーダは,テッセレータではなく,SIMD Engine側で実行されることになる。
DirectX 11のレンダリングパイプラインで示されるフローと,ハードウェアの実装ではだいぶ印象が違う点に注意しておきたい。
ところで,HD 4870とHD 5870のGraphics Engine部を見比べたとき,後者で「Interpolators」(インタポレータ,以下 補間ユニット)がなくなっていることに気がついただろうか。
「そもそも補間ユニットってなに?」という人も多いかと思うので簡単に解説しておくと,例えばポリゴン上のピクセルと,そこに貼り付けるテクスチャの対応というものは視線位置によって変わるうえ,描画する1ピクセルがテクスチャ上の1テクセルに対応することはまれだ。そこで,この調整を図るのに不可欠なのが「テクスチャアドレス計算」なのだが,この計算を受け持つのが補間ユニットである。
HD 4000シリーズまでは,テクスチャアドレスの補間計算を行うため,この専用ロジックがGraphics Engine側に実装されていた。これに対し,HD 5000シリーズでは,この計算にSIMD Engine側のSPを起用して行うようになったため,Graphics Engineから省略された,というわけである。
こうした設計になった理由は二つ。
一つは,もともと補間ユニットは単純計算ユニットなので,SPを豊富に搭載するHD 5800シリーズでは,こちらを活用するほうがスマートであるという判断が働いたため。
もう一つの理由は必然で,DirectX 11におけるプログラマブルシェーダの新機能に「Programmable Interpolation of Input」が追加されたためだ。
付け加えると,この補間計算をSP側で実行させるようにすることで,うれしい副作用が二つ得られる。
一つは,パフォーマンスの向上が見込めるということだ。
高度な微細凹凸表現を行う視差遮蔽マッピング,リアルな人肌表現を実現するスキンシェーダなどは,テクスチャヘビーなシェーダであり,数が固定された専任の補間ユニットでは,テクスチャアドレス計算できる量には制限がある。つまり,テクスチャヘビーなシェーダが動作するときには,補間ユニットがボトルネックとなる可能性があったのだ。

「HD 5800シリーズは,高解像度モード時のテクスチャフィルテストのベンチマークテストを実行したときにもパフォーマンス向上があるはず」(Demers氏)
この処理を,膨大な数量を持つSP側で行えるようにすれば,このボトルネックを解消できるという理屈である。DirectX 9世代の固定数割り当て型シェーダアーキテクチャから,DirectX 10世代の「動的にシェーダ負荷を振り分ける」統合型シェーダアーキテクチャへ移行したときと同じなので,イメージしやすいと思う。
もう一つは,計算精度の向上,計算精度の一貫性が見込めるという点だ。
SPにはIEEE 754-2008準拠(※詳細は第3回で述べる)の演算精度性能があるが,補間計算をこの精度で行えるということは,信頼性が高いということになる。最終的な見た目にはあまり違いがなかったとしても,だ。
さらに,HD 5800シリーズのGraphics Engineでは,「Constant Buffer」(定数バッファ)の更新性能向上,「Geometry Shader」(ジオメトリシェーダ,以下日本語表記)の性能向上などが図られている。この2点は,DirectX 10.x世代以前に対応した3Dアプリケーションの高速処理に貢献できるはずだ。
実のところ,このジオメトリシェーダの性能向上は,間接的な工夫で実現されている。具体的には,ジオメトリシェーダによって増大した頂点データを,なるべくグラフィックスメモリに書き戻さず,GPU内部に溜め込んだままにしているのだ。GPU内部に多くを溜め込むことで,後段の頂点処理において,頂点データへ高速にアクセスできるため,結果としてレンダリングのパフォーマンスが向上するというわけである。
そのほか,OpenGL関連の機能強化も施されている。例えば,CAD分野で多用される「Line Rendering」(線分レンダリング)については,性能向上を望む声が大きかったため,HD 5800シリーズでは専用ハードウェアを実装することで,高速化を実現したという。

続いては,SP(=Stream Core)と,それが5基集まったThread Processor(以下,TP)について見ていこう。
HD 5870の32bit浮動小数点(FP32)の演算性能は,前述したように,2720GFLOPS(=2.72TFLOPS)だ。では,倍精度,64bit浮動小数点(FP64)の演算性能はどうなのか。
これは半分ではなく,5分の1となる544GFLOPSとなっている。
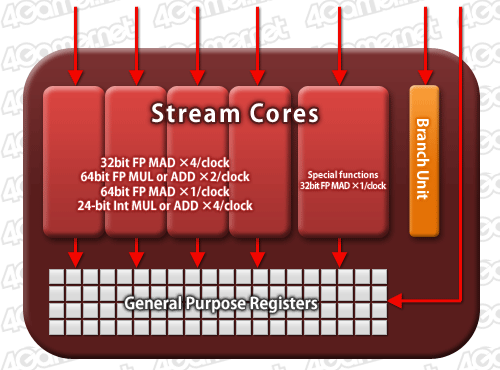
HD 5800シリーズのTP構成。Stream ProcessorがStream Core(もしくはStream Processing Unit)へと名を変えた以外は,従来製品と変わっていない
これは別に驚くべきことではなく,HD 4800シリーズと同様,HD 5800シリーズに倍精度演算ユニットは存在せず,TP内の5SP(※実動は4SP)がFP64演算に従事するため。だから16TP×20 SIMD Engine×2FLOPS×850MHz =544,000FLOPS ということになる。
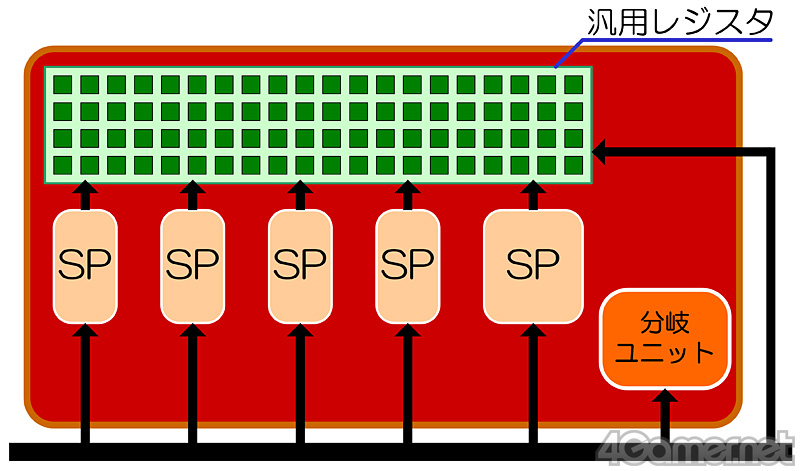
(参考)HD 4800シリーズのSP(=Stream Processor)構成
TPの基本的な構成はHD 4800シリーズまでと変わらない。標準仕様のFP32スカラ演算器のSPが4基,そして指数,対数,三角関数などといった複雑な超越関数(Transcendental Function)計算能力を持ったスペシャルなSPが1基,これらにBranch Unit(分岐ユニット),General Purpose Register(汎用レジスタ)群で成り立っている。
ただ,SIMD Unitと呼ばれていたHD 4800シリーズ時代とまったく同じかというとそうでもなく,1サイクル当たりの命令実行効率向上を図るべく,TPを構成するSPには,細かな改良が施されている。
例えば,2×2ベクトルの内積演算命令の2命令同時実行や,依存関係のある積算と和算の同時実行など。これらは実質的に,そうした2命令を1命令語に割り当てた命令語を新設したことに相当する。
これに加え,SAD(Sum of Absolute Differences:絶対差総和)命令の新設もトピックとして強調されていたりもする。
これは,二つのアドレスに格納された数値データ間の差分の絶対値の総和を求めるもので,画像認識やビデオのトランスコードなどにおいては,動き検出として高頻度で行われる計算だ。これまで,この動作を実現するためには複数命令を用いた小プログラムを構成する必要があったが,HD 5800シリーズでは同処理を1命令で実現できるようになったというわけである。
AMDによると,実行効率は12倍に向上したとのことだ。ただし,これはOpenCLのAMD拡張仕様として提供されるという。
このほか,DirectX 11で新設されたbitカウント,bit挿入,bit取り出しなどの新しい二進論理演算も追加されている。これらは,グラフィックス用途というよりは暗号生成/解読,圧縮展開などといったGPGPU用途のためのものだ。
また,厳格な精度規定がなされた積和算手法であるFused Multiply-Add(FMAD)命令にも対応した。
第2回はここまで。シリーズ最終回となる第3回では,テクスチャユニットやキャッシュシステム,レンダーバックエンド,メモリ周りの解説などを行いつつ,HD 5000シリーズの立ち位置を明確にしてみたい。
- 関連タイトル:
 ATI Radeon HD 5800
ATI Radeon HD 5800
- この記事のURL:
(C)2009 Advanced Micro Devices, Inc.