









レビュー
レビュー後編。依然として謎の多いプロセッサの正体に,基本テストで可能な限り迫ってみた
Ryzen Threadripper 1950X
Ryzen Threadripper 1920X
 |
レビュー前編では,マルチスレッドが有効なアプリケーションを実行する限り,1950Xが2017年8月中旬時点で世界最高性能を持つことと,1920Xは同じタイミングにおけるIntelのHEDT市場向け最上位モデルである「Core i9-7900X」(以下,7900X)と互角のマルチスレッド性能を持つことをお伝えした。「買いか?」という疑問に対する回答も前編でお伝え済みなので,未読という人はぜひ一度読んでもらえればと思う。
今回は,前編の最後で予告していたとおり,もう少しミクロな視点からRyzen Threadripperの特性を調べ,どのような可能性を持つCPUなのかを考えてみることにしたい。
CPUコアのリビジョンやステッピングはRyzen 7シリーズと同一か?
 |
 |
簡単におさらいしておくと,UMAはCPUがメモリ空間に対して一律の速度や遅延でアクセスできるシステムで,これまでのデスクトップ向けPCのCPUはすべてこれだ。
一方,NUMAは複数のCPUがそれぞれ自前のメモリコントローラを持ち,メモリ空間に対して一律の速度や遅延ではアクセスできないシステムである。マルチソケットのサーバー機がNUMAの典型で,各ソケットのCPUは自身が持つメモリコントローラに接続されたメモリに対して高速にアクセスできるが,他のソケットのCPUのメモリコントローラに接続されたメモリに対してはアクセス遅延が生じる。
 |
そしてもう1つ,先行して市場に登場しているRyzen 7・5・3と,CPUコア周りに何か違いはあるのかないのかも気になるところだ。
というわけで,まずは「CPU-Z」(Verson 1.80)の表示から確認してみると,「Revision」欄がRyzen 7と変わっていないことが分かった。下に示したのは,1950Xと1920X,そして「Ryzen 7 1800X」(以下,1800X)のCPU-Z表示だが,「Family」から「Revision」までのすべてでRyzen ThreadripperとRyzenの表記は共通だ。つまり,Ryzen Threadripperは,「Ryzen 7を,Infinity FabricでMCMとして実装した製品」という可能性が高くなる。では,本当にそうなのか? ここもチェックしていきたいポイントということになるだろう。
なお,Infinity Fabric(やMCM)についてはレビュー前編で紹介済みなので,「なんだっけ?」という人は前編を参照してほしい。
 |
 |
 |
というわけで,さっそくテスト結果の考察に入っていきたい。
レビュー前編で再三お断りしたとおり,Ryzen Threadripperの貸し出し期間は短く,筆者の手元にはすでにない。テストシステムや基本設定を変更してテストすることなどはできるはずもなく,短い試用期間の中で,1950Xと1920X,そして比較対象である1800X,7900X,そして「Core i7-7700K」(以下,7700K)を用いて集中的に取得したデータのうち,前編で掲載していないものを載せる感じになる。
というわけで,5製品の主なスペックは表1のとおりだ。
 |
テスト環境は表2のとおりで,こちらももちろん前編と変わらない。
 |
Ryzen 7比で約2倍の性能を確認。見かけのメモリバス帯域幅はNUMAのほうが大きい?
以下,同じテスト項目のテスト結果を並べる場合であっても,数字の単位が異なるなど,そのまま1つのグラフで掲載すると見づらくなる場合はグラフを複数に分けることをお断りしつつ,テスト結果を順に見ていきたい。
まずは,FinalWare製のシステムチェック&ベンチマークツール「AIDA64」(Version 5.92.4300)である。
5.92.4300版AIDA64(のEngineer Edition)は,テスト時点においてRyzen Threadripperの対応が謳われていないが,AIDA64のベンチマーク部は古典的なx86およびx87命令やSSE,AVX,AVX-2命令を使用しているため,特別な対応を行うまでもなかったりはする。AIDA64のスコアは,「従来型のCPU」としての速度比較用として意味を持つと考えてもらえばいいだろう。
ここでのテストでは,Ryzenの「Precision Boost」および「XFR」,Coreの「Enhanced Intel SpeedStep Technology」(以下,EIST)および「Intel Turbo Boost Technology」(以下,Turbo Boost)と,7900Xでは「Intel Turbo Boost Max Technology 3.0」(以下,TBMax3)といった,自動の動作クロック変更機能はすべて有効化した。
まずは,PCユーザーが常用している状態で,Ryzen Threadripperと比較対象にどの程度の違いがあるのかを見ていこうというわけだ。
というわけでグラフ1は,主に整数演算主体のテスト結果から,4項目を抜き出したものになる。
 |
「CPU Queen」は,古典的なNクイーン問題(N-Queens Problem,n
結果を見ると,1950XのUMAとNUMAはほぼ同じスコアで,7900Xに対して約20%高いスコアを示し,明らかに頭一つ抜けている。動作クロックが異なるため,単純比較はできないものの,7900XをCPUコア数で6基上回る1950Xが堂々の勝利といったところだろうか。
1920Xのほうは,対7900XでUMA時に約3%,NUMA時に約2%高いスコアを示した。おおむね同等レベルのスコアという理解でいいかと思う。
1800Xのスコアが7900Xに対して約79%で,ほぼコア数比になっていることを考えると,1950Xおよび1920Xのスコアはもう一声ほしいところではある。このスコアからは,「CPU Queenのような単純なベンチマークであっても,Inifinity Fabricで相互接続となる2ダイ構成のRyzen Threadripperでリニアに性能が伸びるわけではない」ことを読み取るべきなのかもしれない。
なお,UMAとNUMAの違いは,CPU Queenにおいてはほぼ誤差範囲で一致と言っていい。Nクイーンの探索という比較的,シンプルな問題だとNUMAのほうが有利になるかと思っていたので,やや意外だ。
また,1950Xの「Game Mode」と1800Xとで,スコアがほぼ同じなのは面白い。8コア16スレッド化した1950XのGame Modeは,CPU Queenだと1800Xとほぼ同等の性能を持つということである。
続く「CPU PhotoWorxx」は,整数演算を使った写真の加工処理を行うテストで,AVXやAVX2,SSEといったSIMD演算を多用する。
ご覧のとおり,ここではUMAとNUMAの違いがはっきり出ており,1950XではUMAに対してNUMAのスコアが約22%,1920Xでは同12%高いという結果だった。画像のピクセル処理なので,メモリアクセス遅延が累積的に効いて,遅延状況で有利なNUMAのスコアが高くなった可能性はありそうだ。
一方,対7900Xだと1950XのNUMAモードは約7%,1920XのNUMAモードは約1%高いスコアとなっている。コア数の違いを考えるとギャップは大きくないが,1800Xが対7900Xで約64%に沈み,7700Kと比べてもわずかに低いスコアを示していることを考えると,Ryzen Threadripperはかなり健闘しているとも言える。
ここでRyzen ThreadripperのGame Modeに目を移すと,1950Xは約5%,1920Xは約3%,それぞれ1800Xより高いスコアだった。AIDA64の他の整数演算のテストでは1950XのGame Modeのスコアが1920Xのそれに対して約30%高いスコアを示すものの,CPU Photo Workxxでは約1%しか変わっていないのも目立つ点と言えるだろう。
原因は何とも言えないが,Ryzen系の3コアや4コアでは高い成績が得られないテストだ,と考えられる。
「CPU AES」はAES暗号化を行うテスト,「CPU Hash」はハッシュ値を求めるテストで,前者ではAES-NI命令を,また後者ではSHA命令をそれぞれ用いたものとなる。
このテストでは過去に1800Xが高いスコアを叩き出していたが,1950Xと1920XもRyzenなので,やはりスコアはとても高い。UMAとNUMAの両モードにおいてスコアは誤差範囲で一致しているため,今回はひとまずUMAモードのスコアを基準とするが,対7900Xで1950XはCPU AESで約2.7倍,CPU Hashで約3.9倍,1920Xも順に約2.1倍,2.9倍という圧倒的な大差を付けているのが見てとれよう。
1800Xに対して,1950Xが90〜100%程度,1920Xが約50%と,おおよそコア数分の性能向上が得られているのも目を惹く。
CPU AESやCPU Hashは暗号化というシンプルなテストだからこそ,コア数分の性能向上が得られるのかもしれない。いずれにせよCPU AESとCPU Hashの結果は,デスクトップPC用途ではあまりメリットがないものの,この数字は,Ryzen Threadripperと基本的には同じ設計のサーバー向けCPUであるEPYCにとって,相当な強みになるだろう。
整数演算系テストのうち,グラフ2にまとめたのは,古典的なx86命令のみを使ってデータの圧縮および展開を行うテスト「CPU Zlib」の結果だ。
1950Xと1920Xで,UMAとNUMA両モードのスコア差は誤差程度。一応,UMAモードのほうがわずかに高い傾向は見せているものの,ほぼ同じと言っていいはずである。
対7900Xだと,1950Xのスコアは約148%,1920Xだと約116%。リニアではないものの,コア数に応じたスコアが得られていることは分かる。1800Xが7900Xに対して約76%,7700Kに対しては約171%のスコアというところからしても,「Ryzenシリーズは古典的なx86命令を苦手にしていない」と言い切っていいように思われる。
 |
続いてはAIDA64から,浮動小数点演算を使うテストの結果だ。まずは6項目中4項目の結果をグラフ3に示した。
このうち「FPU VP8」はVP8形式のエンコードを実行するテストなのだが,7900Xのレビュー時と同様に,今回もほとんど横並びになってしまった。Ryzen,Coreとも,コア数に応じた性能の違いがほぼ生じていないという不思議な結果であり,ここから何かを推測するのは避けたほうがいいだろう。
 |
「FPU SinJulia」は,古典的なx87命令セットを使い,IEEE標準の80bit拡張精度浮動小数点演算でジュリア集合(Julia set,複素平面上である条件を満たす点の集合のこと)を計算するテストである。
1950Xと1920Xで,UMAとNUMA両モードの違いはないと言い切って問題ない。対7900Xだと1950Xは約2.1倍,1920Xは約1.58倍と,コア数比を超えたスコア差を競合製品に対して付けている。そもそも,8コア16スレッド対応の1800Xが10コア20スレッド対応の7900Xより若干ながら高いわけで,この結果は納得と言っていい。Ryzenは古典的なx87命令セットを得意としているわけだ。
続く「FP32 Ray-Trace」は,32bit単精度浮動小数点演算を使ってレイトレーシングを実行するベンチマークで,AVX系のSIMD演算やFMA命令を使用する。
1950XではNUMAモードのほうがUMAモードに対してわずかに高いスコアを残しているものの,「ほとんど一致」と言っても差し支えない程度の違いだ。
対7900Xだと,1950Xは91〜92%程度,1920Xは71〜72%のスコアで,コア数を考えるとかなり分が悪い。1800Xのスコアに至っては約47%でしかなく,7700Kよりも低いスコアだったりもするので,このテストはRyzenにとって不利なようである。
前述のとおり,Ryzen系はAVX-2のスループットがあまりよろしくないので,FP32 Ray-Traceはそれを反映したものということだろう。x87命令セットを前にしたときの無双ぶりとは対象的だ。
64bit倍精度浮動小数点演算を用いてレイトレーシングを行う「FP64 Ray-Trace」もFP32 Ray-Traceとさほど変わらない結果で,UMAとNUMAの違いはほぼないと言っていいだろう。
対7900Xだと1950Xが約84%,1920Xが約65%。1800Xが7700Kに届いていない点も,FP32 Ray-Traceと変わらない。
グラフ4は浮動小数点演算を使うテストの残り2項目におけるスコアをまとめたものになるが,「FPU Julia」は先ほど紹介したジュリア集合の計算を32bit単精度で行うもので,こちらもSIMD演算やFMAを使用する。というわけで,スコア傾向はFPU Mandelとほとんど同じだ。一応触れておくと,7900Xと比べて1950Xのスコアは約98%,1920Xは76〜77%程度といったところである。
「FPU Mandel」は64bit倍精度浮動小数点演算でマンデルブロ集合(Mandelbrot set,ジュリア集合と同様に複素平面上である条件を満たす点の集合のこと)を実行するテストで,SIMD演算やFMAを多用する。
1950Xと1920Xでは,あえて言えばUMAモードのほうがスコアは高いものの,ほぼ同じと見るべきだろう。対7900Xだと1950Xが約96%,1920Xが約75%で,コア数に見合ったスコアは得られていない。1800Xのスコアが7700Kと同程度という点からしても,RyzenがSIMD演算(AVX)やFMAを不得手にしていることはほぼ疑いようがない。
 |
以上,クロックを揃えずに1950Xと1920Xのスコアを見てきたが,大雑把にまとめるなら,古典的なx86命令やx87命令ではコア数に見合う性能が得られるものの,AVX系やFMA命令セットが使われるとRyzenは不利になるという傾向を,Ryzen Threadripperでも確認できる。
また,ここまであえて少ししか触れなかったが,1950XのGame Modeにおけるスコアは,1800Xと同等から約5%高めという傾向が出ている。
1950Xと1800Xの公称の動作クロックはほとんど変わらず,Game Modeでは1800X相当の8コア16スレッドになる。1800Xより,やや高めのスコアを出す傾向からするとCPUコアに何らかの改良が入った可能性が否定できない。しかし,一方で1950Xは1800Xより体積が大きく,よって熱容量も大きくなるので,1800Xよりクロックが上がりやすい可能性はあるだろう。約5%ならクロックのブレの範囲内という見方も可能で,CPUコアに改良が入ったと即断するのは危険だと考えられる。
次にグラフ5は,「Memory Read」「Memory Write」「Memory Copy」という,メモリ関連のテスト結果をまとめたものになる。
ここで「おや?」と思うかもしれない。1950Xと1920XではNUMAモードのほうがUMAモードより高いスコアを示しているからだ。
具体的に数字を見ていくと,1950XでNUMAモードはUMAモードに対してMemory Readで約21%,Memory Writeで約1%,Memory Copyで約4%高いスコアを示す。1920Xも順に約19%,約2%,約6%高いスコアだ。「メモリバス帯域幅で有利なのがUMA,メモリアクセス遅延で有利なのがNUMA」というのがAMDの言い分だが,それとは完全に逆の結果である。
 |
なぜこんなことになったのかだが,おそらく,AIDA64のメモリテストがマルチスレッド化されていることに原因があると,筆者は考えている。
NUMAモードではテストスレッドが特定のNUMAノードに割り当てられるが,UMAモードでは物理的なNUMAノードを無視して割り当てることになる。その結果として,UMAモードだとInifinity Fabricを介したメモリアクセスが発生し,Inifinity Fabricの輻輳などがメモリ帯域を圧迫したのではないだろうか。そうだとすれば,マルチスレッドでメモリにアクセスする場合は,帯域幅でもNUMAが有利になるかもしれない。
1950Xと1920XのGame Modeで,スコアが1800Xと同じかやや高い程度に留まるのも,AIDA64のメモリテストがマルチスレッド化され,総合性能を見ているとすれば,納得できるものと言えると思う。
なお,ここではもう1つ,1950Xと1920Xのスコアが同じ4chメモリアクセス仕様である7900Xをおおむね上回ることにも注目できる。細かく見ればUMAの1950Xおよび1920XだとMemory Readで7900Xを下回るが,それ以外のスコアは優秀だ。
Ryzen系では1800Xも,ライバルの7700Kに対してAIDA64のメモリテストで好成績を上げている。メモリの読み出しおよび書き込みの帯域幅では,1800Xの優秀さをそのままRyzen Threadripperが受け継いでいるという理解でいいだろう。
同じメモリ関連のテストから,グラフ6はメモリアクセス遅延を見る「Memory Latency」の結果だ。こちらはAMDの言い分どおり,1950Xでも1920XでもNUMAモードのほうがUMAモードと比べて20ns以上短いというスコアが出ている。付け加えるなら,NUMAモードのRyzen Threadripperは1800Xよりも優秀だ。
一方で気になるのはGame Modeのアクセス遅延で,スコアはなんと,UMAモードより大きい。Game Modeはゲーム向けに用意されているモードにも関わらず,メモリのアクセス遅延が大きいとなると良好なゲーム性能が得られない可能性が高くなってしまう。
 |
1つ気になっているのは,レビュー前編で述べたように,筆者が試用した時点ではAMD製のチューニング用ソフトウェア「Ryzen Master Utility」(以下,Ryzen Master)が未完成で,Ryzen MasterからUMAとNUMAを切り替えることができなかった点だ。
もしかすると,「Ryzen MasterでGame Modeを選択および適用したときにUMAからNUMAに固定されるはずが,今回は機能していなかった」という可能性は捨てきれない。
評価キットは筆者の手元を去って久しいため,もはや確認しようもないのだが,筆者の推測が正しいとすると,Game Mode時のメモリ性能はもっと上がってもおかしくはない。
さて,ここまではCPUの定格クロックを設定し,最高性能を期待できる状態で5つのCPUを見てきたが,ここからは参考までに全コアの動作クロックを3.5GHzで固定した状態のスコアも見ておきたい。
ただし,前編から再三の繰り返しで申し訳ないが,とにかく時間が足りなかったため,今回3.5GHz設定を行ったのは1950XのUMAモードと1800X,7900Xのみだ。1950XのUMAモードと1800XではPrecision BoostおよびXFRを無効化,7900XではEISTとTurbo Boost,TBMax 3.0を無効化してている。
グラフ7,8は,AIDA64における整数演算ベンチマークの結果だ。対1800Xで見ると,1950XのスコアはCPU Queenで約51%,CPU PhotoWorxxで約44%高い。単純な探索を多数のスレッドで処理するCPU Queenでは,コア数分の性能向上がもう少し得られてもいい気はするものの,性能が上がるかどうかはコードの書き方にもよるため,なんとも言えない。
CPU Queenだと,コア数の力で1950Xが7900Xを上回るものの,SIMD演算が多用されるCPU PhtoWorkxxだと1950Xが不利なるといった具合に,得手不得手がはっきり分かれている。
一方,CPU AESやCPU Hashではコア数分のきれいな性能向上を確認できた。1950Xのスコアは前者で約103%,後者で約100%高いので,「きっちり2倍」ということになる。
単純なテストだからこそCPUコア数が倍になっただけの性能向上が得られるわけだが,ただ,Inifinity Fabricの素性の良さがなければこうならないのも確かだ。AMDがZenマイクロアーキテクチャの鍵としているInifinity Fabricの実力がもたらした結果と見ていいだろう。
 |
 |
浮動小数点演算ベンチマークの結果はグラフ9,10のとおり。FPU VP8のテスト結果はここでもあまり当てにならない。
注目したいのは,残るすべてのテスト項目で,1800Xに対して1950Xのスコアがきれいに約2倍になっていることだ。コア数分の性能向上が得られているのは見事である。
一方,7900Xと比べると,古典的なx87命令を使うFPU SinJuliaで1950Xが約127%高いという圧倒的なスコアを叩き出しているのを除けば,おおむね互角かあと一歩という感じになっている。具体的なパーセンテージを示すと,FP32 Ray-Traceで約96%,FP64 Ray-Traceで約87%,FPU Juliaで約99%,FPU Mandelで約98%。AVX系の命令セットでSIMD演算を交えるとクロックあたりの性能でRyzen系が譲るものの,1950Xはコア数でそれを跳ね返して,7900Xとおおむね肩を並べるといった傾向がしっかりと窺える。
 |
 |
Sandra 2017ではUMAとNUMA両モードの違いが少し出てくる
続いては,SiSoftware製のシステム検査&ベンチマークツールである「Sandra」(Version 2017.06.24.27,以下 Sandra 2017)の結果も見ておきたい。まずはAIDA64と同じように,常用環境における結果からまとめていこう。
グラフ11はCPUの演算性能を見る「Processor Arithmetic」の総合スコア「Aggregate Native Performance」だ。
1950Xと1920Xで,UMAとNUMA両モードのスコア差はほぼないと言っていい。対7900Xだと1950Xは約32%,1920Xは3〜4%程度高いスコアで,この結果からは「コアあたりの性能でRyzen Threadripperは7900Xに及ばないが,コア数で押し切った」ことを確認できる。
また,1950XのGame Modeにおけるスコアは1800Xの約99%で,ほぼ同じという結果になっている。Game Modeに切り換え,8コア16スレッド対応となった1950Xの演算性能は1800Xとほぼ一致するという,AIDA64と同じ傾向だ。
 |
Processor Arithmeticの個別スコアをまとめたのがグラフ12となる。Ryzen Threadripperの2製品でUMAとNUMAの両モードに違いが見られないのは総合スコアと同じ。1950XのGame Modeにおけるスコアが1800Xとおおむね一致するのも同じだ。
対7900Xの具体的なスコアを見てみると,1950Xは「Dhrystone Integer Native AVX2」で約25%,「Dhrystone Long Native AVX2」で約29%高いスコアを示しているのに対して,「Whetstone Single-float Native AVX/FMA」と「Whetstone Double-float Native AVX/FMA」では約39%高いスコアだ。
1920Xも同じ傾向で,Dhrystone Integer Native AVX2だと約1%低いスコア,Dhrystone Long Native AVX2では約2%高いスコアのところ,Whetstone Single-float Native AVX/FMAでは約9%,Whetstone Double-float Native AVX/FMAでは約8%,それぞれ高いスコアを示している。
AVXやFMAが混ざるとRyzenで分が悪いという傾向がAIDA64では見られたわけだが,少なくともSandra 2017のProcessor Arithmeticだと,そういう結果は出ておらず,整数演算テストであるDhrystoneより,浮動小数点演算テストであるWhetstoneのほうがスコアは高い。要はテストによるということだろうか。
 |
続いてはマルチメディア処理性能を見る「Processor Multi-Media」だ。Processor Multi-Mediaでは筆者のミスにより,1920XのGame Mode時におけるデータを上書きして失ってしまった。それゆえ,当該条件のスコアがN/Aとなる点はお詫びしつつお断りしておきたい。
さて,Sandra 2017のProcessor Multi-Mediaだが,このテストでは,デスクトップPC向けとしてCore Xプロセッサで初めてサポートが始まった拡張命令「AVX-512」が多用されている。
7900Xのレビューでも触れたように,AVX-512を使う一般ユーザー向けアプリケーションはほとんど存在しない。総合スコアにあたる「Aggregate Multi-Media Native Performance」を見るグラフ13だと,AVX-512のおかげで7900Xがほかを圧倒してしまうが,ここで7900Xと比較することにあまり意味はないことを,まずは押さえてもらえればと思う。
というわけで1950Xと1920Xだが,UMAとNUMAの両モードでスコア差はほとんどなく,ほぼ一致していると述べていい。1800Xとの比較において,1950Xのスコアは約83%,1920Xのスコアは41〜42%程度それぞれ高いので,コア数の違いに応じたスコアがおおよそ出ているとも言えるだろう。
もちろん,4コア8スレッド対応の7700Kを相手にしないスコアも得られているので,AVX-512という,現時点では夢物語でしかない命令セットの仕様を除けば,マルチメディア系の処理でもRyzen Threadripperで高い性能が得られる期待が持てることになる。
なお,1950XのGame Modeにおけるスコアは,1800Xとここでもほぼ一致した。
 |
Processor Multi-Mediaの個別スコアはグラフ14,15のとおりだ。総合スコアと同様,1950Xと1920Xのいずれも,UMAとNUMAのスコア差は誤差範囲となっている。また,1950XのGame Modeと1800Xのスコア差もほぼない。
細かくチェックすると,単精度浮動小数点演算を使って画像のピクセル処理を行う「Multi-Media Single-float Native x64 AVX512F, AVX2」のみ,1950Xが1800X比で約98%と,ギャップが若干大きくなっているものの,ブレの範囲だと筆者は考えている。
個別スコアで興味深いのは,x86命令のみを使う「Multi-Media Quad-int Native x1 ALU」の結果だ。AIDA64だと,古典的なx86命令でRyzen系が圧倒的な優位性を見せていたが,ここでは7900Xや7700Kとの間にあるコア数の違いを踏まえるに,Ryzen Threadripperの優位性はそれほど生じていない。やはりここはコードの内容によるということなのだろう。
 |
 |
CPUを用いた暗号化の性能を調べる「Processor Cryptographic」の総合スコア「Cryptographic Bandwidth」をグラフ16にまとめた。
ここで注目したいのは,Ryzen Threadripperにおいて,NUMAモードと比べ,UMAモードが明らかに高いスコアを示しているところである。1950Xは約71%,1920Xでも約44%,UMAモードのほうが高い。
Sandra 2017のProcessor Cryptographicには,暗号化のアクセラレーションを用いるテストが含まれているため,メモリバス帯域幅がスコアを左右しやすくなる。素直に考えれば,UMAモードの持つメモリアクセス帯域幅の広さが出たと考えられるが,個別スコアを参照して判断すべきだろう。また,NUMAモードでは1950Xが1920Xより低いスコアを出しているが,その理由も個別スコアを見て判断したほうがよさそうだ。
7900Xとの比較だと,1950XのUMAモードは約12%高いスコア,1920XのUMAモードはぴったり同じスコアをそれぞれ示した。いずれもまずまずと言ったところか。
ちなみに,1950XのGame Modeは1800Xと比べて約10%高いが,これは今回のテストにおいて,Game ModeにおけるUMAモードが有効になっているためだと思われる。
 |
Processor Cryptographicの個別スコアがグラフ17で,UMAとNUMA両モードのスコア差がより顕著に出ているのはアクセラレーションを使う「Encryption/Decryption Bandwidth AES256-ECB AES」のほうだということがよく分かる。1950Xだと,NUMAモードに対してUMAモードのスコアは約123%,1920Xでも約107%高く,いずれも2倍以上だ。
また.「Encryption/Decryption Bandwidth AES256-ECB AES」はUMA,NUMAの両モードで1950Xよりもむしろ1920Xのほうがやや高いスコアになっている。アクセラレーションを行うAES命令を使うテストなので,AESのアクセラレーションではコア数に応じた性能向上が得られない,という可能性がある。
アクセラレーションを使用しない「Hashing Bandwidth SHA2-256 AVX512, AVX2」に目を移すと,NUMAモードでは1950Xと1920Xのスコアがほぼ変わらないのに対し,UMAモードだと1920Xに対して1950Xで約29%高いスコアが得られている。NUMAモードでコア数に応じた性能が得られない理由は推測の域を出ないが,NUMAノードにスレッドを集中させる関係で遊んでいるCPUコアができているのかもしれない。
一方,対7900XだとRyzen系はEncryption/Decryption Bandwidth AES256-ECB AESがいま1つで,アクセラレーションを使用しない「Hashing Bandwidth SHA2-256 AVX512, AVX2」のほうが成績がいい。
AES命令で高い性能を持つようだというAIDA64の「CPU AES」の結果と正逆だが,その理由は正直,不明だ。
 |
グラフ18は,科学技術計算を行う「Processor Scientific」の総合スコアにあたる「Aggregate Scientific Performance」をまとめたものだ。ここでも,Ryzen ThreadripperではUMAモードのスコアがいい。対NUMAモードで1950Xは約40%,1920Xは約38%高いスコアを示した。
1950Xと1920Xのスコアがほとんど変わらないのも特徴だが,その理由は個別スコアを見て判断すべきだろう。
対7900XでRyzen Threadripperが振るわないのも特徴で,UMAモードで見ても1950X,1920Xとも約91%というスコアになっている。
 |
その原因は個別のスコアを見るとはっきりする。グラフ19,20に示したのがそれだが,グラフ20の「Fast Fourier Transform (FFT) FMA」(以下,FFT)におけるテスト結果はかなり極端で,これが総合スコアを大きく左右したと言えそうだ。
FFTでは,まずUMAモードとNUMAモードの違いが「General Matrix Multiply (GEMM) FMA」や「N-Body Simulation (NBDY) FMA」に比べると相当に大きい。対NUMAモードで,UMAモードのスコアは1950Xが約92%,1920Xが約90%それぞれ高いといった具合である。
また,1950XのUMAモードと1920XのUMAモードのスコア差がほとんどないことから,CPUコア数に応じた性能の向上が得られていないことも見てとれる。
ちなみに7900Xとのスコア差は大きく,UMAモードにおける1950Xのスコアは7900X比で約76%,1920Xでは約66%になってしまっている。
 |
 |
何故こうなるかだが,FFTの一般的なアルゴリズムだと同じデータに頻回のアクセスが発生する。そのため,「キャッシュやメモリの帯域幅が最終的な性能を左右する度合い」が大きい。
NUMAモードだとFFTのスレッドはおそらく特定のNUMAノードに割り当てられるため,CPUが半分遊ぶ形になるだろう。となればUMAが極めて高いスコアを残したことが納得できる。
7900Xとのスコア差が大きいのは,Ryzen Threadripperdで同一データへのアクセスコストがInifinity Fabricの影響で大きいことが影響したか,あるいはキャッシュの性能差が出たといったところではないかと推測している。
続いては,AVXやFMAを使用した2D画像の処理性能を見る「Processor Image Processing」だ。
ここでも筆者のミスにより,1950XのNUMAモード時におけるテストデータを上書きして失ったため,当該スコアはN/Aとなる。この点はお詫びしたい。
さて,グラフ21は総合スコアにあたる「Aggregate Image Processing Rate」だが,UMAとNUMA両モードの違いは,1920Xのテスト結果を見る限りほとんどなかった。ここまでのテスト結果からするに,1950XでもUMAとNUMAで大きな違いは生じていないはずである。
対7900XだとRyzen Threadripperは振るわず,1950XのUMAモードは約104%,1920XのUMAモードは約83%に留まっている。コア数の力で1950Xがようやく7900Xに肩を並べている格好だ。
 |
Processor Image Processingは3つのグラフに分けたが,全体としてRyzen Threadripperのスコアは,7900Xと比べて出入りの激しいものとなっている(グラフ22,23,24)。
興味深いスコアを拾ってみると,まずグラフ22にある「Diffusion: Randomise (256) Filter x8 AVX2/FMA」で,1920XのUMAモードとNUMAモードを比較したとき,前者のほうが約24%高いスコアを示している点が興味深い。また,1920XのUMAモードは7900Xに対しても約24%高いスコアを示す。1950XのUMAモードに至っては,対7900Xで約54%高いスコアだ。
なぜこうなるかは推測の域を出ないが,Diffusion: Randomise (256) Filter x8 AVX2/FMAは誤差拡散を行うテストなので,マルチスレッド化すると複数のスレッドが同一のデータ(メモリ領域)を参照する実装になることが考えられる。その場合,NUMAモードだとスレッドをNUMAノードに割り振るためにCPUコアが遊びやすくなり,UMAモード有利になるのかもしれない。
 |
 |
 |
そうかと思えば,グラフ22の「Blur: Convolution (3x3) Filter x8 AVX2/FMA」やグラフ23の「Sharpen: Convolution (5x5) Filter x8 AVX2/FMA」などでは,1950XのUMAモードでも7900Xに及ばない結果になった。
いま名を挙げた2つのテストは,前者が畳み込みを使ったボカシ,後者が畳み込みを使った先鋭化で,双方ともFMA命令が主役になる処理だ。Core Xと比べて,Ryzen系はFMA命令を苦手としている可能性が高い。
グラフ25は,CPUコア間のデータ転送の帯域幅を調べる「Processor Multi-Core Efficiency」の結果だ。グラフ画像をクリックすると,スコアの詳細をまとめた表3を表示するようにしてあるので,そちらもぜひ参考にしてほしい。
スコアで非常に面白いのは,1950Xが7900Xに対し,L2キャッシュに収まる容量帯である「4x 64kB Blocks」を中心として,大きなコア間帯域幅を持っているという点だ。具体的に言うと,「4x 64kB Blocks」では1950Xが7900X比で約27%大きい。Infinity Fabricの持つ帯域幅が極めて大きいことを示すという解釈でいいだろう。
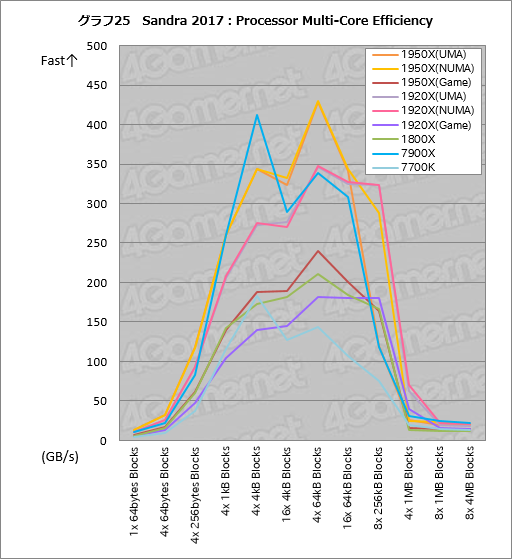 |
1950Xのスコアに注目すると,NUMAモードに比べてUMAモードでは「8x 256kB Blocks」でやや大きめの落ち込みが見られる。ただ,1920Xでは同様の傾向がないので,たまたま何か起きた可能性は否定できない。
付け加えると,1920XのNUMAモードでは「4x 1MB Blocks」の帯域幅がかなり高く出ているのに対して,UMAモードや1950XのUMAおよびNUMAモードではそうではないなど,同じRyzen Threadripperでもメモリアクセスモードや製品によってやや異なる傾向を見せるのが面白い。何故こうなるのかは今のところよく分からないが,一筋縄ではいかないCPUという印象はある。
グラフ26は,メモリバス帯域幅を見る「Memory Bandwidth」の総合スコアをまとめたものだ。「Ryzen ThreadripperはUMAモードよりNUMAモードのほうが成績がいい」という点で,AIDA64のメモリテストと同じ傾向になった。
AIDA64と同じように,Sandra 2017のメモリテストもマルチスレッド化され,NUMAノードにテストスレッドが割り振られる影響ではないかと推測している。
 |
上のグラフ26で1950Xより1920Xのほうが高いスコアを示しているのに気付いた人もいると思うが,その傾向は整数を使う「Integer Memory Bandwidth B/F AVX512/512, AVX2」や浮動小数点数を使う「Float Memory Bandwidth B/F AVX512/512, AVX2」でも変わらない(グラフ27)。
メモリ周りの設定は1950Xと1920Xでとくに変えていないため,この結果はそれ以外の要因によるものだろう。テストスレッドが16コア32スレッドと大きく増えていることが輻輳を招いたとか,そういった原因があるかもしれない。
いずれにしても,1950X,1920Xとも総合的には7900Xのメモリバス帯域幅に引けを取らず,NUMAモードだと7900Xを超えるスコアが得られた。ただし,NUMAモードでは「2つのNUMAノードに割り当てられたテストスレッドの,総合的なメモリバス帯域幅」という意味合いになるので,NUMAノードが1つのみである7900Xのメモリバス帯域幅とは性質が異なるため,その点には注意が必要だろう。
 |
キャッシュおよびメモリの遅延を計測する「Cache & Memory Latency」の結果がグラフ28である。ここでもグラフ画像をクリックすると,詳細データをまとめた表4を表示するようにしてあるが,見てもらうと分かるように,Ryzen系では「CPU Complex」(以下,CCX)が持つ容量8MBの共有L3キャッシュ以上のサイズで遅延が大きくなるのが見てとれる。これはRyzen ThreadripperとRyzenで共通の傾向だ。
8MBならRyzen ThreadripperのL3の範囲と思うかもしれないが,Ryzen ThreadripperのL3は2基のCCXに8MBずつで合計16MBだ。テストブロックサイズが8MBだと,CCXあたり8MBとなるL3キャッシュの更新が頻繁に発生するため,オーバーヘッドが大きくなり,遅延となって現れるわけである。
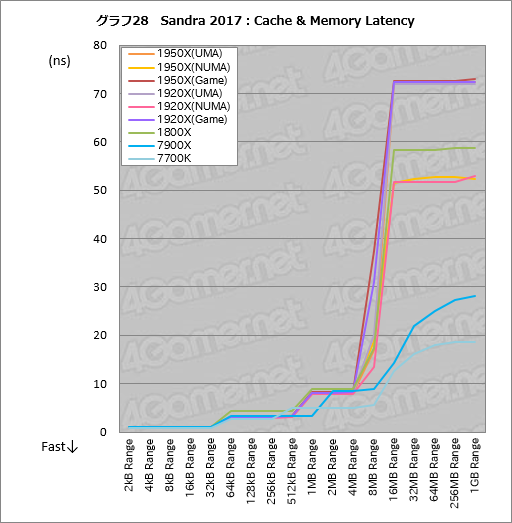 |
UMAとNUMA両モードの違いは,2基あるシリコンダイ(=CCX
ちなみにNUMAモードだとUMAモードに対して約20ns良好だった。ここはAMDのアナウンスどおりといったところである。
なお,「32MB Range」以上のサイズで1950Xと1920XのNUMAモードにおける遅延状況が1800Xに対して低くなっているのは,レビュー前編でお断りしたとおり,メモリモジュールの仕様が異なるためである。
32MB Range以上のサイズでむしろ注目したいのは,Intel勢に対しAMD勢の遅延が大きいことと,さらに14-14-14-34という実にアグレッシブな設定のメモリモジュールを組み合わせてあるRyzen Threadripperですら,7900Xより相当大きな遅延状況になっていることのほうだ。AMDも「AGESA」の改善などによりメモリアクセス遅延を減らす努力をしているが,現時点だとまだDDR4の扱いではIntelに一日の長があるということがよく分かる。
次にグラフ29はキャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果である。以前,Sandra 2017が本テストで7900XのL3キャッシュを認識しないことがあったため,今回は今回はテストブロックサイズごとに個別帯域をグラフにまとめてある。グラフ画像をクリックすると,詳細スコアのまとまった表5を参照してもらえるので,そちらもチェックしてほしい。
結果で面白いのは,L2キャッシュに収まる「256kB Data Set」以内の帯域で7900Xが他を圧倒する一方,それを超えると,「16MB Data Set」までは1950XのUMAおよびNUMAモードが他を圧倒するところだ。とくにCCXが持つL3キャッシュの合計容量を超える「16MB Data Set」の帯域幅が770GB/sを超えているのが目を惹く。
前述のとおり,2基のCCXが持つ合計16MBのキャッシュと同一サイズのテストだと,Infinity Fabricやメインメモリの帯域幅が効いてくるはずだ。ここまでも何度か触れているとおり,Infnity Fabricは極めて高い性能を持つようである。
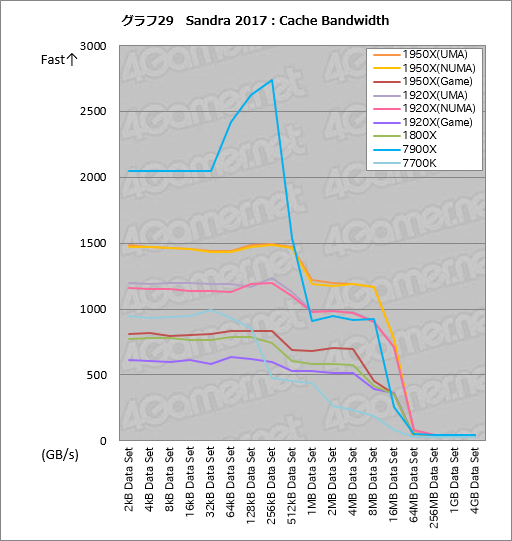 |
グラフ30は「マルチスレッド環境において,スレッド間でメモリの競合が発生した場合」のメモリ速度性能を見る「Memory Transaction Throughput」だが,一見しただけで分かるように,TSX命令セットをサポートするIntel勢の圧勝。Ryzen系はまったく勝負になっていない。
もちろん,TSX命令セットはまだ積極的に使われているわけではないので,デスクトップPCでこの性能差がハンデになることはないだろう。ただ,Intelはエンタープライズ向けのオンメモリデータベース「SAP HANA」におけるTSX命令の効用をアピールし始めていたりするので,サーバー向けCPUであるEPYCでは「TSX命令をサポートしないこと」がハンディキャップとなる可能性は感じる。
 |
以上,Sandra 2017のスコアを見てきたが,自動クロックアップ機能が有効な状態ではやや分かりにくいところがある。そこでAIDA64と同じように,1950XのUMAモードと1800X,7900Xの3製品で全コアを3.5GHzに固定したときのスコアも参考までに掲載しておきたい。
グラフ31,32はProcessor Arithmeticの結果である。1950Xと1800Xを比較すると,総合スコアも個別スコアもきれいに約2倍という性能向上率が得られている。また,クロックを揃えた7900Xに対して,1950Xが総合スコアで約50%,個別スコアで44〜59%程度高いという,コア数とおおむね見合う比率の結果が出ているのも見どころだ。
 |
 |
Processor Multi-Mediaのスコアはグラフ33〜35にまとめた。
前述のとおり7900XではAVX-512が使われてしまうため,1950Xの7900Xに対するスコアはほとんど参考にならない。古典的なx86命令を使うMulti-Media Quad-int Native x1 ALUで,1950Xが約57%高いスコアを示し,またAVX-512を使用しない「Multi-Media Quad-float Native x2 FMA」で18%高いスコアを出しているのが見どころだろうか。
対1800Xだと1950Xは総合スコアで約92%高いスコアを叩き出し,個別のテストでも78〜104%高いスコアを示した。Processor Arithmeticほどの安定感はないものの,コア数に応じたスコアの向上はおおむね得られているという理解でいい。
 |
 |
 |
続いてグラフ36,37はProcessor Cryptographicの結果である。
対7900Xで1950Xは総合スコアで約114%,AES命令によるアクセラレーションを使うEncryption/Decryption Bandwidth AES256-ECB AESで約94%,AVX-2命令を使うHashing Bandwidth SHA2-256 AVX512, AVX2では約138%というスコアになっている。クロックを揃えた場合でも,AVX2を使う後者のほうが1950Xの成績はいいわけだ。
対1800Xだと,1950XのスコアはHashing Bandwidth SHA2-256 AVX512, AVX2で約2倍。総合スコアでも約88%高い。
 |
 |
グラフ38,39,40はProcessor Scientificの結果だが,やはり特徴的なのはグラフ40のFFTだろう。1950Xは対7700Xで約77%,対1800Xでも約120%のスコアに留まる。原因は前述のとおり,FFTのアルゴリズムにあるはずだ。
 |
 |
 |
Processor Image Processingの結果がグラフ41〜44だ。クロックを揃えていないときの結果を覆すスコアは出ていない。
Diffusion: Randomise (256) Filter x8 AVX2/FMAで1.68倍とやや伸び悩む以外,1950Xは1800Xと比べてほぼ2倍のスコアが得られている。
 |
 |
 |
 |
動作クロック3.5GHz揃えでのテスト,最後は「Processor Multi-Core Efficiency」である(グラフ45)。ここでもグラフ画像をクリックするとスコアの詳細がまとまった表6を表示するようにしてあるが,先のグラフ25と比べると,動作クロックが揃っている分だけ分かりやすくなり,「4x 64kB Blocksを中心に1950Xが極めて広い帯域幅を持つ」傾向がよりはっきりする。
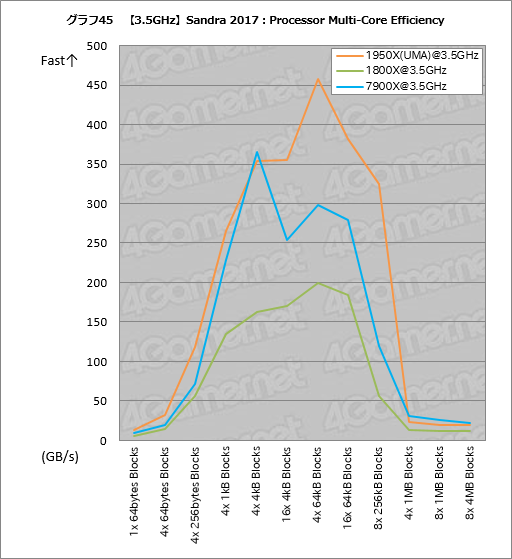 |
……ここまで,長々とSandra 2017の結果を見てきた。UMAモードとNUMAモードで明快な違いが出るケースが多く,このことがAIDA64との違いと言えるのではなかろうか。
ちなみにWindowsでは,NUMAノードが2基以上あるプラットフォームに対して,特定のNUMAノードのメモリを割り当てるAPI「Virtual
Ryzen ThreadripperのNUMAモードで,これらのAPIを使ってアプリケーションを最適化すれば,Ryzen Threadripperでさらに高い性能が得られる可能性はある。ただ,これらのAPIを使った最適化はこれまで,サーバーでしか行われていないことは,押さえておく必要があるだろう。
「Ryzen Threadripperが登場したからといって,一般向けのアプリケーションでNUMAノードを意識した最適化が行われる期待はあまり持てないかな」というのが,筆者の見方だ。もちろん,最終的にはこれからのAMDの働きかけにかかっているのだが。
消費電力補足:典型的な消費電力を調べてみた
最後の最後は補足である。
レビュー前編で,1950Xおよび1920Xの消費電力を掲載した。4Gamerでは,ベンチマークレギュレーション20.0で,消費電力測定にあたってはEPS12Vの電流を測定し,12を掛けて電力換算した値を使うことにしているが,このとき採用する値は基本的に,「アプリケーション実行時のピーク値」としている。
これはこれで無意味なデータではないのだが,EPS12Vの電流は「CPUのナマの消費電力」に近いため,変動が極めて大きい。そのためピークだけを見ると一種の異常値を拾ってしまう問題がある。つまり,ごくわずかな回数しか測定されていない異常なピークが現れた場合,それがスコアとして採用されてしまう欠点があるわけだ。
実際,レビュー前編で異常だったのは1800Xのスコアで,「DxO OpticsPro 11」を用いたテストの実行時に,なんと210Wという,10コアの7900Xに迫るピークを叩き出してしまった。
この問題を解決する豊富はいろいろ考えられ,最もシンプルな解決策は「平均を取る」となるわけだが,実のところ「平均を取ると,あまり公平でなくなる」という問題がある。
というのも,測定の開始と終了を手動で行っている関係で,各テスト対象で完全に揃えるのがほぼ不可能だからだ。そのため,あるCPUのテストではアプリケーション終了後のデータ5分ぶんも集計しているが,別のCPUでは3分しか集計していないというバラつきが生じる。
言うまでもなく,アプリケーション開始前や終了後のデータ件数が多いCPUほど,平均を取ると有利になってしまう。「アプリケーションがいつ始まり,いつ終わったか」を残されたデータから推測するのはとても難しく,また,「開始終了を推定してデータを切り出す」という方法も,推定の仕方次第で結果が変わってしまう恐れがある。
そこで今回は,残されたデータの頻度分析を行い,最も高頻度で測定された消費電力を調べてみることにした。いわゆる「最頻値」を調べてみようというわけだ。最頻値であれば,異常なピークだけでなく,CPUがアイドル状態へ入ったときの低い消費電力もスコアから取り去ることができ,おおよそ「アプリケーション実行中の典型的な消費電力」を得ることができるのではないか?
というわけで今回分析することにしたのはDxO Optics Pro 11である。結果はグラフ46のとおりで,またもや驚きの結果となってしまった。
1950Xの最頻値は148W,1920Xだとそれより低い139W。つまり「DxO Optics Pro 11を実行中,当該消費電力で推移している時間が最も長かった」わけだが,16コア32スレッド対応,もしくは12コア24スレッド対応のCPUとして,Ryzen Threadripperの消費電力最頻値はかなり低いと言っていいのではなかろうか。というか,140WとされるTDP(Thermal Design Power,熱設計消費電力)をはるかに超える数字が最頻値となった7900Xと比べると,Ryzen Threadripperの消費電力対性能比は素晴らしいと言っていい。
今回4Gamerで試した個体が2個とも「当たり」だった可能性は排除できないものの,Ryzen Threadripperが7900Xと比べて扱いやすいCPUということは,言い切ってしまっても構わないと考えている。
 |
レビュー前編でピークが異常に高かった1800Xのスコアは今回,1920Xと同じレベルに収まった。もっとも,95WというTDPのスペックからすると高めで,1800XはCPUをフルに回したときにかなり高い消費電力を記録する性質があることは間違いないようだ。
なお,前述のように4Gamerのベンチマークレギュレーション20.0では測定されたピークの消費電力をアプリケーション実行時のスコアとして採用しているが,異常値を取り去るという意味で,ピーク以外のデータも採用していく形に改善することになりそうだ。
最頻値を取るか,あるいは中央値を取るのかは検討の余地がありそうだが,いずれ改定したレギュレーションを公開できるのではないかと思う。
まだまだ追求できた気がしないRyzen Threadripper
 |
ただ,UMAとNUMA両モードの振る舞いは,まだ理解できたとは言いがたい。とくに厄介なのが,標準のメモリアクセスモードであるUMAで,見かけのメモリ読み出し/書き込み帯域幅はNUMAより劣る場合がある一方,SandraのFFTに見られたようにUMAが有利になる場合もある。
最も大きな要因として推測できるのは,NUMAモード時,物理的に近いメモリを割り当てるため,CPUコアの半分が有効に使われないから,と考えられるが,短い試用期間の間でCPU負荷率を調べることができたのはffmpegを使ったトランスコード時のみだ。その他のアプリケーションでは調べられていない。
ffmpegと同様のことが多くのマルチスレッドアプリケーションで発生するのなら,UMAを選択するのが無難という結論になるだろう。というのも,Sandra 2017の考察,最後のところでも述べたとおり,NUMAモード向けの最適化がゲームを含めた一般ユーザー向けアプリケーションで広く実現されることは考えにくいからである。
ちなみに筆者が理解している限り,UMAモードだと,「CPUに近いメモリを意図的に割り当てる」といった,Ryzen Threadripperの特性に合わせたアプリケーションの最適化は行えない。アプリケーションレベルから物理メモリページを操作する方法がないからである。
機会があれば,Ryzen ThreadripperのCPUの振る舞いをもう少し調べてみたいと思うが,今回はここまでとしたい。
- 関連タイトル:
 Ryzen(Zen,Zen+)
Ryzen(Zen,Zen+) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー