









ニュース
「Haswell」って何だ? 第4世代Coreプロセッサが採用するアーキテクチャのポイントを一気に押さえよう
 |
さて,実機による性能検証の結果は,別途掲載しているレビュー記事を参照してもらうとして,本稿では,第4世代Coreプロセッサ(以下,Haswell)の技術的なキーポイントを,判明している限りの情報を基にまとめてみたいと思う。「HaswellってそういえばどんなCPUなんだっけ?」と疑問に思った人は,ぜひ一読を。
チップセットを集積した“SoC”が登場するHaswell
方向性は明確に「薄型化」「省電力化」
別記事でお伝えしているとおり,6月2日時点でスペックが明らかになっているのは,ほとんどがデスクトップPC向けのクアッドコアモデルだ。だが実のところ,IntelがHaswellで力を入れているのは,UltrabookやタブレットPCなどのモバイルPC向けラインナップのほうである。これらは6月4日の正式発表で,詳細が明らかになると思われる。
 |
モバイルPCに向けてどれくらい力を入れているかは,下にまとめたラインナップを見れば一目瞭然だろう。
デスクトップPC向けモデルでは,「Unlocked」の「K」に,通常モデルとなる“無印”,省電力版となる「S」「T」といった具合に,製品ラインはいくつかあるものの,パッケージ自体は(一部の例外を除いて)LGA1150となる。
それに対してモバイルPC向けでは,CPUとPCH(Platform Controller Hub。いわゆるチップセット)の2チップ構成だけでなく,CPUとPCHのチップをワンパッケージに収めたモデルが用意され,しかもそれぞれ,ターゲットとなるプラットフォーム(≒UltrabookやタブレットPCといった製品ジャンル)ごとに,さらに細かく細分化されているのだ。
●デスクトップPC向けHaswellの製品ライン
- K-Processor Line:ハイエンドユーザー向けのUnlocked(倍率ロックフリー)版
- 無印:メインストリーム(≒ミドルクラス)市場向けの標準版
- S&T-Processor Line:省電力版
●ノートPC向けHaswellの製品ライン
- H-Processor Line:Intelが「Premium Notebook」(プレミアムノートブック)と位置づける製品ライン。BGAパッケージのクアッドコアCPU+PCH構成。「Intel Iris Pro Graphics」採用モデルあり
- M-Processor Line:μPGAパッケージのクアッドコア+PCH構成。ゲーマー向けノートPCで最もよく使われる製品ラインになると思われる
- U-Processor Line:Ultrabook向け製品ライン。デュアルコアCPU+PCHのBGAワンパッケージ。「Intel Iris Graphics」採用モデルあり
- Y-Processor Line:2-in-1,もしくはデタッチャブルと呼ばれる「キーボード部を取り付けるとノートPC,取り外すとタブレットPC」向け製品ライン。デュアルコアCPU+PCHのBGAワンパッケージ
以下本稿では,「H-Processor Line」「M-Processor Line」といった表記の代わりに「Hシリーズ」「Mシリーズ」と表記していくが,このなかでも目玉となるのが,CPUとPCHをワンパッケージ(≒1チップ)化したUシリーズとYシリーズである。
「CPUとPCHをワンパッケージ化した」というのがどういう意味なのかは,下に示したスライドの左半分を見てもらったほうが早いだろう。長辺の長い長方形に,CPUダイとPCHが載り,パッケージ上で接続される仕様となっている。Intelはこのマルチチップパッケージを「SoC」(System-on-a-Chip)と位置づけているが,ARMアーキテクチャの普及によって,1チップSoCで構成されるモバイル機器が当たり前になってきたことに対する,Intelの回答ともいえそうだ。
なお,下のスライドで右に見えるのは,HシリーズとMシリーズで採用される,従来どおりな2チップ構成のイメージである。
 |
Intelは4つの製品ライン中3つで,CPUソケットを採用せず,マザーボードに直づけするBGA(Ball Grid Array)パッケージを採用した。そして,3つのBGAパッケージ中2つで,CPUとPCHのマルチチップ化を実現したわけだが,その目的は端的に述べてPCの小型軽量化と省電力化の2点だ。
「小型軽量化は何となく分かるけど,何が省電力化と関係があるの?」と思う読者も多いと思われるので,少々長くなるが,Haswellにおける省電力関連技術の詳細から説明していきたいと思う。
モバイルPC向け製品ラインでは
より深い省電力ステートをサポート
今日(こんにち)のCPUでは,負荷がないときには,ステート(State,状態)と呼ばれる動作モードを省電力仕様に切り替え,次の仕事を待つ仕組みが広く使われている。PCのCPUでは,ステートは「C-State」(以下,Cステート)という名前で呼ばれるのが(業界内部では)一般的だ。これはPCの電力制御に関する業界団体が策定したACPIという規格で規定されているものとなる。
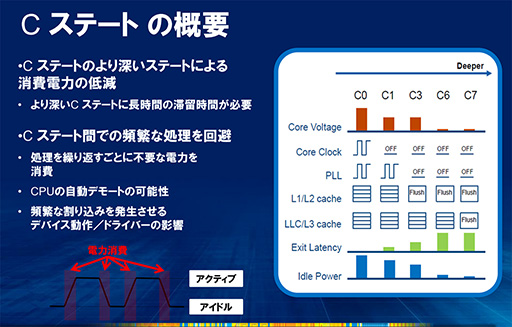
Intelのデスクトップ向けCPUでは,全力疾走状態の「C0ステート」に加え,電力消費を抑えた「C1ステート」(スタンバイ状態)と「C3ステート」(スリープ状態)という3段階のステートが使われている。また,モバイル向けでは,さらに省電力化を推し進めた「C6ステート」が採用され,一世代前の「Ivy Bridge」(アイヴィブリッジ)こと第3世代Coreプロセッサからは,CPUがほとんど電力を消費しないとされる「C7ステート」がサポートされている。
 |
複数のステートを用意したのは,簡単に言えば「仕事がないときには各部の電源を切って,電力消費を抑える」ためだ。人が就寝時に照明を消して寝るのと同じで,必要がない時は電源を切りましょうという理屈である。
このCステートの切り替えが極めて有効なのは,PCはほとんどの時間,仕事がないという事実があるためだ。たとえば,PCでゲームをプレイしている最中は,CPUもわりと忙しい。一方,Webブラウジングの最中などは,CPUにとっては暇な時間が多くなる。ユーザーがマウスをクリックしたり,キーボードを叩いたりした直後だけ仕事が発生する程度で,ユーザーが操作する合間の何もしていない時間は,CPUの処理速度から見れば,膨大な時間と言っても過言ではない。
Cステートは数字が大きいほど,消費電力が小さい。C0ステートは全力疾走で,つまり消費電力を抑えていない状態だ。C1ステート以上は以下のような区分けとなっている。
| C1ステート | コアクロックをオフにした“浅い”ステート。即座にC0ステートに戻せる。 |
|---|---|
| C3ステート | C1ステートの処理に加えて,内部のクロック生成回路「PLL」(Phase Locked Loop)をオフにする。C1ステートより省電力になるが,C0ステートへの復帰には少しだけ時間かかるようになる。 |
| C6ステート | C3ステートに加えて,L1/L2キャッシュのデータをL3キャッシュに移して,L1/L2キャッシュをオフにする。C0ステートへの復帰にはさらに時間がかかるうえ,C0ステートに戻った直後は,メモリアクセスに時間がかかるようになる。 |
| C7ステート | Ivy Bridgeで導入された,より“深い”Cステート。C6ステートに加えて,L3キャッシュの内容をメインメモリに書き戻して(フラッシュと呼ぶ),ここもオフにする。そのためC0への復帰には,より多くの時間を必要とする。 |
このように,Cステートの数字が増えるほど電気を切る部分が増えていくので,その分だけCPUの消費電力を減らせるわけだ。それなら,もっと多くの部分をオフにできれば,消費電力はさらに減らせることになる。そこでHaswellの“少なくとも”UシリーズとYシリーズには,従来よりも深いCステートとして,「C8,C9,C10」という3つのCステートが導入された。
“少なくとも”と述べたのは,UシリーズとYシリーズにC8,C9,C10ステートが導入されていることは明言されているものの,そのほかのシリーズに導入されているのかいないのか,明言している資料がないためだ。基本的には,省電力性能に対する要求が高い,UシリーズとYシリーズのために用意されたCステートと考えておけばいいだろう。C8,C9,C10ステートの内容は,以下のとおりだ。
| C8ステート | CPU内部の電源レール(内部の電力線のようなもの)をオフにして,入力電圧を1.2V以下に下げる。さらにPLLを完全にオフにして,外部から供給されるクロック(クリティカルクロックと呼ぶ)だけで動作を維持する。 |
|---|---|
| C9ステート | CPUコアに対する入力電圧もオフにする。 |
| C10ステート | CPU内部に組み込まれた「電圧レギュレータ」もオフにする。電圧レギュレータ(詳細は後述)はCPUの電源電圧を制御するものだが,それ自体も電力を消費するので,これを止めてしまう。 |
深いCステートに移行するほど,C0ステートへの復帰には時間がかかるようになる。たとえば,下のスライドにある「メモリアクセスレイテンシー」は,そのステートに移行したあとで,C0ステートに復帰してメモリアクセスが行えるようになるまでの時間のことだ。
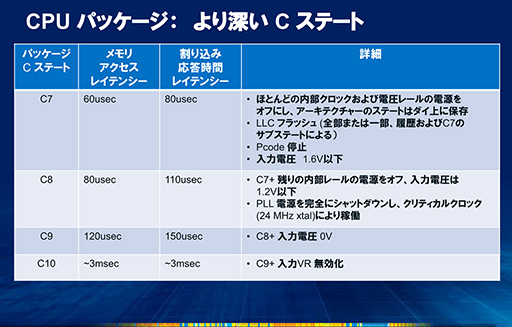 |
「割り込み応答レイテンシー」の「割り込み」とは,PC内部の機器や周辺機器が,CPUによる処理を要求していることを知らせる信号で,CPUをC0ステートに復帰させる引き金でもある。
PCではさまざまな機器や人間の操作が,割り込みを発生させている。たとえば,ユーザーがマウスをクリックすると,その操作を引き金としてCPUに割り込み信号が送られて,クリックを処理するプログラムを実行している。割り込み応答レイテンシーとは,周辺機器(や人間)のリクエストに対して,CPUが応じられるようになるまでの待ち時間,と考えればいい。
スライドを見ると,C10ステートの割り込み応答レイテンシーは,最大3msとある。したがって,3msよりも長い間,割り込みが発生しない状態が続かない限り,CPUはC10ステートに移行できないということになる。
つまり,HaswellではC8,C9,C10ステートがサポートされたといっても,それが適切な効果を上げるためには,深いCステートに移行できるように条件,つまり割り込みが発生しない時間を作ってやる必要があるわけだ。
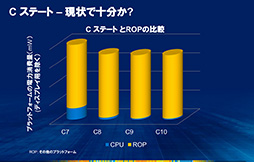 |
右のスライドは,CPUやディスプレイとそれ以外の部分が消費する電力を示したものだが,Haswellでより深いCステートを導入しても,それだけではバッテリー駆動時間が延びにくいのが分かるだろう。
そこでこうした問題を解決するために,Haswellで導入されたのが,次で説明する「Power Optimizer」(パワーオプティマイザ)である。
CPU以外の電力を抑えて,
深いCステートの時間を長くするPower Optimizer
Power Optimizerというのは,IntelからPCメーカーに提供されるフレームワーク(枠組み)のことだ。CPU以外のデバイスによる消費電力を抑えると同時に,CPUが深いCステートに長時間留まれるように,メーカーがチューニングを行うための情報や,解析ソフトウェアなどのツールなどが提供されている。
では,どうやってCPU以外の消費電力を抑えられるのだろうか? 先に割り込みという言葉が出てきたが,割り込みは「マウスのクリック」といった周辺機器が起こすものだけでない。たとえば,OSは自分の仕事をするため,PC内部で一定時間ごとに発生する定期的な割り込み,「タイマー割り込み」を利用する。
現在のPCでは,チップセットに「HPET」(High Precision Event Timer)という高性能なタイマーが内蔵されており,多くの場合,このHPETがタイマー割り込みを発生させている。その発生間隔はOSによって異なるが,Windows 7では10msだ。
前述したように,割り込みを受けたCPUはC0ステートに復帰して,OSが必要とする仕事,たとえば処理が必要なバックグラウンドプロセスを少し動作させるといった仕事をする。仕事が済んだら,またC1やそれ以上のステートに切り替わる,といった動作を繰り返している。
そこでタイマー割り込みの発生間隔,たとえばWindows 7なら10msの間,CPU以外のデバイスの電力も落としてしまえば,PC全体の消費電力をもっと抑えられるだろう,とIntelは考えた。しかし,それはCPUだけでは実現できず,CPU以外のデバイスやドライバソフトも,電力を落とす動作ができるように改良しなくてはならない。Power Optimizerとは,デバイスメーカーがそうした改良を行うためのフレームワークと考えていい。
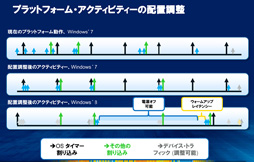
下のスライドは,改良された各デバイスの動作を図にしたものだ。横軸は時間の流れを示し,図の上に「Expected Sleep Duration」と書かれているのが,次のタイマー割り込みが発生するまでの待ち時間だ。その下には,CPUとメモリ,USBコントローラやSATAコントローラ(Controllers),さらにコントローラのための外部クロック(Clocks),電源(VRs,電圧レギュレータ)の動作状況が並んでいる。「Idle Window」と書かれた灰色の部分は,CPUと各デバイスが電源を落として,次のタイマー割り込みを待っている状態を示している。
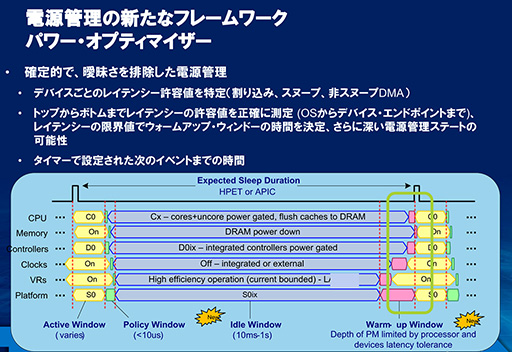 |
CPUがC0ステートに復帰するまでに時間を要するように,CPU以外のデバイスも,復帰には時間がかかる。そこでHaswellには,C0ステートに復帰するためのタイマーが内蔵されており,タイマー割り込みが発生する少し前に,各デバイスを目覚めさせて割り込みを待つという仕組みが用意された。図の右側にある「Warm-up Window」と書かれている部分がそれで,タイマー割り込み発生より少し前から,CPUや各デバイスが動き始めているのが分かるだろう。
ちなみにIntelは,タイマー割り込み待ちの間にデバイスの電源を落とすスリープ期間のことを,「S0ix」(エスゼロアイエックス)と呼んでいる。これはPCで一般的な電力制御規格「ACPI」が定義しているスリープモード,「S0,S1,S2」にならって命名したと思われるが,S0ixはACPIとは関係なく,IntelがHaswellに合わせて定義した,特殊なスリープ期間である。
話を戻そう。Warm-up Windowの長さや,各デバイスがタイマー割り込みを待てる時間はデバイスによって異なる。そのためデバイスメーカーは,IntelがPower Optimizerで提供するツールによって,Warm-up Windowの長さを変えたり,ドライバ側の割り込み処理を修正するといった調整を行うわけだ。
ただし,割り込みというのはタイマー割り込みだけではない。「キーボードが押された」とか「マウスがクリックされた」という動作も,CPUは割り込みとして受け取る。こうした割り込みはタイマーとは関係なく発生するので,割り込みがあるたびにCPUはC0ステートに復帰して,それに対処しなければならない。つまり,非同期の割り込みがある限り,CPUは落ち着いて深いCステートに入っていられない。
そこで,非同期に発生する割り込みをタイマーに同期させるように,Power Optimizerに含まれるツールで調節できるようになっている。
 |
さらにWindows 8では,OSに必要なタイマー割り込みがプログラマブルになり,タイマー割り込みを必要に応じて停止できるようになった。これにより,Windows 8でHaswellを使えば,さらに長い時間,深いCステートやS0ixに留まれる,つまりバッテリー駆動時間を長くできるようになるわけだ。
一見良いことずくめに聞こえるかもしれないが,課題も多い。まずこうした調節は,基本的にPCメーカーが行わなければならないが,これがかなり面倒なものになると思われる。なぜなら,割り込み処理に対する応答を待てる時間は,デバイスによって変わるからだ。
分かりやすい例が,サウンドカードやUSBサウンドデバイスだ。サウンドデバイスには,定期的にCPUからサウンドデータを送り込まないと,音切れが発生する。そのためサウンドデバイスがデータを要求する割り込みに,CPUは即応する必要がある。
したがって,PCメーカーが割り込みの最適化を行うには,割り込み処理に即応しなくてもいいサウンドデバイスを調達するか,自分で設計する必要がある。サウンドドライバ側も,タイマー割り込みに合わせて,割り込み処理への応答を遅らせる処理を組み込む必要があるかもしれない。
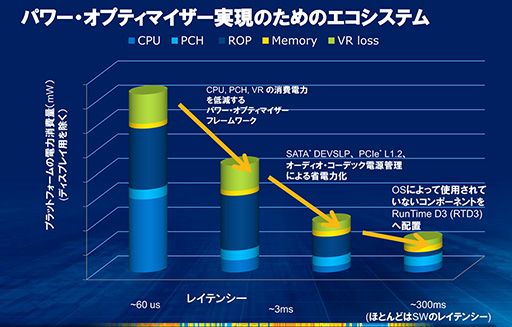
Intelも,Power Optimizerによる割り込みの最適化は,コストがかかることを認めている。そのためPower Optimizerには,PCメーカー側が選択できる“レベル”がいくつか設定されているようだ。たとえば,コストを抑えるためにCPUとPCH,電圧レギュレータだけを最適化するとか,もう少し手をかけてUSBやSATA,サウンドも最適化する,といった選択が可能となっているという。
下のスライドは,4段階の最適化レベル別に省電力効果を比較したグラフである。一番左はあまり手間をかけない例で,CPUとPCH,電圧レギュレータだけを最適化している。そのため消費電力はやや多い(縦棒が長い)ものの,レイテンシ(遅延)は短く,作りこみも楽になる。右に行くにしたがって最適化の手間が増えるものの,CPU以外の消費電力も抑えられて,消費電力も下がるというわけだ。
 |
要するに,Power Optimizerに従って,省電力を実現できるようどこまで作り込むかは,PCメーカー任せになる。ユーザーにとっては,Haswell世代のノートPCやタブレットPCでは,同じCPUやバッテリーを搭載するマシンであっても,「やや高価だがバッテリー駆動時間が長い機種」と「安価だがバッテリー駆動時間は短い機種」という差が出てくることを意味する,というのは覚えておいたほうがいいだろう。
ただし,コストをかけて省電力のために最適化したPCでも,最適化が簡単に崩れてしまう可能性があるという厄介な問題を抱えている。というのは,ユーザーがPCに接続する周辺機器も割り込みを発生させるからだ。
IntelがPower Optimizerで想定しているのは,バッテリーで動作する間は外付けの周辺機器を接続することがあまりない,UltrabookやタブレットPCのようだ。しかし,こうしたPCでも,ユーザーが何を接続するかなど分からない。割り込みに即応しなくてはいけないデバイスを接続した途端,割り込みの最適化が崩れて,うまく機能しなくなる可能性は高い。
Intelによると,Power OptimizerでデスクトップPCの消費電力を最適化することも不可能ではないそうだ。だが,内部に拡張カードやストレージを装着できるデスクトップPCの場合,最適化の努力などするだけ無駄になりそうで,そこまでするPCメーカーがあるとは考えにくい。
では,HaswellとPower Optimizerによる最適化は実用的ではないのかというと,そうとも言い切れない。Haswell搭載PCに適した,省電力に最適化された周辺機器が登場する可能性があるからだ。Intelは,Power Optimizerの最適化をできるだけ壊さない,省電力デバイスの設計を支援する情報を,周辺機器メーカーに提供するという。割り込み最適化に対応したり,タイマー割り込み待ちの間に短時間のスリープができる,S0ix対応の周辺機器などが,今後登場してくるかもしれない。
逆に,ゲーマー向けマウスの一部に見られる,スリープに入らない(Always On機能とも呼ぶ)タイプのデバイスは,Haswellの省電力機能にとって最悪の存在とも言えそうだ。なにせスリープに入ってくれないので,USBホストコントローラもスリープするわけにいかなくなり,S0ixは機能しなくなる可能性すらあるからだ。今後のゲーマー向けマウスも,Haswellに対応して省電力化に向けた改良が行われたりするのか,今はまだ分からない。
新たな熱設計指標
Scenario Design Power
新しいCステートにPower Optimizerによる割り込みの最適化を組み合わせることで,Haswellはとくにアイドル時において,極めて低消費電力になるとされている。UltrabookやタブレットPCなら,アイドル時の消費電力を100mW以下に抑える設計も可能という。
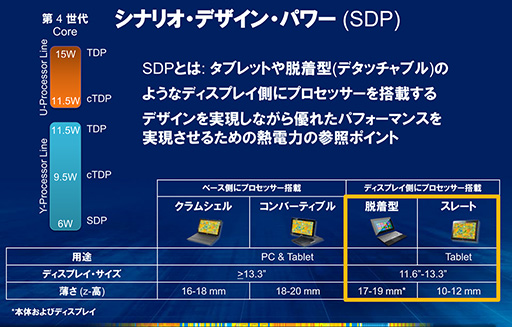
消費電力を抑えるということは,CPUから発生する熱も抑えられるわけだが,これらはユーザーの使い方によって,大きく変動するものだ。そこでIntelはHaswellで,従来の熱設計指標「TDP」に加えて,PCの使い方を考慮した新たな熱設計指標「SDP」(Scenario Design Power)を定義した。言うなれば「使い方のシナリオに合わせた熱設計値」といった意味だろうか。
そうは言っても,Haswellで実際にSDPが定義されているのは,タブレットPC向けのYシリーズのみだ。タブレットPCは薄いため,熱設計的に厳しいフォームファクタだが,その代わり処理負荷の高いアプリケーションを,長時間動かすような人はまれだろう。そこで,「タブレットPCに必要とされる程度の性能」で動作させたときの発熱を基準とした放熱設計の基準値をSDPという形で示してきたわけだ。
 |
PCの性能を重視するゲーマーにはほとんど関係なさそうな用語だが,Haswellにおける重要な初出キーワードとして覚えておくと,Haswellや今後のCPUに関するニュース記事などが読みやすくなるだろう。
電圧レギュレータを内蔵するHaswell
Haswellが新たなCステートを導入できた背景には,よりきめ細かな電力制御が可能になったという理由があるようだ。
ご存知の読者も多いと思うが,現在のCPUはマザーボード上の電圧レギュレータ(Voltage Regulator)から,複数の電源を供給されている。CPUにはいまや,メモリコントローラやPCI Expressインタフェースを司る「MCH」に加えて,GPUまで集積されるのが当たり前になった。そのため供給すべき電源ラインの数が増大している。
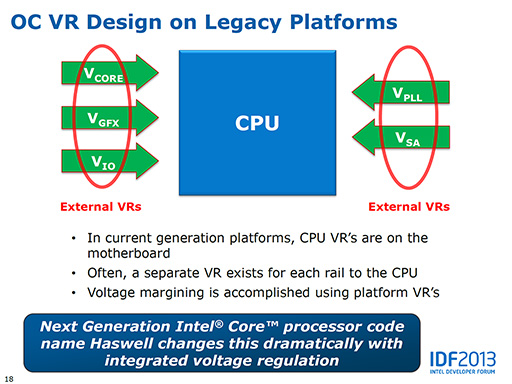
下のスライドは,Ivy Bridge世代の電源ラインを示したもので,メモリインタフェースの電源(VDDQ)が描かれていないので5本しかないが,実際には次の6本の電源ラインが供給されている。
- Vcore:CPUコア電圧
- Vgfx:GPUのコア電圧
- Vio:I/O電圧
- Vpll:内部PLL電圧
- Vsa:MCH機能の電圧
- VDDQ:DRAMインタフェース電圧
 |
これらの電源ラインは,負荷に応じて適切に電圧を制御する必要があるが,マザーボード上の電圧レギュレータはCPU外部の回路であるため,制御のきめ細かさには限界がある。
そこでHaswellでは,電圧レギュレータをCPUコアに内蔵してしまった。外部から供給される電源ラインは2本だけとなり,あとはCPUコア内部の電圧レギュレータ(iVR)で,複数の電源ラインを作り出して各部に供給しているわけだ。
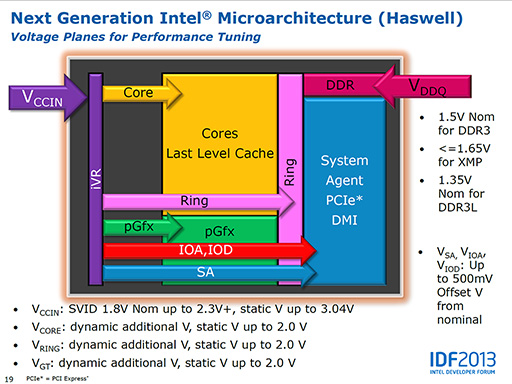 |
電圧レギュレータをCPU内部に組み込むというのは,実はかなりの難題だ。電圧レギュレータはパワートランジスタを使って,パルス変調で電圧を制御する一種のアナログ回路である。コンデンサやインダクタといった電源関連の素子を外付けせずに実現できるものではない。
だからiVRを実現するには,プロセス技術に及ぶ技術開発が必要なはずで,実際にHaswellでは,iVRのためにプロセス技術の改良が行われたようだ。また,チップ上にコンデンサやインダクタを載せる,実装上の技術開発も必要だっただろうと思われる。
いずれにしても,このiVRの実現によって,より効率が高い電圧制御が行えるようになり,CPUの省電力化につながっているものと考えられる。
またIntelは,デスクトップ向けのUnlock版であるKシリーズなどでは,Ivy Bridge以上のオーバークロックが可能になるとしている。右下のスライドを見る限り,6本の電圧が可変できるようで,またクロックを制御できる項目も増えているそうだ。オーバークロッカーにとっては,楽しめるCPUになるかもしれない。
 HaswellのKシリーズは,「Intel Extreme Tuning Utility」によるオーバークロックに対応する |
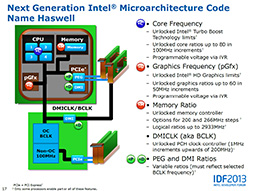 HaswellとIntel Extreme Tuning Utilityで設定できる項目。従来の項目に加えて,PCI ExpressやDMIのクロック倍率が変更できる |
CPUのマイクロアーキテクチャはIvy Bridgeの改良版
同一クロックで10〜15%の性能改善を実現
Intelは1年置きに,マイクロアーキテクチャの刷新と製造プロセスの微細化とを交互に行う「Tick-Tock」(チクタク)戦略を導入していることを,ご存知の読者も多いだろう。2012年4月に発表されたIvy Bridgeは,製造プロセスの微細化を行う「Tick」にあたる年の製品で,3次元トライゲート・トランジスタを用いる22mnプロセスの導入が,大きなニュースになった。
一方,Haswellは「Tock」にあたり,マイクロアーキテクチャの刷新が行われる世代になる。マイクロアーキテクチャが新しくなる以上,当然ながら演算性能は向上しているはず,である。
発表されているHaswellのトランジスタ数は14億個であり,Ivy Bridgeと変わっていない。そしてIntelによると,HaswellのマイクロアーキテクチャはIvy Bridgeを踏襲し,それに改良を加えたものであるという。トランジスタの使用効率は上がっているが,完全に刷新されたものではないわけだ。
まずはHaswellの全体像から見ていこう。下のスライドには,CPUコアとGPUコア,それらが共有するLLC(Last Level Cache,L3キャッシュ),そしてプロセッサ全体を統括する「System Agent」と,それらを接続するリングバスが示されている。リングバスやSystem Agentには,Haswellでどのような改良が加えられたかが説明されている。
スライドの図を見ると,プロセッサ全体の基本的な構成要素や,それらを高速なリングバスで接続するという形態は,Ivy Bridgeのそれと変わりがない。LLCの帯域が引き上げられたり,DRAMアクセスの効率が上がったり,System Agentが賢くなっていたりといった改良が施されてはいるが,基本構成はIvy Bridgeをそのまま継承していることが分かるだろう。
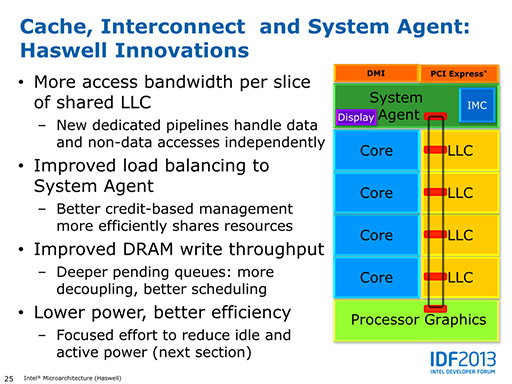 |
各CPUコアの基本アーキテクチャも同様で,Ivy Bridgeを受け継ぐとされる。各CPUコアが独立したL1/L2キャッシュを持ち,全体で共有するLLCがあるという3レベルのキャッシュ構成をしているのも同様だ。
一方,CPUコア内部の改良点をざっくりまとめると「命令実行の並列度を上げるための改良」が施されたようだ。
次のスライドはHaswellの改良点をまとめたものだ。「実行ユニットの拡大」(More execution units)が目を引くほか,分岐予測の改良やフロントエンド部(TLBやキャッシュ)の改良,並列度を上げるためのバッファの拡大などが挙げられている。
その一方で,CPUパイプラインの深さは変更されていない(No pipeline growth)とも書かれている。そのため,分岐予測ミスが起きたときのペナルティや,L1&L2キャッシュのレイテンシはIvy Bridgeと変わらないはずだ。
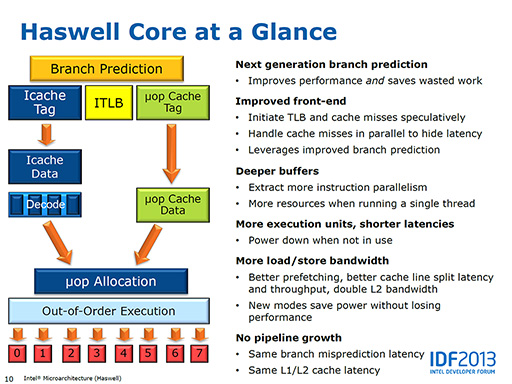 |
それではこれら改良点の中から,重要な点をピックアップしていこう。
まず実行ユニットの拡大だが,Haswellでは整数演算ユニットやストアアドレス生成ユニット,分岐ユニットが追加されたほか,パイプラインに対して命令を実行させる命令発行ポート数が,Ivy Bridgeの6つから8つに拡張されている。下のスライドにある「Port0〜Port5」はIvy Bridgeから受けついだ6つのポートで,「Port6」と「Port7」が新たに追加されたポートだ。
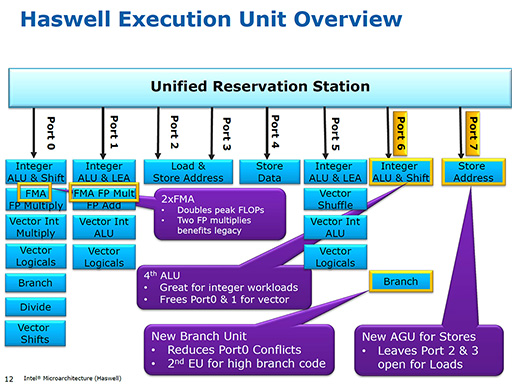 |
ポート数の増加により,同時にパイプラインに発行できる命令数も,6から8へと増加した。また演算ユニットが増えたことで,一部の命令発行ポートで発生しがちだったポートの渋滞も緩和される。スライドに示されているように,Port0から命令を発行する演算ユニットは,整数演算や浮動小数点演算など多岐にわたる。そのためPort0は,とくに混雑しやすいポートだった。
同じような理由で,Port7にはストアアドレス生成ユニットが追加された。これにより,ロードアドレス生成時のPort2,3の混雑が,回避しやすくなると期待できる。要するに,これらのユニットの追加によって,同時に実行できる命令数が増えたわけである。
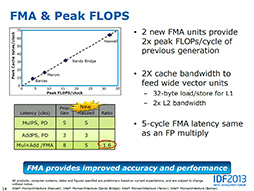 FMA(積和命令)の強化による演算性能向上をアピールするスライド。従来の命令セットで同じ計算を行うのに対して,1.6倍の性能が得られるという |
 Haswellの「Intel AVX2」は,FMAの改良と256bit演算のサポートが追加されたものになる |
FMAのほかに,Haswellでは従来のAVXがサポートしていなかった,256bit演算に対応した。これとFMAの改良を合わせて,IntelはHaswellでのAVX拡張を,「Intel AVX2」と呼んでいたりする。
余談になるが,FMAの導入には,若干の紆余曲折がある。もともとIntelは,オペランド(演算対象の値)を4つ使う「FMA4」という命令セットを発表していたが,AMDがIntelに先駆けて,FMA4をBulldozer世代のCPUでサポートしてしまった。
ところが,Intelは諸般の事情からFMA4のサポートを見合わせてしまい,代わりに3オペランドの「FMA3」を導入した。HaswellがサポートするFMAも,「FMA3」のみである。一方,AMDはPiledriver世代でFMA3をサポートするハメになり,いわば二度手間をとらされていたりする。
次は下のスライドを基に,「バッファの拡大」について説明しよう。
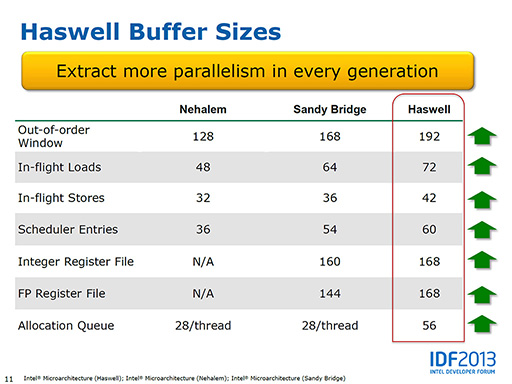
「Out-of-order Window」とは,命令を順不同に実行するOut-of-Orderにおいて,順番を入れ替える命令の数(Window)のことだ。ここを拡大すれば,より多くの命令を入れ替えて実行できるようになる。
「In-flight Loads/In-flight Stores」とは,メモリから値をロードしたりストアしたりするときに,これをまとめて行うためのバッファである。メモリアクセスはまとめて行ったほうが効率がいいので,In-flight Loads/In-flight Storesのバッファを増やすと,メモリアクセスの効率は上がるわけだ。
「Scheduler Entries」とは,パイプラインに対する命令発行順を管理する,スケジューラに保持できる命令数(エントリー数)のことだ。エントリー数が増えれば,命令発行順を管理する効率が上がる。
「Integer Register File/FP Register File」とは,CPU内の物理レジスタのことだ。CPUはレジスタに値を置いて演算を行うが,レジスタファイルが増えればレジスタの競合が減るので,並列に実行できる命令数が増やせる。
最後の「Allocation Queue」とは,スレッドに対してCPU内部のリソースを割り振るときに使う,一種のバッファである。この拡大でリソースの割り当て効率が上がると期待できる。
 |
こうしたバッファの拡大が何の役に立つのかと言えば,命令の実行効率が上がり,並列実行の効率も上がる。それにより,処理性能全体が向上するというわけだ。
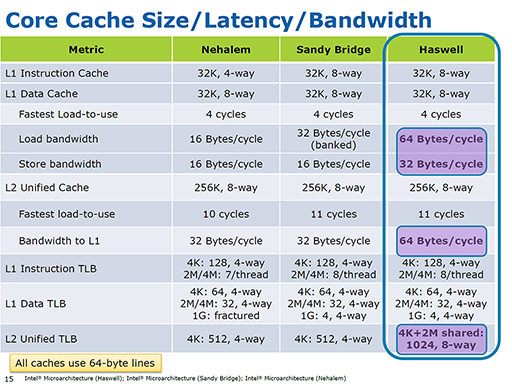
詳細は割愛するが,そのほかにもHaswellでは,L1&L2キャッシュの帯域幅も強化されているという。
 |
Haswellでのマイクロアーキテクチャの改良は,以上のようになる。Intelによれば,これらの改良によってIvy Bridgeに対し,同クロック比で10〜15%の性能向上が実現できるそうだ。これを多いと見るか少ないと見るかは,意見が分かれるかもしれないが,Ivy Bridgeのマイクロアーキテクチャをトランジスタ数を増やさずに改良したものと考えれば,順当な性能向上と評価していいのではないだろうか。
統合型GPU「GT3」の規模は
Ivy Bridgeに対して2.5倍に
最後に,Haswellの統合型グラフィックス機能(以下,統合型GPU)についても触れておこう。IntelはHaswellの特徴として,統合型GPUの性能向上を大きな特徴に挙げているからだ。
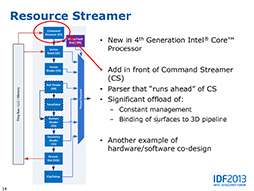 |
継承したとは言っても,そのまま受け継いだわけではなく,拡張されている部分もある。たとえば統合型GPU内部の実行ユニット(Execution Unit。以下,EU)は,パイプラインに「Command Streamer」(以下,CS)というステージが追加された。CSでストリームを解析する前処理を行うことで,パイプラインの効率を向上させているという。
Haswellの統合型GPUは,Ivy Bridgeのそれとは規模も異なっている。復習がてら振り返っておくと,Ivy Bridgeで最上位の統合型GPUであった「Intel HD Graphics 4000」は,16基のEUで構成されていた。1基のEUが4基の演算ユニットを持つことから,演算ユニット数の総計は64となる。
それに対してHaswellの統合型GPUでは,EU×20基とL1キャッシュ,テクスチャユニットなどをひとまとまりにした「スライス」(Slice)という単位があり,スライス単位で拡張が可能な設計になっている。
統合型GPUは4種類あるが,そのうちGT2はスライスが1つの構成だ。EUあたり4基の演算ユニットというのは変わっていないので,GT2は1スライスで80基の演算ユニットを持つ計算になる。演算ユニットの数ならば,Ivy BridgeのIntel HD Graphics 4000に対して1.25倍に強化されたというわけだ。
下位のGT1は? と思った人もいるだろうが,GT1についてはあまり情報がない。少なくともGT2よりは規模が小さいはずなので,縮小したスライス1基で構成されているのかもしれない。
Intelが性能向上を大いにアピールし,「Iris」という新ブランドを与えたGT3になると,2つのスライスで構成されているという。つまり40基のEUにより,160基の演算ユニットを搭載することになるわけで,GT3の演算ユニット数は,Intel HD Graphics 4000の2.5倍にもなる。もちろん,演算ユニット数が3Dグラフィックスの性能に直結するわけではないので,グラフィックス性能が2.5倍になる,とは言えない。それでもGT3では,かなりの性能向上が期待できそうだ。
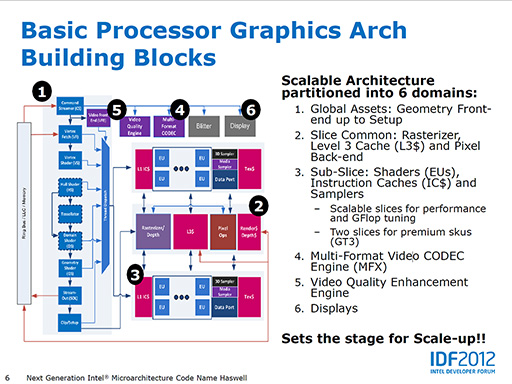 |
一方,注目が集まっているにも関わらず,具体的な情報が公開されていないのが,GT3eである。GT3eは,GT3に「Embedded DRAM」(eDRAM)というオンチップの高速DRAMバッファを追加したものとされるのだが,肝心のeDRAMについての情報がまったくない。Intelの関係者も「当分の間,eDRAMに関する情報は公開されないのではないか」と述べていたりするので,容量や帯域幅といった情報は,しばらく明らかにならないのではないかと思われる。
だが,eDRAMの用途は分かっている。eDRAMはグラフィックスメモリのキャッシュとして使われ,LLCとの整合性(キャッシュコヒーレンシ)を取る機能も備えるという。
メインメモリをグラフィックスメモリとして使う統合型GPUでは,メモリ帯域幅が大きな足かせになる。高速なeDRAMをグラフィックスのキャッシュとして使うことで,その足かせを緩和しようという考えだろう。
eDRAMの搭載により,GT3eのメモリ階層は,メインメモリ→eDRAM→LLC→L1キャッシュという,かなり深いものになる。単体GPUのメモリ階層は深いのが一般的だ。演算ユニットの近くに高速なメモリを置くことで,演算ユニットのクラスター(集合体)であるGPUを,効率的に働かせられるためである。160基の演算ユニットを持つに至ったHaswellの統合型GPUは効率を上げるために,単体GPUに似た深いメモリ階層が必要になったのだ,という見方もできそうだ。
Ivy Bridgeから順当に進化したHaswell
というわけで,Haswellの主な特徴やIvy Bridgeとの違いを見てきた。こうした特徴をおおまかにまとめると,「省電力に最も力を入れたCPUだが,マイクロアーキテクチャの改善によって,CPU性能も向上しているのが特徴」ということになるだろう。
統合型GPUは,Ivy Bridge比でGT2が1.25倍,GT3では2.5倍もの拡大を果たした。この規模拡大が,ノートPCや液晶一体型PCの3Dグラフィックス性能を,底上げしてくれることは間違いない。「統合型GPUになんて興味はないよ」というゲーマーにとっても,GPU全体の底上げにつながるのであれば歓迎,というところではなかろうか。
4Gamerでは本稿の掲載に合わせ,デスクトップPC向け「Core i7-4770K」「Core i7-4670K」の検証記事も掲載している。本稿でここまで説明してきた改良点を踏まえつつ,レビュー記事を読み解いてもらえれば幸いだ。
- 関連タイトル:
 Core i7・i5・i3-4000番台(Haswell)
Core i7・i5・i3-4000番台(Haswell) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー