




![[COMPUTEX 2006#11]効果物理アクセラレーションはRadeon X1000が本命? ATI,“Radeon 3枚差しHavok FX”の詳細を公開](/image/rss_noimage_w2400.png)








ニュース
[COMPUTEX 2006#11]効果物理アクセラレーションはRadeon X1000が本命? ATI,“Radeon 3枚差しHavok FX”の詳細を公開
 |
そう,これはCOMPUTEX TAIPEI 2006のレポート#02でお伝えしている,Intel基調講演で公開された「Havok FX」のデモシステムだ。
■あらためて確認するHavok FXの仕組み
「Havok FX」は,Havokの物理シミュレーションミドルウェア「Havok 4 SDK」に統合される「効果物理(Effects Physics)」のサブシステムである……というのは,レポートしたとおり。
このHavok FXによって実現される効果物理を,GeForce 6/7シリーズのGPU(グラフィックスチップ)でアクセラレートする仕組みは,GDC 2006でNVIDIAが発表済みだ。今回発表されたのはそのATI版とでもいうべきもので,Radeon X1000シリーズを利用して,アクセラレーションを行う。
 |
さて,この剛体の衝突物理の処理で負荷がかかるのは,登場する剛体同士の相互衝突判定と,衝突後の挙動の更新だ。
Havok FXでは,こうした処理をGPUのピクセルレンダリングパイプラインに流し込んで処理する。さらに細かくいえば,衝突する可能性を秘めているオブシェクトのペアを見つける処理と,衝突処理の結果(次にどの方向に向かうか,速度や加速度はどう変化するか)を反映する処理を,ピクセルレンダリングパイプラインで実行しているのだ。
実際の「何と何が衝突したか」という判定と,それにまつわる処理系はHavok FXにおいてもCPUで処理されている。GPUで100%処理されるわけではない。
ちなみに,この「CPU側に戻される」ことは必ずしもデメリットばかりではない。ゲーム進行に関わる“親”物理ともいうべき物理処理「ゲームプレイ物理」(Game Play Physics)を介入させられることにもつながる。
■「効果物理のアクセラレーションはRadeon X1000シリーズのほうがGeForceより有利」
さて,ATIのロシア担当広報で,物理シミュレーションに詳しいNick Radovskiy(ニック・ラドフスキー)氏は「効果物理のアクセラレーションでは,NVIDIAのGeForceシリーズよりもRadeon X1000シリーズのほうが優れている」と切り出すところから,プレゼンテーションを開始した。
 |
この処理系において,各ピクセルシェーダユニットに専属の分岐ユニットを実装するRadeon X1000シリーズのアーキテクチャは有利に働くと,Radovskiy氏はいう。
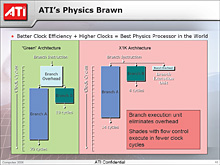 |
具体的に説明すると「衝突スレッドA」の分岐結果が「衝突後の処理」に進み,「衝突スレッドB」の分岐結果が「衝突しなかった場合の処理」に進んだとき,Radeon X1000シリーズでは並列実行が可能なのだ。ちなみにRadeon X1000シリーズでは,衝突スレッドは1ピクセルシェーダユニット当たり16スレッドを処理する。これはもちろん,Radeon X1000シリーズのピクセルレンダリングパイプラインが4×4ピクセルの処理をひとかたまりとしていることから来ている。このあたりの仕組みについての詳細は,筆者の連載でRadeon X1800やRadeon X1900シリーズについて解説した回を参照してほしい。
これに対して,GeForce 6/7シリーズのピクセルシェーダユニットには専属の分岐ユニットがないため,分岐時にレイテンシが発生する。さらに分岐先の同時実行もできないので,分岐処理時のオーバーヘッドが大きくなるという。
また,単純にトップエンドで比較すれば,GeForce 7900 GTX/GTのピクセルシェーダユニットが24基なのに対し,Radeon X1900 XTX/XTは48基であり,単純な数の比較でもRadeon X1000シリーズが有利とのことだ。
■Radeon X1000シリーズの物理シミュレーション処理能力
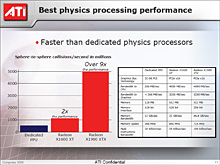 |
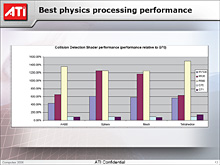
ATIの実験によれば,単位時間あたりに行える球状衝突判定量で比較すると,Radeon X1600 XTには,AGEIA Technologies製物理演算チップ「PhysX PPU」の2倍の処理性能があると判明しているとのことだ。Havok FXは効果物理のアクセラレーションだけなので,ゲームプレイ物理のアクセラレーションまでが行えるPhysX PPUが劣っているという短絡的な判断はできないが,このデータを信じるなら,効果物理に関していえば,Radeon X1600 XTで必要十分なパフォーマンスが得られることになる。
 |
Radeon X1000シリーズが強力な物理シミュレーション処理能力を持っていることを踏まえて,プライベートブースでRadeon X1000シリーズを3枚差したシステムを展示,披露したというわけである。
展示されていたシステムは,2パターン。一つは,Intel 975X Expressチップセットを搭載し,PCI Express x16スロットを3本用意したIntel製マザーボード「D975XBX」を利用し,Radeon X1900 XTを3枚差し(正確にはRadeon X1900 XTが2枚と,Radeon X1900 CrossFire Editionが1枚)したシステムだ。このシステムでは,2枚がCrossFire動作し,1枚がHavok FXの動作に専念する仕様になっていた。
ただし,各PCI Express x16スロットに割り当てられるレーン数には制限があり,このデモにおいては,CrossFireの2枚が各8レーン,Havok FX専任の1枚は4レーン接続になっているという。
もう一つは「効果物理のアクセラレーションなら必要十分」とされた,Radeon X1600 XTを利用したデモだ。
こちらは,Intel製CPU用チップセットとなる,未発表のチップセット「RD600」(開発コードネーム)ベースのマザーボードを使用。いずれも16レーンで動作する,2本のPCI Express x16スロットにRadeon X1900 CrossFire EditionとRadeon X1900 XTカードを差してCrossFire動作させ,2枚の間にあるPCI Express x1スロットに,Radeon X1600 XTを差すという構成だ。Radeon X1600 XTは,x1→x16のスロット変換アダプタを挟み込んで,半ば強引に差している。
スロット幅をPCI Express x16にしたところで,伝送は1レーンで行われるため,素直にPCI Express x1仕様のRadeon X1600 XTカードを差すほうがスマートだが,そういったデザインのカードがないため,このような形のデモになったのだという。Radovskiy氏いわく,「変換アダプタを実際に発売する計画はない」とのことで「あくまでコンセプトの展示」ということらしい。
 |
 |
 |
ちなみに同氏は,2個のGPUでグラフィックスレンダリング,1個のGPUで物理アクセラレーションを行うシステムを「2+1」,1個のGPUでグラフィックス,1個のGPUで物理を行わせるシステムを「1+1」と表現。このように,GPUに異なる仕事を行わせるシステムを「非対称コンフィグレーション(Asymmetrical Configurations)」と呼称した。
なお,1+1はともかく,2+1システムに関しては,どのような形でユーザーに提供するかの方針はまったく決まっていないとのこと。現時点で2+1の3枚差しシステムは,モーターショウでいうところの「コンセプトカー展示」という位置づけと捉えたほうがいいだろう。
 |
 |
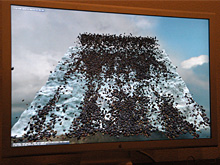
Radovskiy氏はプレゼンテーションの最後に,実際にRadeon X1900 XTの2+1システムを利用して,Havok FXのアクセラレーション性能を披露した。
デモは15000個の岩を斜面から転がすというもので,Core 2 Duo E6700/2.66GHzによるソフトウェア処理だと平均フレームレートが6〜7fpsに留まるのに対し,この2+1システムでは,60〜70fpsをマークしていた。
 |
 |
■次なるステップはゲームプレイ物理のアクセラレーションか
 |
やはり,ゲームの進行を司るのはCPUの仕事であり,そこまではGPUが介入できるものではないからだ。
次なるテーマはやはり,ゲーム進行やゲームロジックに関わる物理シミュレーションである「ゲームプレイ物理」を,GPUでアクセラレーションするパラダイムではないだろうか。
この点について,Radovskiy氏は,あくまで個人的な意見であると断ったうえで,次のように述べる。
「ゲームプレイ物理をGPUでアクセラレーションすることは十分可能だ。しかし,そうなると,ゲーム設計がGPU性能に依存してしまい,ゲームの設計そのものが難しくなる。そのため,ゲームの開発者はそうした技術を活用するのにあまり積極的にならないと思う」
現在のHavok FXもATI用とGeForce用には別バイナリが必要であり,GPUの性能がハイエンドとバリュークラスとで異なることまで考えると,確かにゲーム進行に無関係な効果物理はスケーラビリティの面で実装が簡単だ。性能の低いGPUを利用するときは,それこそ“割れた岩の破片”を少なくすればいいだけだし,その破片は散らばるだけでゲーム進行には何の影響も及ぼさない。
ところが,ゲームプレイ物理の場合,登場する敵や障害物の数が異なれば,ゲームのルール設定やバランス面の設計までもスケーラブルにする必要がある。これは,簡単なことではない。
とはいえ,「ゲームプレイ物理も演算精度や演算頻度の側面でスケーラビリティを設ければ,ある程度は対応できる」と言われている。例えば,高性能なCPUを搭載するシステムにおいては,物理シミュレーションの演算頻度を毎フレーム行うが,そうでないCPUでは数フレームごとに行い,間を線形補間でつなぐという実装を行っているゲームタイトルも,現時点ですでに存在する。
WinHEC 2006のレポートで述べたように,Windows Vista+DirectX 10.1世代では,GPUが完全に仮想化されて,システムから“自由に使えるコプロセッサ(CPUの補助をするプロセッサ)”として見えるようになる。この時代になれば,そうした実装はより実現されやすくなるだろう。
GPUと物理演算の関係はまだ始まったばかり。今後の動向に注目していきたい。(トライゼット 西川善司)
- 関連タイトル:
 ATI Radeon X1900
ATI Radeon X1900
- 関連タイトル:ATI Radeon X1600
- 関連タイトル:Havok
- この記事のURL:
キーワード
- ニュース
- HARDWARE
- GPU
- Radeon
- イベント
- COMPUTEX TAIPEI 2006
- COMPUTEX(旧称:COMPUTEX TAIPEI)
- AMD
- ライター:西川善司
- HARDWARE:Havok
- Havok.com
(C)2006 Advanced Micro Devices Inc.
(C)2006 Advanced Micro Devices Inc.
(C)Copyright 1999-2008 Havok.com Inc (or its licensors). All Rights Reserved.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー