














業界動向
数値演算から機械学習へと手を広げるIntelのプロセッサ「Xeon Phi」を,ゲーマーはどう位置づけるべきか
 |
ただ,振り返ってみると,4Gamerで「Xeon Phiとはなんぞや」という話を系統立てて行ったことはなかった。そこで本稿では,Xeon Phiとはいったいどういうプロセッサであり,それがゲーマーにとってどのような位置付けにあるものかを説明してみたいと思う。
汎用GPUを目指した「Larrabee」
競合に追いつけず製品化もされず
まずはXeon Phi誕生のきっかけあたりから話を始めよう。
Xeon Phiの前身にあたるのは,開発コードネーム「Larrabee」(ララビー)という,GPUやGPGPU用途をターゲットにしたコアである。
Larrabeeの開発がいつ始まったのかは,明確な資料がない。筆者の記憶が確かなら,統合型シェーダ(Unified Shader)を実装する「DirectX 10」(Direct3D 10)がMicrosoftの開発ロードマップに載り始めたのは,2004年頃だ。それより前のタイミングで主要なGPUベンダーには説明が行われていると考えるに,2003年頃にはそうした話は出てきていても不思議ではない。
ある意味では今も変わっていないのだが,当時のIntelは,グラフィックス用プロセッサとして,グラフィックスチップ「Intel 740」を発展,拡張したものしか持っていなかった。これをなんとか改良して統合型シェーダアーキテクチャ(≒Direct3D 10)へ対応させたところで,競合に対する性能面のアドバンテージはない。
そのうえ2003年頃には,GPUを汎用計算に利用する新しい手法「GPGPU」(General Purpose GPU)が,いよいよ現実的になりつつあった。こうした動向を見据えて,Intelは,まったく新しいGPUをゼロから構築しようと考えたようだ。これがLarrabeeである。
Larrabeeという開発コードネームは,2006年頃から漏れ伝わるようになっており,2007年にも日本でのイベントで,ちょっとだけ情報を公開していた(関連記事)。
Intelが,明確に製品としての存在を明らかにしたのは,2008年春に行われたIntel Developer Forum(以下,IDF) China 2008でのことである。このときに,「Visual Computing」(ビジュアルコンピューティング)をキーワードとして,初めてLarrabeeの存在を公表した。ただ,この時点では,「Intel Architecture(以下,IA)ベースのメニーコア構成になる」という以上の詳細は明らかにされていない。
Larrabeeの内部構造や特徴が明らかにされたのは,2008年8月に開催されたSIGGRAPH 2008だった。
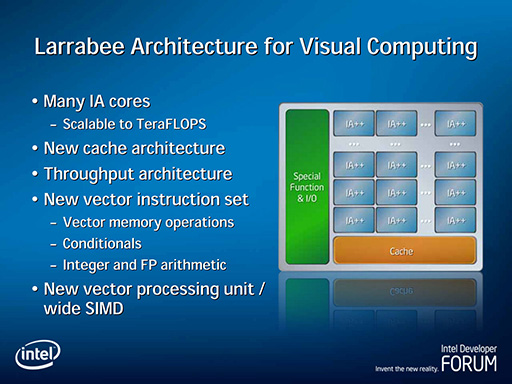 |
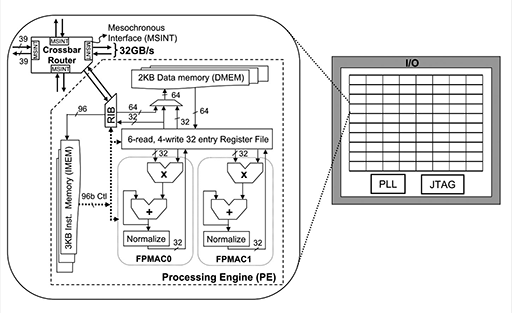
簡単に説明すると,Larrabeeの内部は,複数個のIAコア(のちに16個と明らかにされた)とL2キャッシュ,周辺回路を512bit幅の双方向リングバスでつなぐ構造になっていた。
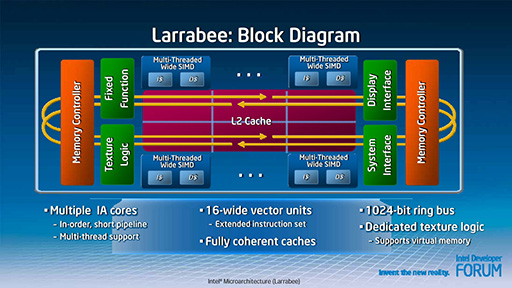 |
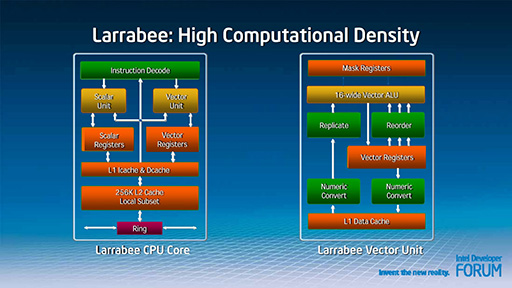
それぞれのIAコアは,「P54C」,つまり初代「Pentium」をベースにした2命令のインオーダー構造であるが,新設の「Vector Unit」を備えているのがポイントだ。Vector Unit内部は,16並列のSIMDエンジン(Vector ALU)という構成になっている。
 |
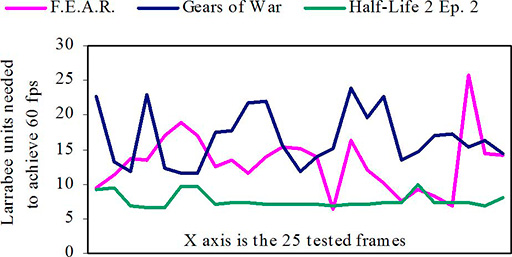
動作クロックなどは明らかにされなかったが,SIGGRAPH 2008でIntelは,「F.E.A.R」「Gears of War」「Half-Life 2: Episode Two」(以下,Half-Life 2:EP2)を60fpsで動かすのに,Larrabeeが何コアあれば足りるかという数字を公表したこともある。
それが下の折れ線グラフだ。これは縦軸が「60fpsで動かすのに必要なコアの数」,横軸がゲーム中の計25シーンを示している。当時のLarrabeeは最終製品が16コアになる予定になっていたから,「Half-Life 2: EP2なら安定して60fpsを出せるが,残る2タイトルではけっこう厳しい」レベルだったようだ。
ちなみに,2008年時点では,まだテスト用の10コアのものがあるだけで,目標としていた16コアのLarrabeeは存在しなかったという。
 |
 |
ところがそこから急に同社の方針は切り替わり,最終的に「製品化しない」決断を下した。Intelの方針転換を伝えた2009年12月の記事で,その理由はいくつか挙がっているが,致命的だったのは,Larrabeeのサンプル版を評価した顧客から,「絶対的な性能が足りず,かつ消費電力が大きすぎて,AMDやNVIDIAのGPUと比較して競争力がない」と評価されたのが,やはり致命的だったようだ。
なおIntelは,45nmプロセス技術を用いて製造する16コア版Larrabeeに続き,32nmプロセス技術を用いて24コアを統合する「Larrabee 2」(開発コードネーム)の投入も予定していたのだが,これも同時にキャンセルしている。
GPU路線からの方針転換
Larrabee 3はGPGPU用途のKnights Ferryへ
ただ,方針転換の記事にもあるように,「GPGPU的な用途では悪くない」という評価を受けていたため,IntelはLarrabeeプロジェクトを,GPU向けからGPGPU向けへと方針転換することになる。その背景にあるのは,Larrabeeとは別に,Intelの研究開発チームが研究を進めてきたメニーコアプロセッサの存在だ。
方針転換の2年前となる2007年2月,Intelは,半導体関連学会であるISSCC 2007で,「Network on Chip」(NoC)と称する80コア構成のテストチップを発表していた(関連記事)。NoCはIAベースのプロセッサではなく,1サイクルで乗算と加算を2つずつ実行――つまり4FLOPS――可能な,浮動小数点演算のみに対応するプロセッサを80個集積したうえで,これらを二次元メッシュ接続したものである。
 |
 |
このNoCを動作クロック3.13GHz,動作電圧1Vで動かして,「1チップで1TFLOPSを実現した」というのが,論文の内容だった。
ちなみに,消費電力は動作電圧1Vの場合で,98W程度である。同時期のGPUを思い出すと,2007年登場の「GeForce 8800 GT」はシェーダプロセッサの動作クロックが1.5GHz,単精度浮動小数点演算性能がおおむね500GFLOPS程度,消費電力が105Wだったので,NoCはその倍近いの性能を実現できていたわけだ。
あくまでもNoCはテストチップなので,これをそのまま製品化するわけにはいかない。だが,ここで得た知見は,とくにソフトウェア開発に役立ったようである。Larrabeeよりも,もっと多くのGPUコアを効率的に動かすためには,ソフトウェア側の対応が必須だからだ。
この新しいコアは,当初こそ「Larrabee 3」という開発コードネームで呼ばれていたが,縁起が悪いとでも思ったのか,Intelは新しく「Knights Ferry」(ナイツフェリー)という開発コードネームを与えている。
正確を期せば,Knights Ferryはチップを搭載するカードの開発コードネームであり,チップ自体の開発コードネームは「Aubrey Isle」(オーブリーアイル)だ。しかし,
さて,Intelは,2010年3月に開かれたスーパーコンピュータ関連イベントである「International Supercomputing Conference」(以下,ISC)の会場で,Knights Ferryを公開した。
 |
 |
Knights Ferryの構成は,Aubrey Isleチップと容量1GBもしくは2GBのGDDR5メモリを2スロット仕様のPCI Expressカードに収めるというもので,TDP(Thermal Design Power,熱設計消費電力)は300Wとなっていた。
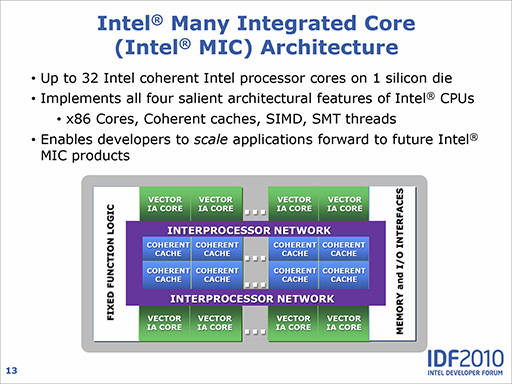
ちなみにこの頃からIntelは,アーキテクチャの名称として「Intel Many Integrated Core」(Intel MIC)を使い始めている。MICの読みは「マイク」だ。
 |
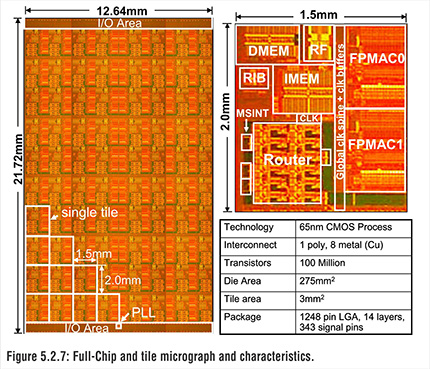
Larrabeeと比較すると,製造プロセスは引き続き45nmプロセスのままで,コア数だけが倍に増えたような印象を受ける。ただ,コアそのものはP54Cをベースにしつつも,64bit命令対応となった。
どうせ64bit対応なら,当時のAtomプロセッサに使われていたCPUコアである「Silverthorne」(開発コードネーム)にすればよさそうに思ったものだが,実現しなかったのは,コア部分のエリアサイズを抑えるためだろう。Silverthorneのエリアサイズは,1コアあたり24.4mm2なので,32コアもあると,それだけで780mm2を超える途轍もないサイズになるからだ。
 |
さて,このKnights Ferry,2010年9月には動作デモが披露となり,単精度浮動小数点演算で理論的には750GFLOPSという性能を発揮すると言われたものの,商品化は取りやめになってしまう。
それというのも,2009年11月,NVIDIAが発表したFermi世代のHPC向けGPUとなるTesla 20シリーズが,倍精度浮動小数点演算で500GFLOPS以上,単精度浮動小数点演算では1TFLOPSを超える性能を発揮していたからだ。出荷が1年以上遅れて単精度浮動小数点演算性能が750GFLOPS程度では,勝負にならない。
そこでIntelは,Knights Ferryを製品ではなく,「ソフトウェア開発用のプラットフォーム」であると位置づけ,次世代のMICアーキテクチャ製品を導入する予定の研究機関などに無償提供することにしたのだった。
最初の製品版Xeon Phiは2013年に市場投入
MICアーキテクチャの「製品」として初めて出荷されたのは,Larrabeeから数えて3世代めとなる,開発コードネーム「Knights Corner」(ナイツコーナー)こと初代Xeon Phiである。
2011年に開かれたISCでIntelは,Knights Cornerのチップや性能のデモを披露しているが,製品を発表したのは2012年のISCであった(関連記事)。Xeon Phiというブランド名が明らかになったのも,このタイミングだ。
 |
 |
 |
2012年6月に発表された,世界のスーパーコンピュータ性能ランキング「TOP500」では,Intelが試験的に社内で構築したKnights Corner搭載システムが150位に入った(関連リンク)。
また2012年11月には,テキサス大学の「Stampede」というシステムが,Xeon PhiとSandy Bridge世代の「Xeon E5-2680」,合計20万4900基のプロセッサコアを組み合わせ,2660TFLOPSの実効性能を記録して,TOP500の世界ランキング7位に入ったこともある。
正式発売前から,特定顧客に対しての出荷は順調に進んでいたようだ。
特定顧客向けの提供が一段落した2013年あたりから,「Xeon Phi 5110P」やXeon Phi 3120シリーズの正式な販売が始まる。それらよりも少し性能が向上したXeon Phi 7100シリーズも,2013〜2014年にかけて市場投入されることになった。
 |
先ほど,Knights Ferryとの主な違いは採用するプロセス技術だという話をしたが,実際,プロセッサの構造自体はKnights Ferryからそれほど変わっていない。各コアやメモリコントローラがリングバスでつながる構成で,コア自体はP54Cをベースとしたままだ。異なるのはL2キャッシュメモリ容量が256KBから512KBへ増量になったことと,GDDR5対応メモリコントローラの配置最適化によって,メモリアクセスの遅延が削減となったあたりか。
 |
第4世代Knights Landingでアーキテクチャを大きく変更
Knights Cornerの後継として,2016年から特定顧客向けの出荷が始まったのが,第4世代品となる,開発コードネーム「Knights Landing」(ナイツランディング)である。正式な発表は2014年のISCに合わせて行われたが,2013年のISCでIntelは部分的な情報を明らかにしていた。
 |
このKnights Landingでは,Larrabee由来のさまざまな特徴が,全面的に刷新された。それにより,Knights Landingの性能は,倍精度浮動小数点演算の場合で3TFLOPS以上,つまりKnights Corner世代と比べて3倍以上に達したというのがポイントだ。
具体的な特徴を列挙してみよう。
- CPUコアをP54Cから,Atomプロセッサで使われた「Silvermont」をベースにしたものに変更。2コアで1つのタイル(Tile)を構成する構造になった。また,Vector Unitをコアあたり2基搭載するようになった。ちなみに,1タイルあたり,容量1MBのL2キャッシュメモリを備えている
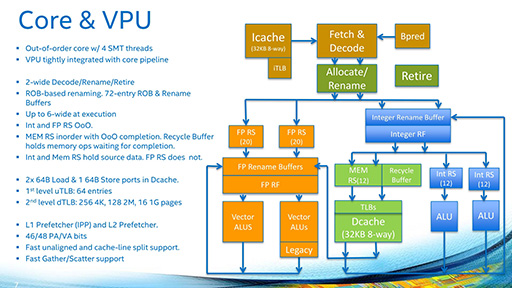 |
- 対応する命令セットが拡張され,TSX命令を除くCoreプロセッサの全命令に対応した。逆に,Knight Cornerまでの命令セット(LNI)には対応しないので,以前のプログラムを利用するには再コンパイルが必要
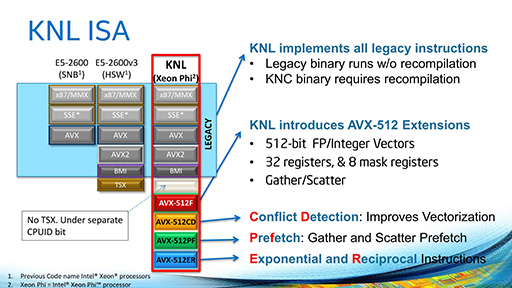 |
- タイル間の接続を,(NoCに似た)二次元メッシュ方式に変更
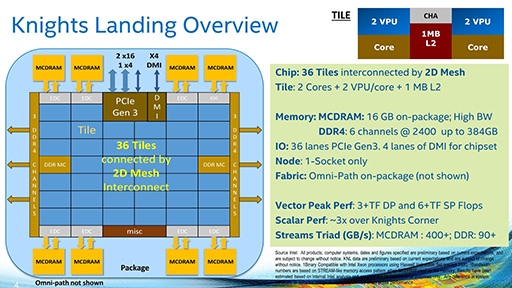 |
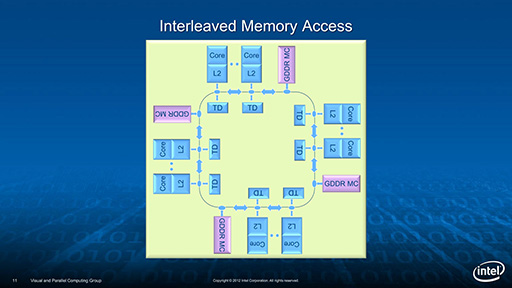
- メインメモリとして,パッケージ上に3D積層DRAM「MCDRAM」を8チップ搭載した。1チップあたりの容量は2GBで,総容量は16GB。MCDRAMのメモリバス帯域幅は未公開だが,チップあたり50GB/s前後,8つでトータル400GB/s程度と推定されている
- MCDRAMとは別に,DDR4メモリのインタフェースを6チャネル分搭載する。DDR4-2133〜2400に対応し,最大メモリ容量は384GB。メモリ帯域幅は100GB/s以上となる。MCDRAMとDDR4メモリは混在して使えるほか,MCDRAM側をDDR4メモリのキャッシュとして使うことも可能で,使い方はアプリケーション側から指定できる
- 外部インタフェースとして,DMIやPCI Expressに加え,「Intel Omni-Path Architecture」(以下,Omni-Path)にも対応
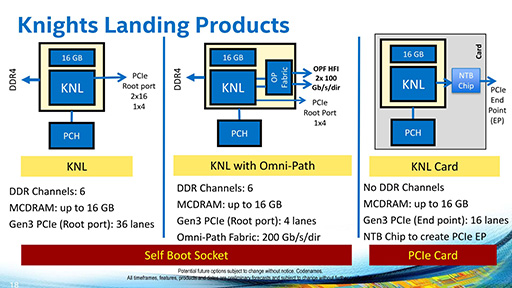 |
Knights Landingベースの製品は,Xeon Phi x200シリーズとしてラインナップされている。現在は,「Xeon Phi 7250」「Xeon Phi 7230」「Xeon Phi 7210」の3製品が出荷中。2016年内には,さらに5製品が追加で発売となる予定だ。
第5世代はKnights Hill? それともKnights Mill?
さらにIntelは,Knights Landingに続く第5世代――Xeon Phiとしては第3世代――の製品についても予告をしている。それが,10nmプロセス技術を利用して製造する予定の,開発コードネーム「Knights Hill」(ナイツヒル)だった(関連記事)。
ところが,2016年9月に行われたIDF 2016でKnights Hillの名前はなく,その代わりにIntelは,「Knights Mill」(ナイツミル)という新しい開発コードネームの製品を,2017年に発表すると予告したのだ。
 |
現時点では,Knights MillがKnights Hillのリネームなのか,それとも別のチップなのかは明らかになっていない。ただ,元々のKnighs HillはHPC向けだったのに対し,Knights Millは,「ディープラーニング向けにXeon Phiが利用され始めた」という基調講演の中で登場したのが,気になる部分だ。
この分野の場合,精度よりも演算性能が重要となる。NVIDIAがMaxwell世代のGPUから,ディープラーニング向けにFP16(半精度浮動小数点演算)をサポートしたのは,ディープラーニングにFP32(単精度浮動小数点演算)の精度は不要であり,FP32を1回実施する間にFP16を2回実施できるなら,そのほうが効果的だ,と判断したからだった。それを考えると,Knight MillにもFP16のサポートが追加されていそうではある。
重要なポイントとしては,Xeon PhiおよびSkylake世代のXeonでのみサポートされる512bit幅SIMD命令「AVX-512」(関連リンク)が,8bitや16bitの整数演算をサポートする一方でFP16をサポートしないことが挙げられる。AVX-512に対応するKnights Hillも,FP16はサポートしなかったはずだ。
これは推測になるが,Intelは現在,AVX-512にFP16を追加する作業を行っている最中で,これと並行して,Knights HillにFP16のサポートを追加実装しているのではないだろうか。要するに,
- Knights Hill+FP16のサポート = Knights Mill
となるのではないか,ということである。
もっとも,Knights HillにしてもKnights Millにしても,現時点で詳細は一切明らかになっていない。Intelから発表があったのは,以下の2点のみだ。
- 10nmプロセスを利用して製造される
- インタフェースに第2世代のOmni-Pathを採用する
Knights Hillは,米国のアルゴンヌ国立研究所(Argonne National Laboratory)が2018年に導入予定のシステム「Aurora」に採用されることが決まっている(関連記事)。
Auroraは最終的に,Knights Hillをベースにした5万基以上の計算ノードにより,理論上のピーク性能で180〜450PFLOPSを実現するという。仮に450PFLOPSを5万ノードで構築するとすると,1ノードあたりの処理性能は9TFLOPSになる計算で,Knights Cornerと比べて3倍ほどの性能になる。もっとも,1ノードあたりにいくつのKnights Hillを搭載するのかは分からないし,納入時にはKnights Millに変わるのかといったあたりも不明だ。
可能性だけで語るなら,現行製品と比べて1.5倍の演算性能,つまりKnights Hill 1基あたり4.5TFLOPS程度にして,これを1ノードに2基搭載する程度ならば,技術的難易度はそう高くはないと思われる。とはいえ,このあたりは最終的に製品が登場するまでは分からないのだが……。
IDF 2016の2か月ほど前,2016年7月に開催されたISC 2016では,Intelは登場したばかりのKnights Landingの説明に終始しており,Knights Hillの話はなかった。もちろん,Knights Millなんぞおくびにも出ていない。そんなわけで,Knights Hill/Knights Millの詳細がもう少し明らかになってくるのは,2017年6月に開催予定のISC 2017になると思われる。
ゲーマーにとってのXeon Phiは……まったく無縁な製品
Larrabeeから始まり,Knights Hill/Knights Millへと続くXeon Phiの概要は以上のとおり。さて問題は,これがゲーマーにとってどういう位置付けにあるのかだが……,はっきりいってXeon Phiは,ゲーマーにまったく無縁の代物である。それは,価格が高いからとか,一般消費者向けの製品がないからではない。
Xeon Phiのライバルとなるのは,AMDやNVIDIAのGPGPU製品だが,それらのアーキテクチャは,基本的にゲームグラフィックス用のGPUと同じで,構成が若干異なる程度である。だがXeon Phiは,ここまで説明したように,Larrabeeの頃はGPUを志向したアーキテクチャだったものの,途中からGPU的要素を切り捨てて,純粋に数値演算向けプロセッサへ特化した形になっている。
NVIDIAの数値演算アクセラレータ「Tesla P4」が,グラフィックス用の「GeForce GTX 1080」と同系統のコアを使っているのとは異なり,Xeon PhiはPC用CPUであるCoreプロセッサとは,まるで違うプロセッサなのだ。
「物理シミュレーション用のエンジンになら使えるかも……」と考える人がいるかもしれないが,これも可能性は皆無だろう。Intelは,2007年にゲーム向け物理エンジンの開発元であるHavokを買収したが,2015年には,これをMicrosoftに売却してしまっている。今後,Intel自身が物理エンジンを提供する可能性はまずないだろうし,サードパーティがXeon Phi向けに,物理エンジンを実装するという話もまったく聞かない。
そんなわけで,IntelのXeon Phiシリーズはゲームとは無縁のものであり,技術トレンドしての面白さはあるものの,ゲーマーがその動向に注目する必要はまったくない製品と断言して,本稿を締めくくらせていただきたい。
IntelのXeon Phi 製品情報ページ
- 関連タイトル:
 Xeon Phi
Xeon Phi - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー