









ニュース
NVIDIA,Fermi世代の次期GeForce「GF100」グラフィックスアーキテクチャを発表
 |
本稿では,2010 International CESの会期中に開催された報道関係者向け事前説明会の内容を基に,GF100におけるグラフィックス周りの拡張について解説していきたいと思う。なお,Fermiアーキテクチャそのものについては,2009年10月1日の記事で西川善司氏が解説を行っているため,そちらを併せてチェックしてもらえれば幸いだ。
 |
GT200の拡張にあらず!
新設計でジオメトリ性能を大幅に強化
 |
しかし,GF100でNVIDIAは,独自のアプローチでグラフィックスアーキテクチャを拡張してきている。説明会によれば,GF100の開発に当たってNVIDIAが目指したのは,以下の4点だ。
- ジオメトリのリアリズム
- 比類なきイメージ品質
- ゲームにおける革新的なGPUコンピューティング機能
- 過去最高のGPUパフォーマンス
 |
| Jonah M. Alben上級副社長(Senior Vice President, GPU Engineering, NVIDIA) |
 |
| GF100では,「GT200にテッセレーションを付加する」という単純なアプローチを採用しなかった。それは,GT200アーキテクチャにテッセレータを追加しても,ジオメトリ処理のボトルネックが発生しやすいためだ |
同社でGPU開発を統括するJonah M. Alben上級副社長は,「DirectX 9&10世代のGPUでは,統合型シェーダ化によって,シェーダパフォーマンスが飛躍的に向上している。しかし,ジオメトリ処理に関しては,専用ハードウェアを持っていた前世代のGPUよりもパフォーマンスが落ち込むことになった」と説明する。実際,「GeForce GTX 285」(以下,GTX 285)は,シェーダ性能が「GeForce FX 5800」(以下,FX 5800)の150倍以上へ引き上げられた一方で,ジオメトリ処理性能はFX 5800の3倍弱にしか上がっていないという。
一方,DirectX 11では,キャラクターや背景など,オブジェクトが持つシンプルなジオメトリデータに頂点データを付加することでポリゴンデータを細分化し,よりリアルなグラフィックス表現を可能にするテッセレーション(Tessellation)機能が追加された。GPUの持つジオメトリ処理性能が問われる世代になったわけだ。
 |
 |
 |
 |
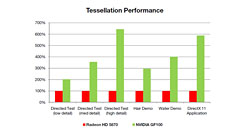 |
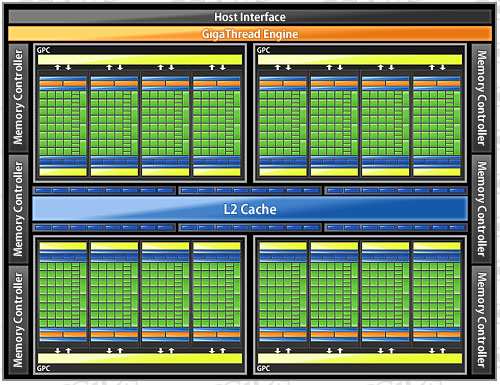
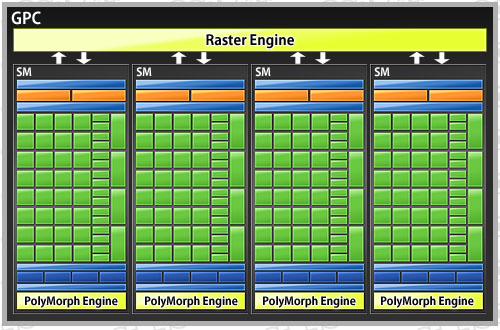
そんなDirectX 11時代に向けて,一連の処理をGPC内で完結できるようにすることにし,ジオメトリ処理の並列化を加速するのが,NVIDIAの狙いだ。
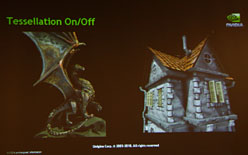 |
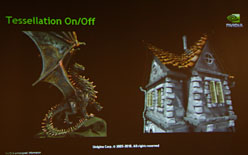 |


基本機能も大幅強化
〜ポイントごとにチェック
●テクスチャユニット&テクスチャキャッシュ
 |
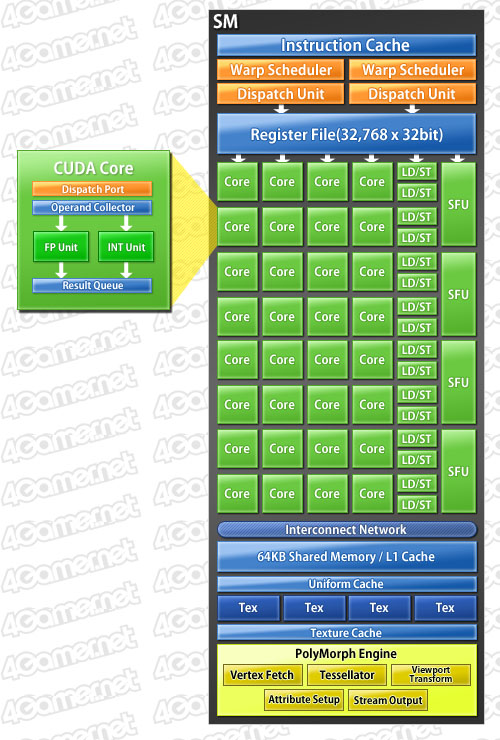
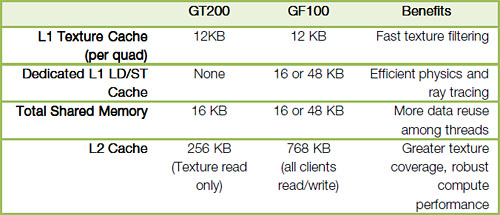
現行のGT200アーキテクチャでは,3基のSM(=24 CUDA Core)で構成されるTPCごとに8基のテクスチャユニットを搭載。フルスペックの240 CUDA Core仕様となるGTX 285で,合計80基のテクスチャユニットを搭載していた。これに対してGF100では,SM(=32 CUDA Core)ごとに4基で,合計64基。数のうえでは減ったことになるが,この点についてNVIDIAは,「(GT200のTPCごとではなく)SMごとにテクスチャユニットを搭載することで,処理効率は大幅に向上する」としている。
 |
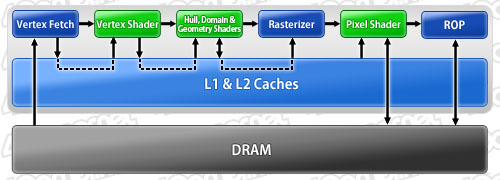 |
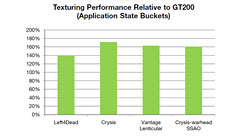 |
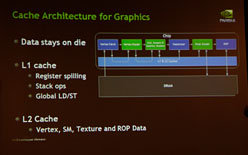
また,Fermiアーキテクチャの要とも言える新しいキャッシュアルゴリズムも,GF100のパフォーマンス向上を支えている。
Fermiアーキテクチャでは,GT200の256KBから768KBと容量が3倍に増えたL2キャッシュや,16KBまたは48KBに設定可能(※排他)なL1キャッシュと共有メモリによって,グラフィックスメモリにアクセスすることなく多くの処理をこなせるようになる。とくに,大容量化されたL2キャッシュのインパクトは大きく,頂点データやテクスチャ,ROPデータをSMやGPCで共有することが可能になり,より効率的なグラフィックス処理が可能になるという。
●ROP
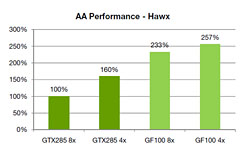 |
| GF100に搭載された新ROPによって,アンチエイリアシング適用時のパフォーマンスも飛躍的に向上したとされる。NVIDIAが示したこのグラフは,「Tom Clancy's H.A.W.X」におけるアンチエイリアシング適用時のフレームレートをGT200と比較したもの |
 |
| Emett Kilgariff氏(VP, GPU Architecture, NVIDIA) |
GF100で採用される新型ROPは,32bit整数ピクセルを1クロックで,FP16ピクセルを最高2クロックで,FP32ピクセルを最高4クロックでそれぞれ出力できる。また,アンチエイリアシング性能が大幅に引き上げられるとともに,32x CSAA(Coverage Sampling Anti-Aliasing)もサポートされるようになった。
CSAAは,GeForce 8800シリーズで実装されたアンチエイリアシング機能で,サンプリング点が,ターゲットとなるキャラクターなどのエッジとなる部分に対して外側になるのか,内側になるのかといった位置情報と色情報を圧縮してメモリに格納することによって,より多くのサンプリング点を持たせたアンチエイリアシング処理が可能になるものだ。32x CSAAでは,八つのカラーサンプルと24のサンプリング点によって,より滑らかなスムージングが可能となったと謳われている。
同社のGPUアーキテクチャ担当副社長Emett Kilgariff氏(VP, GPU Architecture)は,「GF100では,32x CSAAを有効にしても,8xAAと同等のパフォーマンスを実現できる」と,イメージ品質を高めても優れたパフォーマンスを発揮するGF100アーキテクチャの優位性をアピールする。
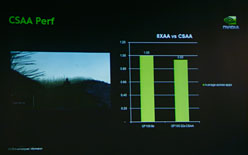 |
 |
 |
●並列コンピューティング性能
 |
| Fermiアーキテクチャの強みを活かし,GF100ではさらに強力な物理演算やAI処理,ポストプロセシング処理が可能になるという |
 |
| GF100では,リアルタイムレイトレーシング性能も向上。ラスタライズ処理と併用すれば,ゲームプレイでもレイトレーシングの手法を取り入れた“シネマクオリティモード”などを用意できるはず,というのがNVIDIAの主張である |
NVIDIAでデスクトップGPUビジネスを統括するDrew Henry氏(General Manager, Desktop GPU Business Unit)は,「GF100の登場により,“シネマクオリティモード”といった,より高画質なゲームプレイが実現可能になる」とアピールする。
GF100に搭載されたリッチなテッセレーション機能を使えば,キャラクターや背景の距離に応じてディテールを切り替えるLoD(Level of Detail)により,最小限の負荷で高品質のグラフィックス表現が可能になるが,それだけに留まらず,GF100の処理能力を活かし,リアルタイムレイトレーシングの手法を部分的にゲームに盛り込むことも不可能ではないというわけだ。

 |
●3D Vision Surround
 |
 |
3D Vision Surroundを担当するJason Paul氏(Sr. Product Line Manager, Enthusiast GPUs, NVIDIA)は,「3D立体視環境をマルチディスプレイ対応させることで,レースゲームやフライトシミュレータなどで,よりリッチな体験ができるようになる」と,現行3D Visionの発展系として,同機能を位置づける。
ただ,3D Vision Surroundを利用するためには,「GF100またはGeForce GTX 200シリーズのGPUを搭載したグラフィックスカードでNVIDIA SLI構成をとり,さらに,3台の液晶ディスプレイを,すべて同じ製品で揃える」という,高いハードルがある。

なおも詳細な製品スペックは公表されていないが
一部ベンチマークテスト結果が明らかに
 |
下に写真で示したとおり,「Far Cry 2」と「Dark Void」によるベンチマークテスト結果は明らかになったものの,Drew Henry氏は,今回公開されたグラフィックスカード(の実機)はすべてエンジニアリングサンプルで,製品版とは異なる可能性が高いと釘を刺しており,そのベールが剥がされたとはまだまだ言えない状況だ。
 |
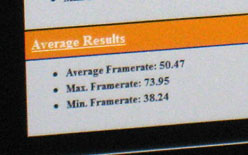 |
| 「Far Cry 2」の「Ultra High」設定で,GF100(左)とGeForce GTX 285のベンチマーク比較も行なわれた。前者が平均フレームレート83.99fps,最低フレームレート65.42fpsなのに対し,後者は同50.47fps,38.24fpsとなったていた | |
 |
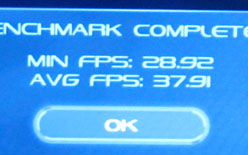 |
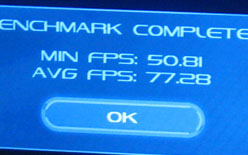
| こちらはGPU PhysX対応タイトル「Dark Void」を用いたベンチマーク比較。GF100だと平均フレームレートが77.28fps,最低フレームレートが50.81fpsなのに対し,GeForce GTX 285は同37.91fps,28.92fps。GF100が倍近いパフォーマンスを示している | |
 |
Henry氏は,「GF100は,PCグラフィックスの新たな10年を切り開く,高品質なグラフィックスを実現する」と,最新アーキテクチャに絶対の自信を見せていたが,実際のところはどうなのか。一刻も早い製品発表を待ちたいところである。
- 関連タイトル:
 GeForce GTX 400
GeForce GTX 400 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation

4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー