



![[CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/001.jpg)





イベント
[CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート
![画像ギャラリー No.002のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/002.jpg) |
しかし,口パクアニメーション制作は実のところ面倒なもので,制作効率を向上する技術が望まれているテーマでもある。
その難題に取り組んだのが,音声・音響系ミドルウェアの開発を得意とするCRI・ミドルウェアだ。本稿では,同社がCEDEC 2019で行った「キャラクターをより魅力的に!ゲーム向けリップシンクミドルウェア」と「ニューラルネットワークを用いた音声信号によるリップシンク(口パク生成)技術」という2つのセッションを簡単にまとめてみたい。
音声データから口パクアニメを生成する方法とは?
素人考えでは,台詞の音声データがあるのなら,それを解析して口パクアニメのデータを自動出力する仕組みが作れそうだ。実際,この考え方で口パクアニメを制作手法は,すでにいろいろと存在する。最もシンプルな手法は,波形データの音量変化に応じて口の開け具合(開口度)を変化させるというものだ。これは言語を選ばず利用できるのが利点であるものの,発音する音素の種類,つまり口の形は考慮しないので,品質面は今ひとつである。
![画像ギャラリー No.003のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/003.jpg) |
シンプルな方式よりも自然な口パクアニメを生成できるのが,「最尤(さいゆう)エントロピー法」という方式を用いた「フォルマント」認識ベースのアプローチだ。
フォルマントとは,音声の波形における周波数のピークを示す。人間が発する声は,ピークが複数出ることがあり,低い周波数から第1フォルマント(F1),第2フォルマント(F2)と呼ばれる。このF1とF2をグラフの横軸と縦軸に割り当てると,その組み合わせで,音声におけるおおよその母音を推測できることが知られている。
![画像ギャラリー No.004のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/004.jpg) |
アイウエオの母音は,大まかな口の開け方を決定するもので,入力音声を解析して母音を推測すれば,母音を発声しているときの口の形状が決まるので,それに合わせてキャラクタの口を動かすことで,かなりリアルな口パクアニメが生成できる。
![画像ギャラリー No.005のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/005.jpg) |
![画像ギャラリー No.006のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/006.jpg) |
当時は,計算量が少なめで相応のフォルマント認識が行える線形予測分析手法として最尤エントロピー法を採用したと押見氏は述べる。
![画像ギャラリー No.007のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/007.jpg) |
この手法を使うとF1の推定はうまくいくのだが,F2の推定が困難であるという。そこで推定精度を上げるため,あらかじめ生成しておく話者特有の母音辞書を用意して組み合わせることで,母音を推測する仕組みを採用していた。
![画像ギャラリー No.008のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/008.jpg) |
ただ,音声の種類によっては推測精度が安定しなかったという。それ以上に,母音辞書の生成が大変で,生成した母音辞書の信頼性もよくなかったのだとか。母音辞書は話者固有の辞書なので,不特定多数の音声に対応しにくいという問題点もあったそうだ。
こうした経験を踏まえてCRI・ミドルウェアが開発したのが,機械学習型AI(ニューラルネットワーク)ベースの口パクアニメ生成ミドルウェア「ADX LipSync」だ。なお,ADXはCRI・ミドルウェアの音声関連ミドルウェアのブランド名であり,LipSyncは,「声と口の動きを同期させる」という意味の「Lip sync」から取っている。
ADX LipSyncは何ができるのか
![画像ギャラリー No.009のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/009.jpg) |
製品としてのADX LipSyncは,最尤エントロピー法のアプローチとは異なり母音辞書は不要で,すでに学習済みのAIを搭載しているので,基本的にはどんな話者の音声に対しても対応できるそうだ。
また,リアルタイム動作も可能で不特定多数の話者にも対応可能であり,マイク入力したリアルタイム音声から口パクアニメを生成できるとのこと。たとえば,VTuberのキャラクターを喋らせるのにも使えるわけだ。
音声をADX LipSyncに入力すると,どのようなデータが出てくるのだろうか。口パクデータで動かしたいキャラクターは,ゲームや場面によって当然異なるわけで,アニメ調の美少女キャラと無精髭のマッチョ系オヤジキャラとでは,口周りのボーン構造がかなり違ってくる。そのため,ADX LipSyncでは,直接3Dモデルを駆動するデータを返すわけではないという。
具体的には,以下に示すスライドのような流れで,入力音声をリアルタイム解析して,流れる音声が「あ,い,う,え,お」である確率を母音ごとに返す。
![画像ギャラリー No.010のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/010.jpg) |
![画像ギャラリー No.011のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/011.jpg) |
![画像ギャラリー No.012のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/012.jpg) |
ADX LipSyncが出力する口パクアニメデータは,音声の流れに合わせて並んだ確率変数なので,「あ」が1.0だけでなく0.8になったり,「い」が0.2になったりすることもあり得る。我々が言葉を話しているときも,「あ」の発音から「い」の発音へ推移することや,「あ」と「い」の中間的な音を発することもあるので,ADX LipSyncの出力は理に適っていると言えよう。
ゲーム側で出力データを使うには,あらかじめ,キャラクターが「あいうえお」の各母音を発音したときの口パクアニメーションを用意しておき,ADX LipSyncが出力した確率変数に合わせてアニメーションを再生することになる。「あ=0.8」「い=0.2」という場合,どう処理するかはゲーム側の実装次第となるが,たとえば「あ」と「い」のアニメーションを適度にブレンドするといった対応が考えられるだろう。
またADX LipSyncは,母音の推定確率以外にも,口の形状を縦開き具合(Height)と横開き具合(Width)の2軸で表現する「Height-Widthパラメータ」で返すこともできるそうだ。たとえば,「あ」ならHeightが強めの変数を返し,「い」ならばWidthが強め,「う」ではHeightとWidthが同じくらいで,おちょぼ口っぽくなるような変数を返す。自分の口で試してみると,縦横の具合をイメージできるだろう。
![画像ギャラリー No.013のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/013.jpg) |
![画像ギャラリー No.014のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/014.jpg) |
Height-Widthの値も,顔のボーンを直接駆動する変数ではなく抽象的な推論値であるため,キャラクターモデルのボーン構造には依存しない。値をもとにして,どう3Dモデルの口を動かすかはゲーム開発者に委ねられるのだ。
さて,実際に人間が発声するとき,口の動きは母音だけに連動するわけではない。上田氏はその好例として「毛虫」(ケムシ)を挙げた。
ケムシの母音は「えうい」だが,母音の前に子音があり,それが「ケムシ」の音を決定している。「ケ」や「シ」は,舌使いなどが発音に深く関係した子音が母音の前にあり,「ム」も唇を閉じて出す子音が母音よりも先に来る。
![画像ギャラリー No.015のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/015.jpg) |
![画像ギャラリー No.016のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/016.jpg) |
たとえば「ム」のように,唇を閉じて出す音は唇音(しんおん)と呼ばれている。ADX LipSyncは,音声から唇音の存在を認識した場合,「唇を閉じよ」という口パクデータを出力するそうだ。また,「ケ」や「シ」は,その他と分類して,直前における口の状態から,適切に補間する口パクデータを返すという。
![画像ギャラリー No.017のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/017.jpg) |
これらに加えて,まだ完成形ではないそうだが,実験的に「舌の高さ」を口パクデータとして返す仕様も盛り込んでいるそうだ。今のところ,舌の高さ情報しか出力していないそうだが,「将来的には,舌の動き(情報)を拡張していきたい」と上田氏は述べていた。舌の動きを推測する精度が上がると,上下の歯で舌を挟み込むような英語の「TH」発音に対応した口パクデータを出力できるかもしれないそうだ。

ADX LipSyncにおけるAIの教育
![画像ギャラリー No.018のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/018.jpg) |
ADX LipSyncにおけるAIの学習は,いわゆる「教師あり学習」として行ったという。
まず,音声データに相当する入力特徴量と,教師データとなる口の形状データをDNNに入力して,DNNが予測した口の形状データが教師データとどれくらい誤差があるかを算出する。そのうえでDNNに誤差を与えて(逆伝播),推測データと教師データの差が小さくなるようにDNNの係数を更新していく。これを繰り返すことで学習データが洗練されていき,AIとしての精度が高まっていくということだ。
なお,入力特徴量としての音声データは,PCM的な音圧データではなく,時間方向に音声スペクトラムが変化する周波数的なものである。
![画像ギャラリー No.019のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/019.jpg) |
![画像ギャラリー No.020のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/020.jpg) |
飯島氏は,ADX LipSyncの開発にあたって,学習用データの作成が最も大変だったと振り返っていた。質の悪いデータで学習させてしまうと,正しい推論ができなくなるし,データ量が少なくても同様だ。
![画像ギャラリー No.021のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/021.jpg) |
![画像ギャラリー No.022のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/022.jpg) |
![画像ギャラリー No.023のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/023.jpg) |
![画像ギャラリー No.024のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/024.jpg) |
なお,ADX LipSyncで使う音声解析AIの学習は,CRI・ミドルウェアが済ませているので,ゲーム開発者側で新たに行う必要はないとのこと。とはいえ,開発者向けのミドルウェアなので,開発側の都合や要望に即した特別な学習データを提供してもらう,といったことはあるのかもしれない。
あえてリアルタイム活用しない選択もあり
![画像ギャラリー No.025のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/025.jpg) |
そうしたニーズを考慮してADX LipSyncでは,台詞の音声データを入力して口パクデータを一括生成したうえで,データを開発者が編集するといった使いかたも可能であるそうだ。
![画像ギャラリー No.026のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/026.jpg) |
このユースケースでは,CRI・ミドルウェアが提供するもう1つのサウンド系ミドルウェアである「ADX2」と連動させる。
具体的には,あらかじめADX LipSyncで出力した口パクデータを,ADX2のツール上で台詞の音声とともに読み込ませて,音声を聴きながら編集するのだ。
![画像ギャラリー No.027のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/027.jpg) |
口パクデータの編集は,ADX LipSyncが返すHeight-Width式のデータに対応しているのはもちろんのこと,「あいうえお」+唇音の音素形式によるデータにも対応している。
![画像ギャラリー No.028のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/028.jpg) |
以下に示す動画では,「あいうえお」の台詞に対する口パクデータを編集して,「い」の発音で口を上下に大きく開けるようにしている。ADX2による編集のプロセスが分かるだろう。
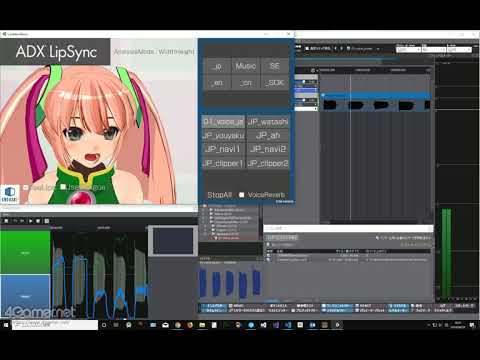
さらに高い精度を目指すには,日本語と英語以外の言語も学習する必要が
ADX LipSyncは,音声データを解析して口パクデータを出力するツールなので,基本的には音声データがどの言語であっても,人間がその声を出すときに使うであろう口の形状に合わせた口パクデータを出力できる。言うなれば,全言語対応型の口パクデータ生成ミドルウェアというわけだ。
現在開発中のAI学習データは,英語音声をベースに学習させたものだそうだが,今のところ,日本語の入力に対しても問題ない口パクデータを出力できているとのこと。
ただ今後は,口パクデータの出力精度を高めていくにあたって,さまざまな言語の音声データを学習に組み込むことも検討中であるそうだ。
人間が発声できる音声のうち,実際の言語で使われている子音と母音を記号化した「国際音声記号」の表から,日本語の子音と英語の子音を異なる色で塗りつぶしてみると,片方の言語にしかなかったり,どちらの言語でも使われていなかったりする子音があるのが分かる。
![画像ギャラリー No.029のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/029.jpg) |
![画像ギャラリー No.030のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/030.jpg) |
子音を絡めた口パクデータの精度を上げるためには,より多彩な言語の学習に取り組むべきなのかもしれないと,CRI・ミドルウェアは考えているわけだ。
ADX LipSyncは2019年秋に正式リリースの予定で,上述した精度向上への取り組みは,今後のバージョンアップで反映していくことになるだろう。ちなみに,すでにADX LipSyncの採用事例も決まっているそうで,カラオケ事業大手の第一興商が採用するそうだ(関連リンク,リンク先はPDF)。
具体的には,第一興商が10月1日に発売予定のカラオケ採点システム「LIVE DAM Ai」で,「シンプル採点 3D」というモードにADX LipSyncを使っているという。シンプル採点 3Dでは,ユーザーの歌声にあわせて画面上の3Dキャラクターが歌う演出があり,これにADX LipSyncを使っているそうだ。
ちなみに,シンプル採点 3Dに出てくるゆるキャラ風の3Dキャラクターは,CEDEC 2019会場で披露していた美少女キャラクターによるデモよりも,アグレッシブに口を動かすだけでなく,顔全体を振るわせてこぶしを効かせるような表現もあって,なかなか見応えがあった。
![画像ギャラリー No.031のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/031.jpg) |
![画像ギャラリー No.032のサムネイル画像 / [CEDEC 2019]AIが音声データからリアルタイムに口パクを生成。CRIの音声ミドルウェア「ADX LipSync」をレポート](/games/999/G999905/20190906158/TN/032.jpg) |
そのうちCRI・ミドルウェアのYouTubeチャンネルで公開する予定だそうなので,興味のある人は,力の入った歌いっぷりを披露するキャラクターを見てほしい。爆笑すると思う。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー