










ニュース
Atomの常識が根本的に変わる? 次世代AtomのCPUコア「Silvermont」の詳細が明らかに。Intel Developer Forumレポート その2
 |
抜本的な改良でAtomの性能を大幅に引き上げるSilvermont
 |
Atomシリーズは今まで,45nmプロセス世代の「Bonnell」(ボンネル,同)コアや,32nmプロセス世代の「Saltwell」(ソルトウェル,同)コアを使っていた。これらは基本的に同一のアーキテクチャで,命令をメモリ内での順番通りに実行する「インオーダー実行」という仕組みを採用していた。
Bonnellがインオーダー実行を採用したのは,主に消費電力の削減を実現するためだった。ところが,Atomが対抗しようとしているARM系のCPUコアは,命令の実行順序を入れ変えて,処理の高速化を実現する「アウトオブオーダー実行」※1を取り入れて性能を向上させてきた。
※1 念のために補足しておくと,Atom以外のIntel製x86系CPUは,Pentium Pro以降どれもアウトオブオーダー実行である。
性能が向上したARM系CPUに対抗するには,Atomといえども性能の抜本的改善が必要だ。そこで新世代となるSilvermontは,「3Dトライゲートトランジスタ」(FinFET)を使う22nmプロセスで製造することにより,消費電力低減と動作周波数向上を実現するとともに,アウトオブオーダー実行を導入して高速化を行い,さらに64bit対応や仮想マシン支援機能(Intel VT)といった,PC用のCoreプロセッサに導入されている機能も一部取り込むことで,性能と機能を大幅に強化することとなった。
Intelが主張するには,SilvermontはSaltwellの3倍のピーク性能を持ち,消費電力は約5分の1となっているという。別の言い方をするなら,SilvermontはSaltwellと比べて,同じ動作周波数ならば消費電力は半分に,同じ消費電力なら1.3倍以上の動作周波数で動作できるということだ。
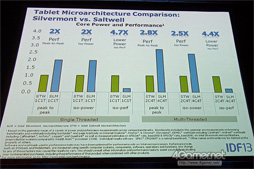 同じ性能なら,Silvermontの消費電力はSaltwellと比べて最小で5分の1に(左から3番めのグラフ,ここでは4.7倍と表記),同じ性能なら最大2.8倍(左から4番め)になるという |
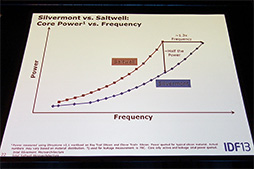 Silvermont(青)とSaltwell(赤)の動作周波数と消費電力の関係を示したグラフ。同じ動作周波数なら消費電力は半分で,同じ消費電力なら性能は1.3倍と謳う |
Silvermontでは,CPUコア数とマルチスレッド動作にも変更が加えられている。SaltwellまでのAtomでは,1つの物理CPUコアが2つのスレッドを実行可能な「Intel Hyper-Threading Technology」(以下,HTT)に対応していた。一方,SilvermontはHTTをサポートせず,1つの物理CPUコアでは,同時に1つのスレッドしか実行しない。
先にも触れたように,Saltwellはインオーダーであるため,メモリ内のデータアクセス待ちによりプログラムの処理(パイプライン)が止まって性能が低下することが頻繁に起きる。そのため,マルチスレッド化により少しでも高速化を図ろうと,HTTを導入していた。
しかし,Silvermontではアウトオブオーダー実行になったことで,Saltwellに比べれば,パイプラインが止まりにくくなっている。そのため,HTTを捨ててその分CPUコアを単純化し,さらに,CPUコア数そのものを増やしやすいアーキテクチャに変更することで,マルチコア対応を強化した。つまり,マルチスレッド性能はHTTのような技ではなく,CPUコア数そのものでカバーしようというわけだ。
用途に応じてCPUコアの数を柔軟に増減
Silvermontは,2つのCPUコアと1つの共有L2キャッシュをまとめて1モジュールとしており,各モジュールがSoC(System-on-a-Chip)内の「System Agent」と呼ばれる部分に接続される構成になっている。CPUコアを増やす場合には,このモジュールを増やせばいい。メモリコントローラもSystem Agentに接続されているので,各モジュールからのメモリアクセスを調停する役目も担っているようだ。
 |
登場した当初のAtomは,グラフィックス機能や周辺回路を持たない単体CPUとして設計されていたので,Pentium ProからCore 2プロセッサまで続いた「フロントサイドバス」によって,CPUとチップセットを接続していた。ところが,Atomに統合型グラフィックス機能や周辺回路が導入され,SoCと呼べる機能を備えるようになってからも,この構造はそのまま残り続けてしまう。SoC内部ではフロントサイドバスと同様の仕組みで,チップセットに当たる機能と接続されていたのだ。
この古い構造を引きずったままでは,用途に応じてCPUコア数を増やしたり,SoC内部の転送速度を向上させるといったことは難しい。Silvermontでは,内部構造を一新してこの問題を解消し,必要に応じてモジュールの数を柔軟に増減させることが可能になった。たとえば,Bay Trail-Tは2モジュールで4CPUコアを搭載しているが,サーバ向けのAvotonは4モジュールで8CPUコアを搭載するといった具合だ。
CPUコア内部の構造をチェック
Silvermontの内部構造を簡単に見てみよう。L1キャッシュはデータと命令で分離されており,メモリから読み込まれた命令は,デコーダ(図のdecode)でμOPS(マイクロ命令)に変換されて実行される。ただし,1つのx86命令を複数のμOPSに細かく分解するのではなく,まずはメモリのロードや演算,ストアなどをセットにした,比較的大きな単位のμOPSに変換するそうだ。この大きなμOPSを,5つの命令発行ユニットに振り分ける段階で,さらに細かい内部命令へと分解して実際の処理を行うという。
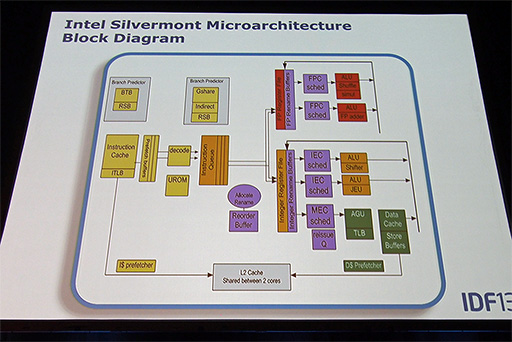 |
実行部分は大きく,整数演算用と浮動小数点演算用に分かれており,それぞれがレジスタファイル(複数のレジスタセットをまとめたもの)を持つ。
アウトオブオーダー実行では,同じレジスタに対する処理が重複する可能性がある。元々汎用レジスタが少ないx86 CPUでは,とくにその可能性が高い。そこで汎用レジスタとは別に,たくさんの内部レジスタを用意して処理を進めておき,最終段階で汎用レジスタを確定させる「レジスタリネーミング」という手法が使われるのが一般的だ。
Silvermontの場合,アウトオブオーダー実行中の演算結果を「リオーダーバッファ」(Reorder Buffer)と呼ばれる領域へ一時的に保存しておき,命令が確定した段階で結果を汎用レジスタへ転送する方式が採用されているようだ。
整数演算側の実行部には,2つの演算ユニットと1つのメモリアクセスユニットが,浮動小数点演算側には2つの演算ユニットがある。各演算ユニットは,処理できる命令が一部異なるように設計されていて,内部命令の種類により実行先を切り替える仕組みだ。Silvermontの構成では,最大5つの内部命令を同時に処理できることになる。
さて,アウトオブオーダー実行のCPUでは,プログラムの中に分岐命令が出てきた場合,分岐するかどうかを予測して実行を行う(分岐予測)。予測が当たれば,分岐命令に続く処理を先に実行しておくことで,CPUの動作を高速化できるためだ。しかし予測が外れてしまうと,分岐命令まで処理を巻き戻して,再開させる必要があり,大きなタイムロスとなる。
だからこの仕組みでは,分岐予測の精度が非常に重要だ。とくに電力消費という点から考えると分岐予測を間違えた場合,取り消された処理で使った電力はまったくのムダとなってしまう。低消費電力が重要となるAtomでは,なおさら影響は大きい。
そこでSilvermontでは,分岐予測精度を向上させるため,予測のもとになる情報を格納する領域を拡大した。また,分岐命令の予測精度を上げるだけでなく,間接分岐(レジスタやメモリ内の値を使って分岐先を指定する分岐命令)の予測精度も向上させたという。間接分岐では分岐先が変化するため,どこへ分岐するのかも予測しなくてはならない。これを予測できないと,分岐するかどうかを予測できても,その先の命令を実行できないという,間の抜けた事態に陥るからだ。
また,プログラム中の繰り返し(ループ)は挙動が予測しやすいため,ループを検出する機構を使って,通常の分岐とは区別して専用の予測機構を使う。Silvermontではこの仕組みも強化されて,性能向上に役立っているそうだ。
CPUやグラフィックスの負荷を監視して
動作周波数を上げる「Intel Burst 2.0」
 |
これは,Coreプロセッサでお馴染みの自動オーバークロック機能「Intel Turbo Boost Technology」のSilvermontとも言えるもので,各CPUコアや統合グラフィックス機能の消費電力や温度を監視して,システム全体として余裕があるなら,特定CPUコアだけ動作周波数を上げて,処理速度を向上させる機能を備えるという。
また,メディア演算命令である「SSE4.1」「SSE4.2」,暗号化処理を高速化する「AES New Instruction」が追加されたり,仮想マシン支援機能も強化されている。
とくに仮想マシン支援機能は,仮想アドレス変換のためのページテーブルの制御をハードウェアで可能にした「VT-x2」が搭載されたため,ホスト側(ハイパーバイザーやホストOS)が仮想マシンのページテーブルの操作を毎回処理する必要がなくなったために,動作が高速化している。
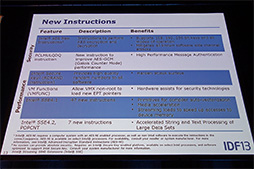 Silvermontに追加された命令セットの解説スライド。セキュリティや仮想マシンに関わる機能強化が目立つのは,サーバー用途を意識したものだろうか? |
 Saltwell(左)とSilvermont(右)の仮想マシン実行にかかる時間を比較したスライド。当然ながらSilvermontでは大幅に高速化されている |
以上のように,全体的にみるとSilvermontは,今までのAtomに使われたアーキテクチャとはまったく別物と言っていいほど,大幅な改良が施されたアーキテクチャになっている。前世代をベースに改良されたのではなく,まったく違うものに置き換わったのがSilvermontであり,これをベースにしたBay Trail-T搭載のタブレットは,性能面でも大きな期待ができるだろう。
「Atom=低性能」といったイメージは,Silvermont世代では忘れたほうが良さそうだ。
- 関連タイトル:
 Atom
Atom
- この記事のURL:
(C)Intel Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー