














レビュー
レビュー後編。基礎検証と消費電力&温度測定でその特性を掘り下げる
Core i9-7900X
Core i7-7740X
 |
4Gamerでは,「Skylake-X」コア採用の10コア20スレッド対応モデル「Core i9-7900X」(以下,i9-7900X)と,「Kaby Lake-X」コア採用の4コア8スレッド対応モデルである「Core i7-7740X」(以下,i7-7740X)について,ゲームをはじめとする一般アプリケーションにおける性能と消費電力評価をすでに行っているわけだが(関連記事),レビュー後編となる今回は,両製品の特性を少し掘り下げてみることにしよう。
 |
 |
置き換え対象となるBroadwell-E世代のCore i7や,現行の主力製品となるKaby Lake-S世代のCore i7,そして競合のRyzen 7と何が違うのか,いくつかのテストを通じて見ていきたい。
「Core i9-7900X」「Core i7-7740X」レビュー前編。10コアのSkylake-Xと4コアのKaby Lake-Xは誰のためのものか
キャッシュ構成の変更に加えSkylake-XではAVX-512をサポート
テスト結果の確認に先立って,CPUの特性に影響を与えそうなアーキテクチャ上の変更点を簡単に押さえておこう。まずはi9-7900Xからだ。
 |
 |
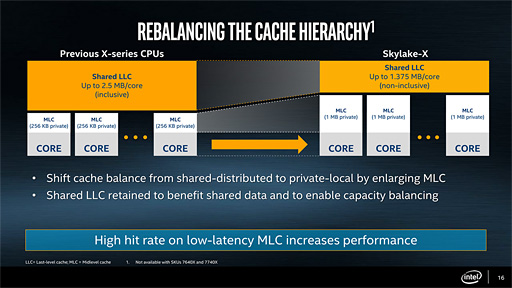
そんなSkylake-Xは,既存のSkylakeマイクロアーキテクチャをベースにしているが,2つ,大きく異なる点がある。1つはレビュー前編でも触れたキャッシュ構成だ。
Skylake世代では,CPUコアごとに容量256KBのL2キャッシュを持ち,全CPUコア(と統合型グラフィックス機能)で共有するL3キャッシュも持っていた。一方,今回のSkylake-XではCPUコアごとのL2キャッシュ容量が1MBへと増強を果たしている。
ただ,Broadwell-Eとの間で採用する製造プロセス技術に大きな違いはない。厳密に言えば,Broadwell-Eは第1世代の14nmプロセス,Skylake-Xは第2世代の14nm+プロセスを採用しているが,その程度だ。
コスト的な理由からダイサイズを拡大を避けたかったからなのか,L2キャッシュの容量引き上げに伴ってL3キャッシュ容量は減らされている。具体的には,i7-6950Xの25MBに対してi9-7900Xでは13.5MBと,約54%になった。L2+L3キャッシュの総容量も,i7-6950Xの27.5MBに対してi9-7900Xは23.5MBと約85%に減ってしまった計算だ。
 |
Intelはこれを「キャッシュ階層のリバランス」(Rebalancing the cache hierarchy)とアピールしているが,リバランス(rebalance,再均衡)の結果として何が良くなるのかについてはほとんど語っていない。
単純に考えるなら,CPUコアごとのローカルメモリにあたる低レイテンシのL2キャッシュ容量が大きければ,Intelが「メガタスキング(Mega Tasking)」と呼ぶ,複数のタスクを同時に実行するような用途で有利になることが考えられる。その典型的な例が,レビュー前編で試みた,ゲームをしながらのエンコードといったような用途だろう。
いずれにしても,キャッシュ階層のリバランスがどんな違いをもたらすのかは,以降のテストでチェックすべきポイントということになる。
 |
キャッシュ階層のリバランスと同時に,IntelがSkylake-Xの内部バスへ大きく手を入れていることも,押さえておきたいポイントだ。
IntelのCPUは,L1およびL2キャッシュを含むCPUコアと,「LLC」(Last Lebel Cache)と呼ばれるL3キャッシュ,そしてメモリインタフェースなどを含むアンコア(Uncore)部を,リング状の高速バス,いわゆるリングバス(Ring Bus)で接続する仕様を長らく採用してきた。
ただ,CPUコア数が増えるとリングバスでは対応しづらくなる。たとえば,Broadwell-E世代のCPUだと,多数のCPUコア同士を十分な帯域幅で接続する必要から,リングバスを内部で二重化したのだが,結果としてLLCやメモリインタフェースとコアの対称性を崩してしまい,多コアモデルにおいて内部のアクセス遅延が大きくなるという欠点を抱えるに至っている。
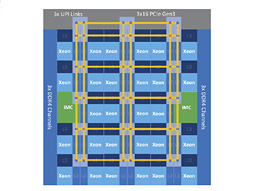 |
右の画像はXeon Scalable ProcessorにおけるMesh Interconnectのイメージだが,L3キャッシュを含むCPUコアがメッシュ状の二重バスでつながっているのが分かる。これにより,リングバスに見られた「多コア構成時の非対称性」を解消でき,結果としてアクセス遅延が大幅に低下するというのが,Intelの主張だ。
ちなみにi9-7900Xの場合,Mesh Interconnectの動作クロックは4GHz。Broadwell-E世代のi7-6950Xだとリングバスのクロックは3.0GHzだったので,動作クロック引き上げとアクセス遅延低減により,性能の大幅な向上を期待できる。
 |
AVX-512は,数値演算向けのアクセラレータ「Xeon Phi x200」(開発コードネーム「Knights Landing」)で初めてサポートされた命令セットで,新設の512bitレジスタ「ZMM」を使ってSIMD演算を行うものとなっている。
AVX-512にはいくつかのレベルがあるのだが,Skylake-Xがサポートするのは,512bit長レジスタを使って64/32bit長浮動小数点数のSIMD演算を行う「AVX-512/F」と,64bit長整数のSIMD演算を行う「AVX-512/DQ」の2つだ。
従来のAVX-2に比べ2倍の長さのレジスタを使って,2倍のSIMD演算を行うことができるため,AVX-512を使った演算はAVX-2比で2倍のスループットが得られる理屈である。
もっとも,Xeon Phiシリーズ以外でAVX-512をサポートするのは今回のSkylake-Xが初である。なので,「AVX-512を使う一般向けのアプリケーション」は現状,ほとんどない。今後,アプリケーションが増えてくればAVX-512の恩恵が受けられるようになるはずだが,今のところ使い道はほぼないという理解で間違いないだろう。
 |
なお,命令セットのサポートはKaby Lake-Sと変わらずAVX-2止まりなので,こちらは新しい命令セットの恩恵を受けられない。
目を引くのは,TDP(Thermal Design Power,熱設計消費電力)が,Kaby Lake-S世代の「Core i7-7700K」(以下,i7-7700K)の91Wから,Kaby Lake-Xベースのi7-7740Xで112Wと約23%も増大している点だ。動作クロックはi7-7700Kが定格4.2GHz,i7-7740Xが定格4.3GHz(最大クロックは両者ともに4.5GHz)と,定格ではわずかに後者のほうが高いのだが,少なくともTDPの増大に見合う性能向上が得られているわけではないということは,レビュー前編で明らかになっているとおりだ。
では細かく特性を見ていけば何か違うのか,というのが,今回チェックすべきポイントということになるだろう。
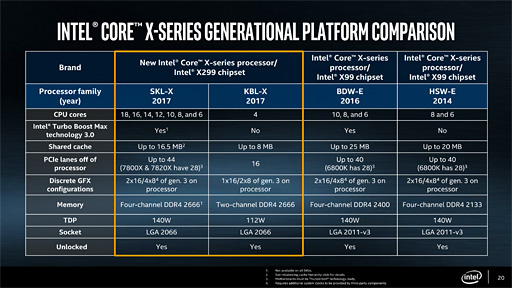
Skylake-XやKaby Lake-Xは「Basin Falls」(ベイスンフォールズ)という開発コードネームで呼ばれてきたHEDTプラットフォームを構成するCPUだが,その対応チップセットは新登場の「Intel X299」(以下,X299)である。
前世代にあたる「Intel X99」だとチップセット側のPCI Express(以下,PCIe)はGen.2だったが,X299では最大24レーンのPCIe Gen.3を備えることができるようになった。さらに,X299マザーボードでは仮想RAID技術「Intel VROC」(VROC:Virtual RAID On CPU)に対応しており,PCIe Gen.3 x4接続のSSDを複数用意することで,OSのブートが可能なRAIDアレイを構築できるようになっている。総じて,PCIe周りの強化を果たしたチップセットという理解でいいだろう。
 |
 |
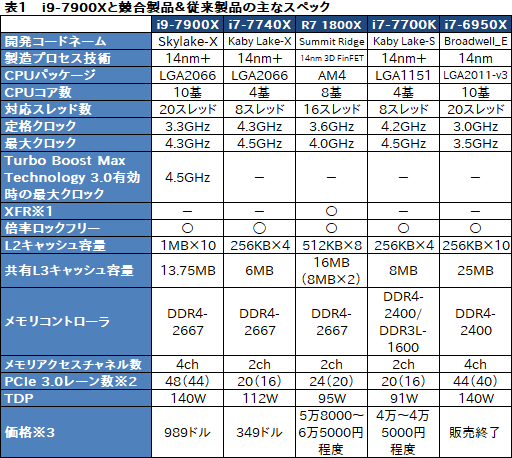
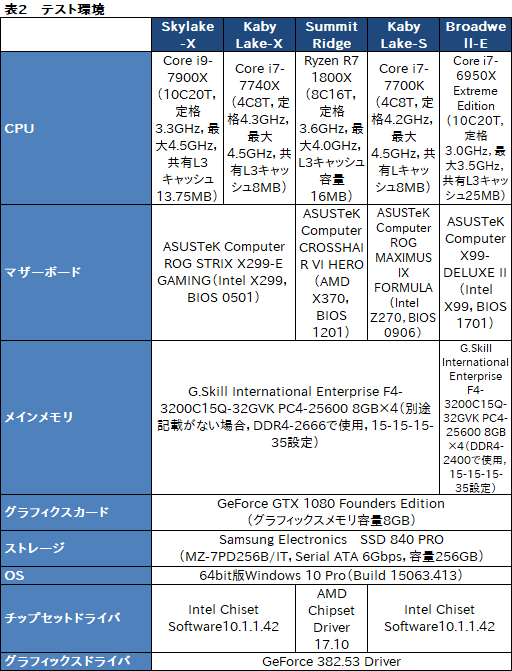
下に示した表1は,レビュー前編でも示した各製品の主なスペックとなる。以下,スペースの都合で,表内,グラフ内に限り,Ryzen 7は「R7」と略するので,この点はご了承を。
 |
テスト機材の一部を変更
テスト結果を見ていく前に,今回のテスト環境について触れておきたい。というのも,前編からメモリモジュールと「Intel X99」(以下,X99)マザーボードを交換したためである。
それはなぜかだが,後編分のテストを始めた時点で,前編で使ったX99マザーボード「ROG STRIX X99 GAMING」がトラブルに見舞われたためである。ただし,トラブルが発生した時点では問題の所在がマザーボードにあるのかメモリモジュールにあるのか分からなかったため,ひとまずメモリモジュールをG.Skill International Enterprise製のPC4-25600,容量8GBモジュール4枚セット「F4-3200C15Q-32GVK」に変更してしまった。ちなみにF4-3200C15Q-32GVKのスペックは前編で使った「F4-3200C15Q-32GTZSW」と同じで,前世代モデルに当たる。
結果的にメモリモジュール側は何の問題もなく,マザーボードだけをASUSTeK Computer(以下,ASUS)製の「X99-DELUXE II」へ変更することで事態は解決を見た。しかし行きがかり上,後編ではすべてのテストをF4-3200C15Q-32GVKで行うことになったという経緯である。
というわけで,今回のテスト環境は表2のとおりだ。X99マザーボードとメモリモジュールが変わった以外は,Windowsのビルドも含めて変更はない。
 |
古典的なベンチマーク「AIDA64」で基本性能をチェック
さて,ようやくテストだが,まずはFinalWare製のシステムチェック&ベンチマークツール「AIDA64」(Version 5.92.4300)を使って,i9-7900Xとi7-7740Xの基本性能をチェックしていくことにしよう。
AIDA64ではバージョン5.92からSkylake-Xのサポートが入っているが,ベンチマーク部でAVX-512の採用が始まったなどといった,特別な「Skylake-X向け最適化」が入っているわけではない。また,Kaby Lake-X対応は謳われていなかったりもする。
AIDA64が採用する命令セットは古典的なx86およびx87命令やSSE,AVX,AVX-2止まりなので,従来型CPUとしての速度を比較することができるわけだ。
というわけで以下しばらくは,常用環境を想定したテストの結果を見ていきたい。常用環境が前提なので,Intel製CPUでは「Enhanced Intel SpeedStep Technology」(以下,EIST)および「Intel Turbo Boost Technology 2.0」を有効化。また,i9-7900Xでは「Intel Turbo Boost Max Technology 3.0」(以下,TBMax3)も有効化する。
同様にRyzen 7 1800Xでも自動クロックアップ機能にあたる「Precision Boost」および「XFR」を有効化してテストを行うことになる。
なお,メモリアクセス設定はDDR4-2667を基本としたが,i7-6950Xのみ同設定ではシステムが起動しなかったためDDR4-2400設定にしている。
記憶力のいい読者だと,レビュー前編でi7-6950Xのメモリ設定がDDR4-2133だったことを憶えているかもしれないが,マザーボードを交換したことで無事にDDR4-2400でアクセスできるようになったため,今回は無事,スペックどおりのメモリ仕様となっているので,この点はご注意を。
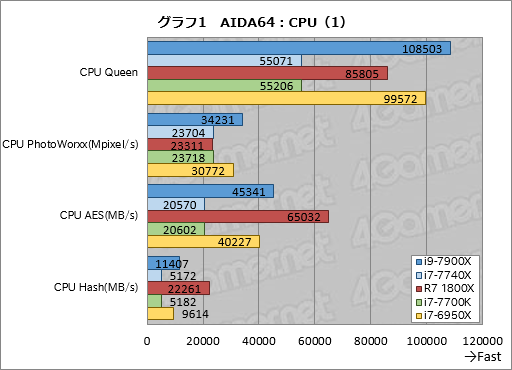
さて,グラフ1,2は,AIDA64のベンチマークから,主に整数演算主体のテスト結果を抜き出してまとめたものだ。グラフ2だけ分けたのは見やすくするためで,他意はない。本稿では今後も,見やすくするためにグラフをいくつか分けることがあるので,その点はあらかじめお断りしておきたい。
 |
 |
「CPU Queen」は古典的なNクイーン問題(N-Queens Problem,n×nの碁盤目状となるボードに,縦横斜めに移動できるチェスのクイーンをn個置くとして,互いに攻撃できないよう配置するパターンがいくつあるか)を解くテストで,AVXおよびAVX2の整数演算を使うことになる。
Nクイーン問題では分岐が多発するため,分岐予測の性能もスコアに影響すると言われるが,i9-7900Xは前世代にあたるi7-6950Xに対して約109%と,クロック比に満たないスコアの向上しか得られていないのが分かる。AVXやAVX2の整数演算性能でSkylake-Xがこれといった改善を見ていないことを窺わせるスコアだが,これはLGA1151向けのSkylakeでも見られた傾向なので,不思議ではないとも言える。
一方,i7-7740Xのスコアはi7-7700Kのスコアと,誤差範囲で一致している。同じKaby Lake系で,少なくとも演算エンジン部分は変わっていないということだろう。
比較対象として用意したRyzen 7 1800Xは4コア8スレッドのi7-7700Kに対して約1.55倍のスコアをマークした。1コアあたりの性能は低めだが,総合的にはまずまずと言っていいのではなかろうか。
続く「CPU PhotoWorxx」は整数演算を使った写真の加工処理を行うもので,AVXやAVX2,SSEといったSIMD演算を多用するテストだ。ここでi9-7900XのスコアはN Queenとさほど変わらず7-6950Xに対して約111%。i7-7740Xのスコアはi7-7700Kのそれとほぼ誤差範囲で一致した。
CPU PhotoWorxxの結果で興味深いのはRyzen 7 1800Xのスコアで,4コアのi7-7700Kとほぼ同じ,厳密に言えば約1%低いスコアに留まった。CPU Queenの結果から見て,命令のスループットが云々というより,Ryzen 7 1800Xが苦手とするコードに遭遇したのだろう。
ちなみに,AIDA64はバージョン5.92からRyzen 7対応も果たしているはずなのだが,CPU PhotoWorxxは最適化されていないようだ。
「CPU AES」はAES暗号化を行うテスト,「CPU Hash」はハッシュ値を求めるテストである。前者ではAES-NI命令を,また後者ではSHA命令をそれぞれ使うので,つまり今日(こんにち)のCPUが持つハードウェアアクセラレーションを使うテストということになる。
ここでi9-7900Xは前世代のi7-6950Xに対してCPU AESで約113%,CPU Hashで約119%のスコアをマークした。クロック比からまずまず妥当と言ってよく,AES-NIやSHAそのものの性能は変わっていないとも言えそうである。
i7-7740Xはi7-7700Kのスコアとほぼ誤差範囲で一致と,ここまでと変わらない結果になった。
両テストで興味深いのは,またしてもRyzen 7 1800Xで。CPU AESでは10コアのi9-7900Xに対して約143%,CPU Hashに至っては約231%と,圧倒的なスコアを叩き出している。Ryzen 7 1800XのAES-NIやSHAは十分に高速という結果がこれまでも出ていたが(関連記事),ここまで競合を“千切る”結果を見たのは筆者にとって初めてだ。正直,理由はよく分からない。
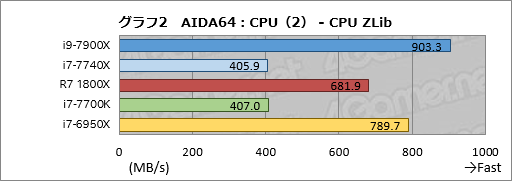
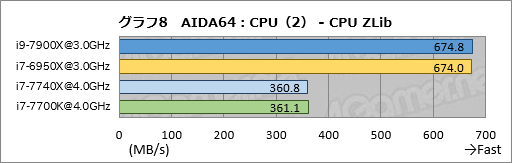
古典的なx86命令のみを使ってデータの圧縮・展開を行う「CPU ZLib」だと,i9-7900Xはi7-6950Xに対して約114%,i7-7740Xのスコアはi7-7700Kと誤差範囲で一致という,ここまでと変わらない結果になった。古典的なx86命令の処理にあたって,クロック比以上の性能向上は見られないと断言していいだろう。
Ryzen 7 1800Xは4コアのi7-7700Kに対して1.68倍のスコアをマークした。コア数およびクロック差から考えてまずまず妥当と言えるレベルだ。
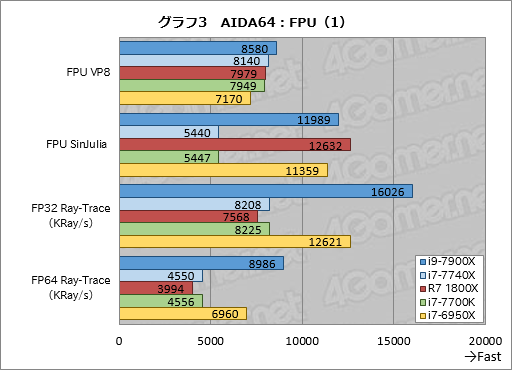
続いてグラフ3,4はAIDA64から浮動小数点演算を使うテストの結果をまとめたものとなる。
 |
 |
「FPU VP8」はVP8形式のエンコードを実行するテストで,SSEを使った32bit単精度のSIMD演算を多用するというが,結果は驚くことに横並びに近く,10コア,8コア,4コアによるスコア差はないどころか,i9-7900Xがトップに立っている一方,i7-6950Xが最下位に沈むという,よく分からないものになっている。マルチスレッド処理に最適化されているはずなのだが……。
このスコアを何かの参考にするのは避けたほうがよさそうだ。
「FPU SinJulia」は,古典的なx87命令セットを使い,IEEE標準の80bit拡張精度浮動小数点演算でジュリア集合(Julia set,複素平面上である条件を満たす点の集合のこと)を計算するテストだ。
i9-7900Xは前世代のi7-6950Xに対して約105%と,インパクトのないスコアしか記録できていない。i7-7740Xのスコアがi7-7700Kとほぼ一致した結果なのは,そろそろ見慣れてきた頃だろうか。
ここでも突出しているのはRyzen 7 1800Xで,10コアのi9-7900Xに対して8コアながら約5%高い。最近だと,80bit拡張精度浮動小数点演算は科学技術計算の一部で使われる程度になってしまったが,Ryzenはもしかするとそこでかなり高い性能を発揮できるのかもしれない。
「FP32 Ray-Trace」は32bit単精度浮動小数点演算を使ってレイトレーシングを実行するベンチマークで,AVX系のSIMD演算やFMA命令を使用するものとなっている。
このテストでi9-7900Xはi7-6950Xに対して約27%高いスコアを示した。ここまでと比べるとスコアの開きは大きい。理由については後段で考えるとして,ひとまずは「どうやらAVXの浮動小数点演算やFMAを多用するアプリケーションだとSkylake-XがBroadwell-Eより有利かもしれない」くらいのことを押さえておいてほしい。
i7-7740Xのスコアがi7-7700Kとほぼ一致するのはここでも同じだ。
Ryzen 7 1800Xは,4コアのi7-7700Kに対して約92%のスコアに留まった。レイトレーシングはマルチスレッドが効果的で,Ryzenを含めてマルチコアが活かせる処理である。なので,Ryzen 7のスコアが低いのは,レイトレーシング自体というより,AIDA64におけるレイトレーシングの実装に何かしらRyzen 7の足を引っ張る部分があるからということなのかもしれない。
64bit倍精度浮動小数点演算のレイトレーシングを行う「FP64 Ray-Trace」でも,i9-7900Xはi7-6950Xに対して約29%高いスコアを示した。i7-7740Xのスコアはi7-7700Kとここでもほぼ一致する。
Ryzen 7 1800XはFP32 Ray-Traceよりもさらに成績が悪く,i7-7700Kに対し約88%に沈んだ。Ryzenはテストごとの“出入り”が激しい。
「FPU Julia」はジュリア集合の32bit単精度版で,SIMD演算やFMAを使うものとなっているが,i9-7900Xのスコアがi7-6950Xのそれの約123%。SIMD演算やFMAを交えるとi9-7900Xがやや有利になる傾向がここでも見られた。一方で,i7-7740Xのスコアはi7-7700Kとここでもほぼ一致している。
Ryzen 7 1800Xのスコアが4コアのi7-7700Kとほぼ一致した点も注目したい。8コアCPUとしてはやや残念な結果で,SIMD演算やFMAを交えるとRyzenはやや不利になるのかもしれない。
「FPU Mandel」は64bit倍精度浮動小数点演算でマンデルブロ集合(Mandelbrot set,ジュリア集合と同様に複素平面上である条件を満たす点の集合のこと)を実行するテストである。SIMD演算やFMAを多用するテストとされるが,それゆえ傾向としてはRay-Trace系やJuliaに近く,i9-7900Xのスコアがi7-6950Xのそれに対して約24%高い一方,Ryzen 7 1800Xは4コアのi7-7700Kよりも低くなった。
i7-7740Xとi7-7700Kがほぼ同じスコアなのはここでも同じだ。
続いてメモリ性能の検証に移ろう。前述のとおり,メモリアクセス設定はi7-6950Xを除いて揃えている。
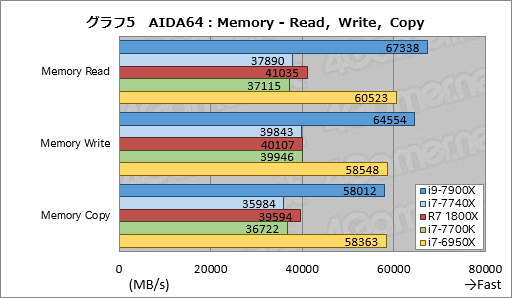
グラフ5は「Memory Read」「Memory Write」「Memory Copy」という3つのテストにおけるスコアをまとめたものだ。
Memory Readではi9-7900Xのスコアがi7-6950Xの約111%,Memory Writeでは約110%と,メモリクロックの引き上げに見合う数字が出ている。しかし,Memory Copyだけはi7-6950Xとほぼ揃ってしまった。
デュアルチャネルメモリアクセスとなるi7-7740Xのスコアはi7-7700Kに対してMemoryにMemory Readで約2%高く,Memory Writeで約2%低く,Memory Copyで一致と理屈に合う結果になっているが,総合的にはほぼ互角と見ていいだろう。
健闘しているのはRyzen 7 1800Xで,同じデュアルチャネルメモリアクセスのi7-7700Kに対してMemory Readで約111%,Memory Writeで約100%,Memory Copyで約108%というスコアを示した。メモリ設定が揃っていることを考えるに,最大で10%以上ものスコア差が出ているのは立派だ。
 |
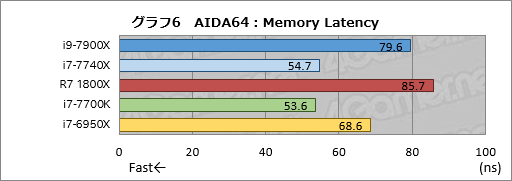
同じAIDA 64のメモリテストから,「Memory Latency」の結果をまとめたものがグラフ6となる。
まずi7-7740Xとi7-7700Kはほぼ同じスコアと言っていいが,厳密に言えばi7-7700Kのほうが約1ns速い。デュアルチャネルメモリアクセス勢で最もスコアが悪かったのは約86nsのRyzen 7 1800Xで,これは今回テストした中で最も悪い数字だ。AMDも「DDR4 SDRAMの扱いではIntelに一日の長がある」と認めているくらいなので,ここはやむを得ないだろう。ポジティブに見れば,Ryzenのメモリコントローラにはまだまだ最適化の余地があるということになる。
クアッドチャネルアクセスとなる2製品で比較した場合,i7-6950Xだと約69nsのところがi9-7900Xは約80nsなので,遅延状況は約10ns悪化してしまった計算だ。アクセス設定は揃えているので,メモリクロックの引き上げ分だけ遅延がやや悪化しているようである。
前出のMemory Copyでi9-7900Xのスコアがi7-6950Xと同程度に留まったのは,Memory Copyでメモリ読み出しに伴う遅延の影響が大きくなるためなのだろう。
 |
以上,常用環境を前提としてスコアを並べてみたが,i9-7900Xとi7-7740Xのクロックあたりの性能が従来製品と比べてどう異なるかは少々分かりにくい。そこで,i9-7900Xとi7-6950XではEISTとTurbo Boostを無効化し,さらにi9-7900XではTBMax3も無効化のうえで全コアの動作クロックを3.0GHzで揃えた状態,i7-7740Xとi70-7700KではEISTとTurbo Boostを無効化のうえで全コアの動作クロックを4.0GHzに揃えた状態でもAIDA64を実行することにした。ここではIntel製CPUの比較が目的なので,Ryzen 7 1800Xは省いている。
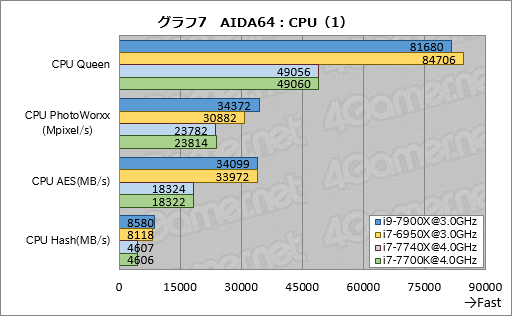
順番に見ていこう。グラフ7,8はAIDA64における整数演算ベンチマークの結果をまとめたものだ。CPU Queenではi9-7900Xのスコアがi7-6950Xに対して約96%に留まっており,有意に低い。逆に,CPU PhotoWorxxではi9-7900Xのスコアがi7-6950Xのそれに対して約11%高かった。
一方,そのほかのテスト項目ではスコアがおおよそ一致している。以上からAVXやAVX2の整数演算性能面で,i9-7900Xのクロックあたり性能は前世代と大して変わってない可能性が高い。
なお,i7-7740Xとi7-7700Kはすべてのテストでほぼ一致したスコアになった。
 |
 |
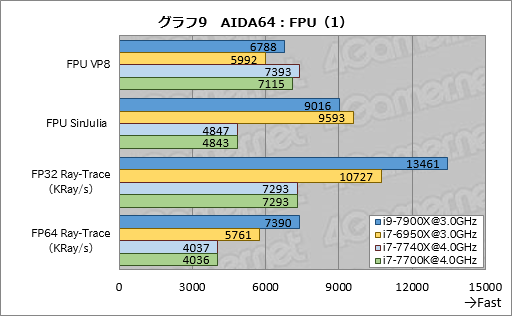
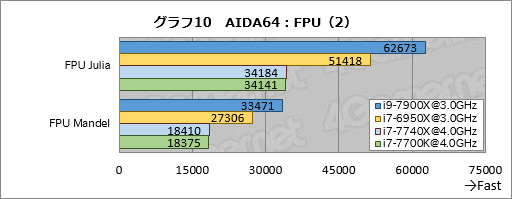
グラフ9,10はAIDA64における浮動小数点演算ベンチマークの結果をまとめたものとなる。
グラフ3,4で触れたように,FPU VP8のスコアは参考にならないので,それ以外を見ていくことになるが,スコア面で唯一の例外はFPU SinJuliaだ。ここでi9-7900Xのスコアはi7-6950Xの約94%に落ち込んだ。前述のとおり,FPU SinJuliaは古いx87命令セットを使うが,そんなx87命令を前にするとSkylake-Xはむしろ性能が落ちているらしい。
それ以外だと,i9-7900Xはi7-6950Xに大して22〜28%程度高いスコアを示している。64/32bitの浮動小数点数に対してSIMD演算を行う場合,クロックあたりの性能がBroadwell-Eに対して伸びていることは確かなようだ。
i7-7740Xとi7-7700Kのスコアはすべてでほぼ一致している。
 |
 |
以上をざっくりまとめるなら,i9-7900Xはi7-6950Xに対し,整数演算性能はクロック増分程度の性能向上しか得られていない一方,SIMDを使った浮動小数点演算ならばクロックあたりの性能が1割強〜3割弱程度高いということになるだろう。i7-7740Xとi7-7700Kは同じCPUとしか思えない。
SandraではAVX-512の効果が顕著に現れる
続いては,SiSoftware製のシステム検査&ベンチマークツールである「Sandra」(Version 2017.06.24.27,以下 Sandra 2017)を使っていこう。
Sandra 2017はAIDA64に比べてより新しい命令セットで最適化されており,AVX-512にも対応している。なので,Sandra 2017ではAVX-512の威力を知ることができる。
まずは,AIDA64のときと同じように,常用環境における結果から見ていこう。
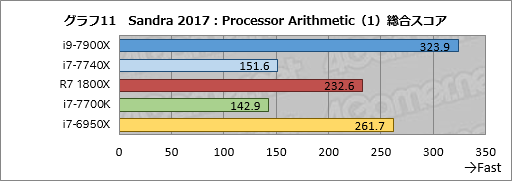
グラフ11はCPUの演算性能を見る「Processor Alithmetic」の総合スコア「Aggregate Native Performance」だ。
i9-7900Xのスコアは前世代のi7-6950Xに対して約124%と,クロック比からして妥当か,やや高めといえる数字になっている。一方でi7-7740Xのスコアはi7-7700Kの約101%なので,ほとんど同じと言っていいだろう。
Ryzen 7 1800Xはi7-7700Kに対して1.63倍と,動作クロックおよびコア数を考えれば,まずまず妥当な結果に落ち着いた。
 |
ただ,個別スコアを見るグラフ12だと,やや異なる傾向を確認できる。
32bit整数演算の「Dhrystone Integer Native AVX2」では,i9-7900Xがi7-6950Xに対して約40%高いスコアを示し,64bit整数演算となる「Dhrystone Integer Native AVX2」では約52%高い結果と,さらにスコア差を広げている。AIDA64だと整数演算は苦手のような結果が出ていたわけで,このスコアはやや奇妙だ。
ちなみに,Processor AlithmeticでAVX-512は使われておらず,あくまでもAVX2の整数SIMD演算を用いている。したがって,「新命令セットのおかげでi9-7900Xのスコアが伸びた」わけではない。
原因として考えられるのは,Dhrystoneが極めて規模が小さいテストなので,キャッシュ性能が効果を発揮したか,TBMax3効果が出たかといったあたりだが,このあたりは後ほどクロックを揃えたテストであらためて考察したい。
また,Dhrystone Integer Native AVX2でi7-7740Xがi7-7700Kに対して約13%高いスコアを示した点も興味深い。ここまでのテストだとi7-7740Xとi7-7700Kがうんざりするほど同じスコアを出してきたので,ようやくやや目立つ違いが出てきたと言えるだろう。
これだけで違いが出てきた原因を語るのは難しいが,自動クロックアップ機能を有効化しているので,クロック要因が考えられなくはない。これも後段であらためて検討したいと思う。
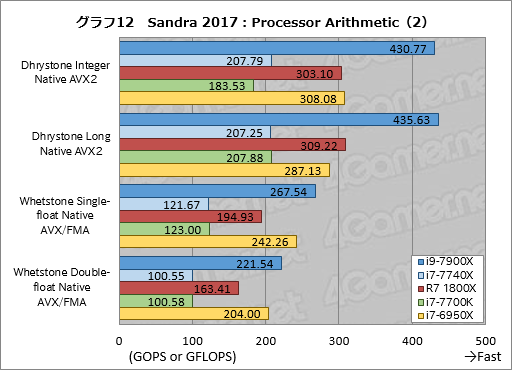 |
浮動小数点演算に目を移すと,32bit単精度の「Whetstone Single-float Native AVX/FMA」ではi9-7900Xが前世代のi7-6950Xに対して約10%,64bit倍精度の「Whetstone Double-float Native AVX/FMA」では約9%,それぞれクロック比に見合わない程度のスコア向上を果たしている。AIDA64ではAVXやFMAを使った浮動小数点演算でi9-7900Xの成績が良かったので真逆だが,ここもこれだけではなんとも言えないので,後ほど再検討したいと考えている。
なお,比較対象として用意したRyzen 7 1800Xについても軽く触れておくと,直接のライバルと言える4コアのi7-7700Kに対して個別テストでも49〜65%程度高いという,極めて妥当な成績を残した。
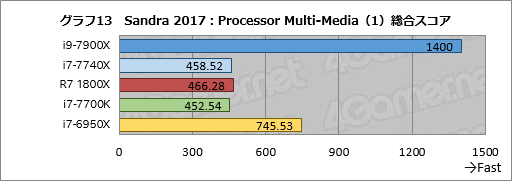
続いては,マルチメディアの処理性能を見る「Processor Multi-Media」だ。このテストではAVX-512を含めて新しい命令セットを多用するので,端的に述べてi9-7900Xが圧倒的に有利となるが,それを如実に示すのがグラフ13にまとめた総合スコア「Aggregate Multi-Media Native Performance」である。
i9-7900Xはi7-6950Xに対してなんと約88%も高いスコアを示し,Ryzen 7 1800Xに対してはトリプルスコアを叩き出している。というか,Ryzen 7 1800Xは4コアのi7-7740Xおよびi7-7700Kと大差のないスコアに沈んでしまった。
 |
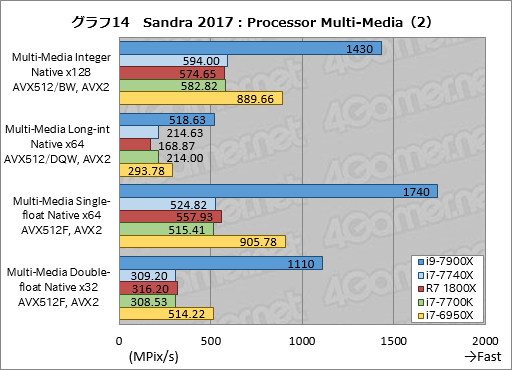
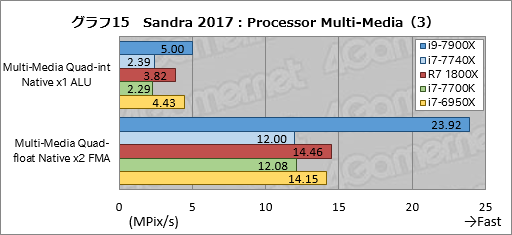
Processor Multi-Mediaの個別スコアをグラフ14,15に示す。目を引くのは項目名に「AVX512」と入っているテストの結果が偶然まとまったグラフ14のほうで,全項目にわたってi9-7900Xが比較対象を圧倒している。とくに「Multi-Media Double-float Native x32 AVX512F, AVX2」に至っては対i7-6950Xでも約216%というスコアを叩き出した。もっとも,2倍の長さを持つレジスタで2倍の演算を行うのだから,2倍近いスコアが出るのは当然なのだが。
もちろん,すべての処理にAVX-512を使うわけではないため,「Multi-Media Integer Native x128 AVX512/BW, AVX」や「Multi-Media Long-int Native x64 AVX512/DQW, AVX2」のように2倍に遠く及ばないスコアに留まるテストもあるわけだ。
AVX-512関連以外では,FMAを使う「Multi-Media Quad-float Native x2 FMA」でi9-7900Xがi7-6950Xに対し約70%高いスコアを示している点も特筆すべきだろう。AIDA64の成績と合わせて考えるに,FMAの性能はかなり高くなっているようだ。
一方のi7-7740Xは,若干のブレはあるものの,i7-7700Kとおおむね同程度のスコアに落ち着いている。Multi-Media Single-float Native x64 AVX512F,AVX2で約4%高いスコアを示しているのは目を引くが,何らかの不定要因で高いスコアが出てしまった可能性は否定できない。
Ryzen 7 1800Xの成績も全体的には芳しくないが,古典的なx86命令を使うMulti-Media Quad-int Native x1 ALUでは,i7-7700Kに対して約67%高いスコアを示した。Ryzenは,AVXやFMAの性能こそ冴えない一方で,古典的なx86命令は得意なようである。
 |
 |
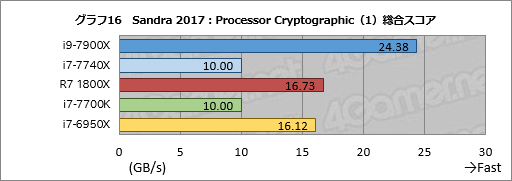
暗号化の性能を調べる「Processor Cryptographic」の総合スコア「Cryptographic Bandwidth」をまとめたものがグラフ16だ。
AIDA64ではRyzen 7 1800Xが突出したスコアを残した暗号化処理だが,Sandra 2017ではi9-7900Xが圧倒的な結果を残している。i7-6950Xに対して約51%,Ryzen 7 1800Xに対して約46%高いスコアである。ただ,そのRyzen 7 1800Xも対i7-6950Xではコア数が少ないにもかかわらず約4%高いスコアであり,これはこれで優秀と言っていいだろう。
 |
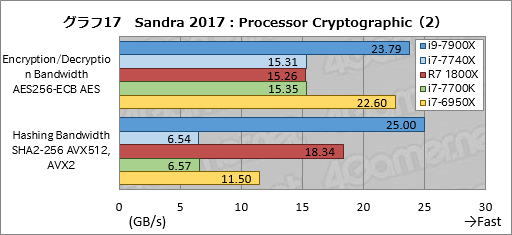
グラフ17はProcessor Cyrptographicの個別スコアだが,AES-NIを使う「Encryption/Decryption Bandwidth AES256-ECB AES」ではi9-7900Xのスコアが冴えない一方,AVX-512を使う「Hashing Bandwidth SHA2-256 AVX512, AVX2」ではi7-6950Xに対して約217%という2倍以上のスコア差を付けている。AVX-512効果なので,これは当然だろう。
よく分からないのはRyzen 7 1800Xで,Encryption/Decryption Bandwidth AES256-ECB AESでは4コアのi7-7700Kと同程度のスコアしか出せていない一方,Hashing Bandwidth SHA2-256 AVX512, AVX2ではなんとi7-7700K比約279%というスコアを示し,対i7-6950Xでも前者で約68%のスコアに留まるところが後者では逆に約159%と圧倒しているのだ。
当然のことながら,このようなバラツキには「何かありそうだ」ということになるだろう。もしかするとRyzen 7はSHA命令のスループットが非常に高いといったことがあるのかもしれない。
 |
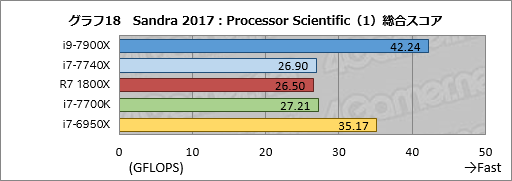
科学技術計算を行う「Processor Scientific」,グラフ18はその総合スコア「Aggregate Scientific Performance」である。i9-7900Xはi7-6950Xに対して約20%高いスコアで,ほぼ妥当な印象と言っていいのではなかろうか。i7-7740Xはi7-7700Kに対して約1%低いスコアが出ているものの,ここはおおむね同じと見るほうが正解かもしれない。
気になるのはRyzen 7 1800Xで,i7-7700K比約97%に留まった。コア数からすればRyzen 7が圧倒的に有利なはずなので,あまり得意な処理ではないのだろう。
 |
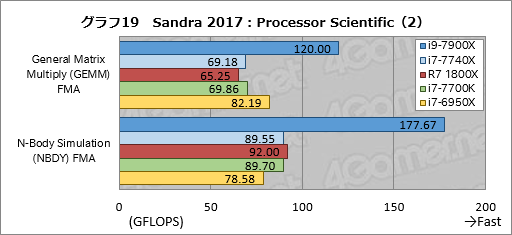
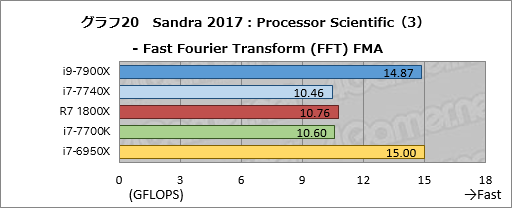
Processor Scientificの個別スコアはグラフ19,20に示すが,上で妥当に見えたi9-7900Xのスコアは,実のところそうでもないということが窺える。行列計算を行う「General Matrix Multiply (GEMM) FMA」だとi7-6950Xに対して約46%高いスコアを示し,多体問題を解く「N-Body Simulation (NBDY) FMA」では約126%高いスコアで圧倒する一方,高速フーリエ変換を行う「Fast Fourier Transform (FFT) FMA」では約99%と,向き不向きがはっきりした結果となった。FMAを使用するベンチマークではこれまでもi9-7900Xが優秀な成績を残してきたが,コードによって大きく性能が変わるのかもしれない。N-Body Simulationのように強烈に高い性能を示す場合もある,ということだろう。
もう1つの主役であるi7-7740Xはi7-7700Kに対して約1%低い,ほぼ同じと言えるスコアを示している。
Ryzen 7 1800XはGeneral Matrix Multiply (GEMM) FMAで4コアのi7-7700Kに対して0.93倍のスコアしか出せていない。FMAやAVXを使うと振るわない傾向がここでも出ているようだ。
 |
 |
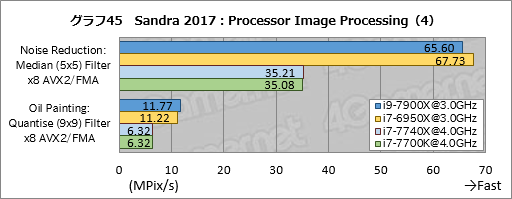
お次は,AVXやFMAを使用した2D画像の処理性能を見る「Processor Image Processing」である。グラフ21が総合スコア「Aggregate Image Processing Rate」だが,これだけ見ると面白みのないというか,非常に妥当な結果となっている。i9-7900Xのスコアはi7-6950Xに対して約13%高く,i7-7740Xはi7-7700Kとほぼ同じ。Ryzen 7 1800Xのスコアはi7-7700Kより約15%高いものの,コア数の違いを考えると物足りない。
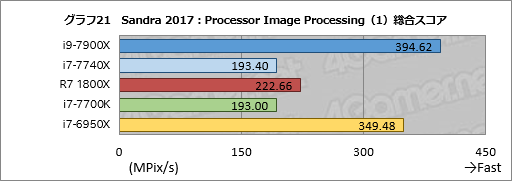 |
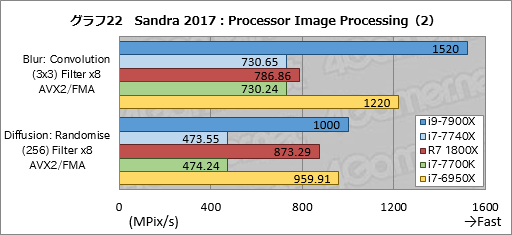
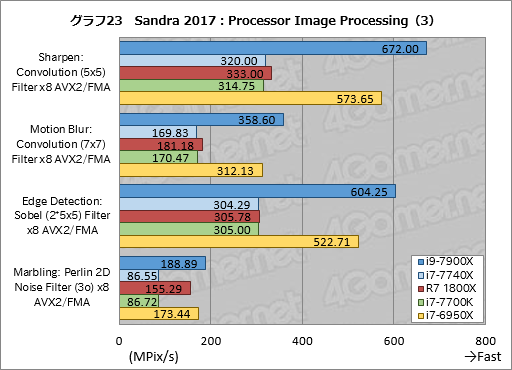
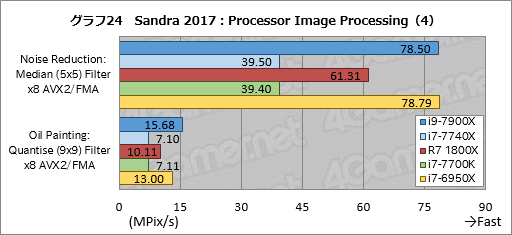
Processor Image Processingの個別スコアはグラフ22,23,24にまとめた。
ぱっと見て気付くのは,FMAやAVXを多用するテストの割に,i9-7900Xのスコアがあまり伸びていないことだ。i7-6950Xに対して最大では約25%高いスコアを示すものの,「Noise Reduction: Median (5x5) Filter x8 AVX2/FMA」ではほぼ互角となっており,数%程度しかスコアが上がっていないテスト項目も複数ある。
i7-7740Xのスコアはここでもi7-7700Kと同等だ。
クセが出ているのはRyzen 7 1800Xで,「Marbling: Perlin 2D Noise Filter (3o) x8 AVX2/FMA」と「Diffusion: Randomise (256) Filter x8 AVX2/FMA」でかなり高いスコアを出しているのが目を惹く。FMAやAVXを苦手とする傾向が見えていたが,アルゴリズムによってはそうならないということだろうか。Perlin 2D Noise Filter(≒パーリンノイズ)やDiffusion: Randomise(≒誤差拡散)はSIMD演算が有効な処理だが,それ以外のテストでもSIMD演算はやはり有効なので,この2項目だけRyzen 7が突出する理由は何とも言えない。
 |
 |
 |
続いて,いわゆる足回りのテストに移る。
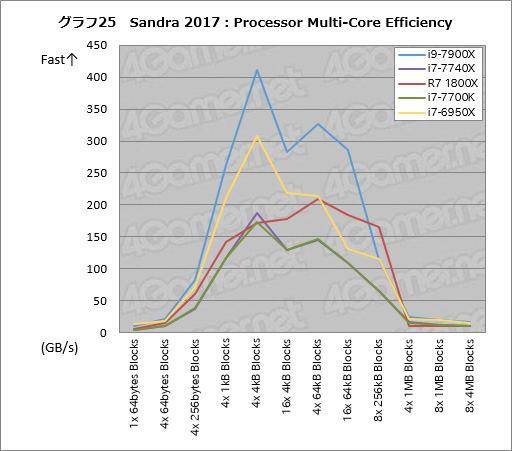
グラフ25はCPUコア間の帯域幅を調べる「Processor Multi-Core Efficiency」の結果だ。
冒頭で紹介したとおり,i9-7900XはCPUコアやアンコア部を接続する内部バスが従来のリングバスからメッシュ構造へ変更となり,動作クロックもi7-6950Xの3GHzから4GHzへ大きく向上しているが,その効果が目立つ形で現れている。具体的には,「1x 64bytes Blocks」を除くすべてのブロックサイズでi9-7900Xのコア間の帯域幅がi7-6950Xに対して格段に高いことが分かる。
また,i9-7900Xで特徴的なのは,i7-6950X比で「4x 64kB Blocks」の帯域幅が約152%,「16x 64kB Blocks」では約217%にまで高くなっていることだ。これはおそらく,キャッシュ階層リバランスの影響だろう。
一方,i7-7740Xはi7-7700Kとおおよそ同じで,「4x 4kB Blocks」のみ約8%高い程度だ。ここでのテストは自動クロックアップ機能を有効にしているので,そのブレの範囲内と考えられる。
内部アーキテクチャが異なるRyzen 7 1800Xはグラフの形そのものがIntelの製品とは異なる。16x 64kB Blocksや「8x 256kB Blocks」ではIntel製CPUを上回る帯域幅を見せるなど独特ながら,少なくともライバルと比べて劣るものではないと言っていいだろう。
 |
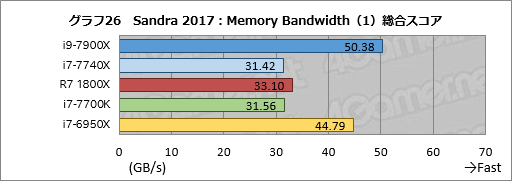
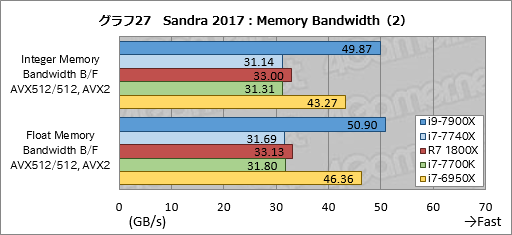
メモリバス帯域幅を見る「Memory Bandwidth」のテスト結果がグラフ26,27だ。Memory Bandwidthは「使えるならAVX-512を使う」という仕様になっているが,計測対象はあくまでもメモリバス帯域幅なので,命令セットの違いがスコアへ与える影響はほとんどない。
結果はグラフ5で示したAIDA64でのテスト結果とほぼ同じ傾向で,i9-7900Xのスコアは,唯一DDR4-2400設定となるi7-6950Xに対して総合スコアで約12%高い。i7-7740Xはi7-7700Kと誤差範囲で一致している。
Ryzen 7 1800Xは同じメモリ設定ながらi7-7700Kに対して約5%高いスコアを示すが,これもAIDA64の傾向と一致する。個別スコアを含めて,おおむね妥当であり,不審な点はないと言っていいだろう。
 |
 |
次はキャッシュおよびメモリの遅延を計測する「Cache & Memory Latency」に移ろう。その結果はグラフ28のとおりだ。
i9-7900Xはキャッシュ階層をリバランスした影響が出ており,L2キャッシュに収まる「64kB Range」から「512kB Range」まで3.3nsという低い遅延を実現できている。i7-6950XだとL3キャッシュの範囲に入ってしまう「512kB Range」で7.3nsまで悪化するのとは対照的だ。
ただ,i9-7900XのL3キャッシュ範囲となる「2MB Range」〜「8MB Range」だと遅延は8.5〜8.9nsと,i7-6950Xの7.3〜7.5nsに比べて大きくなる。L3キャッシュの遅延はBroadwell-EよりSkylake-Xのほうが大きいようだ。
メインメモリの範囲となる64MB Range以上ではi9-7900Xがi7-6950Kよりも3〜4nsほど遅延が大きくなるものの,グラフ6で見られたほどではない。
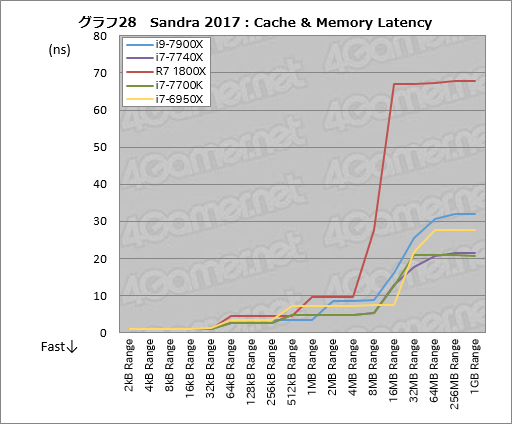 |
i7-7740Xはおおむねi7-7700Kと同じ遅延傾向を見せるが,32MB Rangeのみ3nsほど低かった。このレンジはメインメモリの範囲で,同じメモリモジュール,同じアクセス設定を使っているので理由はなんとも言えない。
Ryzen 7 1800XはL3キャッシュの範囲となる4MB Rangeまではおおむね優秀。4MB Rangeを超える範囲では「Infinity Fabric」の影響が出るためL3キャッシュ内でも遅延は大きくなる。またメインメモリの遅延は極めて大きい。
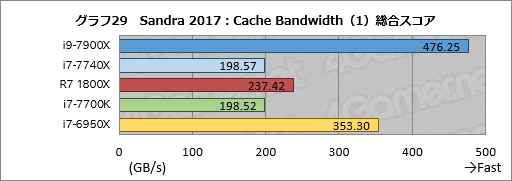
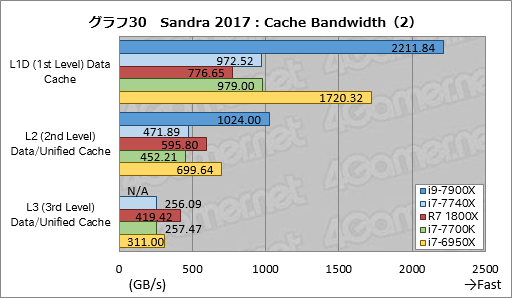
キャッシュ周りの帯域幅を見る「Cache Bandwidth」のテスト結果がグラフ29,30だが,残念ながら今回テストに用いたSandra 2017ではi9-7900XのL3キャッシュ帯域幅を取得できなかった。おそらくはバグか実装の不完全でスコアが出ないので,今回はスコアをN/Aとしている。
そういう事情なので,今回示した数字はあまり参考にならない。読み取れる内容としては,i7-7740Xとi7-7700Kと一致する傾向を示していることと,Ryzen 7 1800XはL2,L3キャッシュともにまずまず好成績を残していることが挙げられる程度だろうか。
 |
 |
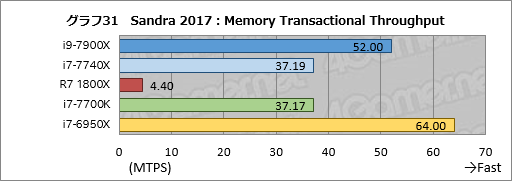
「マルチスレッド環境においてスレッド間でメモリの競合が発生した場合」のメモリ速度性能を見る「Memory Transaction Throughput」,その結果をまとめたものがグラフ31だ。
奇妙なのはi9-7900Xのスコアがi7-6950Xに対して約81%しかない点だろう。双方ともTSX命令(※メモリの競合が起きるメモリアドレスを指定して,競合が起きたときにメモリトランザクションのロールバックを行う命令のこと)をサポートするCPUなので,単純にメモリバス帯域幅の分だけi9-7900Xのほうが良くなるはずだが,そうなっていないのが面白い。TSX命令のインプリメンテーションが変わっているのかもしれない。
i7-7740Xとi7-7700Kはここでもほぼスコアが一致した。
Ryzen 7 1800Xは5製品中,唯一TSX命令を持たないCPUなので,残念なスコアしか得られていない。TSX命令はIntelでさえ実装に1世代かかった命令なので,AMDが同様あるいは類似の命令を実装するとしても,少し先の話になるのではなかろうか。
 |
以上,Sandra 2017のスコアを見てきたが,いくつか,常用環境では分かりにくいところがあった。そこで,AIDA64と同じように,i9-7900Xとi7-6950Xは全コア3.0GHz固定,i7-7740Xとi7-7700Kは全コア4.0GHz固定でテストを実行した結果も見ておきたいと思う。
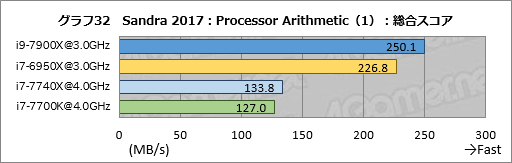
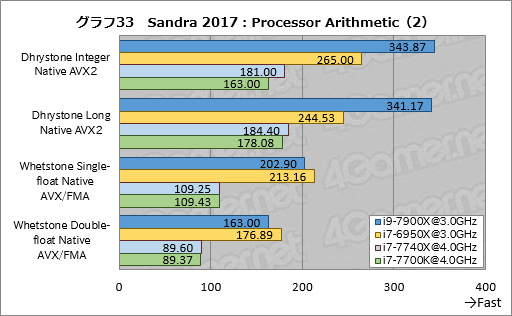
グラフ32,33はProcessor Arithmeticの結果である。
i9-7900Xは整数演算のDhrystone Integer Native AVX2でi7-6950Xと比べて約30%高いスコアを,64bit長整数のDhrystone Long Native AVX2では約40%高いスコアを記録した。一方,32bit単精度浮動小数点演算のWhetstone Single-float Native AVX/FMAでは約95%,Whetstone Double-float Native AVX/FMAでは約92%のスコアしか出せていない。つまり,同じクロックで比較した場合,i9-7900Xはi7-6950Xと比べて整数演算に強く,浮動小数点演算に弱いという結果で,AIDA64の逆となっている。
DhrystoneやWhetstoneは非常に古臭いテストで,サイズも小さい。そのためキャッシュの性能の影響が出やすい傾向にあることは否定できない。それでも,AIDA64と合わせて考えるに,整数演算や浮動小数点演算の性能がi9-7900Xで大きく伸びているわけではない,とは言えそうだ。
i7-7740XはDhrystone Integer Native AVX2でi7-7700Kに対して約11%高いスコアを記録した。これは無視できない違いである。
ただ,ここまでのテストを見る限り,i7-7740Xの演算エンジンが変わっているとは思えないので,足回りの違いが出ているのかもしれない。この点については後ほど考えたい。
 |
 |
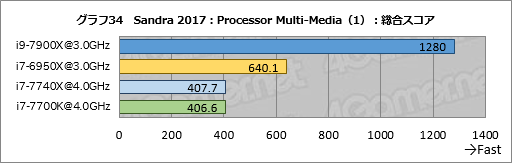
グラフ34はProcessor Multi-Mediaの総合スコアである。i9-7900Xが持つAVX-512の威力がはっきりと分かる結果で,i9-7900Xがi7-6950X比できっちり2倍となった。
 |
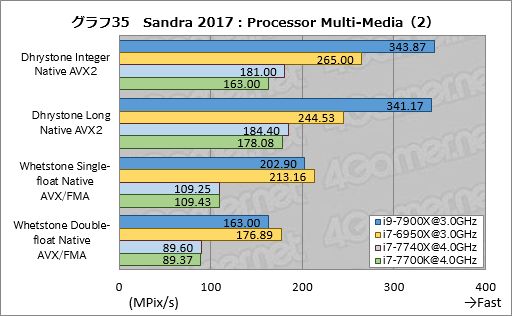
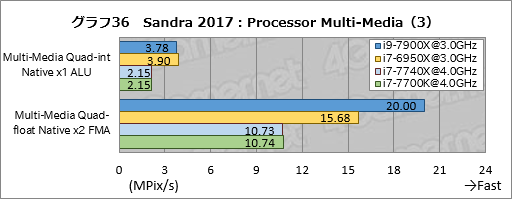
グラフ35,36で個別スコアを見てみると,古典的なx86命令を使うMulti-Media Quad-int Native x1 ALUでi9-7900Xの成績が振るわないという,AIDA64でも見られた傾向が出ている。
AVX-512を使うテストはi9-7900Xが高いスコアを出すのは当然として,Multi-Media Quad-float Native x2 FMAのスコアもi7-6950Xに対して約1.28倍と有意なスコアを出している点も目を惹くところだ。
i7-7740Xのスコアは,全項目がi7-7700Kと誤差範囲で一致したと言っていい結果である。
 |
 |
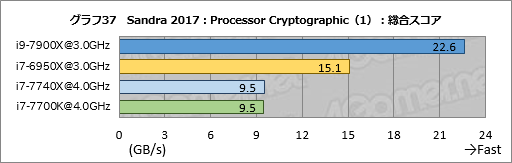
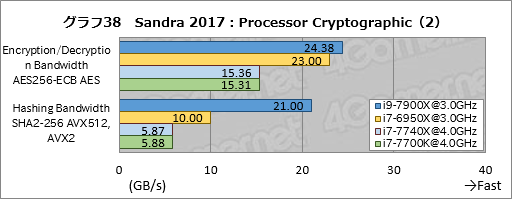
Processor Cryptgraphicsの結果がグラフ37,38だ。AES-NIを使うEncryption/Decryption Bandwidth AES256-ECB AESだとi9-7900Xがi6-6950X比で約7%高いスコアを示しているので,同じ動作クロックで比較したAES-NIのスループットはやや向上しているようだ。
AVX-512を使うHashing Bandwidth SHA2-256 AVX512,AVX2はi9-7900Xがi7-6950Xにダブルスコアをつけており,AVX-512の威力だけが目立つ結果となった。
i7-7740Xのほうは,i7-7700Kとおおむね一致するスコアに収まっている。
 |
 |
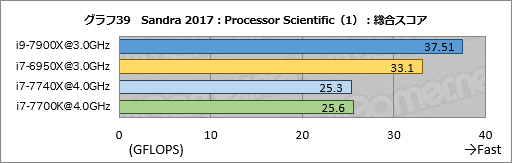
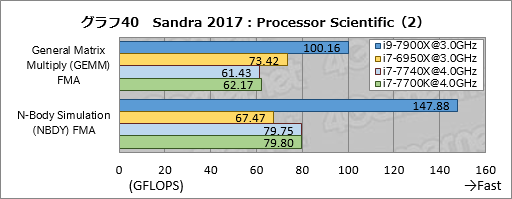
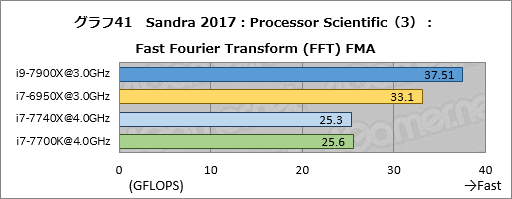
Processor Scientificの結果はグラフ39〜41にまとめた。ここで目を惹くのはN-Body Simulation (NBDY) FMAの結果で,i9-7900Xのスコアがi7-6950X比で約219%と,2倍超になった。一方でFast Fourier Transform (FFT) FMAだと約94%に沈んでいる。
N-Body SimulationではAVX-512を使っていないはずなのだが,2倍を超えるスコアを出すのは何かあるとしか思えない。いずれも並列化が有効なテストで,内部バスの性能向上と言った足回りの違いだけで説明がつくような違いではないため,アルゴリズム的に得手不得手があるのかもしれない。
i7-7740Xのスコアはi7-7700Kとここでもほぼ一致した。
 |
 |
 |
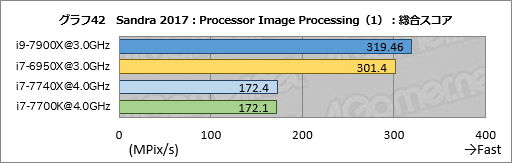
Processor Image Processingの結果がグラフ42〜46となる。総合スコアをまとめたグラフ42では,i9-7900Xがi7-6950X比で約6%高いスコアを示し,わずかながら内部バスやキャッシュの性能向上が効いているという可能性を示唆している。
 |
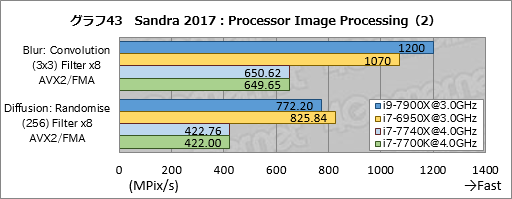
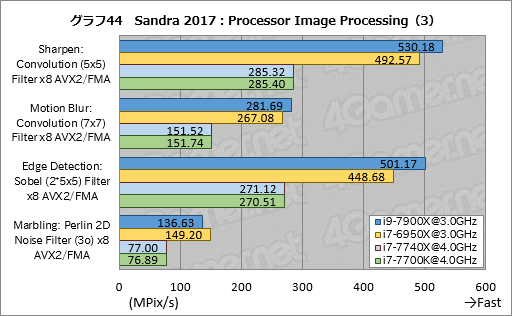
グラフ43〜45にまとめた個別スコアでは,ややバラツキがあるものの,パターンが見えてこない。そのため現時点では,「得意不得意の影響でスコアに“出入り”がある」程度のことしか言えそうもない。
i7-7740Xのスコアはi7-7700Kとここでもほぼ一致している。
 |
 |
 |
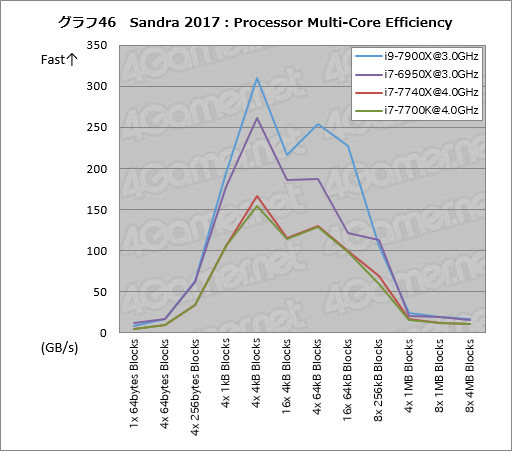
最後はProcessor Multi-Core Efficiencyとなる。i9-7900Xは内部バスがリングバスからメッシュ構造に切り替わり,さらに高クロック動作を実現しているため,CPUコアクロックを揃えてもi7-6950Xに比べて極めて高い性能を持つことがグラフ46から読み取れるだろう。
もう1つ,i7-7740Xの結果にも注目したい。コアクロックを4.0GHzで揃えているにもかかわらず,4x 4kB Blocksや8x 256kB Blocksでi7-7700Kに対し有意に大きな帯域幅を示しているからだ。i7-7740Xではキャッシュ周りに改良の入った可能性がある。
 |
……長くなったが,Sandra 2017のスコア確認はここまでとしたい。
i9-7900Xに関してはAVX-512の効果は極めて高いと言えるが,本稿の序盤でも述べたとおり,利用するアプリケーションがほとんどないため,AVX-512の威力をユーザーが活かせるようになるには,ベストケースでも少し時間がかかるだろう。最悪,デスクトップ用途ではほぼ使えないまま次世代を迎えるという可能性もありうる。
その他の命令セットでは,Broadwell-EやKaby Lake-Sより明らかに優れている部分を探すほうが難しく,むしろ得手不得手がいろいろ出たと言ったほうが適切ではなかろうか。ただ,内部バスはかなり高速になっているようだ。
i7-7740Xはi7-7700Kとほとんど変わらないCPUだが,キャッシュに改良が入った可能性は,スコアから多少読み取れる。たとえば,Dhyrystoneのようなプログラムサイズが小さいテストでi7-7700Kよりもやや好成績を収めているといった違いだ。
とはいえ,一般的なアプリケーションを前にしたi7-7740Xの性能はi7-7700Kとほぼ完全に同じというのは,レビュー前編で述べたとおりである。
連続負荷状態での消費電力と熱をチェック
レビュー前編で「引くレベル」と評したi9-7900Xの消費電力だが,約190Wというのはあくまでもピーク時のものである。常用環境で連続的に負荷がかかったときにどの程度の消費電力があるのか,また気になる発熱はどの程度かを調べてみたい。
連続的に負荷がかかる代表的な処理はエンコードだろうということで,今回はオープンソースのトランスコーダ「ffmpeg」(Nightly Build Version N-86691-gc885356)を利用することにした。
 |
さらに今回は,MUGEN 5 Rev.Bの空冷ファンを+12V直結とし,ファンの温度制御を行わない状態にした。同じクーラーでファンの回転数を等速の1200rpmにすれば,冷却システムの熱抵抗をほぼ同じにできるだろうというわけである。
エンコードのテストにあたってソースとして用意したのは,フルHD解像度で長さ約30分のMPEG-2 TSファイルだ。コーデックとしてx264を使い,平均8MbpsのMPEG-4/H.264形式にトランスコードを行う。
目的は温度と消費電力を測ることだが,せっかくなのでトランスコードにかかる時間も計測する。Windows PowerShellの「measure-command」を使えば,極めて正確にffmpegの実行時間が計測できるはずだ。
 |
「-threads」オプションに0を指定することで,x264は論理コア数×1.5倍のスレッドを立ち上げるので,理屈のうえでは全コアに負荷がかかる設定だ。
del test.mp4
powershell -c measure-command {.\ffmpeg -i sample.ts -vf yadif -c:v libx264 -b:v 8000k -preset slow -tune film -crf 18 -threads 0 test.mp4}
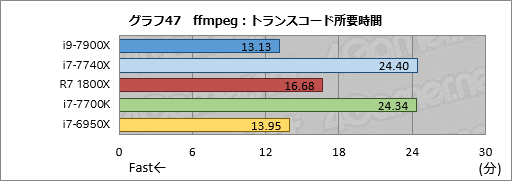
グラフ47は,バッチファイルを使ったエンコードの所要時間をまとめたものだ。
ご覧のとおり,i9-7900Xとi6-6950Xは同じ13分台だった。厳密に言えばi9-7900Xが13分台前半,i7-6950Xは14分弱なので,AIDA64やSandra 2017で確認できた性能差を考えるとまずまずの結果である。ただ,エンコードの性能が劇的に向上しているわけではないとも言えるだろう。
i7-7740Xとi7-7700Kは24分台で,両者の違いは数秒程度。注目したいのはRyzen 7 1800Xで,16分台でエンコードを終えている。エンコードにおける価格対性能比だと,今回のテスト対象ではRyzen 7 1800Xがダントツでないだろうか。
 |
続いてグラフ48はエンコードにおける消費電力の推移をまとめたものだ。今回はRyzen 7 1800Xのレビュー時と同じく,クランプメーターでEPS12Vの電流を測ってそれを電力に直し,CPUの消費電力としてグラフ化している。
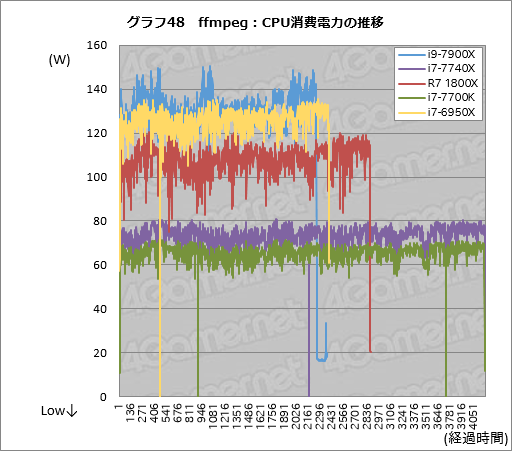 |
グラフの横軸は経過時間だが,テスターが1秒間に3回ほどサンプリングするので,単純な「秒」ではない。「1」≒0.33秒と理解してもらえればと思う。
また,ときおりグラフが0に落ちているが,これはテスターからのデータをソフトウェアがまれに取りこぼすためだ。実際に落ちているわけではない点にも注意してもらえればと思う。
それを踏まえて5本の折れ線を眺めてみると,トランスコード実行中におけるi9-7900Xの消費電力はピークで150W弱程度となり,おおむね130W台半ばから140W台で推移しているのが分かる。i7-6950Xは100W台半ばから130W台前半で推移しているので,i9-7900Xのほうが平均して10W強は消費電力が高いと言えそうだ。
Ryzen 7 1800Xはピークが120W弱,下限は80W台半ばで,10コア20スレッド対応CPUと比べるとざっくり20〜30Wは消費電力が低いと言える。エンコード性能がまずまずで,消費電力もまずまずなのだから,エンコード処理を前にしたRyzen 7 1800Xの素性はいいということになるだろう。
気になるのはi7-7740Xがi7-7700Kよりも10W程度高めに推移する点だ。エンコード時間が変わらないのに消費電力が1割以上も高いのというのは,どう考えても割に合わない。
お次は温度計測だが,CPU温度を測るにあたっては,「HWInfo64」(Version 5.52-3161)を利用することにした。ただし,HWInfo64に限らず,この手のソフトはサーマルダイオードの値を「CPUの温度」として拾ってくるので,Intel製CPUとAMD製CPUとでは得られるスコアが大きく変わってしまう。また,CPUの種別が異なる場合でも,同じ条件でサーマルダイオードの値を拾えているとは限らない。
したがって,HWinfo64の測定値そのものを比較するのは危険で,ここでは「温度制御がない冷却システムでグラフが右肩上がりにならないかどうか」をチェックするに留める。グラフが右肩上がりになることは,ファン回転数を固定したMUGEN 5 Rev.Bで熱を処理できていないことを意味するからだ。
 |
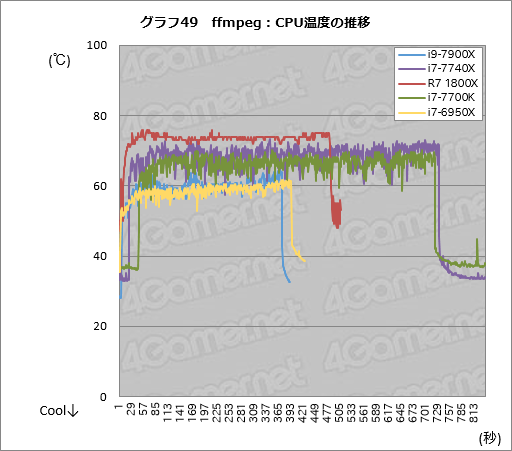
というわけで,まずはHWinfo64のログをグラフ49にまとめておこう。繰り返すが,温度の絶対値はそれぞれのCPUで異なるので,CPU間の比較に意味はない。グラフは傾斜だけを見てもらいたい。
それを踏まえてグラフを確認してみると,右肩上がりが顕著に出ているのは10コア20スレッドのCPU 2製品だということが分かる。とくにi9-7900Xでは終盤に温度の上昇が大きくなっているのが気になるところだ。13分でエンコードが終わっているからいいものの,このまま負荷がかかり続ければ温度はさらに上昇するはずで,CPUクーラーは相当に選びそうだ。
それ以外のCPUは,おおむね平坦なグラフになった。ファン回転数を固定したMUGEN 5 Rev.Bで熱的な平衡状態が得られていると見ていい。i9-7900Xやi7-6950Xと比べれば処理しやすい発熱ということになる。
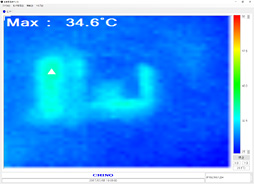
 |
それぞれのCPUにおけるエンコード開始前と終了直後のサーモグラムは,下に並べてみたので参考にしてほしい。その仕様上,サーモグラムは左右反転しているが,今回,向きは重要ではないので,とくに再反転処理などは行っていない。
サーモグラムの中央左寄りに見える四角い部分がMUGEN 5 Rev.Bで,その右側がマザーボード上の電源部だ。電源部の位置は各製品でそれほど変わらない。また,MUGEN 5 Rev.Bの左には「GeForce GTX 1080 Founders Edition」が差さっている。
テスト時の室温は27〜28℃前後で調整した。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
目を引くのはやはりi9-7900Xで,電源部の温度がエンコード終了直後に41℃以上にまで上昇している。i7-6950Xの37℃台よりもさらに高い温度だ。
41℃なら何ら問題はないと思うかもしれないが,相対的にi9-7900X搭載環境が最も高い温度になっているのは確かである。
面白いのは,同じマザーボードに差していても,i7-7740Xだと,電源部の温度はむしろかなり低くなっているということだ。ピークで190Wに達し,コンスタントに140W程度の消費電力を持つCPUへ対応できるマザーボードにとって,100W以下の消費電力で推移するi7-7740Xなど,ほとんど負担にもならないということなのだろう。
なお,Ryzen 7 1800Xも温度は低めで,むしろGeForce GTX 1080の発熱が目立つ程度に収まった。テストに用いたマザーボードの電源部が優秀なのかもしれない。
というわけで,「ピーク190W」という言葉の響きほどではないにせよ,i9-7900Xの発熱,消費電力はかなり大きいと言える。長時間,負荷をかける場合に,空冷のシステムでは心許ないと思う人もいるだろう。
また,消費電力の変動も大きいのも気になるところで,良質な電源部を持つマザーボードを使ったほうがよさそうだということも言える。電源部を“ケチっている”マザーボードを使うと,思わぬトラブルに泣かされるかもしれない。
TBMax3やメモリクロック引き上げ効果も確認
最後にTBMax3と,より高クロックなメモリモジュールとの組み合わせでどの程度の性能向上か図れそうかといったところも見ておこう。
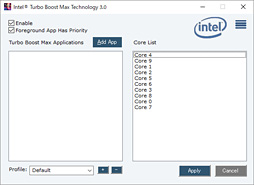 |
i9-7900Xではチップセットドライバのインストールを行うと,同時にTBMax3の常駐ソフトが導入され,TBMax3の動作を制御できるようになる。もっとも,行えるのは有効/無効の切り替えと,通常だとフォアグラウンドのアプリケーションのみにおいて有効なTBMax3を,指定のアプリケーションにおいて強制的に利用できるよう,当該アプリケーションを登録することだけだが。
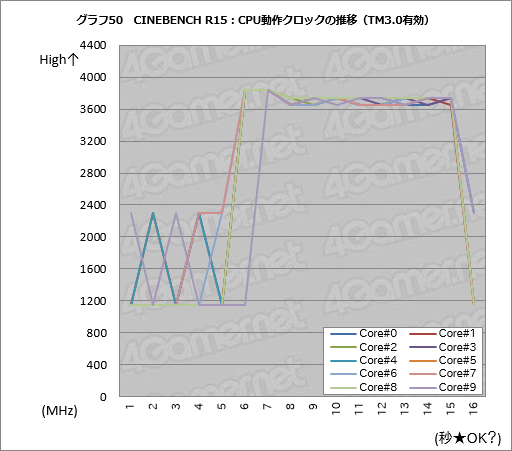
ただ,少なくとも今回のテストにおいて,全コアがトップクロックに入る状況は観測できなかった。参考までに「CINEBENCH R15」(Release 15.038)実行時のクロックの推移をHWInfoから追ってグラフ化したものを掲載しておこう。
グラフ50はTBMax3を有効化した状態,グラフ51は無効化した状態におけるクロック推移だ。HWInfoのログ保存開始と終了は人力で行っているため,テストごとにきっちりと揃えることができない。「だいたいこれくらいだろう」という部分十数秒をログから切り出しているので,開始直前と終了直後のクロックは気にしないでほしい。CPUクロックが3.6GHzを上回っている部分がCINEBENCH R15実行中で,ここでは「3.6GHzを上回っている部分」のクロック推移に注目してもらえればと思う。
というわけでTBMax3を有効化したグラフを見ると,開始直後に10個のコアの動作クロックが3.9GHz弱近くまで上がるが,1秒ほど経つと3.6GHz第まで落ちてしまった。
一方,TBMax3を無効化すると,スタート時のクロックは3.8GHz台で,1秒で3.7GHz台まで落ちる様子を観測できた。つまりCINEBENCH R15実行中はTBMax3有効時よりも無効時のほうがやや高く推移するわけだ。
実はスコアもTBMax3無効化時のほうが高く,TBMax3有効化時の2098に対して,TBM無効化時には2107になった。わずかだが,TBMax3を無効化したほうが成績はいい。
 |
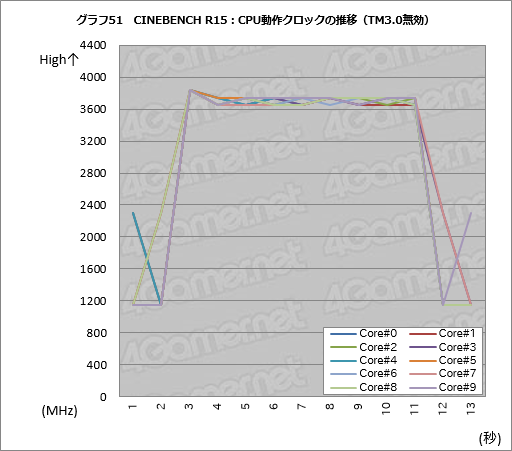 |
このように,CINEBENCH R15開始時の動作クロックは確かにTBMax3を有効にしたほうが高いが,それで力尽きて……というよりもおそらくは熱的,電力的な制限から,以降は低いクロックで推移してしまうため,スコアも下がってしまうのだと考えられる。Intelがわざわざ設定ツールを用意してまでTBMax3の有効/無効切り換えを可能にしているのも,おそらくはCINEBENCH R15のようにTBMax3を無効化したほうが有利なアプリケーションがあるからではないだろうか。
というわけなので,CINEBENCH R15の例を示したようにTBMax3は性能アップに常に有効な機能ではなく,利用は効果を見て慎重にしたほうがいいという結論になる。
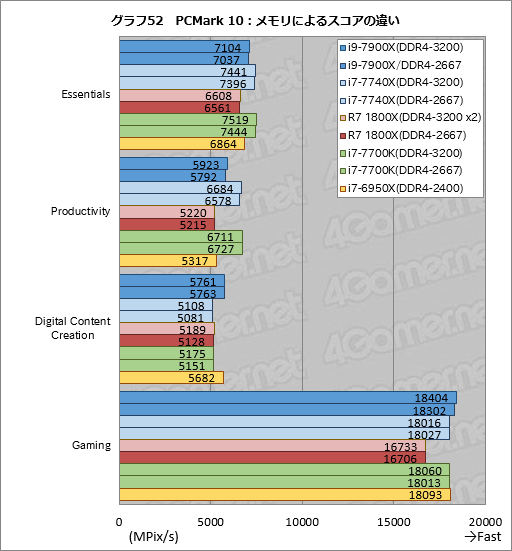
次に,今回はPC4-25600対応のメモリモジュールを使っているので,DDR4-3200動作時にどの程度の性能が得られるか,「PCMark 10」(Version 1.0.1275)を使って調べた結果もお知らせしておきたい。
……と言っても,DDR4-3200設定で正常に機能したのはi9-7900Xとi7-7740X,i7-7700Kのみだ。Ryzen 7 1800Xはメモリモジュール4枚では起動せず,2枚にするとDDR4-3200設定で正常に起動したので,Ryzen 7 1800Xのみ,参考値として,メインメモリ容量16GBでDDR4-3200設定を行ったときのスコアを採用することにする。
また,i7-6950XはDDR4-2400設定以上では起動しなかったため,DDR4-2400設定でのスコアのみ掲載しておきたい。
なお,DDR4-3200設定におけるメモリアクセスタイミング設定は17-18-18-36だ。試用した容量8GBモジュール4枚セット「F4-3200C15Q-32GVK」は,DDR4-3200設定でも15-15-15-35のアクセスタイミングが可能なメモリモジュールだが,今回は異なるプラットフォームで安定して動作することのほうを優先したため,i7-6950Xを除くプラットフォームで確実に起動した17-18-18-36設定を使用している。
結果はグラフ52のとおり。PCMark 10は,PCの快適さを表すEssentialsや,ビジネスユースを前提にしたProductivityのほか,ゲーマーにとって重要な「3DMark」の「Fire Strike」をウインドウモードで実行するGamingが含まれるので,4Gamerの読者にとっても有意なスコアが得られるのが利点だ。
スコアを見ると,全般的にDDR4-2667設定と比べてDDR4-3200設定では約1%のスコア向上が得られているが,なかでも注目できるのはi9-7900XのGamingだろう。DDR4-2667設定に対してDDR4-3200設定で約5%という,有意なスコア向上を確認できた。メインメモリのクロックアップが,とくにゲームにおいて有効ということを示すデータと言えそうだ。
一方でメモリクロックアップの効果が大きいはずのRyzen 7 1800Xは今回,約1%のスコアアップに留まっている。もっとも,Ryzen 7 1800Xではメインメモリの総容量も減ってしまっているので,それが影響を与えた可能性は否定できない。
 |
i9-7900Xが「現時点で最高性能を持つCPU」なのは間違いないが……
レビュー前編と比べてもかなり長くなってしまったが,いろいろと基礎テストの結果をお届けしてみた。まずi9-7900Xについての評価を軽くまとめるなら,クロックあたりの性能ではSIMD演算やFMAの性能が向上している一方で,古典的なx86命令やx87命令では前世代比でむしろ性能が落ちているようだ,ということが言えそうである。
もっとも,現在はコンパイラの自動ベクタ化(=自動的にSIMD命令を生成する機能)が一般的に使われるようになっており,古典的なx86命令やx87命令の重要性は以前と比べても高くない。i9-7900Xでは動作クロックの向上も実現しているので,総合的には前世代のi7-6950Xに対して順当に性能向上を果たしたCPUと結論付けていいかと思う。
一方のi7-7740Xは,キャッシュの改善がちらりと見えなくはないものの,“素の”実用性能はi7-7700Kと変わらない。i7-7740Xが持つ存在意義は,むしろ温度や消費電力にあるかもしれない。
標準動作のi7-7740Xにとって,LGA 2066対応のマザーボードが持つ電源部は明らかにオーバースペックである。逆に言えば,i7-7740Xは標準動作を前提にした製品ではなく,余裕のある電源部を活かして本気のオーバークロックを目指す用途に向いている製品と言えそうだ。
オーバークロックに興味がないのであれば,やや値が張るX299マザーボードを導入してまで積極的に購入するCPUではないだろう。Basin Fallsプラットフォーム向けには,18コア36スレッド対応の「Core i9-7980X Extreme Edition」をはじめとする,12コア超級のCPUが年内にも登場予定なので,それまでのつなぎとして安価なi7-7740Xを買っておくといった消極的な用途ならアリかもしれないが,正直,18コアあたりを狙うなら,18コアCPUに最適化されたX299マザーボード――出るかどうかは分からないが,経験上,出るのではないかと考えている――が出てくるのを待ったほうがいいのではないかという気もする。
また,テストをしていてはっきりしたのは,Ryzen 7の価値だ。最高性能を持つCPUでは決してないものの,マルチコアが有効な用途において,4コア版Core i7より確実に高い性能を発揮し,プラットフォーム全体のコストはBasin Fallsプラットフォームより明らかに安価である。また,消費電力や発熱もi9-7900Xより対処しやすい。
もちろん,Ryzenにはメモリ周りという弱点がある。AMDは改善を予告しているものの,現時点ではIntel製CPUと比べてメインメモリのアクセス遅延が大きく,また,Intel製CPUではさくっと4枚差しで動くPC4-25600対応メモリモジュールが,Ryzen 7 1800Xでは(仕様どおりとはいえ)4枚差しではシステムが起動すらせず,2枚構成にしなければならない。
これはRyzen 7の明らかなデメリットであり,Skylake-XをはじめとするIntel製CPUの明らかなメリットとまとめることができるだろう。
 |
さらに言えば,AMDも,今夏中には最大で16コア32スレッドに対応するHEDT向けCPU「Ryzen Threadripper」を投入予定だ。「最高性能のCPUが欲しい」のか,「最大のマルチスレッド処理能力が欲しい」のか,「十分なマルチスレッド性能をできる限り手頃な価格で入手したい」のか,はたまた「拡張カードの利用を前提に,より多くのPCIe 3.0レーン数が欲しい」のか。人によってHEDT環境に望むものはまちまちだと思うが,少なくとも,現時点ですぐにi9-7900XやLGA 2066環境へ飛びつくのは得策ではなく,向こう数か月は動向を追ったほうがいいのではないかと,筆者は考えている。
i9-7900XをAmazon.co.jpで購入する(Amazonアソシエイト)
i7-7740XをAmazon.co.jpで購入する(Amazonアソシエイト)
i9-7900Xをパソコンショップ アークで購入する
i7-7740Xをパソコンショップ アークで購入する
IntelのCore Xシリーズ製品情報ページ
「Core i9-7900X」「Core i7-7740X」レビュー前編。10コアのSkylake-Xと4コアのKaby Lake-Xは誰のためのものか
- 関連タイトル:
 Core X(Skylake-X,Kaby Lake-X,Cascade Lake-X)
Core X(Skylake-X,Kaby Lake-X,Cascade Lake-X) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー