










ニュース
これで分かるOpenCL。NVIDIAのOpenCLセミナーから,OpenCLの正体と可能性を再確認する
 |
OpenCLは,NVIDIAの「CUDA」(Compute Unified Device Architecture)や,DirectX 11の「DirectCompute」などと同じく,GPUコンピューティングを実現する仕組みの一つである。
GPUコンピューティングアーキテクチャとして,自社のCUDAを強力にプッシュしているNVIDIAが,なぜOpenCLなのか。NVIDIAは,開発者向けイベントの冒頭でわざわざ説明したほどなので,それだけ,OpenCLの立ち位置,そしてCUDAとの関係はまだ理解されていないということなのだろう。実際,さっぱり分からんという読者も少なくないと思う。
今回は,OpenCL seminarの技術セッションにおける講演やQ&Aの内容を中心に,このあたりを整理してみたい。
GPUで動作させるプログラムを
いかにして作成するか?
CPUとは異なり,比較的単純な構造の演算器を大量に搭載するGPUは,大量のデータに対して,同じ演算を行うような処理に適している。データを大量に処理していくというのは,CPUが苦手としている分野なので,この部分をGPUに処理させれば,PCをより効率的に利用できる。
――これが近年,GPUを「グラフィックス描画用プロセッサ」という枠を超えて利用しようという,GPUコンピューティング,あるいはGPGPU(General Purpose GPU)と呼ばれる概念だ。
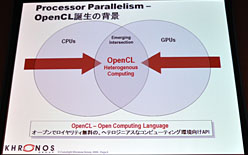 |
| OpenCLを策定したKhronos GroupによるOpenCLのイメージ |
 |
| CPUとGPUを並列動作させるオープンなフレームワークとして,Khronos GroupはOpenCLを位置づける |
このように種類の異なるCPUとGPUを混在させて利用するタイプのコンピュータを,最近はヘテロジニアス(Heterogeneous,異種混合)な並列環境などと言ったりもする(※NVIDIAはヘテロジニアスではなく,「Co-Processing」という言葉を好んで使うようになっている気配だが)。
ともあれ,GPUコンピューティングを実現するためには,「CPUがGPUを制御して,GPUにプログラムを実行してもらう仕組み」が必要になる。先ほどOpenCLやCUDA,DirectComputeを「仕組み」と呼んだのはそのためだ。
冒頭で述べたとおり,このなかでCUDAが特異なのは,NVIDIA製GPUに特化したデザインになっているということ。逆にいえば,OpenCLやDirectComputeはそうでないわけだが,今回はOpenCLが主役なので,OpenCLを中心に,CUDAなどとの関係性を考えてみることになる。
 |
氏はまず,OpenCLを「ヘテロジニアスな並列環境のためのフレームワークで,あらゆるプロセッサで動作することを想定しているもの」と定義する。CPUによるエミュレーションが可能とはいえ,CUDAやDirectComputeは対象をGPUに絞り込んでいるが,OpenCLは,GPUだけでなく,例えばDSP(Digital Signal Processor),あるいは4Gamer的にはPlayStation 3のCPUとして知られる「Cell Broadband Engine」(以下,Cell)などでも利用可能なのが大きな特徴というわけだ。
本稿では以下,便宜的に,GPUやDSP,Cellの各コア「SPE」(Synergistic Processor Element)といった,実際にOpenCLの演算を担当するプロセッサを「演算デバイス」,x86 CPUやCellの「PPE」(PowerPC Processor Element)など,演算デバイスを制御する側を「制御ホスト」と呼ぶことにしよう。これら演算デバイスや制御ホストは,単体で,あるいは(それこそCellのように)一つのプロセッサ内に統合される形で,NVIDIAやIntel,AMD,東芝,Freescale Semiconductor,Texas Instrumentsといったベンダーから提供されている。
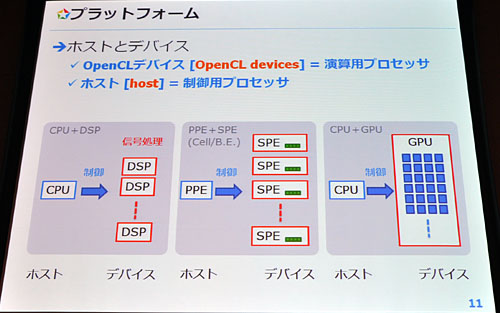 |
この状況を前にして,プログラマーが,これらさまざまな演算デバイスや制御ホストに向けて,対応ソフトウェアをバラバラに開発するのは効率が悪い。演算デバイスの活用によって,ある機能を実現しようと思ったときに,GeForce向けにCUDAのSDK(Software Development Kit,ソフトウェア開発キット)で開発しつつ,ATI Radeon向けにはAMD Stream SDKで,PlayStation 3向けにはソニー・コンピュータエンタテインメントのSDKで作っていくというのは二度手間,三度手間になってしまうからだ。
OpenCLが解消するのは,この「手間」であり,OpenCLでは,一度の手間で,さまざまな並列環境(=演算デバイスと制御ホストの組み合わせ)に対応したソフトウェアの開発を行えるようになる。
これを実現するに当たってクリアすべき条件は,“並列環境側”がOpenCLをサポートしなくてはならないこと。具体的には,演算デバイスや制御ホストを提供しているハードウェアベンダーや,サードパーティとなるソフトウェアベンダーが,大まかに,次に挙げる三つの仕組みを提供する必要がある。
- 「OpenCL Platform Layer」(OpenCLプラットフォームレイヤー)
OpenCLをサポートするプラットフォームの情報を得たり,OpenCLで作成したプログラムを動作させるためのリソースを得たりといった,OpenCLを利用するために無くてはならない足回りを実現する部分 - 「OpenCL Compiler」(OpenCLコンパイラ)
プログラマーは,「演算デバイス上で動作するプログラム」を作るためのプログラミング言語「OpenCL C言語」でソースコードを書くことになるが,そのソースコードを,演算デバイス上で実行できるバイナリ(※誤解を恐れず言い換えると,実行ファイルのようなモノ)に変換するもの - 「OpenCL Runtime」(OpenCLランタイム)
制御用デバイスから,演算デバイス上で実行できるバイナリを演算デバイスに読み込ませ,実行を指示し,実行した結果を制御用ホストに取り込むためのソフトウェア的なインタフェースを提供するもの
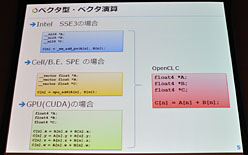 |
| SSE3,Cell,CUDA(対応GPU)では,同じ処理を行うにも,書くべきプログラムがまったく異なっていた。これに対してOpenCLだと,OpenCL C言語という1種類のプログラム記法で,さまざまな演算デバイスへ対応できる |
 |
| OpenCLを使うために必要な3要素 |
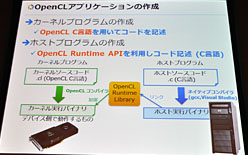 |
| OpenCLを使って演算デバイスを利用するイメージ。ホストプログラム(※ゲームプログラムなど,メインのプログラムのこと)から,OpenCL Runtime経由で,演算デバイスに「演算デバイス上で動作するプログラム」を実行させる。もちろん「演算デバイス上で動作するプログラム」を作成するのに使うのはOpenCL C言語だ |
このとき,制御ホスト上で動作しているゲームプログラムは,OpenCL Runtimeを使って「演算デバイス用のバイナリ」を演算デバイスに読み込ませて,実行を指示し,結果を返してもらうという流れになるわけだ。
ここで押さえておかなければならないのは,OpenCL C言語を元に作られた演算デバイス側のバイナリは,演算デバイスによって異なる(=互換性がない)こと。
OpenCLにおいて,演算デバイス側プログラムの互換性が保たれるのは,あくまでもOpenCL C言語で書かれたソースコードの段階まで。ベンダーの提供するコンパイラを使って,ソースコードをバイナリに変換すると,そのバイナリは,演算デバイスに依存したものになるのだ。
つまり,OpenCLを「演算デバイスの違いを完全に吸収して,演算デバイスが持つ最高のパフォーマンスを発揮してくれる仕組み」と捉えるのは,誤解ということになる。「OpenCL Cコンパイラを提供する各ベンダーには,OpenCL規格で定義されるOpenCL C言語の仕様を必ずサポートすることが求められているため,最終的にどんな演算デバイスを使うにしても,同じソースコードを利用できる」ことこそが,OpenCLの持つ最大のメリットなのである。
エンドユーザーから見た
OpenCLのメリットはどこにある?
 |
この世に流通しているすべてのGPUに対応したバイナリをすべて用意できれば,この問題は解決するが,言うまでもなく現実味は乏しい。そこでOpenCLには,実行時にソースコードを渡して実行するAPIが2種類,以下のとおり用意されている。
- clCreateProgramWithBinary():演算デバイスのアクセラレーションをバイナリで提供するAPI
- clCreateProgramWithSource():実行時にソースコードを渡して,その場でバイナリにコンパイルするAPI
 |
もっとも,ソフトウェアベンダーがどちらを選択するかは,今のところ何ともいえない。後者の場合,そのまま実装してしまうと,ソースコードが第3者に見られてしまうため,実際には暗号化が必要だったり,コンパイルに時間がかかるうえ,コンパイルしたバイナリは演算デバイス側のメモリ上に置くしかないため,複数のバイナリをとっかえひっかえするような用途だと,演算デバイス側のリソースを相当量消費してしまうという課題もあるからだ。
ただ,OpenCLに,エンドユーザーが演算デバイスの違いを気にすることなく利用できる仕組みが用意されているという事実は,押さえておきたいポイントだといえる。
ちなみに土山氏は,さまざまなプラットフォームに対応したOpenCL環境が今年中に出揃うという見通しを示していた。また,氏が所属するフィックスターズも,同社のYellow Dog Linux上にCUDAとOpenCLの開発環境をセットにした製品や,x86 CPU向けOpenCL環境などをリリースする予定とのこと。
OpenCLを取り巻く開発環境が整ってくる2010年以降は,いよいよ,エンドユーザーの元へも,さまざまメリットがもたらされることになるはずだ。
OpenCLとCUDAの関係を再整理
〜NVIDIAはGPUコンピューティング発展を目指す
最後に,OpenCLとCUDAの関係をあらためて整理しておくことにしよう。ここまで述べたとおり,OpenCLは,Platform LayerとCompiler,Runtimeが用意されていれば,演算デバイスに限定されずに利用できる。対するCUDAの場合,NVIDIA製GPU限定という制約がある一方で,NVIDIA製GPUの機能をフルに生かしたアプリケーションの開発を行えるというメリットがあるわけだ。
 |
OpenCLは,CPUやGPUだけでなく,世の中にあるさまざまなプロセッサを演算デバイスとしてサポートする都合上,ハードウェアの構造に依存した細かな制御を行うのは難しい。基本的には,メモリ階層をを大まかにしか制御できないのである。
この点,CUDAでは,NVIDIA製GPUに特化した,きめ細かなメモリ制御が可能だ。換言すれば,CUDAではデータを置く場所を最適化しやすく,OpenCLよりもパフォーマンスを引き上げやすいということになる。
 |
デベロッパは,OpenCL C言語のソースコード一つで,AMD製GPUやコンシューマゲーム機に対応させつつ,CUDA C言語をベースにNVIDIA製GPUへの徹底的な最適化を行うことで,技術的な優位性をアピールしたり,もっと露骨な話をすれば,それによってNVIDIAからの技術的,マーケティング的,金銭的援助を得たりできるのである。
いずれにせよ,AMDがCUDAを牽制するときによく使う,「3dfxのGlideと同じように,特定のGPUに依存したCUDAは,OpenCLなどに取って代わられる」という話は,CUDAに最適化したほうがより高いパフォーマンスを得られることと,開発環境の整備でOpenCLよりもCUDAのほうが進んでいることを踏まえるに,少なくともすぐ起こるようなことではない。
しかも,NVIDIAの立場からすると,CUDAとOpenCLは競合しているにあるわけではなく,むしろパフォーマンスと互換性の面で相互補完の関係にある。OpenCLの普及を後押しすることにより,GPUコンピューティングの普及を図り,ひいては,性能面,機能面で優れるCUDAともども,GPUの利用を加速させるのが狙いである。おそらく今後もNVIDIAは,独自の立場から,OpenCLをプッシュしていくはずだ。
ゲーマーの立場からすると,「OpenCLでもCUDAでもDirectComputeでも,何でもかまわないから,GPUコンピューティングにより,次世代感を感じさせてほしい」というのが本音だが,汎用性の高いGPUコンピューティングの仕組みであるOpenCLが花開く可能性は十分にある。そう簡単に,ぽこぽこと対応タイトルが出てくるとは思えないが,見守っていくだけの価値はあるだろう。
- 関連タイトル:
 CUDA
CUDA
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー