















連載
西川善司の3DGE:AMD,次世代GPU「Vega」における4つの技術ポイントを公開。HBM2はキャッシュで使う!?
 |
2016年12月の報道関係者向けイベント,AMD TECH SUMMITで,AMDのGPU部門であるRadeon Technologies Groupを率いるRaja Koduri(ラジャ・コドゥリ)氏は,「Vegaには4つの新しい技術ポイントがある。今回はこれらについて解説することにしたい」と述べ,懐からVegaのサンプルチップパッケージを出して掲げたのだが,今回,機密保持契約の期限が来たことでお届けできるのは,これら4つの技術ポイントについてだ。
 |
 |
AMDの公式見解として,スペックも含めた,より詳細な情報は後日あらためて発表する,とのことだ。
Vegaは搭載するHBM2をキャッシュとして利用する!?
 |
AMDは2016年3月の時点でVegaがHBM2を採用することを明らかにしていたが(関連記事),Macri氏によると,VegaはそのHBM2を「High-Bandwidth Cache」(以下,HBC)として使うのだという。従来のSRAMに代わるキャッシュとして,HBM2を使うというわけだ。
 |
HBM(High Bandwidth Memory)を世界で初めて採用したしたGPUは,開発コードネーム「Fiji」(フィジー)ことRadeon R9 Furyシリーズである(関連記事)。メモリチップを高層ビルのように積み上げて(=スタックさせて)配置し,それを「TSV」(Through Silicon Via,シリコン貫通ビア)技術によって串刺しに貫通させて配線するメモリ実装技術で,省スペースかつ高帯域幅なメモリ性能を発揮できる新世代のメモリ技術だ。
 |
ちなみに,HBM2自体は,2016年4月にNVIDIAが発表したGPGPU向けプロセッサ「Tesla P100」が初採用である。
 HBM2は,同じ動作クロックで比較したとき,HBMに対して2倍のメモリバス帯域幅を持つ |
 同じメモリ容量を実現するのに,HBM2ならGDDR5比で基板上の専有面積を50%以上削減可能。また,HBMと比べて1スタックあたり8倍の容量を実現した |
では,HBM2をHBCとして採用するVegaのキャッシュメモリシステムは,SRAMを採用している従来型GPUのそれと何が違うのか。
「VegaではHBM2を採用した」。ここはいい。しかし「このHBM2をキャッシュメモリとして利用する」ということの意味がピンとこない読者も多いだろう。
AMDの解析によれば,PCゲームに代表される現在の主要なGPUアプリケーションでは,テクスチャや各種バッファなど向けに確保したメモリのうち,実際にレンダリングパイプラインが一周するまでに使われる容量はその半分程度に留まるという。
言い換えると,実際のレンダリング時に高速性が要求されるメモリアクセスは,確保した容量の半分で足りると言うわけだ。
 |
そこで採用したのが,「であれば,高速性が必要なメモリにHBM2を割り当てよう」という発想である。
「それ以外のデータ」用のメモリは,HBM2以外,それこそCPU側のメインメモリや,あるいはグラフィックスカード上に別途搭載するDDR3メモリでいいかもしれない。
ただ,この場合,キャッシュマネジメントを相当にうまくやらないと,レンダリング実行速度が遅くなってしまう。
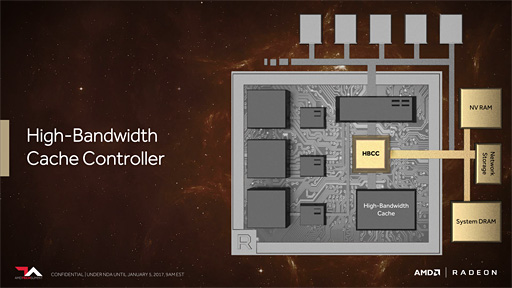
そこでVegaは,キャッシュ管理機構としての「High-Bandwidth Cache Controller」(以下,HBCC)を実装した。
HBCCの仕事は,大別して2つある。
1つは,GPUに直結されているHBM2以外のメモリに対するアクセス,より正確に言えば入出力マネジメントだ。
下のスライドを見てほしい。これを見ると,HBCCは,HBM2(=HBC)とは別に,「System DRAM」「Network Storage」「NV RAM」とつながっているのが分かる。System DRAMはPC側のシステムメモリ(≒メインメモリ)のことだが,面白いのはNetwork StorageとNV RAMだろう。Network Storageはネットワーク接続されたストレージ,NV RAMはNVIDIAとは無関係で(笑),電源を落としてもメモリの内容が消えない不揮発性メモリを指している。AMD側の認識としては,ここは単体SSDも含むようだ。
 |
HBCCが受け持つ仕事,もう1つは,「GPU(プログラム)に対する仮想アドレス空間の提供」である。
Vegaでは,実体としてのグラフィックスメモリがなくなり,HBM2が大容量キャッシュメモリとなったため,メモリアクセスにあたっては,GPUプログラム側が指定したアドレスを解釈して,HBM2にアクセスしたり,あるいは前述したようなHBM2以外の外部メモリへのアクセスを提供したりしなければならない。これらアドレス変換とメモリの入出力も,HBCCの仕事となる。
ここまでアーキテクチャが変わると既存のプログラムとの互換性が気になるかもしれないが,これは問題がない。GPUプログラム側が実行時に用いるアドレス空間はこれまでも仮想アドレスだったからだ。つまり,従来のGPUでもVegaでも,いずれにせよ仮想アドレスから物理アドレスへの変換を行ってアクセスしているので,俯瞰視点で見れば,アドレス解決の仕方とメモリ管理の仕方が変わったというだけなのだ。ワーストケースで実行速度に影響が出る可能性は否定できないものの,GPUプログラムの実行において,「GPUのメモリアーキテクチャが異なっていること」の影響を受けることはないはずである。
 |
今回の発表では,オンパッケージの搭載となるHBM2容量の発表はなかった。Koduri氏が掲げたチップパッケージを見る限り,メモリスタックは2つなので,総容量にして4GBもしくは8GBあたりといったところではなかろうか。
そう考える根拠は,GPGPU専用用途ではなく,PCゲーム用途を含めた民生用途を考えると,コストの高い8層式HBM2を採用するとは思えないためだ。そうなると2層式か4層式となり,2層式のHBM2は2スタックで4GB,4層式では2スタックで8GBとなる。
ちなみに,ピンあたり2Gbps仕様のものと仮定すると帯域幅は512GB/s(※256GB/sの2スタック)で,ハイエンドGPUとしてはそれっぽい値になる。なお,現在,量産提供中のHBM2については,SK Hynixが公開しているHBM2の仕様ページが参考になるはずである。
 |
新しいシェーダステージ「Primitive Shader」を導入
 |
GPUコアのアーキテクチャ面について説明したAMDのMike Mantor(マイク・メンター)氏によれば,NPGPにおいて,従来のGPに対して2つの改良ポイントがあるという。
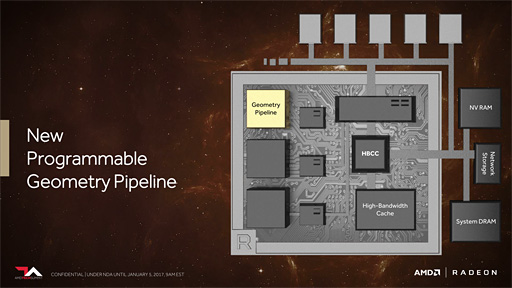 |
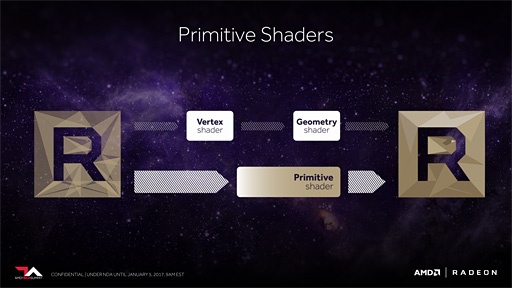
1つは,「Primitive Shader」(プリミティヴシェーダ)という新プログラマブルシェーダの導入である。
DirectX 10で登場したCompute Shader(コンピュートシェーダ)は,DirectX 11以降でとくに活用が進んだプログラマブルシェーダだが,近年では,これまでPixel Shader(ピクセルシェーダ,以下カタカナ表記)で行ってきたポストエフェクト処理やVertex Shader(頂点シェーダ,以下カタカナ表記)が行ってきた頂点パイプライン処理までをCompute Shaderで代行するような活用が始まっている。
Compute Shaderが便利なのは,あらゆるリソースに対し自在に読み書きできる点で,これは従来の頂点シェーダや「Geometry Shader」(ジオメトリシェーダ,以下カタカナ表記)にはない利点だ。
 |
具体的な活用事例やアプリケーション側からの活用手法については正式発表を待ってほしいとのことだが,Primitive Shaderを使うことで,NVIDIAが2015年6月に発表したVR向けの不均衡解像度レンダリング「Multi-Res Shading」のようなことも高効率で行えるようになる見込みだ。
 |
2つめは「Intelligent Workgroup Distributor」(以下,IWD)である。
初耳という読者もいるだろうが,実のところ筆者は,連載バックナンバーでIWDについて解説済みだったりする。どこでかというと,PlayStation 4 Pro(以下,PS4 Pro)のハードウェアについて解説した記事において,である(関連記事)。PS4のGPUには,Vegaの機能がいくつか先行実装されているのだが,その1つがこのIWD(相当の機能)だったのだ。
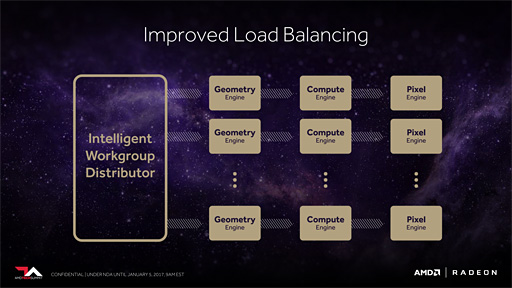 |
IWDは,いわぱ,ジオメトリエンジン側の機能強化にあたるもので,ジオメトリタスクを最も高効率で実行できるよう制御する仕組みとなる。
上でリンクを張ったPS4 Pro解説記事を執筆した時点だと,IWDについての情報提供がそれほど詳細でなかったことから,筆者は推測ベースで解説を試みたが,残念ながら,AMD TECH SUMMITのタイミングでもそれほど詳しい内容は出てこなかった。ただ,先の記事で推測したことはほぼ正解だったようである。
要約すれば,IWDは,スレッド発行先となるShader Engine(≒ミニGPU)の選択を,当該スレッドの実行をなるべく効率よく行えるよう適宜選択する。そのとき,レジスタファイルなどの有限リソースを最も効率よく使えるか否かを考慮し,さらにメモリアクセスがキャッシュアクセスで済むような配慮も行うらしい。
Compute UnitはFP16とINT8のPacked実行に対応
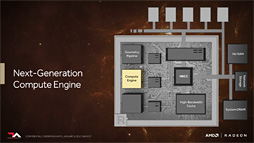 |
「Graphics Core Next」(以下,GCN)アーキテクチャを採用するGPUでは,1クロックあたり16個の32bit単浮動小数点(FP32)の積和算を行えるSIMD-16ベクトル演算器を4個ひとかたまりにして,これを1つの単位演算ユニットたるCompute Unitとして扱っている。ざっくり言えば,Compute Unit 1基で,1クロックあたり64個のFP32積和算(2 Ops)を実行できるということである。
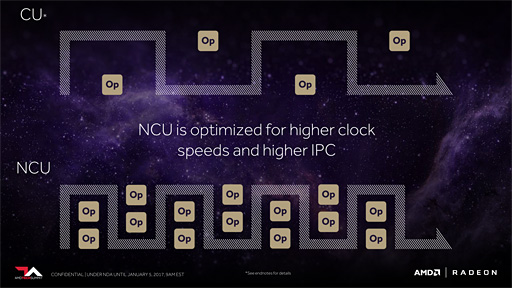
Vegaでは,ここが拡張となり,演算単位を16bit単位,もしくは8bit単位に細分化して行えるようになった。専門的にいえばPacked実行が可能になったということである。
 |
たとえば半精度浮動小数点(FP16)であれば,Compute Unitあたり128個の積和算を1クロックあたりに実行できようになったのだ。8bit整数(INT8)であれば,さらにその倍の256個となる。
 |
FP16やINT8はピクセルフォーマットで活用される傾向にあり,そうしたテーマの演算では,かなりの性能向上を期待できることになる。
なお,倍精度64bit浮動小数点(FP64)に対しては,製品種別ごとにコンフィギュレーションが可能だとのこと。GPGPU専用のVegaであればFP64性能を高く設定しての製品化を行ったりできるということなのだろう。
なおAMDは,今回のVegaで仕様拡張されたCompute Unitを「Next-Generation New Compute Unit」(以下,NCU)と呼んでいる。
 |
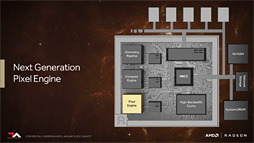
Pixel Engineの改良
Vegaにおける技術ポイント,4つめはPixel Engine(≒ピクセルシェーダ)の改良だ。具体的には,「描画結果の書き込みにまつわる最適化」に関するものになる。
 |
しかし,視点から見て3D的に奥のオブジェクトは,せっかくピクセルシェーダを起動して計算して書き込んでも,それより手前にあるオブジェクトによって上書きされてしまう。つまり,上書きされた領域は,視点から見えなくなるので,その箇所の描画に要したピクセルシェーダの演算コストは「骨折り損」ということになる。
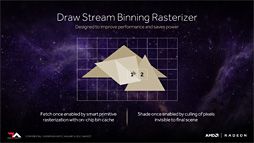 |
どういう拡張かといえば,ラスタライザに専用キャッシュを与え,「上書きされる見込みのピクセルかどうか」をこの段階で判断し,上書きされる見込みならば後段でピクセルシェーダの起動を行わないよう抑制する制御を行う。AMDはこれに「Draw Stream Binning Rasterizer」(ドローストリームビニングラスタライザ)という呼び名を与えている。
詳しい動作メカニズムは明らかにされなかったが,おそらくImagination Technologies製GPU IPコアである「PowerVR」のような振る舞いをするものと思われる。
つまり,ラスタライザ専用キャッシュというのは,ある程度の大きさ(=タイルサイズ)のZバッファ的なもので,ラスタライズ時に,すぐにはピクセルシェーダを起動せず,一定量のポリゴンをラスタライズしてから,このキャッシュ内でZテストを行い,これをパスしたピクセルについてのみピクセルシェーダを起動するのだ。
Pixel Engineのキャッシュ関連だともう1つ,ユニークなアーキテクチャ改変が入っている。「キャッシュメモリの階層構造」が変わっているのだ。
従来のRadeonだと,Pixel Engine(=ピクセルシェーダ)の書き込んだピクセルデータはRender Back-End(レンダーバックエンド,以下カタカナ表記)経由でメモリコントローラを介してメモリに出力する流れになっていた。
文章で書くと当たり前なのだが,ポイントは,ピクセルシェーダが書き込んだデータがL2キャッシュには載らないということだ。なので,次のパスのレンダリングで,「いま書き込んだデータ」を読み出すときには,グラフィックスメモリからの読み出しになってしまう。同じ領域を反復的に読んだ場合はキャッシュに載るので,そのキャッシュヒットは期待できるが。
 |
「一度描画したものを次のパスですぐに参照する」ということ自体は,近代ゲームグラフィックスではありふれている。たとえば,一度,プレイヤーキャラクターの周囲を環境マップテクスチャとしてレンダリングし,これを次のパスのレンダリングでテクスチャマッピングすることで映り込み表現を行うというのは,代表的な事例だと言えるだろう。
あるいは,「Unreal Engine 4」をはじめとする近代ゲームエンジンが採用するDeferred Rendering(ディファードレンダリング)法なら,描画する対象を直接描画することなく,まずは一度,中間パラメータを画面座標系でレンダリングして,それを後段のシェーディングフェーズで参照し,材質ごとの陰影の出方を計算して解決していくわけだが,まさにこれも「レンダリングしたものをすぐ後段で活用する」事例の1つだと言える。
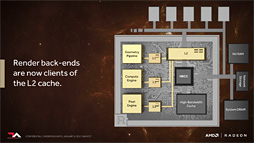 |
こうすることで,いま述べたような事例において,直前のレンダリングで出力したデータが高確率でキャッシュに載るようになり,実メモリアクセス量が減り,性能向上を期待できるようになる。
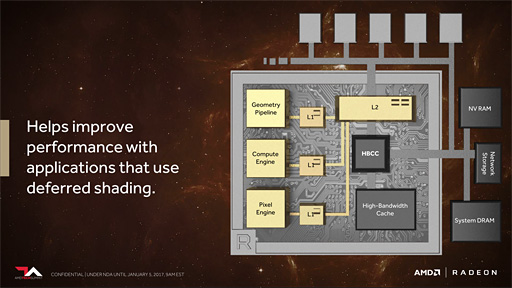 |
ただ,ピクセルシェーダからの描き出しデータ量は得てして膨大になるため,すべてのデータをL2キャッシュに載せてしまうと,本来ならばもっと長時間キャッシュに載っていて欲しいデータがキャッシュから追い出されてしまう可能性がある。
これについては,そうならないよう,HBCCが賢い制御を行うということなのだろう。
SSD搭載Radeon ProはVegaベースであることも判明。で,Vegaの絶対性能は?
今回の先行技術説明会を通じて,まだまだ予告段階という印象は拭えなかったが,それでもキーポイントとなる技術についての説明は一通り入ったと言っていいのではなかろうか。
個人的には,グラフィックスメモリを丸ごとHBM2化したうえで,これをシステムアーキテクチャ上はキャッシュメモリとしてしまう発想はなかなか面白いと感じた。
GPUから見て,システムメインメモリはもちろん,SSDやネットワークストレージすらGPUメモリとして透過的に取り扱えるという発想は,地味ながらも革新的な発明だ。というか,これから主流になるであろう,CPUとGPUの統合型コンピューティングアーキテクチャにおいて,必要不可欠になってくるアイデアだともいえるかもしれない。
そして次期APUが,今回のメモリアーキテクチャ革新を採用する確率も高いはずだ。
 |
AMD TECH SUMMITのデモルームでは,このRadeon Pro SSGを用い,リビングルームの3Dシーンをリアルタイムにレイトレーシングするデモが公開された。
このデモ,リアルタイムレイトレーシングとは言いつつも,シーン内の空間に伝搬する光の情報はすべて事前に計算済みで,その結果をRadeon Pro SSG上のSSDに記録しておき,ランタイムでは,SSDからその大局照明情報を読み出して適用しているだけなのだ。いわば,この3Dシーン内のオブジェクト界面上にやってくる全方位の光の情報を事前計算しているということである。言い換えれば,膨大な地点数の全方位環境マップデータを事前計算して持っているということである。
その事前計算済みの光の伝搬情報は,トータルで20GB以上にもなるそうだ。
 事前計算しておいた巨大な大局照明データをRadeon Pro SSGのSSDに格納し,そのデータを利用して高速に大局照明付きのシーン描画を行うデモ |
 デモを実演する原田隆宏氏(Senior Member of Technical Staff, AMD)。AMD製GPUレイトレーシングエンジン「Radeon Pro Render」は,氏が中心になって開発を進めている |
ここまで巨大になると,CPU管理下のシステムメインメモリ側に置いておくこともままならないいほどのビッグデータなわけだが,Radeon Pro SSGの仕組みであれば,GPUは,その瞬間のレンダリングに必要な分だけのデータを読み出し,それを適切にキャッシュしていくことで,インタラクティブレベルのレンダリングを実現しているのである。
さて,読者が一番に気になっているのは,そんなVegaの絶対性能ではないだろうか。
昨年は,ハイエンドGPUクラスにおいてはGeForce GTX 10シリーズ一強状態が続いただけに,2017年は,Vegaを武器としたAMDの巻き返しが期待される。
AMDは今回,性能面に関する言及を避けていたが,正式発表時には,もちろんそうした情報も明らかになるはずだ。
今からX-DAYを心待ちにしたい。
 |
AMD公式Webサイト
- 関連タイトル:
 Radeon RX Vega
Radeon RX Vega - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー