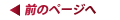![[西川善司の3Dゲームエクスタシー]「ATI Radeon HD 2000」シリーズのGPUアーキテクチャ徹底解説](img/title.jpg)

最新世代のGPUでは,プログラマブルシェーダユニットの数を多くして演算性能を向上させることに注力している。そうなると,“遅い”メモリアクセスを伴うテクスチャユニットは,たとえその数を増やしたところで,実際に活躍できる個数がメモリ速度とのバランスで頭打ちになってしまい,シェーダユニットとペアで実装する形にしたところでまったく意味がなくなってしまう。そういうわけで,NVIDIAもAMDも最近のGPUではテクスチャユニットをシェーダユニットから分離して,複数のシェーダユニットから共用させる設計としている。
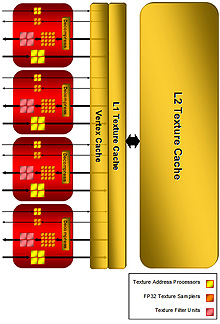
テクスチャユニット周辺。(ここでは4個の大きな)赤いブロックがテクスチャユニットだ
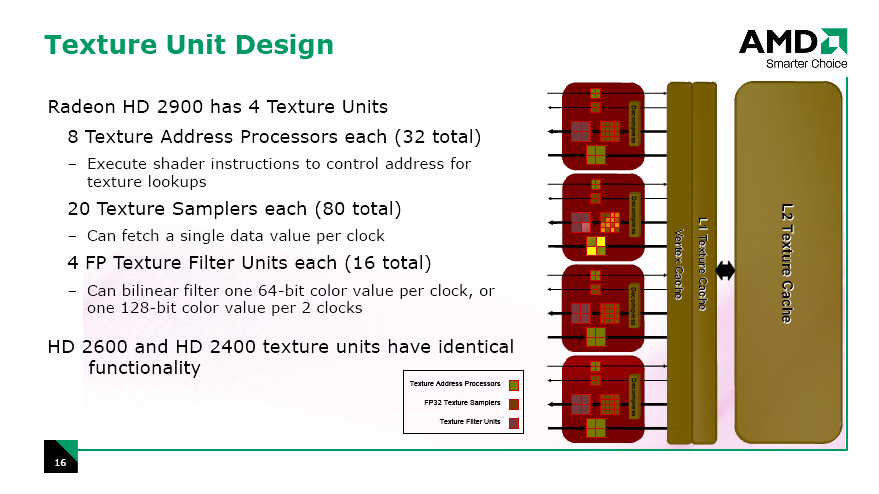
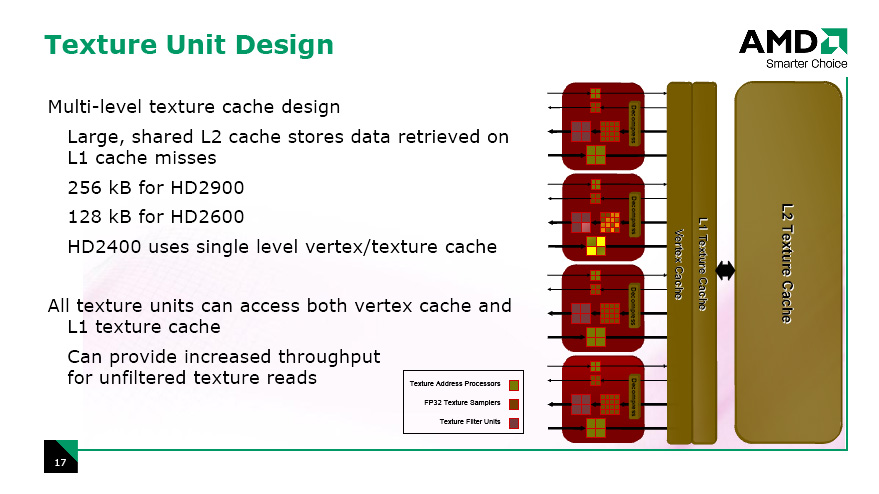
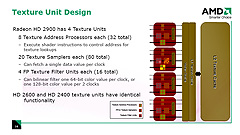
テクスチャユニットの数は,最上位のRadeon HD 2900で4基,Radeon HD 2600シリーズでは2基となり,Radeon HD 2400シリーズだと1基。右はRadeon HD 2900が持つテクスチャユニットのイメージになる。
テクスチャユニット1基につき,「テクスチャアドレス計算器」(Texture Address Processor)は8基実装されている。Radeon HD 2900では8×4で合計32基になる計算だ。ちなみにテクスチャアドレス計算とは,あるピクセルに対してテクスチャからテクセル(テクスチャを構成する画素=一つ一つの点)を適用するとき,テクスチャメモリのどの場所(アドレス)から取ってくるかを計算すること。
ブロック図を見ると,8個のテクスチャアドレス計算器は大4個,小4個という構成になっているのが分かると思うが,前者は“フィルタ処理あり用”で,主に通常の画像テクスチャを取り扱うときに利用される。後者は“フィルタ処理なし用”で,数値データテーブルとしてテクスチャをアクセスするような用途で活用される。
そして実際にテクスチャメモリからテクセルを読み出してくる「テクスチャサンプラ」(Texture Sampler)は,1テクスチャユニット当たり20基が実装されている(Radeon HD 2900だと20×4で総数80基)。図中で「FP32」とあることからも分かるように,テクスチャサンプラそれぞれは32ビット浮動小数点の値をデコード可能だ。20基のうち,取り出したテクセルをフィルタ処理して出力するのが16基,フィルタ処理なしで出力するのが4基で,これも図中では区別されている。

64bitのHDRテクスチャに対するバイリニアフィルタリングを“フルスピードで”実行可能と謳う
また,16基まとまったテクスチャサンプラは,1テクスチャユニット当たり4基実装される「テクスチャフィルタ処理ユニット」(Texture Filter Unit)へと接続される。
4基のテクスチャフィルタユニットはすべて32ビット浮動小数点演算に対応しており,バイリニアフィルタなら,フィルタ処理されたFP32テクセルを1クロックあたり同時に4個出力可能。64bit浮動小数点テクセルであれば1クロックあたり1個,128ビット浮動小数点テクセルであれば2クロックで1個のバイリニアフィルタ付きのテクセル出力が実現できる。さすが「HDRレンダリング時代の最新世代GPU」といったところか。
前述したように,これと同時にテクスチャフィルタ処理なしの4テクセルも出力できるので,1クロック当たりの最大テクセル出力数に着目すると,4個のバイリニアフィルタ処理付きFP32テクセルと4個のフィルタ処理無しのFP32テクセルが出力できるということになる。
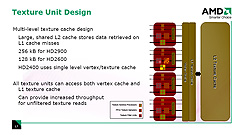
続けてテクスチャユニットのブロック図右側に注目してほしい。ポイントは,ATI Radeonの歴史上初めて,L1&L2という,贅沢な二段構えのシステムを採用している点。全テクスチャユニットから共有される形での実装となり,AMDによると,容量はRadeon HD 2900でL1が32kB,L2が256kB。Radeon HD 2600はこの半分になっており,さらにRadeon HD 2400では(1ページめの最後で軽く触れたとおり)Radeon HD 2600からさらにL2キャッシュが省かれている。
 |
 |
| ATI Radeon HD 2000シリーズにおけるテクスチャユニット仕様の違いについて説明するスライド |
少しばかりテクスチャユニットに話を戻すと,ATI Radeon HD 2000シリーズのテクスチャユニットだが,実は頂点フェッチユニット(Vertex Fetch Unit)も兼ねている。先ほど,テクスチャアドレス計算やテクスチャサンプラのところでフィルタリングなしの機能があったと思うが,あれは主に頂点シェーダとして起用された汎用シェーダユニットが頂点バッファから頂点データを取り出してくるときのパスとして利用されるのだ。そのためATI Radeon HD 2000シリーズでは,テクスチャキャッシュとは並行して「頂点キャッシュ」(Vertex Cache)もこのテクスチャユニットに隣接する形で実装されている(ただしRadeon HD 2400シリーズだけは,L1テクスチャキャッシュと頂点キャッシュが共用設計)。
テクスチャキャッシュと頂点キャッシュでは用途がまったく異なるが,すべてのテクスチャユニットから頂点キャッシュの内容とテクスチャキャッシュの内容の両方を透過的に参照できるような設計となっているそうだ。これには,頂点情報をテクスチャにレンダリングする「頂点バッファレンダリング」のような,テクスチャと頂点バッファを透過的に取り扱うテクニックなどにおいて,キャッシュヒット率を稼いでパフォーマンス向上を狙おうという思惑があるものと考えられる。

テクスチャユニットの機能面には,ATI Radeon X1000シリーズと比較してかなりの進化が認められる。
64bit HDRテクスチャのバイリニアフィルタリングをパフォーマンス低下なしに行えることは前段で述べたとおりだが,AMDによれば,実効レートにおいて,ATI Radeon X1000比で7倍のパフォーマンスアップを達成したという。
またこれも「テクスチャユニット(1)」で述べているが,実効速度は半分になるものの,128bit浮動小数点テクスチャのフィルタリングにもATI Radeon HD 2000シリーズは対応している。さらに,サポートされるすべてのテクスチャフォーマットに対して整数,浮動小数点の区別なくバイリニア,トライリニア,アニソトロピック(異方性)の全フィルタリングモードをサポートしたとのことだ。これは非常に強力である。
さらにさらに。これまで特許問題からGeForceにしか搭載されてこなかったDST/PCF(Depth Stencil Texture with Percentage Closer Filtering),別名「NVIDIA SHADOW」機能がついにATI Radeonでもサポートされたことは特記しておきたい。Xbox 360-GPUでもこの特許問題をクリアできたようなので,NVIDIA SHADOWの使用に当たって,NVIDIAと全面的な合意がなされたのだろう。
 |
 |
| 「Tomb Raider: The Angel of Darkness」より。従来のATI Radeonでは左の画面のように影のジャギーが目立っていた。これに対してGeForceではデプスバッファ参照時にPCFを利用できるためジャギーを低減できていたのだが,ついにATI Radeon HD 2000シリーズでこの機能に対応した |
また,新しいテクスチャフォーマットの「RGBE=9:9:9:5」がサポートされる。これは仮数9bit,共通指数項5bitの浮動小数点型HDRフォーマットで,RGBの各項に対して共通の指数項Eを持たせたものだ。各項のデコードはX=X×2Eの形で行われる。Xbox 360-GPUには「αRGB=2:7e3:7e3:7e3」の10bit浮動小数点HDRフォーマット(7bit仮数,3bit指数)がサポートされているが,あれと似たような,パフォーマンスとHDR精度のバランスをとったフォーマットとして,さまざまなゲームで活用されるようになるかもしれない。

ATI Radeon X1000シリーズがVTFをサポートしなかったことを叩かれ,当時のATIが必死の弁解をしていたことが思い返される。ATI Radeon HD 2000シリーズは大丈夫。VTF対応だ
このほか主だったところでは,最大テクスチャサイズが従来の4096×4096テクセルから8192×8192テクセルへと引き上げられた点もトピックだ。
それと,改めて説明する必要のないことかもしれないが,いついかなるときも汎用シェーダユニットはテクスチャユニットを利用できるので,例えば頂点シェーダやジオメトリシェーダとして起用された場合でも,汎用シェーダユニットはテクスチャユニットを利用できる。つまり,DirectX 9/SM3.0時代にGeForce 6/7の特権的機能だった,頂点シェーダユニットからのテクスチャアクセス機能「VTF」(Vertex Texture Fetching)は,ATI Radeon HD 2000シリーズなら難なくこなせてしまうということだ。

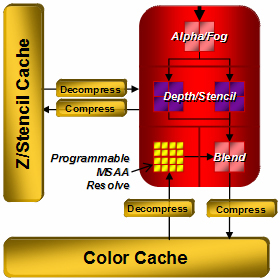
レンダーバックエンドの概要
頂点シェーダやジオメトリシェーダによる頂点単位の陰影処理,ピクセルシェーダによるピクセル単位の陰影処理を終えて,最終的に,ビデオメモリに対して出力を行うのが「レンダーバックエンド」(Render Back-End)だ。NVIDIAが「ROP」(Rednering Output Pipeline)と呼んでいる部分の,AMD(というか旧ATI)的な呼び名である。
ATI Radeon HD 2000シリーズのレンダーバックエンドは,機能的にDirectX 10/SM4.0の要求仕様に沿った拡張が行われている。
例えば,同時に複数のバッファに対して出力する「マルチレンダーターゲット」(MRT:Multiple Render Target)はDirectX 9/SM3.0仕様の4枚から8枚へと増加した。バッファのブレンディングもDirectX 9/SM3.0仕様の64bit浮動小数点バッファ(FP16-64bitバッファ)の上を行く,128bit浮動小数点バッファ(FP32-128bitバッファ)にまで対応している。
Radeon HD 2900シリーズのレンダーバックエンドはメモリバスシステムの設計との関係が深く,後述する「リングバスメモリインタフェース」(Ring Bus Memory Interface)が持つ,4基の「リングストップ」(Ring Stop)に連動するような形で4ブロック設けられている。なお,Radeon HD 2600/2400シリーズはリングバスを採用しておらず,従来方式のクロスバーメモリインタフェースを採用しているため,レンダーバックエンドは1ブロックのみだ。
Radeon HD 2900シリーズのレンダーバックエンドの各ブロックは1クロックで2×2の4ピクセル(テクセル)の出力が可能。つまり,1クロック当たりでは4ピクセル×4ブロック=16ピクセルとなるため,レンダーバックエンドの個数は,従来の数え方でいくと16基ということになる。Radeon HD 2600/2400は,レンダーバックエンドが1ブロックしかないから,従来的なスペック表記だと4基になる計算だ。
深度値(Z値)テストやステンシルテストのみであれば出力が倍になるのは先代と同じ。Radeon HD 2900シリーズであれば1クロック当たりのZ/ステンシル出力は32ピクセルということになる。

GeForce 8にはない,レンダーバックエンドならではのユニークな機能としては,「RTT」(Render to Texture)のアグレッシブな高効率実行支援機能がある。
RTTとは,最終的なシーンレンダリングに必要な素材となるテクスチャをリアルタイムにレンダリングすること。「周囲の映り込み情景を実際に当該シーンのテクスチャにレンダリング(=RTT)して,それを環境マップとして利用したりする」ような,環境マッピングなどで活用される。
このRTT時に問題となるのが,RTTで生成されたテクスチャを取り扱えるようになるタイミングだ。
あるシーンに登場する自動車のモデルに,上で示した環境マップを適用したい場合を考えてみよう。このとき従来のGPUでは,GPU内で自動車モデルのレンダリングスレッドが環境マップのRTTスレッドと同時に走っていても,環境マップのRTTが終了するまでは,自動車モデルの環境マップ適用フェーズは待たされてしまっていた。当たり前のことだ。
ところが,ATI Radeon HD 2000シリーズではテクスチャユニットとレンダーバックエンドとが連携。環境マップのRTTが進行中であっても,その環境マップの参照先テクスチャアドレスが既にRTTが終えている箇所であることが分かれば,テクスチャの読み出しに“見切りで”ゴーサインを出してしまえるのだという。
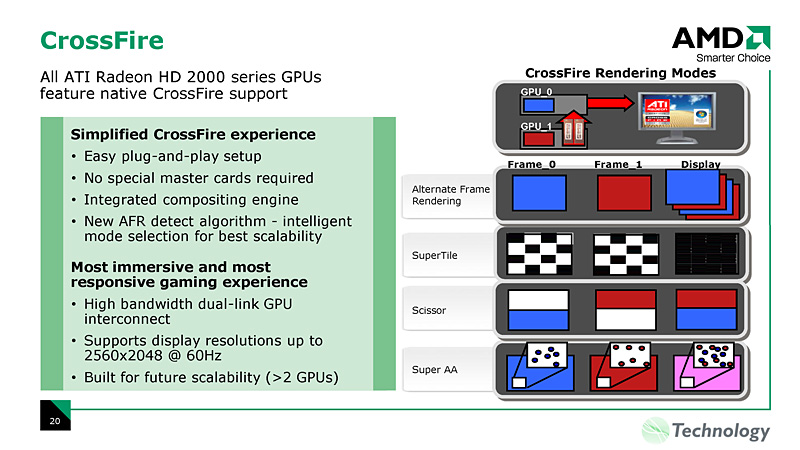
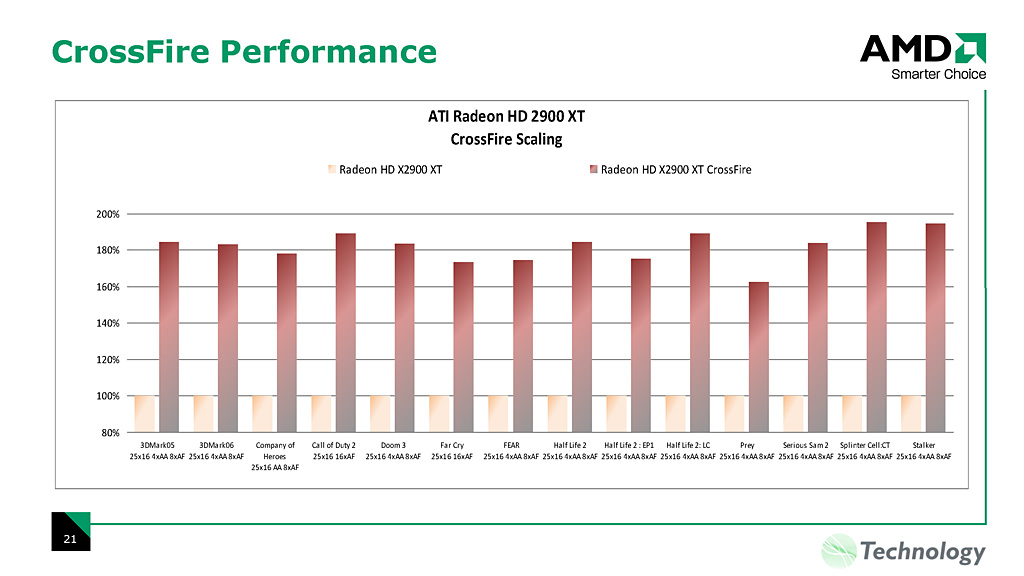
これがRTTテクニックの劇的なパフォーマンス向上を実現しそうなことは想像できると思うが,実はデュアルGPUソリューション「CrossFire」をも加速する可能性を秘めている。なぜかというと,デュアルGPU環境でパフォーマンス向上の足かせとなってきたのが,このRTT問題だからだ。
これまでのデュアルGPUソリューションでは,GPU1でRTTしたテクスチャをGPU2で利用したい場合,GPU2はGPU1のRTTが完了するのを待たなくてはならなかった。これに対してATI Radeon HD 2000シリーズでは,GPU1でRTT途中のテクスチャにもGPU2がアクセスできるようになるから,複数GPUのRTTにまつわる同期レイテンシをかなり低減できる。
実際にテストしてみなければ実効パフォーマンスは分からないが,デュアルGPUソリューションをAFR(Alternative Frame Rendering)モードで実行させた場合のパフォーマンス向上率は,NVIDIA SLIよりも高くなることが期待できそうだ。
 |
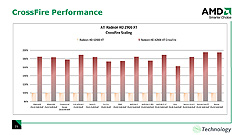 |
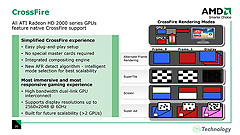
左:CrossFireのAFRモードで,さらなる高速化が期待できるATI Radeon HD 2000シリーズ
右:Radeon HD 2900 CrossFireでは,シングルカード時と比較して6割以上のフレームレート向上が図られるとされる |

従来のGPUでもそうであったように,アンチエイリアシング処理もレンダーバックエンドで実行される。
ATI Radeon HD 2000シリーズにおいて,歴代のATI Radeonが搭載していた以下の技術はすべてサポートされる。
- マルチサンプル・アンチエイリアシング
- テンポラル・アンチエイリアシング
- 適応型スーパーサンプル/マルチサンプル・アンチエイリアシング
- CrossFire スーパー・アンチエイリアシング
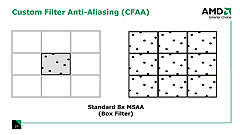
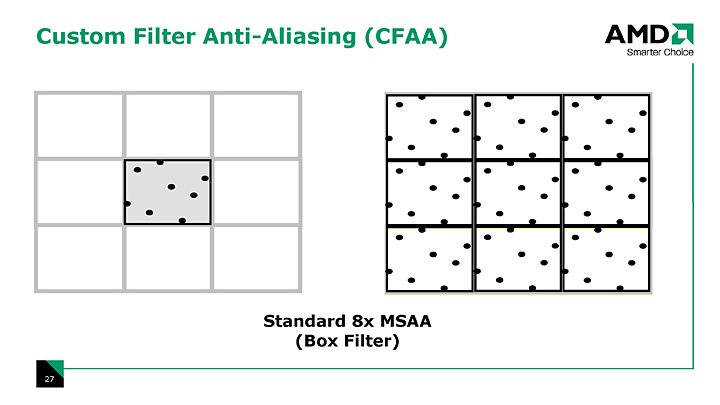
従来のアンチエイリアシング処理では,どんなにサブピクセルサンプルを増やそうが,そのピクセル境界内に限定されていた
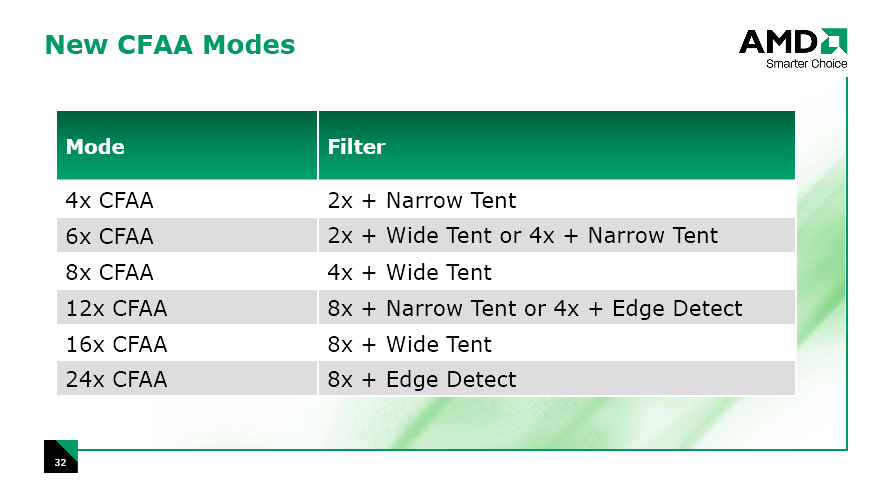
それぞれがどういった特徴を持つかは,過去の製品について解説した記事を参照してほしいが,ATI Radeon HD 2000シリーズではこれらに加えて新たに,「カスタムフィルタアンチエイリアシング」(Custom Filter Anti-Aliasing,以下CFAA)という新技術がサポートされる。
マルチサンプルにせよスーパーサンプルにせよ,これまでのアンチエイリアシング技術は,レンダリング結果として得たいピクセルを起点として“それよりも小さな仮想的なサブピクセル”を想定して処理していた。簡単にいえば,そのサブピクセルに対して実際にレンダリングを行うのがスーパーサンプル法であり,また,そのサブピクセル単位で深度値を見てエッジかどうかを判定してアンチエイリアシング処理するのがマルチサンプル法だったわけだ(このあたりの詳細な解説は筆者の連載バックナンバーを参照のこと)。
つまり,従来のアンチエイリアシング処理では,「処理に用いるサブピクセルは,必ずターゲットとなるピクセルの内側にあるもの」と限定されていたのである。


サポートされるCFAAのモード(上)と,各モードの違い(下)を示したスライド
こう書くと,CFAAの正体をなんとなく掴めるだろう。そう,CFAAは,あるピクセルのアンチエイリアシング処理を行うとき,その処理に用いるサブピクセルを,ピクセル境界にとらわれないで隣接するピクセルにまで広げて確保しようというものだ。
ピクセル境界を越えたサブピクセルが想定できるため,アンチエイリアシングの品質が上がり,また不用意にピクセルをぼやかしてしまう問題が低減し,シャープなエッジはちゃんと鋭く出るようになる。また,3Dグラフィックス映像でときどき目にする,「シーン内のキャラクターが細かく動いたときに見える,ピクセルが微妙に明滅したり踊ったりするような,アンチエイリアシング処理の弊害」も劇的に減らせる。
Demers氏によれば,CFAAはATI Radeon HD 2000シリーズのハードウェア機能として実装されているため,Windows XP環境下のDirectX 9/SM3.0世代のゲームソフトでもその効果を確認できるとのことである。
氏いわく,CFAAは少ないサンプル数でも効果は得られ,HDRレンダリングやステンシルシャドウとの相性がいい。また,このCFAAの発想は先ほど1〜4で示した既存のアンチエイリアシング処理と組み合わせることもできるという。
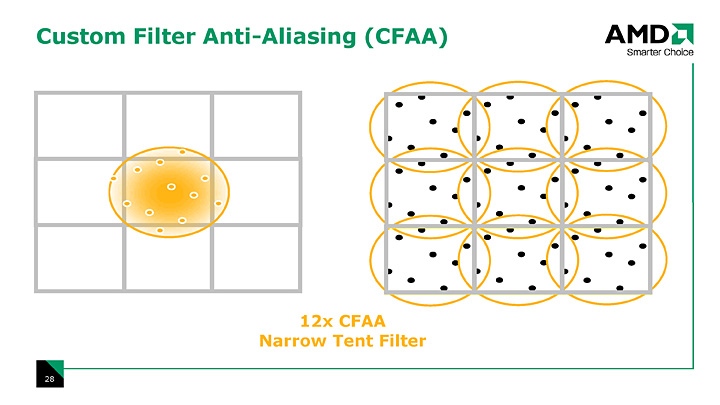
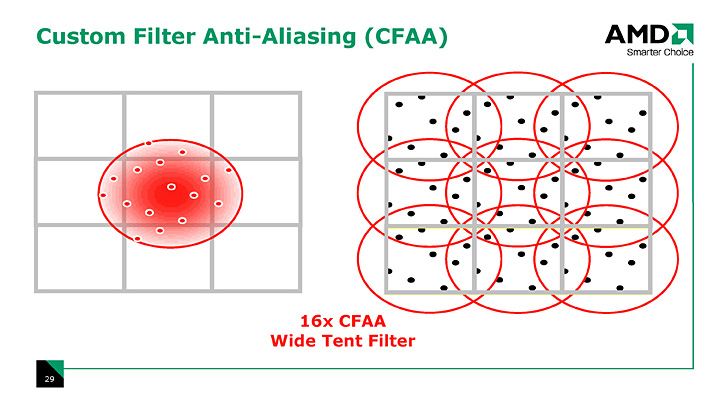
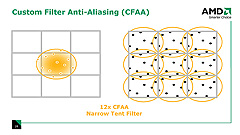
CFAAのフィルタパターンは,現在のバージョンだと,ごく近いサブピクセルを想定した「ナローテント」(Narrow-tent)や,隣接ピクセルのかなり中央寄りにあるサブピクセルをも想定した「ワイドテント」(Wide-tent)が用意されている。しかし,ハードウェア的にはサブピクセル位置をカスタマイズ可能だそうで,将来的に新たなフィルタが追加される可能性も示唆されている。
 |
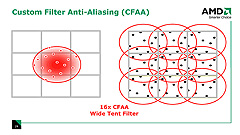 |
| 左が,隣接するピクセルにちょっとだけサブピクセルを想定するナローテントフィルタ。右は隣接するピクセルの奥まで貪欲にサブピクセルを想定するワイドテントフィルタ |
なお,現行のDirectX 10においては,こうしたアンチエイリアシングのフィルタカーネルはプログラマブルフィーチャーとして開放されていない。そのため,AMDがほのめかす新フィルタの追加が実現するには,DirextXでの対応とGPUメーカーの新ドライバ提供などを待たなければならない。しかし,将来登場するといわれるDirectX 10.1やDirectX 11では,プログラマブルアンチエイリアシングの標準的な仕組みを提供するとMicrosoftが予告していることは付記しておきたい。
ところで,こうしたピクセル境界を越えたサブピクセルを想定できるようになったのはなぜなのか。
これは,右に示したレンダーバックエンドのブロック図を改めて見てもらうと想像しやすいと思う。「Z/ステンシルキャッシュ」(Z/Stencil Cache)と「カラーキャッシュ」(Color Cache)が増強され,隣接するピクセルのサブピクセルの情報をキャッシングしておけるようになった。これが理由だ。
ピクセルAに着目した場合を考えてみると,ピクセルA境界外のピクセルB内のサブピクセルをサンプルしたとして,これをキャッシュメモリに保存しておくとする。続くピクセルBの処理の時には,同じ位置のサブピクセルの処理が必要になるが,先ほど保存したキャッシュから取り出して処理すれば,実際にグラフィックスメモリへアクセスしなくて済むのだ。ピクセル境界を超えたサブピクセルの想定は一見大胆かつ重い処理に思えるが,実は容量の大きいキャッシュメモリシステムと組み合わせれば,積極的な再利用ができるため,大きなパフォーマンス低下にはならないという理屈である。
|