既報(「こちら」)のとおり,ATI Technologies(以下ATI)は2005年6月1日に,2個のグラフィックスチップをシステム上で動作させるソリューション「CrossFire」(十字砲火の意)を発表した。
久々の連載再開となった今回は,このCrossFireの仕組みを解説していきたいと思う。
Radeon 9700やRadeon 9800にもマルチVPUソリューションはあった
 |
| Radeon 9700(あるいはRadeon 9800)を1枚あたり2個搭載し,2枚セットとなるsimFUSION(左),右はsimFUSIONを16基搭載したグラフィックワーステーション「RenderBeast」だ |
ATIは2001年,ハイエンドの業務用グラフィックワークステーション用として,「simFUSION」という,4個のRadeon 9700あるいはRadeon 9800を使ったイメージジェネレータをEvans&Sutherlandと共同で開発したことがある。また,後にはこのsimFUSIONを16個搭載した,つまり64個のRadeon 9700/9800を並列動作させた「RenderBeast」というグラフィックワークステーションも開発している。なお,これらはプラネタリウムや業務訓練用フライトシミュレータに使われており,実際に今も世界の各所で稼働中だ。
 |
| 「CrossFireがグラフィックスカード2枚差しソリューションでも世界最速を勝ち取る」(ATI,Vice President & general Manager Desktop Business UnitのRich Heye氏) |
ATIの副社長兼デスクトップビジネスユニットゼネラルマネージャであるRich Heye氏は,CrossFireの発表会で以下のように述べている。
「CrossFireは,そうしたプロフェッショナル用途で使われてきたマルチグラフィックスチップシステムを,満を持して一般ユーザーに届けるものなのだ」
要するに「NVIDIA SLI対抗として,うちらも2枚動作させてみました」という,昨日今日思いついた技術ではなく,過去より積み重ねてきた技術の成果としてCrossFireがあるというわけだ。もっとも,この動きの引き金となったのはおそらくNVIDIA SLIの登場なのだろうが。
さて,上で挙げた発表会レポートでも紹介済みだが,ここで改めてCrossFire導入に必要な条件を振り返っておきたい。
- (a)CrossFireコントローラとでもいうべき「Compositing Engine」チップが搭載された,Radeonシリーズ搭載グラフィックスカード。これがマスターカードとなる
- (b)スレーブカードとなる,Radeon X850/X800シリーズ搭載グラフィックスカード。これには既存の製品も含む
- (c)PCI Express x16カードをPCI Express x8接続で2枚同時に利用できる「CrossFire認証」されたマザーボード
- (d)CrossFireをサポートするCatalystグラフィックスドライバ
(a)と(b)がこれまでのグラフィックスカード2枚差しソリューションと決定的に異なる部分だ。NVIDIA SLIでは,構成する2枚のカードが同列であるのに対し,CrossFireではマスターカードとスレーブカードが存在する。
では実際に,どのように動作していくのか,そのプロセスを細かく見ていこう。
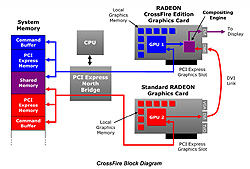 |
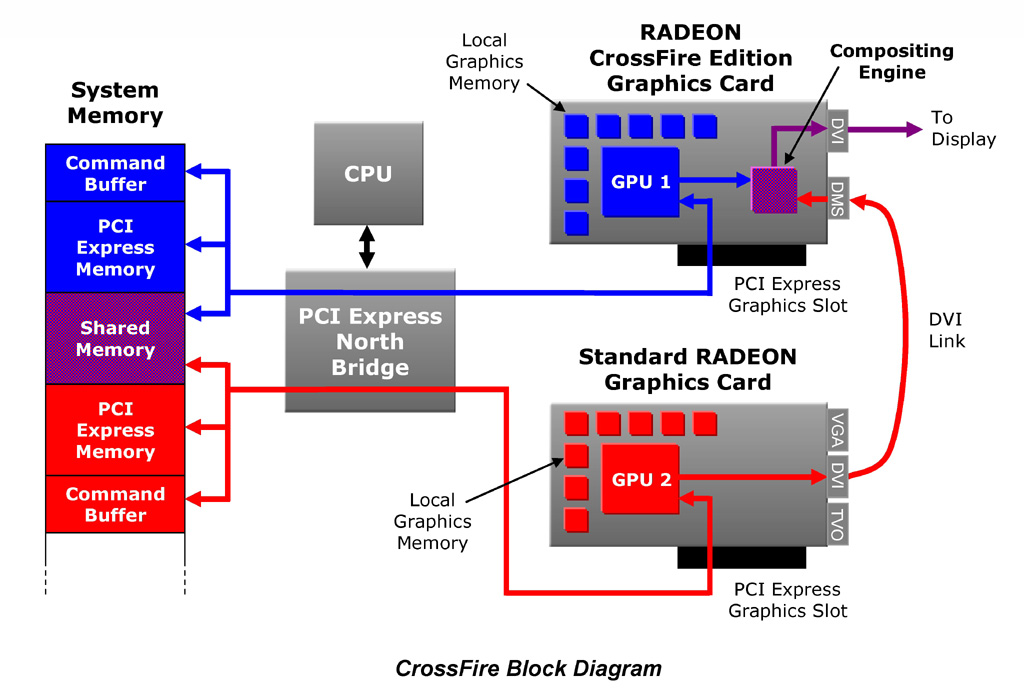
| CrossFireのブロックダイアグラム。最終的な映像合成と表示プロセスはレンダリングプロセスから切り離されたCompositing Engineで行われるので,このとき各グラフィックスチップに負荷はかからない |
まず,グラフィックスチップはメインメモリ側にそれぞれ専用のバッファを確保。このバッファはドライバ側から送られた描画コマンドをバッファリングしておく目的で使われる。それぞれのグラフィックスチップをどのように活用するかはドライバ側でマネージメントされ,その制御方法は後述するCrossFireの動作モードによって変わる。
メインメモリにはもう一つ,2個のグラフィックスチップで共有されるメモリ領域「Shared Memory」が設けられる。ここには2個のグラフィックスチップで共有すべきテクスチャなどが格納され,各グラフィックスチップの作業内容に依存性があった場合,グラフィックスチップはここからデータを取り出して,ローカルグラフィックスメモリへ転送する「整合性処理」を行う。
それぞれのGPUが自身のタスクを終了すると,マスターカード側上のCompositing Engineチップがマスターカード側,スレーブカード側,それぞれで作られた映像を合成して,最終的にディスプレイへ出力する。
Catalyst A.I.がCrossFire動作モードを動的に自動設定
デュアルグラフィックスチップ環境で最大のパフォーマンスを得るためには,レンダリング処理を2個のグラフィックスチップに対して効果的に割り振ることが必要不可欠になる。この点CrossFireには,三つ(+1)のレンダリングモードが用意されており,CrossFire対応版Catalystが持つ「Catalyst A.I.」という機能によって,アプリケーションごとに適切なレンダリングモードが選択されるようになっているという。
例えばNVIDIA SLIでは,NVIDIAの品質管理チームが3Dゲームを個別にテストし,NVIDIA SLIで最大パフォーマンスが得られるレンダリングモードをプロファイル化し,これをドライバ内に実装している。
これに対して CrossFireでは,Catalyst A.I.の熟成度を上げれば,プロファイルのない,まったく新しい3Dゲームに対しても最適なレンダリングモードが随時採択されるようになっているというのだ。
では,CrossFireのレンダリングモード動作の実態はどうなっているのだろうか。
Alternate Frame Renderingモード
〜最大パフォーマンスが得られる理想的な並列動作
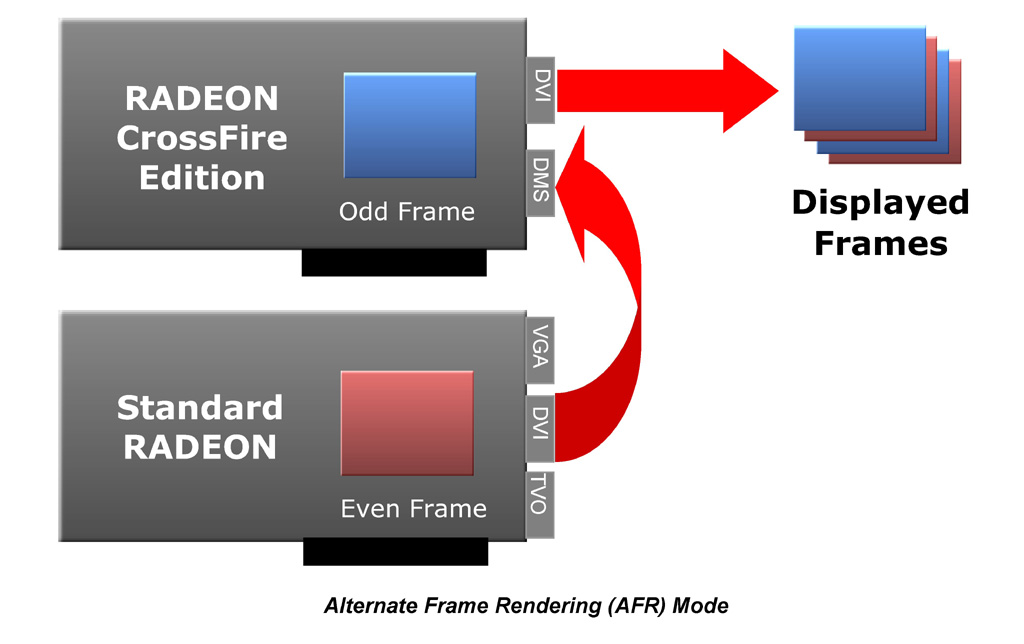
「Alternate Frame Rendering」(以下AFR)モードは,Alternate(交互に)という言葉が意味するとおり,2個のグラフィックスチップがそれぞれ交互にフレームをレンダリングする技法になる。
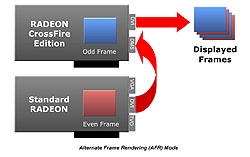 |
| AFRモードの動作概念図。クラシックな3Dゲームを高解像度で楽しみたい人に最適なモードといえる |
AFRモードの動作概念を示したものが右の図だ。2個あるグラフィックスチップのうち,一つめが奇数フレームのレンダリングを専念し,二つめが偶数フレームのレンダリングに専念する。
AFRモードでは,あるフレームを一つめのグラフィックスチップがレンダリング中であっても,次のフレームのレンダリング準備が完了できれば,一つめのグラフィックスチップのレンダリングの完了を待たずに,二つめのグラフィックスチップが次フレームのレンダリングに取りかかれる。処理がオーバーラップ出来た分だけ,高速化に貢献できるわけだ。
頂点パイプライン,ピクセルパイプラインがいずれも完全な並列動作を行えることになり,いわゆる理想的な並列動作になるので,もっとも高いパフォーマンスが得られるモードとなる。
ただしこれは「次フレームのレンダリングの準備」が滞りなく行われるのが前提条件。CPUのタスクが順調に動作できないとAFRモードの並列性が阻害されることになるのだ。すなわち,AFRモードではCPU性能が低いと効果を発揮できないことになる。
また,各フレームのレンダリング時に使用したテクスチャなどが次フレームと相関関係にあった場合は,Shared Memoryを介した整合性処理を挟まなければならず,この処理系の頻度や所要時間も並列動作の足を引っ張ることにもなる。
あるシーンを,次フレーム以降のレンダリング時に(例えば映り込みの反射マップとして)再利用する場合を考えてみよう。こうなると整合性処理が頻発することになり,2個のグラフィックスチップによる並列動作のオーバーラップ処理が理想の状態からかけ離れてきてしまう。
3Dゲームにおいて,こうしたケースが頻発すると感知したときには,CrossFireシステムは後述する2モードのほうへ切り換えを試みるわけだ。
総じて,そうした整合性処理があまり介入してこない,DirectX 8初期世代以前の3Dゲームとの相性がいいようだ。そうしたタイトルを高解像度で楽しみたいというケースに向いていると言えるだろうか。
SuperTilingモード
〜ピクセルレンダリングパイプラインのアクセラレーションに注力
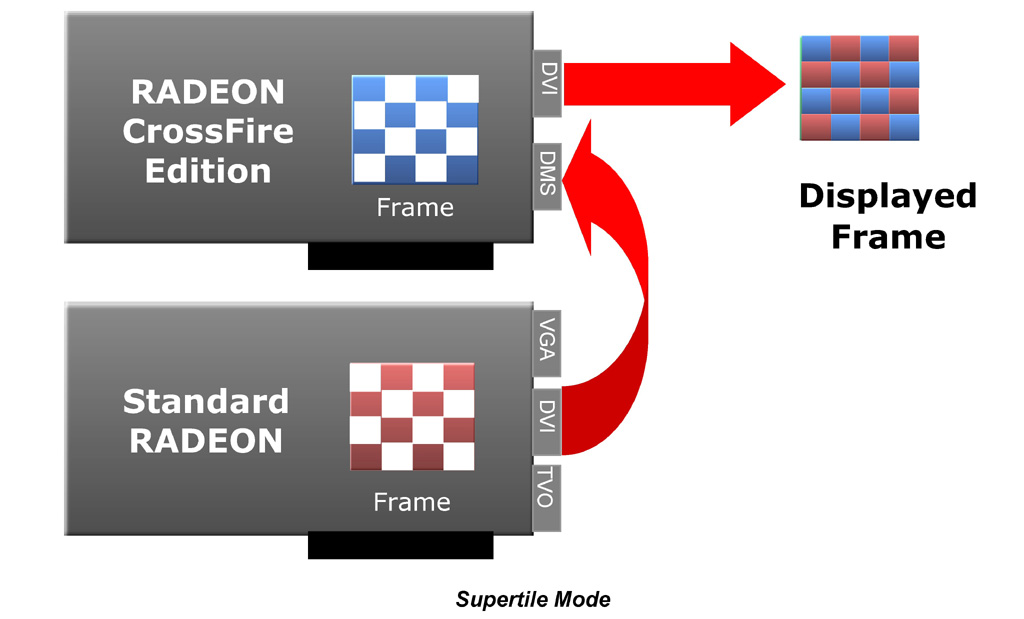
32×32ピクセルをレンダリングタスクの最小単位として,2個のグラフィックスチップを交互に切り換えてレンダリングを進めていくのが「SuperTiling」(以下ST)モードだ。ATIによれば,STモードは冒頭で紹介したsimFUSIONで用いられたテクノロジーを持ってきたものとのことだ。
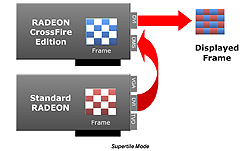 |
| SuperTilingモードの動作概念図。2個のグラフィックスチップがピクセルレンダリングパイプラインのアクセラレーションに専念する |
STモードでは,ピクセルのレンダリングフェーズを2個のグラフィックスチップで分散してレンダリングする格好となるが,その前段階の頂点パイプラインでは,2個のグラフィックスチップがまったく同じ頂点シェーダ処理を行うため,グラフィックスチップの並列動作という観点からはAFRモードに劣ることになる。
前述したように,シーンをテクスチャにレンダリング(Render To Texture)し,これを素材としてそれ以降のシーンのレンダリングに活用するような場合,AFRモードだとShared Memoryを介した整合性処理のオーバーヘッド(パフォーマンス低下)が発生してしまう。対してSTモードでは,2個のグラフィックスチップで同一フレームを手分けしてレンダリングしていく。2個のグラフィックスチップがそれぞれに直結するローカルグラフィックスメモリで処理していくため,フレーム間依存(=参照)データであってもShared Memoryをほとんど使わない。つまりAFRモードのようなオーバーヘッドが発生しないのだ。データの冗長性の観点からすると,二つのグラフィックスメモリ空間にまったく同じ内容のデータが格納されることになるので,無駄は無駄なのだが。
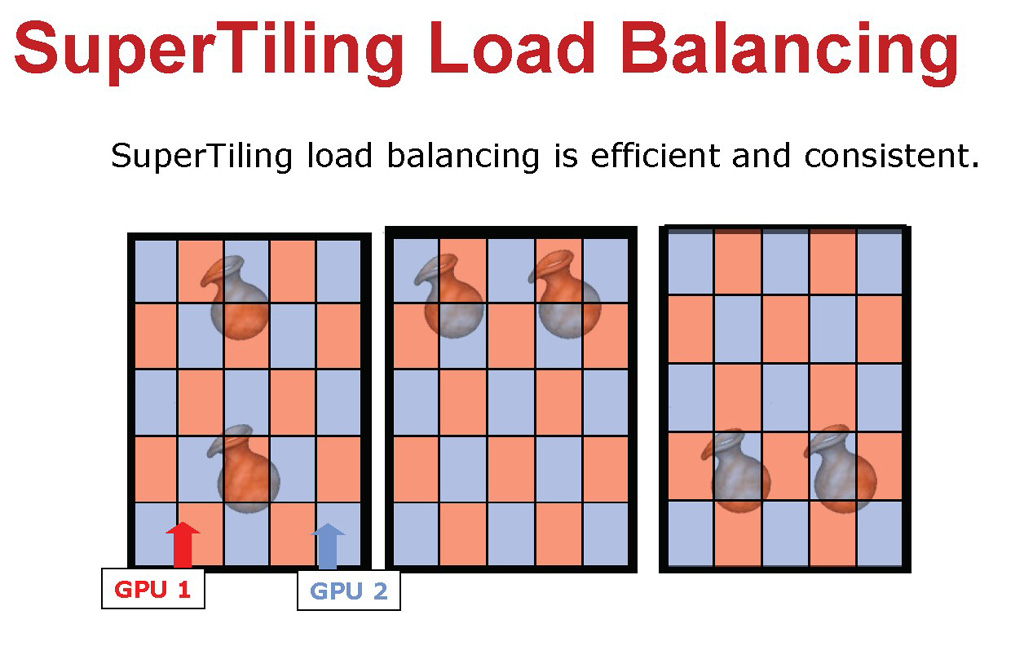
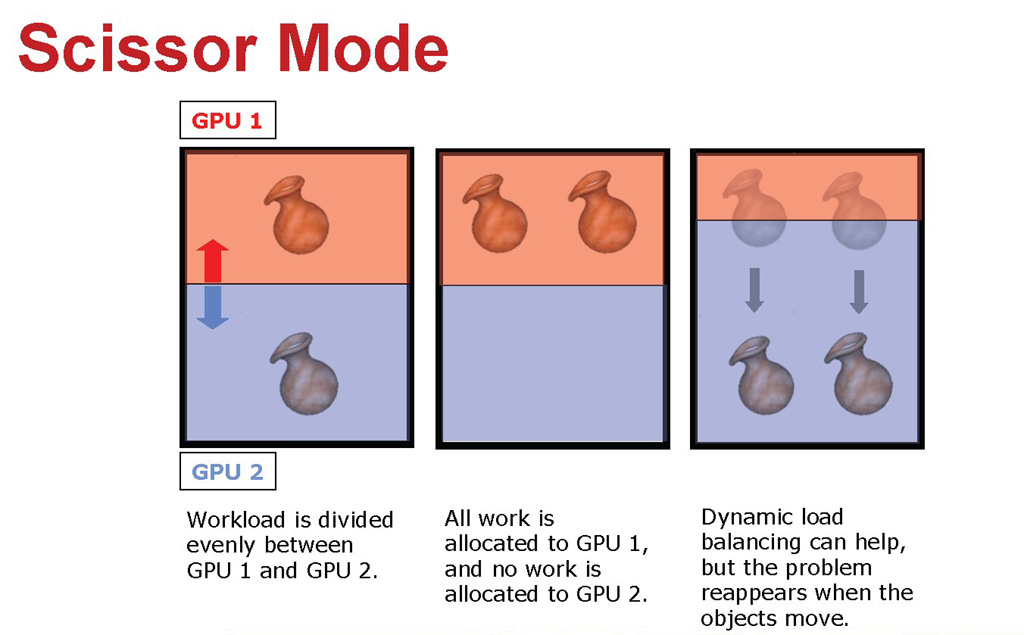
フレームを碁盤の目のように細分化してレンダリングすると,どういうメリットがあるのか。ATIは「シーン内に複雑な陰影処理を要するオブジェクトと軽めなオブジェクトが混在したり,あるいはそれらが画面内を縦横無尽に激しく移動したとしても,GPUを常にほぼ均等な負荷率で駆動できる」と説明する。
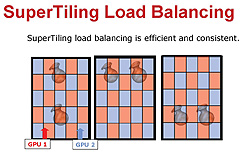 |
| STモードでは,たとえそのフレーム内にピクセル陰影処理の複雑性に偏りがあったとしても,2個のグラフィックスチップがそれぞれ32×32ピクセルの細かさの網を張っているようなものなので,その偏りも無効化,あるいは低減できる……という説明の図 |
右の図は「複雑な陰影処理を要する花瓶が移動した」という例を挙げて,STモードの動作を紹介しているものだ。2個のグラフィックスチップそれぞれの"網"が,ほぼ均等に花瓶に掛かっているのが分かるだろう。2個のグラフィックスチップの負荷は,適度な均等さを持って分散化されているというわけだ。
まとめると,STモードはいわばピクセルレンダリングパイプライン専用の2グラフィックスチップアクセラレーション技法ということになる。AFRモードで問題となりえる整合性問題やCPUボトルネックの問題も発生しないため「互換性と最大パフォーマンス」のトレードオフによって成り立っているモードと言えるだろうか。
CPU性能があまり高くなかったり,動的な反射マップや環境マップを用いた高度な映り込みが多用されたりする場合は,STモードの方がAFRモードよりパフォーマンスが高くなる可能性がある。
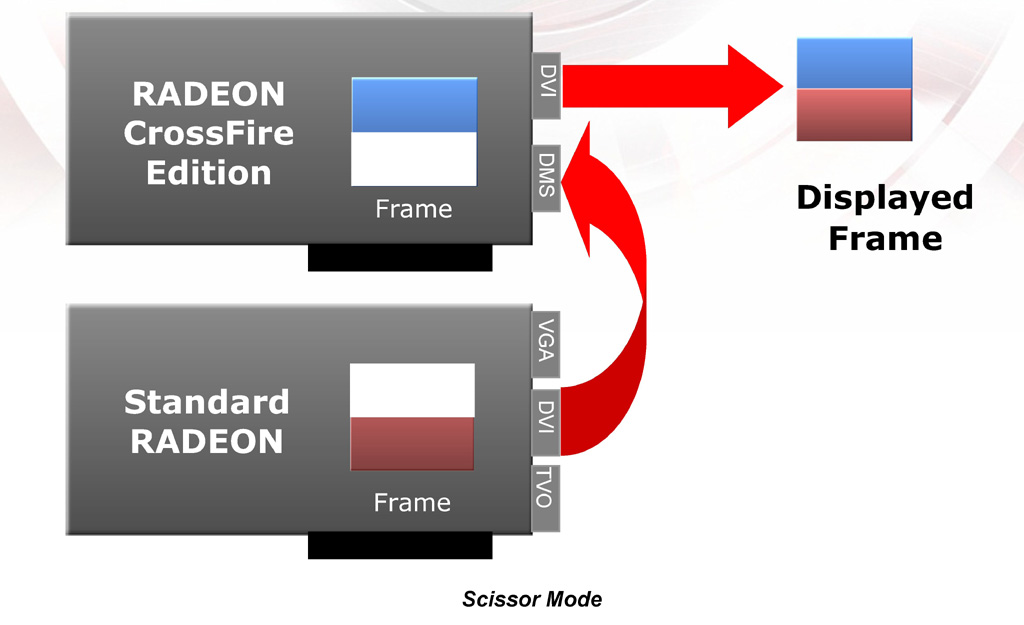
Scissorモード
〜ピクセルレンダリング高速化のもう一つの形
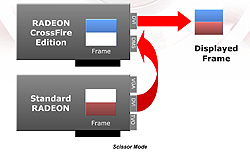 |
| Scissorモードの動作概念。1フレームを上下(または左右)から2個のグラフィックスチップでレンダリングする。NVIDIA SLIのSFRモードと考え方は同じ |
画面を上下あるいは左右に2分割して,それぞれを2個のグラフィックスチップでレンダリングするモードが「Scissor」(以下SC)モードだ。画面分割式の2グラフィックスチップレンダリングモードといえば,NVIDIA SLIの「Split Frame Rendering」(以下SFR)モードを思い浮かべる人も多いだろう。実際のところ,CrossFireのSCモードは,NVIDIA SLIのSFRモードとほぼ同一と考えていい。
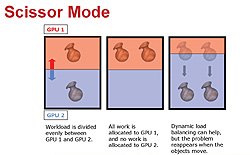 |
| SCモードにおける分割比率はレンダリングするフレーム内容に応じて動的に変化すると説明する図 |
CrossFireのSCモードでは,分割の方向は垂直,水平のいずれも可能で,どれが効果的かはシステム側で随時判断されるという。
分割時の比率は動的に変化するとのことだが,実際には,それぞれのGPUが上下から,あるいは左右から中央に向かってレンダリングを行っていく仕組みになっていると思われる。
STモードと同様,SCモードも実質的にはピクセルレンダリングパイプラインのみを2個のグラフィックスチップでレンダリングすることになるので,STモードと同様の利点と短所を持つ。
では,なぜSTモードだけでなくSCモードも追加したかというと「より確かな互換性を実現するため」で,かつ「ごく少ないケースにおいて,STモードよりもSCモードのほうが効果的な3Dアプリケーションの存在が確認できたため」とATIは説明している。
Super Anti-Aliasing
〜2個のグラフィックスチップで画質向上を目指すという新発想
以上,「三つ(+1)」の「三つ」を説明したわけだが,こう表記したのはもちろんわけがある。ここからは「+1」の部分を採りあげていきたい。
3Dゲームなどの3Dアプリケーションでは,1個のグラフィックスチップで60fps前後のフレームレートが出ていれば,それ以上のパフォーマンスが意味を持たない場合がある。あるいは,AI処理や物理エンジン処理が高度で,CPUがボトルネックとなり,結果としてフレームレートが頭打ちになってくる場合もある。最近の,技術的に先進的な3Dゲームタイトルでは,とくに後者の傾向が強いと思う。
こうした場合,2個のグラフィックスチップを利用しても,フレームレートの向上は望めない。ならば2個のグラフィックスチップを画質向上に使ってはどうか……というATIの提案が,CrossFireの「Super Anti-Aliasing」(以下SuperAA)モードである。一言で説明すると,グラフィックスチップ1個では実現不可能だった,高品質だが高負荷なアンチエイリアシング(以下AA)処理を,グラフィックスチップ2個でやってみようというものだ。
SuperAAの仕組みを理解するにはAA処理の基本的な理解が必要なため,まずは,こちらから見ていくことにしたい。
AA処理は一般に,CG特有の「ジャギー」と呼ばれるギザギザ感を低減する画像処理という認識がなされている。しかし本質的には,1ピクセルに多くの色情報を詰め込むことであり,結果としてジャギーが低減しているに過ぎない。つまりAA処理の高品位化は,1ピクセルにいかに多くの色情報を詰め込むかということに相当する。
そして,これを実現するためには,そのピクセルを構成するサブピクセルを複数レンダリングし,これらを特定の演算を行って1ピクセルにまとめ上げる処理系が必要になる。サブピクセルとは,ピクセルよりも小さい単位の画素の概念。つまり,複数のサブピクセルによって1ピクセルが構成されているというイメージだ。
なお,サブピクセルのレンダリングとは,考え方を変えれば,目標レンダリング解像度よりも数段階高い解像度で映像をレンダリングすることとほぼ同義になる。
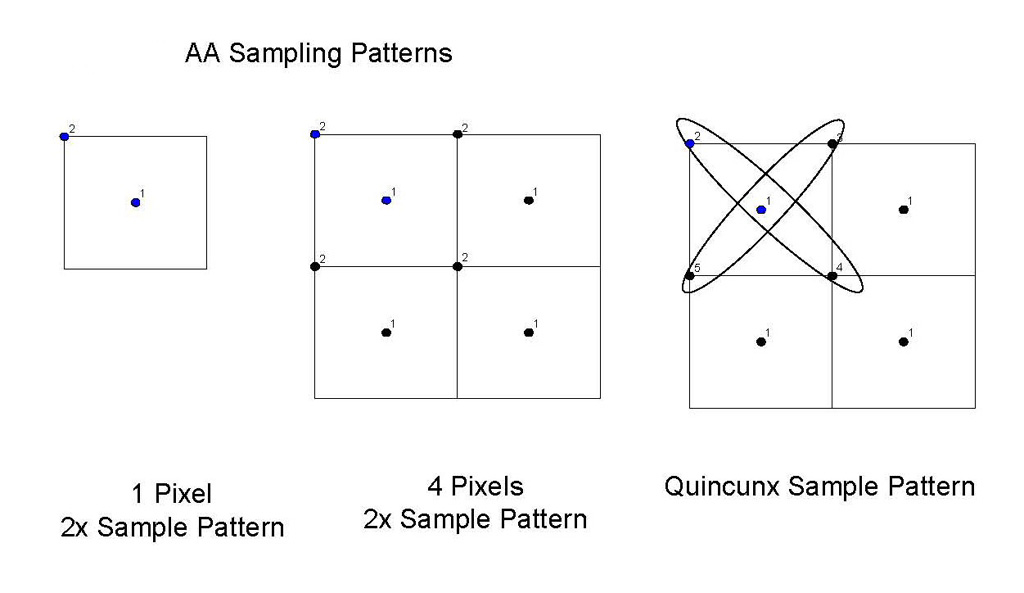
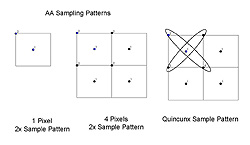 |
 |
上:例としてGeForce 3のAAサンプリングパターンを挙げてみた。図内の□が最終的に得たいピクセルだ。各ピクセルでは点1,2の位置のサブピクセルをレンダリングしていく。これを四つ並べたのが真ん中の図である。このとき,隣接するピクセルのサブピクセル点1,2もAA処理に適用してやれば,より高品位な映像が得られることになる
下:実質的には2x相当のサブピクセルレンダリングしか行わないが,その局所性を利用して周囲のサブピクセルを用いて擬似的に数段階上(ここでは5x相当)のAA映像を得る。これがGeForce 3に搭載された「Quincunx AA」だったわけだ(資料提供:NVIDIA) |
実際,高解像度映像そのものをレンダリングして,それを目的の解像度に縮小変換するような処理系でAA処理を実現する技法があり,これは「Super Sampling Anti-Aliasing」(以下SSAA)と呼ばれる。Voodoo 5のAA処理にはSSAAが採用されていたが,SSAAは考え方が単純なだけに,非常に高負荷でパフォーマンスに与える影響が大きいため,最近の主流技法にはなっていない。ちなみに,AA処理の品質パラメータにはお馴染みの「2x/4x/6x/8x…」があるが,これは,その数値個数分だけサブピクセルをレンダリングしてAA処理を適用する,という意味だ。
では主流はというと,SSAAの改良型ともいうべき,「Multi-Sample Anti-Aliasing」(以下MSAA)になっている。MSAAでは,実際のピクセル陰影処理自体は1個のサブピクセル分しか行わず,大胆にもこの結果を,他のサブピクセルの陰影処理結果としてしまう。つまり,MSAAではサブピクセルを全部同色としてしまうのだ。SSAAではアンチエイリアスの2xとか4xとかいったサブピクセル個数分だけ陰影処理(ピクセルシェーダ処理)しなければいけなかったのが,1個で済むわけだから,高速になる。
「そんな大胆な手抜き処理でAA処理になるのか」という疑問を持つ人もいるだろう。結論から言うと,物理量の計算としては大間違い。しかし,「ジャギーを低減させる」というAA処理の目的においては及第点が与えられてしまうのである。
MSAAでは,サブピクセルの色の値は同じということにしてしまうが,サブピクセルの位置のZ処理(深度情報処理)は,SSAA同様に正しく計算している。そのサブピクセルが,他のポリゴン(ピクセル)によって遮蔽されていないかをチェックして,画面に描かれるべきものなのか否かだけは,ちゃんと診断処理を行っているのだ。
ジャギーの出やすいポリゴンのエッジ付近,要するに深度情報の境界付近では,サブピクセルが描かれるべきと判断されたり,あるいは遮蔽されているから描かるべきではないと判断されたりして,総合処理結果としての最終ピクセル色はうまい具合に薄められることになる。
SSAAは本来のAA処理系として,「多くの色情報を1ピクセルに詰め込むこと」を実践していたが,MSAAはむしろ「ジャギーを低減させる」ことだけに着眼した手法といえるだろう。
ここまで理解すると,SuperAAはずいぶん分かりやすくなる。
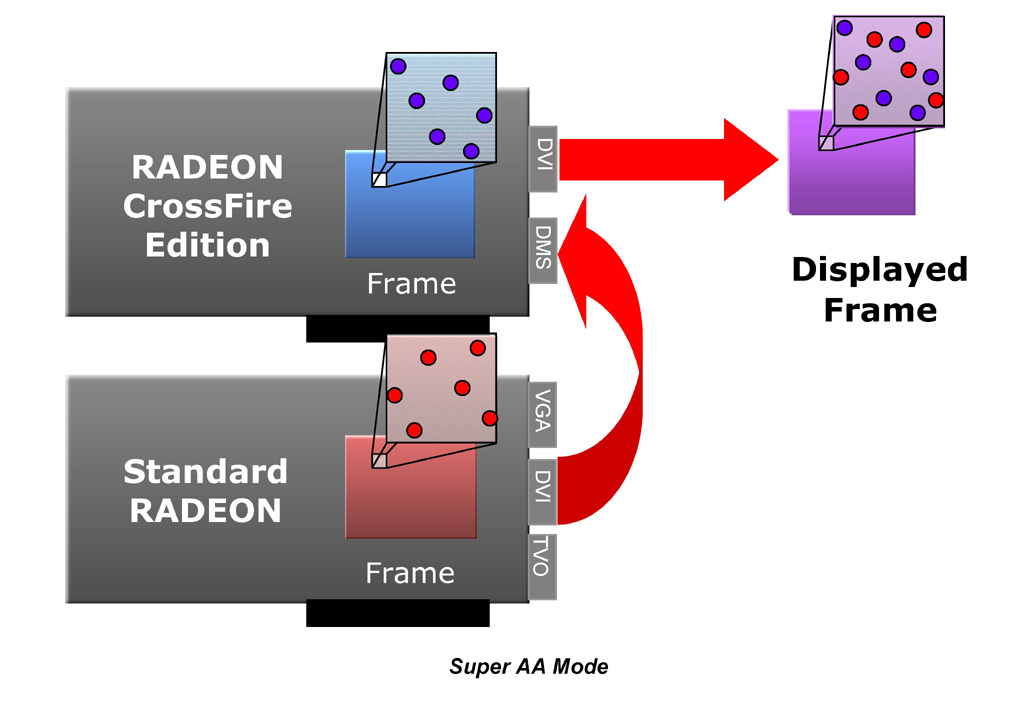
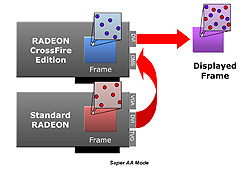 |
| SuperAAの動作概念。フレームレートはとりあえず据え置きで,2個のグラフィックスチップが高画質フレームのレンダリングに注力するのがSuperAAのコンセプトだ |
SuperAAでは,2個のグラフィックスチップが同一のフレームを同時にレンダリングするのだが,そのとき,異なる位置のサンプリング(≒サブピクセルレンダリング)を行い,これを一つに取りまとめてAA処理する。
たとえば,1グラフィックスチップで6x MSAA処理を適用してフレーム落ちしない3Dゲームがあれば,CrossFireで各6x,合計12x MSAA処理の映像を得ても,理論上はフレーム落ちせずにプレイできるわけだ。
2個のグラフィックスチップでレンダリングしているフレーム自体は同一シーンなので,パフォーマンス的には全く向上しないのはいうまでもない。画質だけ向上するのである。
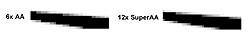 |
| ATIによる6x AAと12x SuperAAとの画質比較。ギザギザが目立ちやすい水平,垂直に近い線もこのように滑らかになる |
実は,ここまでは「SuperAAの機能その1」といったところだ。SuperAAには,もう一つの技術が用意されている。
MSAA手法では,いくらサンプリングポイントを増やしたところで,得られる画質が頭打ちになってしまう場合がある。これはAA処理のサンプリングパターンに規則性があったり,局所性の積極利用や適応型AA処理の弊害だったり,要因はさまざまだ。
SuperAAではこの問題に対処するため,2個のグラフィックスチップで同一フレームをMSAA処理付きレンダリングするとき,レンダリングの視点をグラフィックスチップごとに画面座標系レベルで半ピクセル分ずらして行うアイデアを盛り込んでいる。これには,サンプリングパターンの規則性を散らす効果,さらには解像度不足から来る情報の欠落を補填する働きがあるという。
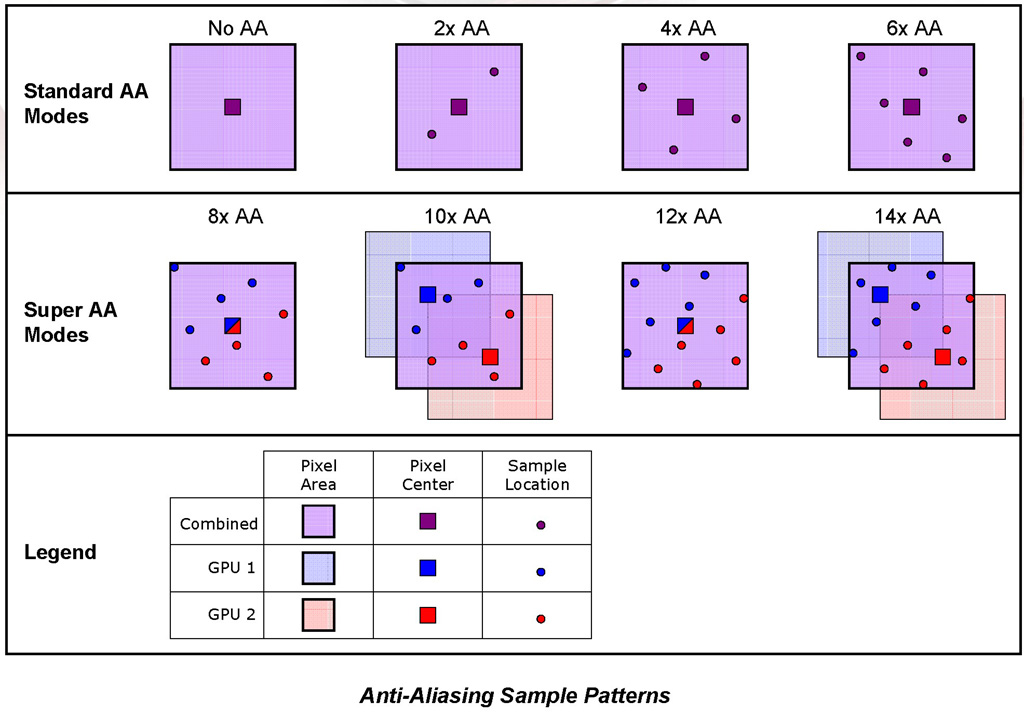
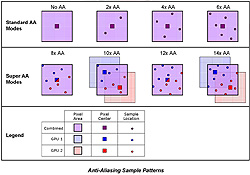 |  |
| SuperAAのサンプリングパターンの詳細(図の中段参照)。8x AA,12x AAは,通常のサンプリングポイント数を2倍にしたMSAAだ。すぐ上で触れた半ピクセル視点ずらしテクニック付きSuperAAは,10x AA,14x AAで利用されている |
ATIによる,6x AAと半ピクセル視点ずらしテクニック付き14x SuperAAとの画質比較。6x AAではピクセルの連続性が立ち消えてしまうような細い線の表現でも,14x SuperAAではしっかりと描画されているのが分かる |
CrossFireとNVIDIA SLI,どちらを選ぶべきか。これは,チップセット選択肢の制限や予算,メーカーの好き嫌いの問題を別にすると,どちらのコンセプトに共感できるかが決め手となるだろう。
ただ,一つだけ注意が必要なのは,ATIが強く訴える「アップグレードの柔軟性」というアピールポイントについてである。CrossFireでは,同世代同アーキテクチャのグラフィックスチップなら,型式番が異なっていても組み合わせられるというのがATIの売り口上。要するに,Radeon X800シリーズとRadeon X850シリーズでCrossFire動作が可能というわけだ。しかし,現実問題として,これはあまりユーザーメリットにならない。
例えば今,Radeon X800 XL搭載のグラフィックスカードを利用しているユーザーがいたとする。このとき,Compositing Engine付きRadeon X850 XTカードと同Radeon X800 XLカードのどちらを購入しても確かにCrossFireで動作するが,得られるパフォーマンスは,Radeon X800 XL×2相当になる。つまり,この状況でわざわざRadeon X850 XTを選ぶ意味はないのだ。
組み合わせの自由度はあっても,現実的なアップグレードパスは1本。その意味ではNVIDIA SLIと変わらないのである。
しかし,CrossFireには理論値2倍の性能向上だけでなく,NVIDIA SLIにはないSuperAAという武器がある。固定画素系で画面解像度が決めうちとなるプラズマディスプレイや液晶ディスプレイにおいて,フレームレートを落とさずにより高品位な映像を得る手段としては,非常に価値の高いものだと筆者は思う。これはハイエンド3Dゲームファンに対して相応の強い訴求力を発揮するだろう。(トライゼット 西川善司)
|