









ニュース
NVIDIA,Keplerベースの新世代Teslaを発表。「GK110」コア採用の「Tesla K20」が年内に登場予定
NVIDIAは,北米時間2012年5月14日から4日間の日程で,GPUコンピューティング関連の開発者会議「GPU Technology Conference 2012」(以下,GTC 2012)を開催しているが,2日めとなる日本時間5月16日4:01,Kepler世代のGPUを搭載する新世代Tesla「Tesla K10」「Tesla K20」が発表された。
NVIDIAは現在,GPUコンピューティング向けの演算アクセラレータであるTeslaを「コンピューティングモジュール」(Computing Module)と位置づけているが,発表と同時に出荷が始まっているTesla K10は,GeForce GTX 600シリーズでも採用される「GK104」コアを2基搭載する製品だ。イメージとしては,「GeForce GTX 690」のGPUコンピューティング向けバージョンといったところである。
一方,2012年第4四半期の市場投入が予告されているTesla K20は,今回初めて存在が公表されたGPUコア「GK110」を搭載するとのことだ。
今回は,GTC 2012の開幕に先立ってアジア太平洋地域の報道関係者を対象として行われた電話会議の内容を基に,新世代Teslaの概要を紹介してみたい。
Tesla K10&K20の紹介に先立って簡単に状況を整理しておくと,NVIDIAは現在,GPUコンピューティング向け製品であるTeslaとしてTesla M2000シリーズを展開している。Tesla M2000シリーズは,Fermi世代のGPUを搭載するコンピューティングモジュールだ。
電話会議で新世代Teslaの説明にあたったのは,Tesla部門のディレクターを務めるSumit Gupta(スミット・グプタ)氏だが,氏は,Tesla K10が,Fermiベースの従来製品とは異なる領域をカバーする製品だと説明している。
Tesla K10は,信号&イメージ処理や,アンテナの設計などに応用されるキルヒホッフ型時間マイグレーションといった処理に適しているとのことだ。
Tesla K10がFermiべースのTesla M2000を置き換えない理由は,倍精度浮動小数点数の演算性能でTesla K10がTesla M2000より劣るためである。
下に示したスライドはTesla M2000シリーズの最上位モデルである「Tesla M2090」とTesla K10とでスペックを比較したものだが,Tesla K10は単精度浮動小数点数の演算性能こそ非常に高いものの,倍精度浮動小数点数の演算性能になると2基のGPUを駆使してもTesla M2090の3割弱とまったく及ばない。そのためNVIDIAは,単精度浮動小数点数の演算性能が効く信号&イメージ処理などに適した製品と,Tesla K10を説明しているわけなのだ。
「GeForce GTX 680」の発表にあたって,NVIDIAはGK104コアを「グラフィックス処理に特化した設計」だと述べていたが,そんなGK104をTeslaとして売っていくにあたり,「新たな分野に適するコンピューティングモジュール」と位置づけてきたのはなかなか興味深い。
一方,GK110コアを採用するTesla K20は,Tesla M2000シリーズと比べて倍精度浮動小数点数の演算性能が最大3倍に高められているという。
また,「Hyper-Q」「Dynamic Parallelism」という新要素のサポートも大きな特徴になるとのことだ。
一言でまとめると,Hyper-Qは,最大32のMPI(Message Passing Interface)タスクを実行できる機能だ。「Hyper-QによってGPUの使用率を上げ,ひいてはCPUが無駄に“遊んで”いる時間も削減できる」とGupta氏は説明していた。
もう1つのDynamic Parallelismは,GPU内部で新たなGPUスレッドを生成できる機能である。
従来,GPUは,データを分割し複数のプロセッサで大量のデータを一斉に処理する「データ並列性」(Data Parallelism)という考え方を推し進めて進化してきたが,Dynamic ParallelismによってGPUが自力で異なるスレッドを生成できるようになると,CPUに近い「タスク並列性」(Task Parallelism,複数のプロセッサで複数のスレッドを並列実行する)という,データ並列性とは異なる方向へ踏み出せるようになる。ある意味ではパラダイムシフトに近い展開といっていいだろう。
Gupta氏は「GPUの応用範囲を広げる拡張」だと強調していたが,確かに相当興味深い機能だ。
Gupta氏はそのほかにも,Tesla K10&K20に共通する特徴として,192基のCUDA Coreをクラスタ化した「SMX」(Streaming Multiprocessor eXtreme)の存在を挙げていた。電話会議の時点で,Tesla K20が採用するGK110のアーキテクチャに関する説明はほとんどなかったが,KeplerアーキテクチャのキモでもあるSMXはGK110でも(当然ながら)採用されるわけだ。
SMXによって「Keplerは従来の3倍の電力性能を持つ」(Gupta氏)そうで,氏は「2年前,東京工業大学は1 PFLOPSのスーパーコンピュータを構築したが,それには42の(サーバー)ラックが必要だった。しかしKeplerなら,わずか10ラックで1 PFLOPSの性能が得られる」と具体例を挙げて,その電力性能の高さを強調していた。
なお,GTC 2012に合わせ,NVIDIAは,同社製GPU向け開発環境「CUDA」の最新バージョンとなる「CUDA 5」のプレビュー版を公開。GPUプログラミング環境の強化も発表した。
これまでWindowsの「Visual Studio」のみの対応だったCUDAデバッガ「Parallel Nsight」が,LinuxおよびMacOS上の「Eclipse」にも対応する点や,ネットワークを介して他のGPUと協調できる「GPUDirect」がKepler世代のGPUでサポートされるというのが後者のトピックだ。
もう1つ,サードパーティのGPUライブラリなどをリンクできる「Library Object Linking」も,汎用コンピューティングプログラムの高速化を容易にする機能として注目されるところである。
従来のCUDAと同様,CUDA 5はNVIDIAの開発者向けサイトでダウンロード提供されるので,興味がある人はチェックしておくといいだろう。なお,CUDA 5の詳細はGTC 2012の会期中に公開される予定だ。
 Tesla K20で採用されるGK110コア |
一方,2012年第4四半期の市場投入が予告されているTesla K20は,今回初めて存在が公表されたGPUコア「GK110」を搭載するとのことだ。
今回は,GTC 2012の開幕に先立ってアジア太平洋地域の報道関係者を対象として行われた電話会議の内容を基に,新世代Teslaの概要を紹介してみたい。
デュアルGK104のTesla K10が先行して登場
新コア「GK110」採用のTesla K20は第4四半期に
Tesla K10&K20の紹介に先立って簡単に状況を整理しておくと,NVIDIAは現在,GPUコンピューティング向け製品であるTeslaとしてTesla M2000シリーズを展開している。Tesla M2000シリーズは,Fermi世代のGPUを搭載するコンピューティングモジュールだ。
電話会議で新世代Teslaの説明にあたったのは,Tesla部門のディレクターを務めるSumit Gupta(スミット・グプタ)氏だが,氏は,Tesla K10が,Fermiベースの従来製品とは異なる領域をカバーする製品だと説明している。
Tesla K10は,信号&イメージ処理や,アンテナの設計などに応用されるキルヒホッフ型時間マイグレーションといった処理に適しているとのことだ。
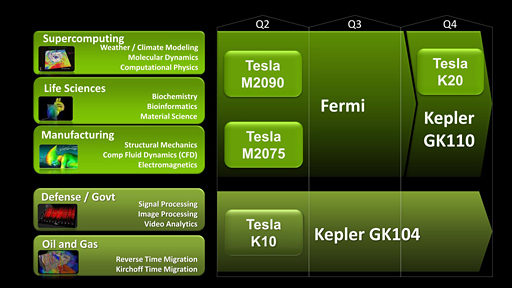 2012年のTeslaロードマップ。まず,Fermiベースの現行Teslaとは異なる領域に向けてTesla K10が登場し,第4四半期に,GK110コアを採用するTesla K20がTesla M2000シリーズの後継として登場の予定だ |
Tesla K10がFermiべースのTesla M2000を置き換えない理由は,倍精度浮動小数点数の演算性能でTesla K10がTesla M2000より劣るためである。
下に示したスライドはTesla M2000シリーズの最上位モデルである「Tesla M2090」とTesla K10とでスペックを比較したものだが,Tesla K10は単精度浮動小数点数の演算性能こそ非常に高いものの,倍精度浮動小数点数の演算性能になると2基のGPUを駆使してもTesla M2090の3割弱とまったく及ばない。そのためNVIDIAは,単精度浮動小数点数の演算性能が効く信号&イメージ処理などに適した製品と,Tesla K10を説明しているわけなのだ。
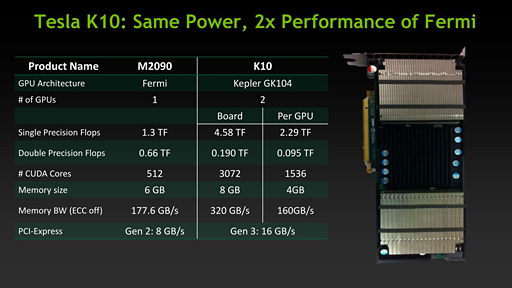 Tesla M2090とTesla K10のスペックを比較したスライド。倍精度浮動小数点演算の性能(※図中「Double Precision Flops」:)は2基のGK104をもってしても,「GF110」コアを搭載するTesla M2090に遠く及ばない |
「GeForce GTX 680」の発表にあたって,NVIDIAはGK104コアを「グラフィックス処理に特化した設計」だと述べていたが,そんなGK104をTeslaとして売っていくにあたり,「新たな分野に適するコンピューティングモジュール」と位置づけてきたのはなかなか興味深い。
一方,GK110コアを採用するTesla K20は,Tesla M2000シリーズと比べて倍精度浮動小数点数の演算性能が最大3倍に高められているという。
また,「Hyper-Q」「Dynamic Parallelism」という新要素のサポートも大きな特徴になるとのことだ。
 GK110を搭載するTesla K20は,従来製品比で倍精度浮動小数点数の演算性能が最大3倍に高められているとのこと。また,Hyper-Q,Dynamic Parallelismという2つの新要素がサポートされる |
一言でまとめると,Hyper-Qは,最大32のMPI(Message Passing Interface)タスクを実行できる機能だ。「Hyper-QによってGPUの使用率を上げ,ひいてはCPUが無駄に“遊んで”いる時間も削減できる」とGupta氏は説明していた。
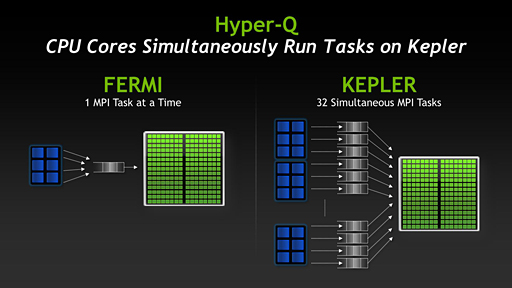 |
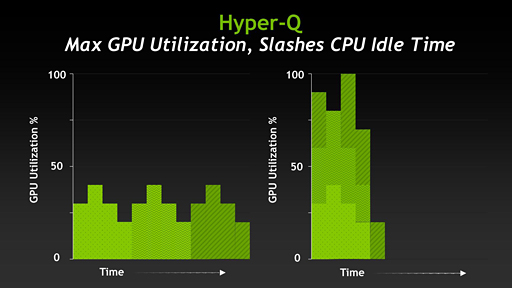 |
もう1つのDynamic Parallelismは,GPU内部で新たなGPUスレッドを生成できる機能である。
従来,GPUは,データを分割し複数のプロセッサで大量のデータを一斉に処理する「データ並列性」(Data Parallelism)という考え方を推し進めて進化してきたが,Dynamic ParallelismによってGPUが自力で異なるスレッドを生成できるようになると,CPUに近い「タスク並列性」(Task Parallelism,複数のプロセッサで複数のスレッドを並列実行する)という,データ並列性とは異なる方向へ踏み出せるようになる。ある意味ではパラダイムシフトに近い展開といっていいだろう。
Gupta氏は「GPUの応用範囲を広げる拡張」だと強調していたが,確かに相当興味深い機能だ。
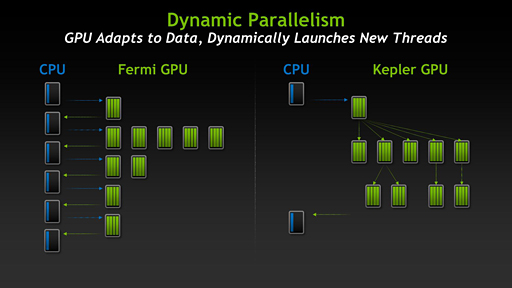 これまでGPUスレッドはCPUから生成させる必要があったのに対し,Tesla K20ではGPU内部からもGPUスレッドを生成させることができるようになる。これがDynamic Parallelismだ |
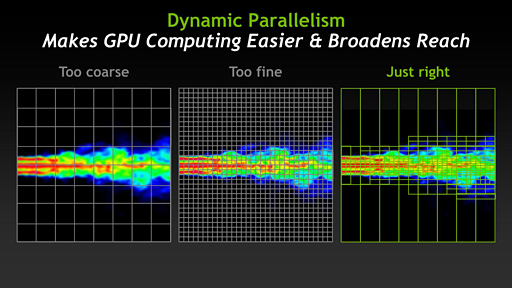 Guputa氏が「Dynamic Parallelismの応用例」として示した,メッシュを使った流体シミュレーションに関するスライド。メッシュを細かくすれば,より精度の高いシミュレーションができるが処理は重くなる。しかし,Dynamic ParallelismによってGPUが動的にメッシュのスレッドを生成することで,解析にかかる負荷を抑えつつ,精度の高いシミュレーションを行えるようになるという |
 Tesla K10&K20ではSMXを採用する |
SMXによって「Keplerは従来の3倍の電力性能を持つ」(Gupta氏)そうで,氏は「2年前,東京工業大学は1 PFLOPSのスーパーコンピュータを構築したが,それには42の(サーバー)ラックが必要だった。しかしKeplerなら,わずか10ラックで1 PFLOPSの性能が得られる」と具体例を挙げて,その電力性能の高さを強調していた。
 Windows上のVisual Studio向けだったParallel Nsightが,Linux&MacOS上のEclipseでも利用できるようになる |
これまでWindowsの「Visual Studio」のみの対応だったCUDAデバッガ「Parallel Nsight」が,LinuxおよびMacOS上の「Eclipse」にも対応する点や,ネットワークを介して他のGPUと協調できる「GPUDirect」がKepler世代のGPUでサポートされるというのが後者のトピックだ。
もう1つ,サードパーティのGPUライブラリなどをリンクできる「Library Object Linking」も,汎用コンピューティングプログラムの高速化を容易にする機能として注目されるところである。
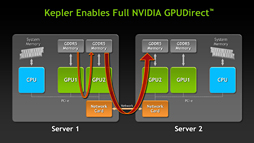 ネットワークを介して他のGPUと協調可能なGPUDirectがサポートされる |
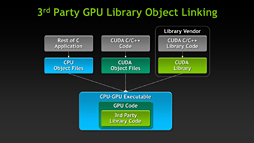 他社製のGPUライブラリなどを自分のオブジェクトにリンクできるLibrary Object Linkingが利用可能に |
従来のCUDAと同様,CUDA 5はNVIDIAの開発者向けサイトでダウンロード提供されるので,興味がある人はチェックしておくといいだろう。なお,CUDA 5の詳細はGTC 2012の会期中に公開される予定だ。
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- 関連タイトル:CUDA
- この記事のURL:
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー