










イベント
対話AIの最新動向をスクウェア・エニックスの三宅陽一郎氏らが紹介した,ラウンドテーブル「2020年AI動向総括と会話型AIの最新研究」をレポート
 |
※12月25日追記:スライドを正しいものに置き換えました
三宅陽一郎氏が語る対話AIの現状と課題,そしてゲームとの関係
 |
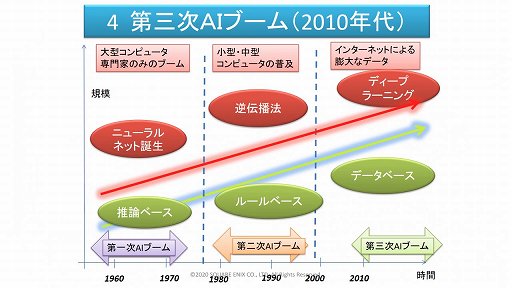
また対話AIについては,Googleの自然言語処理モデル「BERT」や深層学習モデル「Transformer」といったディープラーニング技術の台頭によって,対話技術が向上。それに伴って,対話AIを使ったキャラクターが世界中で開発されるようになった。さらにスマートスピーカーの登場と普及によって,AIへの命令に音声を使うことに対する人々の抵抗感が減ったことも挙げられた。
加えて三宅氏は,コロナ禍により対人を避けるケースが増え,人間ではないキャラクターの需要が人々に認識されたとする。そして2021年以降は,対話AIのより大きなムーブメントが来るだろうと予想した。
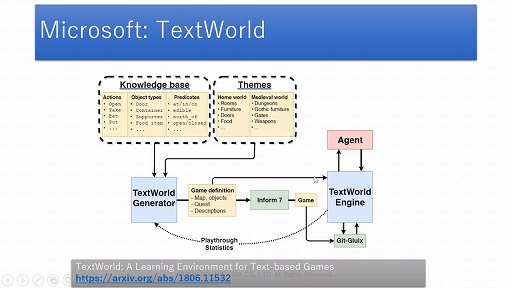
しかし,対話AIの開発には課題もある。まず挙げられたのは,対話の生成を実現するには大量の学習用データ(コーパス)が必要となるのだが,それをどのように作成するかというもの。また英語や中国語と比較すると,日本語のデータは少ないと三宅氏は指摘する。
さらに対話評価の課題も示された。例えば,AIの受け答えがおかしいかどうかは人が評価するのが一番いいのだが,それでは四六時中AIに誰かが張り付いていることになる。そこで人ではない指標による評価,すなわち評価の自動化について研究開発を進める必要がある。
 |
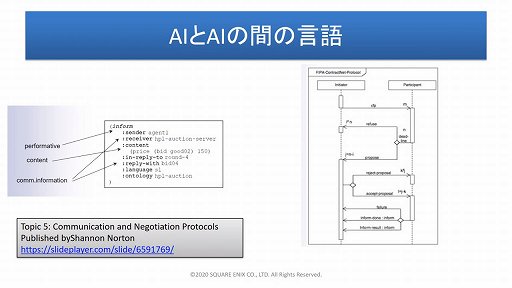
「言語AIの基礎」というテーマでは,AIと人間の対話では自然言語が使われるが,AI同士の会話にはAI専用言語(Agent Communication Language,ACL)が使われていることが紹介された。
 |
 |
 |
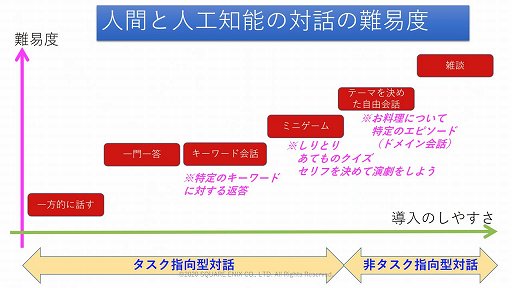
またAIと人間の対話では,雑談がもっとも難度が高く,次いでテーマを決めた自由会話,しりとりなどのミニゲーム,特定のキーワードに対する回答,FAQなどのような一問一答,そしてAIが一方的に話すことの順に難度が低くなっていく。このうち雑談とテーマを決めた自由会話は,目的を持たない「非タスク指向型対話」に分類され,現在のAIにとっては苦手な分野となっているそうだ。
 |
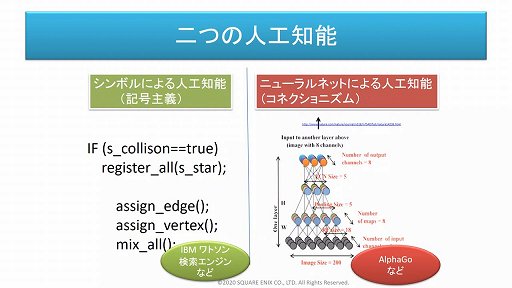
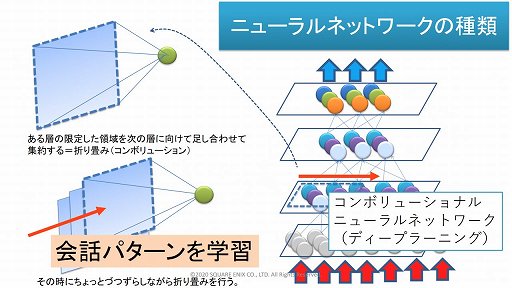
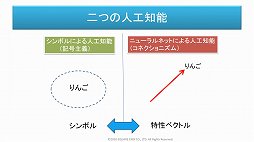
セッションでは,AIがシンボルによる人工知能(記号主義)と,ニューラルネットワークによる人工知能(コネクショニズム)という2系統で,長らく研究が進められてきたことも改めて紹介された。
 |
 |
 |
 |
 |
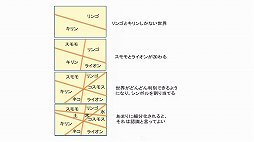
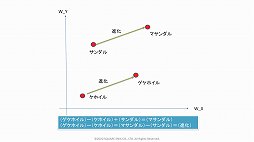
三宅氏によると,言語分野ではこの2種類のAIが融合しつつあるという。つまり100次元,200次元といった多次元の言語空間を設定し,シンボルに数学的な座標を与えてAIに認識させるのである。こうすることによりニューラルネットワークは,りんごとみかんとすももが座標的に近い場所にあると認識し,それらが果物に分類されると認識できるのである。
 |
 |
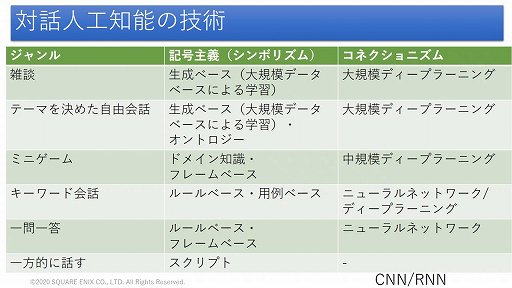
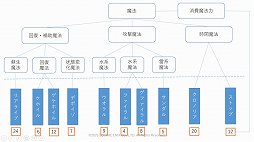
対話AIに使われる技術も紹介された。まずルールベースの技術は,「特定の言葉や話題が出てきたら,こう返答する」というルールを多数用意するというもので,簡単な会話ツールに採用される。
用例ベースの技術は,過去の会話の事例を多数参照し,もっとも適した回答を提示するというもので,Twitterなどの膨大な会話のやり取りを記録したデータベースと,高速な検索機能が必要になる。
そして生成ベースの技術は,学習によって対話を生成するもので,ディープラーニングや巨大なデータベースを必要とする。
三宅氏は,いずれの技術もカバーする会話の領域を大きくするために,巨大なデータが必要になるという難点を持っていることを指摘した。
 |
 |
 |
 |
 |
 |
 |
 |
 |
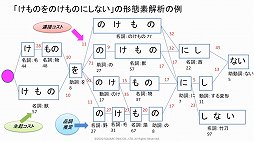
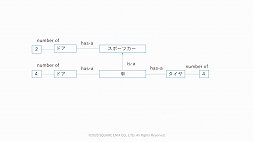
三宅氏によると,AIで対話を実現するための一番簡単な手段はフレームベースを作ることだという。フレームベースを作っておけば,例えばRPGならプレイヤーのプロファイルデータに設定された,さまざまな変数を使った会話が可能になる。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
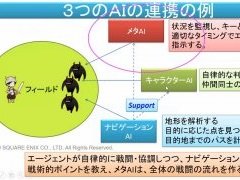
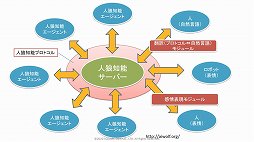
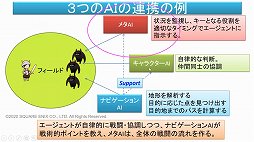
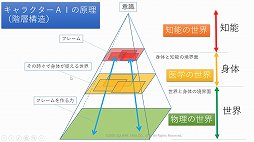
現在のゲームでは,3つのAIが連携しているという。通常,AIはテキストのみのコミュニケーションおよびコーパスによって学習し,人間との対話を行っている。しかしゲームの場合はキャラクターAIが身体を持っているので,ゲームの内部を世界として認識し対話を行っていくと三宅氏はまとめていた。
 |
 |
「会話型AIの基礎技術〜機械学習で会話の実現〜」
坪井氏は,rinnaが提供するチャットボット「りんな」の事例をベースに,AIの機械学習を用いた会話技術の基礎を紹介するセッションを行った。
チャットボットは人間のように会話ができるプログラムで,三宅氏が紹介したように多数のルールを用意するルール型(ルールベース)や,膨大な情報を学習して適した回答を生成するAI型(生成ベース),そして簡単なやり取りにはルール型が回答するが,内容が複雑になってきたら人間と交代するハイブリッド型がある。
 |
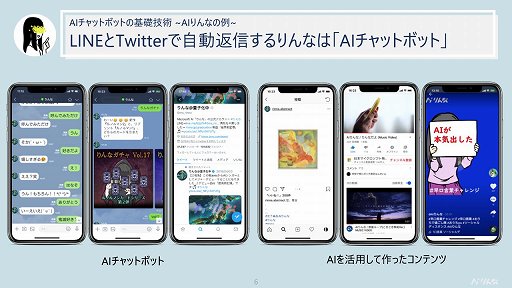
このうちりんなは,AI型のチャットボットにあたる。りんなはさまざまな活動をしているが,そのメインとなるのはLINE上での雑談や,Twitter上での自動返信だ。
チャットボットを開発するにあたっては,目的や用途に応じていくつかのアプローチが存在するが,rinnaでは「筋書きのない決まっていない自由な雑談を実現したい」という目的のもと,「AIで返答内容を作ろう!」というチャレンジを続けている。
 |
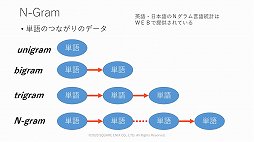
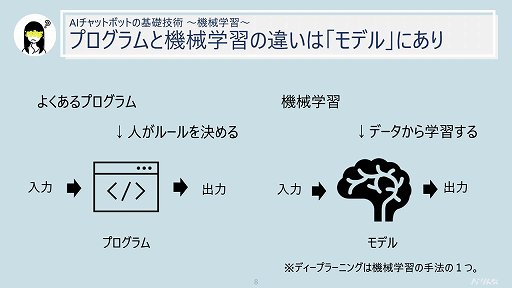
それではAIで使われる機械学習と,プログラムは何が違うのか。通常,プログラムは入力に対してどのように行動(出力)するべきかを人間が設定している。しかし機械学習では,「モデル」が大量のデータから行動を学習し,入力に対する適切な行動(出力)を取っている。
 |
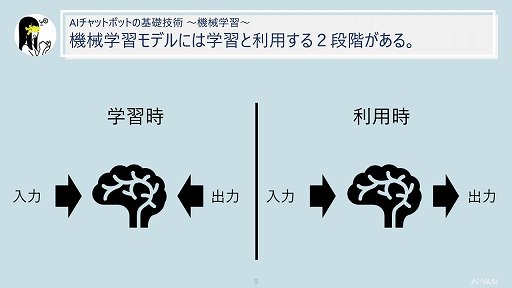
また機械学習モデルには「学習」する段階と,学習済みモデルを「利用」する段階がある。機械学習についての話題は,モデルが学習段階なのか利用段階なのかに気を付けて聞くと,より理解が深まる可能性があるとのこと。
加えて機械学習モデルは,入力と出力双方のデータを学習する必要がある。例えばテキストから音声を合成する場合は,テキストとそれに対応する音声データを大量に用意しなければならない。また音声認識をする場合は,音声とそれを書き起こしたテキストが必要になる。
そして会話をさせる場合には,質問に対する返答が必要であり,質問と返答のテキストデータを大量に用意することになるという。
 |
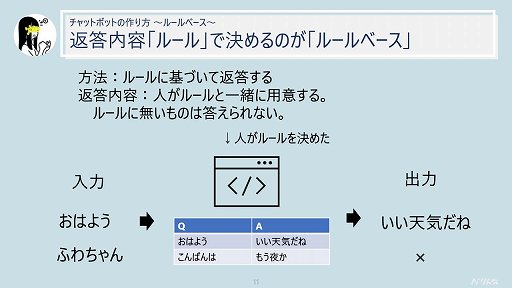
同じように見えるチャットボットでも,ルールベースのものとAIベースのものでは返答の違いがあることも紹介された。ルールベースのチャットボットは,人間がルールと一緒に返答を用意するので,ルールにないものは答えられない。例えば「おはよう」という呼びかけに天候に関する返答をするルールが定められていれば,チャットボットは「良い天気だね」という返答をする。しかし,タレントの名前を出されても,それに関するルールが用意されていなければ,チャットボットは対応できない。
こうしたルールベースのチャットボットは,タスクが明確に限定されていたり,ルールが定義できたりする「タスク志向型」のケースで用いられることが多い。
 |
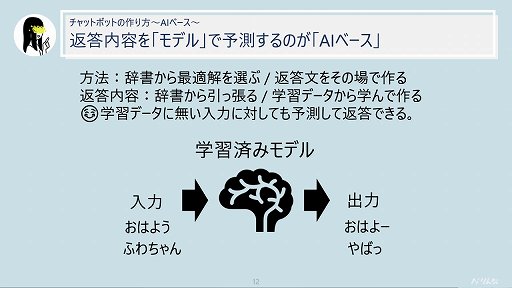
一方,AIベースのチャットボットは,学習済みモデルが辞書などのデータベースから最適解を選択する「辞書型」と,学習データから学んで返答を生成する「生成型」がある。
いずれのタイプも「こういう入力には,こう返答する傾向がある」ということを学習しているので,学習データにない入力に対しても予測して返答することが可能だ。ただし予測なので必ずしもその返答が正しいとは限らず,どのように精度を高めていくかが課題となっている。
 |
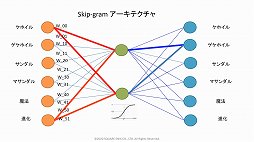
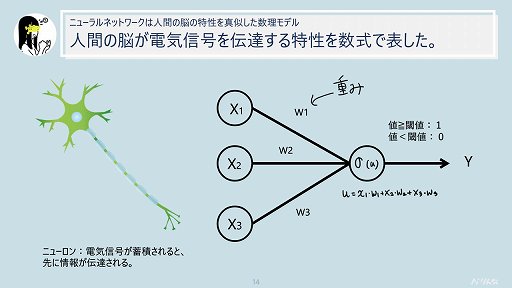
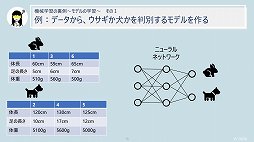
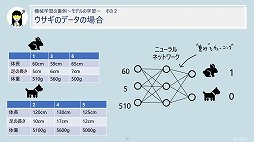
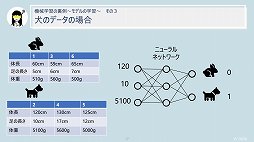
セッションの終盤では,機械学習で起きていることについて言及された。それによると,機械学習で使われるニューラルネットワークは,人間の脳を構成するニューロンが持つ「電気信号が蓄積されると情報を伝達する」という特性を数式化したものであるとのこと。
すなわち,ある変数に対して「重み」(重要性)という概念を付与して計算した値が,あらかじめ定めておいた閾値を超えたときに情報として伝達される。そうやって伝達される情報には,各変数に付与された重みの影響がある──つまり情報に重要性の高い変数の占める割合が高くなるというわけである。そしてニューラルネットワークとは,簡単に説明するとこの仕組みを無数に組み合わせて作られているイメージだという。
 |
 |
 |
 |
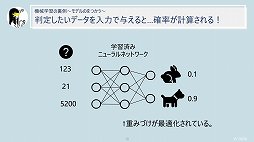 |
以上をまとめて坪井氏は,AIりんなのようなAIチャットボットは機械学習のアプローチを採用したものであることにあらためて言及し,セッションを締めくくった。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー