










ニュース
ARMの次世代CPU「Cortex-A75」「Cortex-A55」は,現行CPUといったい何が違うのか
 |
これらのうち,Mali-G72については西川善司氏がレポートしているが,Cortex-A75とCortex-A55は,果たして現行製品から何が変わるのだろうか。ARM関係者への取材を通じて,両CPU IPコアの概要がある程度見えてきたので,本稿ではその内容をお届けしてみたいと思う。
 |
Cortex-A75:Cortex-A72の後継でモバイル用途でも高性能なCPU IPコア
それでは,まずCortex-A75から見ていこう。
Cortex-A75は,既存のハイエンドSoC(System-on-a-Chip)向けCPU IPコアである「Cortex-A72」や「Cortex-A73」の後継となるものだ。
Cortex-A72は,ある意味では素直な3命令同時実行のスーパースカラ(Superscalar,スーパースケーラ)型CPUコアで,モバイル用途はもとより,サーバー用途にも利用できる構成だった。一方,Cortex-A73は,モバイルに特化した構成で,2命令同時実行のスーパースカラでありながら,モバイル機器向け用途――スマートフォンでは消費電力1W程度,タブレットでは2W程度――においてCortex-A72を上回る性能を発揮するようデザインされたプロセッサであった。
モバイルに特化させた結果として,Cortex-A73は,たとえばメモリエラー回避機能である「ECC」(Error Correcting Code)が省略されるといった具合で,サーバー用途には利用できないスペックになっている(関連記事)。
では,Cortex-A75はアーキテクチャ的にどちらの後継かというと,Cortex-A72のほうである。命令パイプラインは3命令同時実行のスーパースカラに戻り,サーバー用途や車載機器向けにも使える機構を搭載しているからだ。
 |
ARMは,Cortex-A75とCortex-A73の性能比較も公表している。それによると,純粋なALU(論理演算ユニット)やFPU(浮動小数点演算ユニット)の性能では22〜33%,メモリアクセスのスループットでは16%向上しているという。
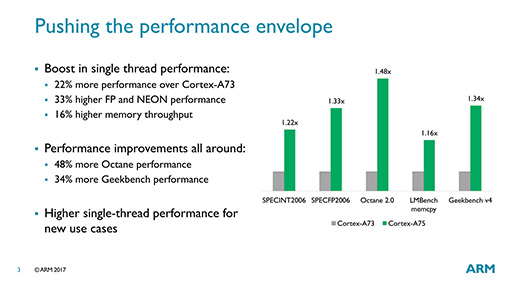 |
一方,消費電力あたりの性能では,コアの消費電力を750mWや1W,2Wまで絞ったときにCortex-A73比で20〜30%高い性能を発揮できるため,モバイル向けのハイエンドSoCとしても最適というのがARMの主張だ。
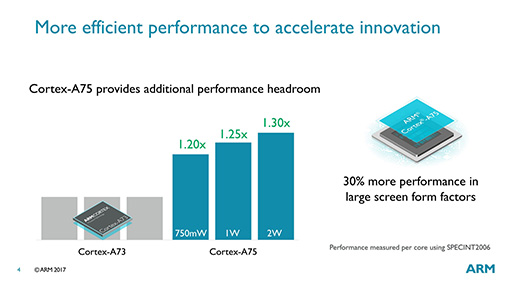 |
ARMは,Cortex-A75とCortex-A55を組み合わせたSoCのシミュレーションも公表している。それによると,Cortex-A53を8基搭載するSoCを基準とした場合,
余談気味だが,ARMが公開したグラフからCPUコアのダイサイズを計算してみると,Cortex-A53と比べてCortex-A73は約2.1倍,Cortex-A75は約1.34倍,Cortex-A55は約1.1倍になる。ただこの試算はあくまでも採用される製造プロセス技術が同じ前提に立ったときのものだ。実際にCortex-A75およびCortex-A55を製造するのに用いられる製造プロセス技術は現行世代のものと比べて微細化が進むはずなので,試算と同じ数値にはならないだろう。
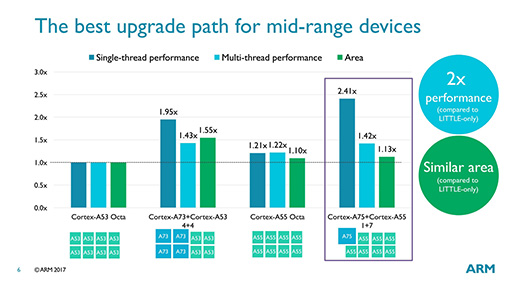 |
サーバー用途を考慮した新機能を多数実装
ARMが,Cortex-A75に盛り込んだ新機能には,下のスライドに示す6種類がある。
 |
実のところ,これらのほとんどは,ARMの命令セットである「ARMv8.2-A」で定義しているもので,Cortex-A55でも同様に利用可能だが,順に説明しておこう。
- Dot product and half-precision float
ベクトル演算機能のこと。とくに「Convolutional Neural Network」(畳み込みニューラルネットワーク,以下,CNN)における畳み込み処理で大活躍する。
ちなみに,「dot Product」が対象するのは8bit整数のみ。「half-precision float」はFP16(半精度浮動小数点演算)のことを指す。 - Virtualized Host Extensions(VHE)
仮想化機能の強化。とくに,任意のOS上で実行する仮想マシン(※Type-2。Type-1は,直接ハードウェアの上で実行する仮想マシン)の処理を高速化するための拡張を施したという。 - Cache stashing and atomic operations
「Cache stashing」とは,キャッシュの一部領域をCPUの外部から直接アクセスすることができるようにする拡張機能で,さまざまなアクセラレータ――CNNやネットワーク処理など,汎用的に使える――を利用するためのものである。
これを使うと,CPUからは(キャッシュ経由で)メモリに書き込んだように見えて,実際はメモリではなく直接アクセラレータに書き込むとか,あるいはアクセラレータからのデータを(メモリを介さず)直接キャッシュへ書き込むといった処理が可能となり,アクセラレータを利用する場合のオーバーヘッドが大幅に減少する。
ただ,この仕組みを機能させるには,キャッシュとアクセラレータの間で書き込みや読み出しのタイミング制御が必要になる。そこで新しくAtomic命令(atomic operations)も追加したというわけだ。
また余談気味だと断ってから書いておくと,個人的には,Cortex-A75とCortex-A55がCache stashing機能を導入したのはちょっと意外だった。今までこの機能を実装したのは,旧Freescale Semiconductor(※現NXP Semiconductors,以下 NXP)の「e500」というネットワークプロセッサ向けPowerPCコアのみだったからだ。
そのNXPが現在,PowerPCに代えてCortex-Aを搭載した「QorIQ Layerscape」シリーズを展開していることを考えると,旧Freescale方面から強い要請でもあったのかなと考えている。 - Cache clean to persistence
これは,不揮発性メモリをメモリモジュールに搭載する「NVDIMM」(Non-Volatile Dual In-line Memory Module)のような新しいメモリ技術に対応するための機能。メインメモリに使うDRAMとは異なり,不揮発性メモリは電源を切っても内容が消えないので,これに対応する機構を加えたようだ。 - Server class RAS
とくにサーバー用途で求められるRAS――Reliability(信頼性)とAvailability(可用性),Serviceability(保守性)の頭文字を取った用語――機能を実現するための要素である。
プロセッサが壊れにくいとか,エラーがあっても修復できるという話が信頼性で,パリティやECCといった機構がこれに相当する。可用性は,故障などがあっても処理を続行できるという要素で,たとえば冗長構成をサポートする機能がこれだ。保守性は,故障時の修理を短い時間で容易に行うための要素で,たとえば主要部品やモジュールのホットスワップなどが該当する。
ある程度は後付けでも可能だが,CPUコアの設計段階から考慮しないと実現できない機能もあるので,Cortex-A75ではそれを当初から考慮しているということだ。 - CPU Activity monitoring
読んで字のごとく,CPUの動作状態を確認する機能の強化で,スレッド単位で稼動状態の確認が可能になった。これもサーバー用途で強く必要とされる。
Cortex-A75の内部構造
ここからはCortex-A75の内部構造について,もう少し詳しく説明していこう。
ARMは今のところ,Cortex-A75のパイプライン構造に代表される詳細を明らかにしていない。とはいえ,基本的にはアウトオブオーダー(Out of Order)型で3-wayのスーパースカラプロセッサであり,このあたりはCortex-A72の延長線上にあると言っていい。
 |
フロントエンドのプリフェッチからデコードまでを見ると,大きな特徴として,デコードそのものがCortex-A73の1サイクルあたり3命令からCortex-A75で4命令になっている点が挙げられよう。同時実行は3命令までなのに,4命令をデコードできるのは,複数の命令を1つにまとめて処理する,いわゆる「Macro Fusion」に対応したためと思われる。
また,クロックあたりの命令実行数(Instructions Per Clock,以下 IPC)を改善するために,アドレス変換キャッシュである「Translation Lookaside Buffer」(TLB)のノンブロッキング化を実現しているのも特徴だ。先頭の命令がキャッシュミスしても,後続する命令がキャッシュヒットする状況にある場合,処理を止めず(=ノンブロッキング)に継続できれば遅延を最小に抑えられるということで,TLBでこれをサポートしたのだと考えられる。
 |
また,分岐予測をミスした場合のペナルティを緩和すべく,分岐命令の移動先アドレスを保存しておき,直近の分岐を高速に呼び出す「micro-BTAC」(micro Branch Target Address Cache)を追加したとのことである。
 |
バックエンドの実行段は,実行ユニットを強化したCortex-A73の構造を引き継いでいる。そのため,実行ユニットが,
- ALU(算術論理演算ユニット)×2,
- ロード/ストア(Load/Store)
- NEON(SIMD演算機能)/FPU
- 分岐
という5つだったCortex-A72と比べて,Cortex-A75では,
- ALU×2,
- ロード/ストア×2
- NEON/FPU×2
- 分岐
の7つとなっている。NEONやロード/ストアのユニットが2つに増えたのは,Cortex-A73〜A75が,データ処理のスループットを上げることを重視したことの表れと言えようか。
 |
SIMD演算ユニットのNEONは,いま述べたとおり,FP16とInt 8のサポートが追加された。
 |
また,これらをサポートするキャッシュ周りは,アウトオブオーダーへの対応を強化したとのことだ。
あるデータをメインメモリに書き込み,それを再び読み出す「Read after Write」は,x86系CPUでは非常に多く行われる演算である。そのため,IntelのCoreプロセッサでは,いちいちメインメモリに書いたものを読み出し直すのではなく,書き込みと同時にその値をレジスタファイルに戻すことで読み出しアクセスの時間を省く仕組みをキャッシュに備えている。それと同等のものを,アウトオブオーダーでも可能な仕組みをCortex-A75では搭載しているようだ。
 |
L2キャッシュは,容量256KBまたは512KBと,そう大きくないが,これはbig.LITTLE構成をサポートするための代償と言えなくもない。big.LITTLEで一番時間を食うのは,キャッシュの内容を移動することである。
これはbig側CPUコアとLITTLE側CPUコアを柔軟に構成できる「DynamIQ technology」(以下,DynamIQ)においても,依然として必要だ。それゆえ,あまり大容量のL2キャッシュは実装しにくいことになる。
その代わりと言うわけではないかもしれないが,データを先読みするプリフェッチ機構(Prefetcher)が強化されたそうだ。
 |
最後がRAS周りで,L1およびL2キャッシュにECC保護,命令キャッシュやTLB,タグにはパリティによる保護を組み込んでいる。
また,複数ビットのエラーが発生したときに,エラーの発生を正しくレポートできる機能「Data Poisoning」や,エラーレポートを追加する機能「Error Injection」といった具合に,アーキテクチャレベルでのエラー検出,報告機能を追加したとのことである。
 |
Cortex-A55:DynamIQ対応のミドルクラスCPU IPコア
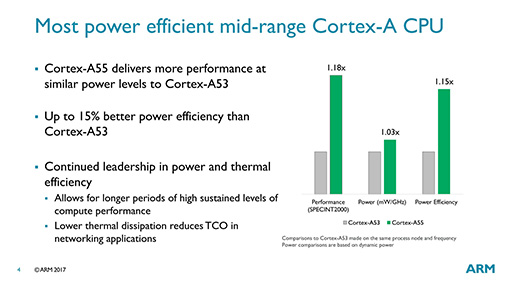
Cortex-A55は,Cortex-A75とbig.LITTLE構成を構成するCPU IPコアとして,ARMv8.2-Aをサポートし,またRASなどの機能も同等のものを備えつつ,Cortex-A53比で最大2倍の性能と最大15%程度となる消費電力あたりの性能向上を目指したCPU IPコアだという。
 |
ちなみに,「最大2倍の性能向上」というのはメインメモリ帯域幅の話で,アプリケーション性能は現行世代比で約20%の性能向上を果たすとのことである。同一の製造プロセス技術を用いて同一クロックに仕上げた場合,消費電力あたりの性能はCortex-A53と比べて約15%の向上になるという。
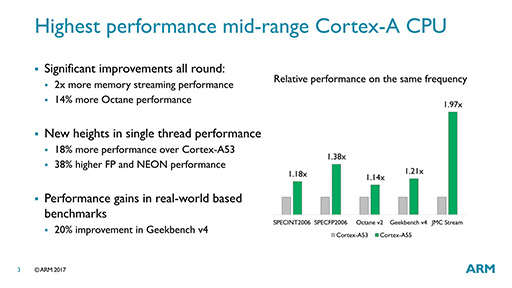 |
 |
Cortex-A55の内部構造も見ていこう。
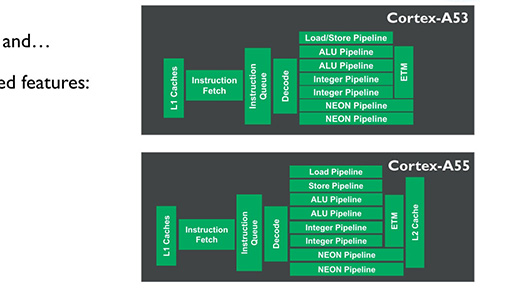
基本構造はCortex-A53と変わらず,インオーダー(In Order)の2-wayスーパースカラ構成で,パイプライン段数が8ステージというのも,まったく変わらない。パイプライン構造における目立つ違いといえば,ロードとストアが分離されていることだろうか。
 |
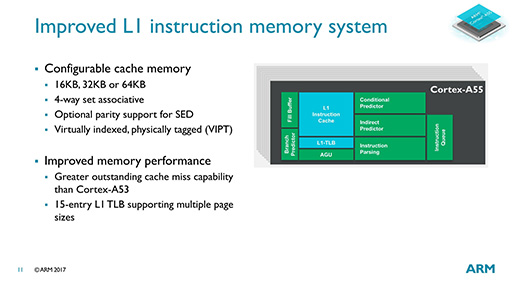
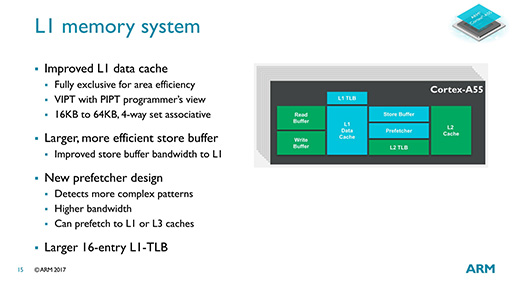
L1キャッシュそのものも,Cortex-A53と変わっていないが,キャッシュヒットミス時のリカバーが速くなったとのこと。L2キャッシュがL1キャッシュと同速で動いているためだろう。
 |
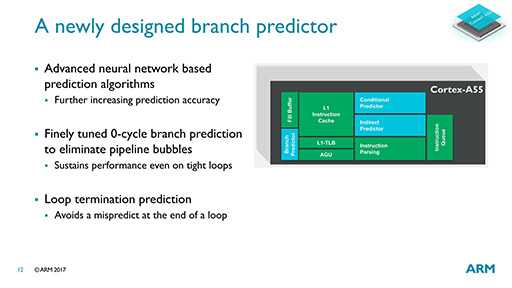
分岐予測機構には,新たにニューラルネット――パーセプトロンベースだろう――を採用し,さらにCortex-A75と同じく0サイクルの分岐予測も実装しているという。
 |
一方の実行ユニットだが,パイプライン構造のところで紹介した「ロードパイプとストアパイプの分離」と,もう1つ,ALU命令における遅延の1サイクル削減がポイントになっている。これにより,ロードとストアが同時に行えるようになり,これがメモリアクセスで最大2倍という性能差につながっている。
また,連続しないアドレスを指定してのL1キャッシュアクセスでも,2サイクルの遅延縮小が可能になったというから,ロード機構の最適化が進んでいるのだろう。
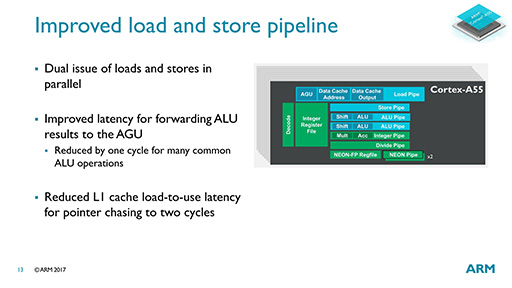 |
またNEON/FPUは,Cortex-A75と同じくFP16のサポートが加わったほか,FPUにおける「FMA」(Fused Multiply-Add)命令の遅延削減も実現しているとのことだ。
 |
L1データキャッシュは最大容量64KBで,L3キャッシュにまで対応できるように,プリフェッチ機構を強化しているとのこと。ただ,その詳細や具体的な効果などは未公表である。
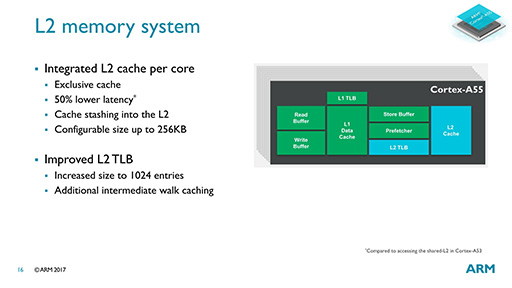
L2キャッシュ容量も最大256KBと小さいが,Cortex-A75でも最大容量512KBだから,ミドルクラス市場向けCPU IPコアであることを考慮すれば妥当だろう。
 |
 |
というわけで,現在判明している範囲で,Cortex-A75とCortex-A55の内部構造を説明してみた。ただ,肝心の製造プロセス技術や動作クロックなどといった部分は,いまだに明確になっていない。
ARMの副社長兼Compute Product Group担当ゼネラルマネージャーのNandan Nayampally氏は,「技術的には16nmプロセスはもちろん,28nmプロセスでも製造できると思う。ただ,ターゲットとなるのは10〜16nmプロセスあたり」と述べてはいる。しかし,CPU設計のもとになる物理IP「POP」(Processor Optimization Pack)は,どの半導体製造事業者(ファウンダリ)のどの製造プロセス向けに提供するのかといった具体的な情報は,公開していないのだ。
そうした製造に関わる情報が明らかになれば,もう少し細かな動作クロックの目標なども見えてくるのではないかと思われる。
- 関連タイトル:
 Cortex-A
Cortex-A
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー