|

ATI Technologies(以下ATI)は,日本時間の2005年10月5日22時,新世代グラフィックスチップ「Radeon X1000」シリーズを発表した。今回は,去る9月21日にサンフランシスコで行われたプレス向けの事前説明会の内容を中心に,この新シリーズについて詳細を明らかにしていきたいと思う。
ハイエンドからバリューまで2か月以内に揃う
Radeon X1000
Radeon X1000は,「R500」という開発コードネームで知られていた製品群だ。一般向けグラフィックスチップとしては史上初めて90nmプロセスで製造され,プログラマブルシェーダ3.0(Shader Model 3.0,以下SM3.0)への対応,「Avivo Technology」の採用などが特徴となる。同シリーズは3セグメントに分かれ,その対応関係は以下のとおり。
ハイエンド:Radeon X1800シリーズ(開発コードネームR520)
メインストリーム:Radeon X1600シリーズ(開発コードネームRV530)
バリュー:Radeon X1300シリーズ(開発コードネームRV515)
 新型Radeonを発表する,ATIの副社長兼デスクトップビジネスユニット ゼネラルマネージャのRich Heye氏
"X900"をスキップしての登場となるRadeon X1000シリーズが興味深いのは,ハイエンドからバリューまでのラインナップが同時に発表されたこと。そして,それが向こう2か月以内にすべてリリースされると明言されたことだ。
最新世代という意味では,NVIDIAのGeForce 7800シリーズがすでに販売されているが,メインストリーム以下の市場向けには未だGeForce 6シリーズが継続販売されている状態。ATIは,Radeon X1000シリーズで一気に全レンジをカバーすることで,GeForceよりも新しいというイメージを前面に押し出していく戦略をとるわけである。
ちなみに,新製品登場のたびに噂される新ブランド名は,今回も見送られた。これについてATIは「向こう(=NVIDIA)が『GeForce』で勝負している以上,ブランディング戦略的に『Radeon』を使い続けるのが得策と判断した」と説明している。
 |
 |
Radeon X1000シリーズを全面展開し,SM3.0対応グラフィックスチップでNVIDIAより一世代新しいことをアピール |
Radeon X1000シリーズ向けとして公開されたRubyの新作デモから。このデモ,タイトルは「Assassin」(暗殺者)という。GeForce 7800 GTXの暗殺に送り込まれたのがRadeon X1000シリーズ!? |
統合型シェーダアーキテクチャは未採用
〜Xbox 360 GPUとはまったく異なる新設計
2005年末発売予定となっているMicrosoftの次世代ゲーム機「Xbox 360」では,ピクセルシェーディングユニット(Pixel Shading Unit,ピクセルプロセッサ/ピクセル演算器ともいう。以下ピクセルシェーダ)と頂点シェーディングユニット(Vertex Shading Unit,頂点プロセッサ/頂点演算器ともいう。以下頂点シェーダ)を統合したユニファイドシェーダ(Unified Shader)アーキテクチャが採用される。「Xbox 360 GPU」と呼ばれる,このATI製グラフィックスチップは,負荷に応じて処理を両シェーダへ自動的に振り分ける構造になっているのだ。
これはDirectX 10(Windows Graphics Foundation 2.0)世代のグラフィックスチップアーキテクチャといわれているが,どちらもATIが開発する以上,新世代Radeonもこれを踏襲するものと思われていた。ところが,蓋を開けてみればこの予想は外れていた,というわけである。
 ATI ディスクリートグラフィックスエンジニアリング部のBob Drebin氏は「1世代先がDirectX 10とすれば,Radeon 1000シリーズよりも半歩先行したものが,Xbox 360 GPUといえるだろう」という
詳しくは後述するが,Radeon X1000シリーズの基本的なパイプライン構造はRadeon X800シリーズと変わらない。ピクセル&頂点シェーダの数は固定されており,それぞれがピクセルパイプラインと頂点パイプラインを形成するイメージになる。このため,DirectX 10で採用される予定の,ポリゴン分割テッセレータ機構や,ジオメトリシェーダもない。
誤解を恐れずにいえば,Radeon X1000シリーズは,Radeon X800シリーズをSM3.0仕様に変更し,新世代技術で再構成したものなのだ。
SM3.0対応もVTFには対応せず
NVIDIAから約18か月遅れでSM3.0世代への移行を果たしたATIだが,Radeon X1000シリーズのシェーダ命令セットはGeForce 6/7シリーズとほぼ同等。SM2.0世代の不毛な拡張合戦で叫び合った「+」というキーワードは,今回は用いられていない。SM3.0に関しては,ATIはNVIDIAと足並みを揃えた格好だ。
ところで,"ほぼ"という言葉を用いたのにはワケがある。
SM3.0では頂点シェーダにテクスチャアクセス機能を与える「Vertex Texture Fetching」(以下VTF)と呼ばれる新規機能が追加されていた。VTFについてはGeForce 7800 GTXについて解説した記事に詳しいので,ここでは深く触れないが,例えば3Dモデルを粘土細工のように変形(モーフィング)させたり,あるいはボーン・スキニング用の行列データを入れておく大容量定数領域として活用したりと,VTFはSM3.0のウリのひとつだった。
だが,Radeon X1000シリーズはこのVTFに対応しないのである。
 Raja Koduri氏。「現状では,頂点バッファレンダリング(Render to Vertex Array)を利用したほうが使い勝手もパフォーマンスもVTFより上だ」
ATIのシニアアーキテクトであるRaja Koduri氏は「この18か月間,3DアプリケーションでVTFの積極利用が行われた実績がない。貴重なトランジスタ予算を割いてまで,この使われないSM3.0機能を実装するのを我々は避けた」と説明する。
確かにこの主張にも納得できるところはあり,実際,NVIDIAも,GeForce 6/7シリーズ用に見栄えのするVTFデモを用意できていない(デベロッパ向けサイトにある実験プログラムは除く)。
しかし,互いの弱点をつつき合うATI対NVIDIAの戦いにおいては,これは隙になるかもしれない。NVIDIAがこの部分を「SM3.0"−"」だと指摘してこない保証はないのだ。
なお,SM3.0のもう一つの機能であるジオメトリインスタンシング(Geometry Instancing:同一3Dモデルの反復描画を効率よく描画するためのジオメトリ情報伝送手法)は,Radeon X1000シリーズでハードウェアレベルの対応が行われているという。
 |
 |
VTFのデモのサンプルはNVIDIAのSDKに含まれている。この画面は,そのSDKに含まれるGeForce 6/7シリーズ用のVTF実験デモ。ピクセルシェーダでテクスチャに対して波動シミュレーションを行い,この結果を元にVTFで頂点ベースの水面を変位させている。このデモはRadeon X1000シリーズだと動作しない |
Radeon X1000シリーズの頂点シェーダブロック図。実際,基本的な構成はRadeon X850からあまり変わっていない |
マルチスレッドによるレイテンシ隠蔽と
動的分岐の高効率実行
ここからは,Radeon X1000シリーズ全体に共通する特徴を解説していくことにしよう。
まず処理系だが,Radeon X1000シリーズでは4×4の16ピクセルのひとかたまりを「1スレッド」と捉え,これを複数のピクセルシェーダでスレッド切り替えを行いながら処理していくマルチスレッド方式になっている。
1スレッドが4×4ピクセルなのは,実際の3Dアプリケーションで最も有効だったという実験結果によるものだそうだ。「スレッドの割り当てや切り替えはDispatch Processorが行う。スレッド切り替えのタイミングは,当該スレッドのテクスチャアクセスの直後だ」(Drebin氏)。例えば,Radeon X1800シリーズなら512内部スレッド(512×4×4=8192ピクセル)の処理に対応する。
テクスチャアクセス(=メモリアクセス)は算術的な処理と比較すると非常に遅く,実質的なテクスチャアクセスが完了するまでには100サイクル以上のレイテンシが発生する。その間,ピクセルシェーダがただぼーっとしているのではもったいない。そこで,待ち時間が生じたら別のスレッドに切り換えて実行し,算術的な処理を進める。そのスレッドでもテクスチャアクセスが発生したら,また別のスレッドに切り換える。
 Radeon X1800シリーズのブロック図。中央の「Ultra-Threading Dispatch Processor」が,スレッド切り替えを統括しているユニットである
この流れをシステマティックに処理すれば,シェーダの演算処理とテクスチャ処理のオーバーラップ実行が可能になり,理論的にはテクスチャアクセスのレイテンシを隠蔽できることになるというわけだ。
ATIはこのアーキテクチャを「Ultra-Threading Architecture」と呼び,その先進性を訴える。ただし,こうしたグラフィックスチップ内マルチスレッド技術は,名前がないだけでNVIDIAもGeForce 6シリーズから実装している点は補足しておこう。
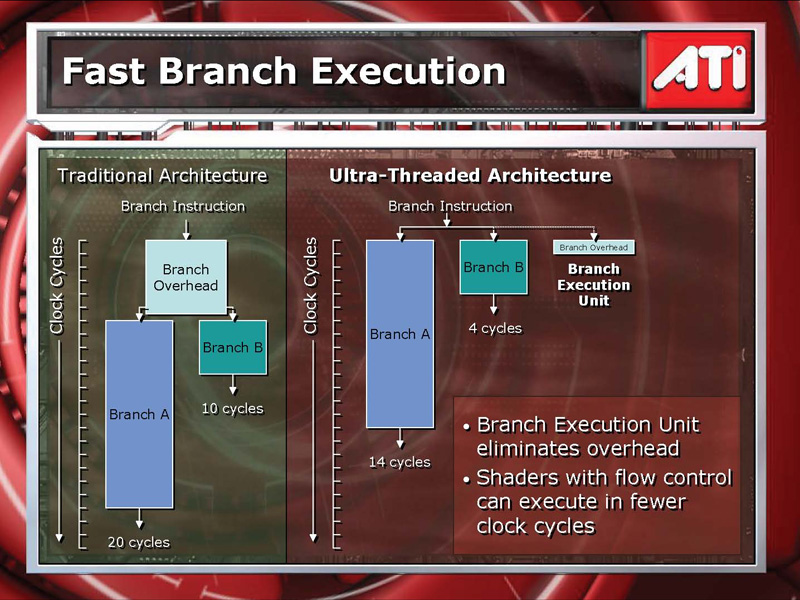
 左が既存のRadeon,右がRadeon X1000シリーズの分岐実行の流れ。投機実行によって,分岐のオーバーヘッドが大幅に減少するというのがATIの主張だ
ただ,後発のSM3.0対応グラフィックスチップらしく,GeForceにはない特徴もある。
それは,ピクセルシェーダの動的分岐の投機実行だ。Radeon X1000シリーズにはハードウェアの分岐命令実行ユニット(Branch Execution Unit)が搭載されており,動的分岐に遭遇すると分岐条件の吟味を始める。このとき,条件成立/不成立後のいずれの分岐先の命令も同時に開始できる。分岐条件の吟味が完了すると正しい分岐先の実行を継続し,外れたほうの実行は捨てるという,完全なる投機実行が可能なのである※。
これをもってATIは「Radeon X1000シリーズでは,動的分岐を活用したピクセルシェーダプログラムのパフォーマンスがついに実用レベルとなった」と断言している。GeForce 6/7シリーズに対する大きなアドバンテージというわけである。
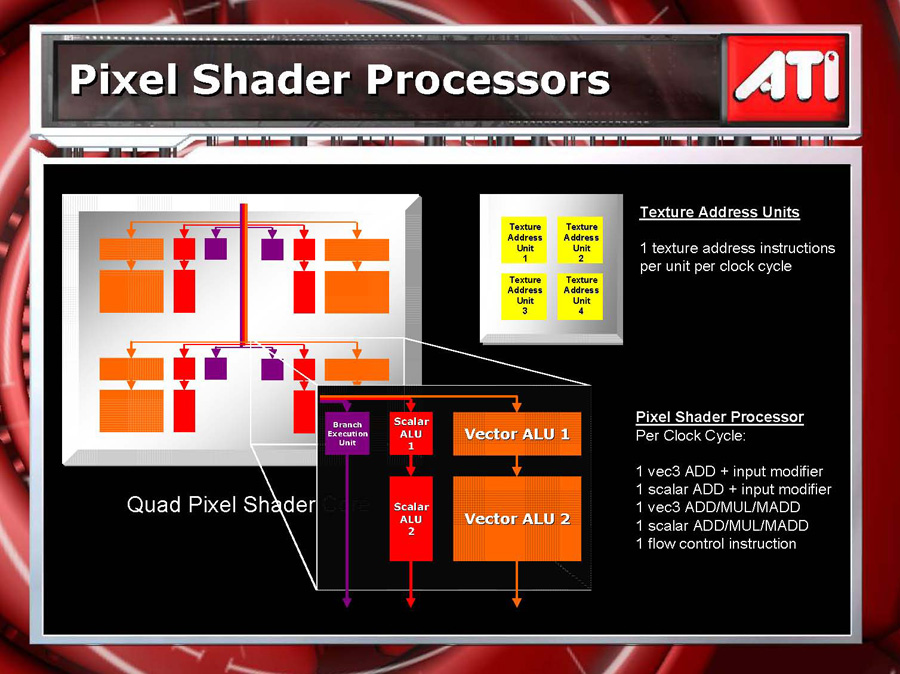
 ピクセルシェーダ1基あたりのブロック図。各ピクセルシェーダでは分岐命令,スカラ命令,ベクトル命令を同時に実行できる ※グラフィックスチップが分岐命令に投機実行を導入したというのは凄いことだが,実際には制限がある。二つの分岐先は片方がScalar ALU関連命令,もう片方がVector ALU関連命令でなくてはならないのだ。つまり,Radeon X1000シリーズの投機実行を効果的に利用するためには,コンパイラでの最適化が不可欠になる。
ピクセル内部演算精度がフル32ビットに
AA性能,3Dcも強化
 Radeon X1000のHDRレンダリングにおけるポテンシャルが,GeForce 6/7シリーズと同等以上に高められたことを示唆するスライド
Radeon 9700以降,Radeonが持つピクセルシェーダの内部演算精度は24ビット浮動小数点(FP24)だったのを覚えている人も多いだろう。Radeon X1000シリーズでは,ようやくフル32ビット浮動小数点(FP32)アーキテクチャとなった。
GeForce FXで早々に移行を果たしたNVIDIAに遅れること3年ではあるが,これにより,既存のRadeonでは不可能だったFP16バッファのブレンディングやFP16テクスチャのフィルタリングに対応。さらには,GeForceが未だサポートしていない,HDR(High Dynamic Range)バッファに対するアンチエイリアス処理も可能になっている。
 HDRバッファはFP16,FP32だけでなく,Int16やInt10もサポートされる。余談だが,A2R10G10B10はMatrox GraphicsのPerheliaもサポートしている またRadeon X1000シリーズでは,いわゆる「A2R10G10B10」(α2ビットRGB各10ビットの計32ビット)のHDR整数フォーマットに対応した。αチャネルのビット数は少なくなるものの,通常の「A8R8G8B8」(α8ビット各RGB8ビット)フォーマットよりもRGB各チャネルは4倍のダイナミックレンジを持つことになる。しかも,バス幅は通常と同じ32ビット。ATIいわく「3Dゲーム向けのHDRフォーマットとしては最適である」とのことだ。
Radeon X1000シリーズでは,アンチエイリアシングにも新たな試みがなされている。
NVIDIAがGeForce 7シリーズで「Transparency Anti-Aliasing」という,半透明要素を持つバッファに対して品質の高いアンチエイリアス処理を適用できる機能を実装したのは以前述べた。これへの対抗措置として,ATIがRadeon X1000シリーズに実装してきたのが「Adaptive Anti-Aliasing」(適応型アンチエイリアシング)である。
アンチエイリアシングは,基本的に3Dエンジン側の設定によって,「Super Sampling Anti-Aliasing」(いわゆるオーバーサンプリングとほぼ同義。以下SSAA)か「Multi-Sample Anti-Aliasing」(以下MSAA)のどちらを適用するかが決まっている。各アンチエイリアシング技法についてはCrossFireのSuperAAを解説した記事に詳しいので,簡単に述べるに留めるが,SSAAは多くのサブピクセルを実際にレンダリングしてサンプリングするのに対し,MSAAは1ピクセルだけをレンダリングし,その結果をほかのサブピクセルにコピーして輪郭にだけ処理を行う。このため,MSAAよりもSSAAのほうが高品位だが,処理速度的には不利になる。
そこで,MSAAを適用するような指定が3Dエンジンによって行われていても,MSAAで画質の落ち込みが目立ちやすい半透明の部分に対しては選択的にSSAAを適用。これがAdaptive Anti-Aliasingである。Adaptive Anti-Aliasingを有効にしたときは,基本的に高速処理が可能なMSAAを利用しつつ,画質への悪影響が大きいところではピンポイントでSSAAを適用するというわけだ。
右のスライドは,MSAAとAdaptive Anti-Aliasingを比較したものだが,その差は歴然といえよう。
 3Dcと3Dc+の両方はDirectX 10に標準仕様として盛り込まれる見通しである
また,Radeon X1000シリーズでは「3Dc Technoology」(以下3Dc)が強化されているのも特徴だ。3Dcは,Radeon X800シリーズで初めて実装された"2要素テクスチャの圧縮(支援)機能"。Radeon X1000シリーズの3Dc+では,3Dcの機能に加えて,3Dcのアルゴリズムを1要素テクスチャに対しても適用できるようになっている。
この1要素テクスチャ圧縮機能を活用すれば,浮動小数点テクスチャの圧縮も可能だとATIはいう。浮動小数点は簡略表記すると「(仮数)×2(指数)」という形になるが,浮動小数点テクスチャに格納されている浮動小数点実数データのその指数部と仮数部のそれぞれを,2枚の1要素テクスチャに分けてから3Dc+で圧縮してやるのだ。
もちろん,読み出し時にはこの2枚の3Dc+テクスチャから値を読み出して,それからプログラマブルシェーダで浮動小数点を再構成する必要があるのだが。
Avivo Technology標準搭載
新開発ディスプレイエンジンの詳細仕様が判明
このほか,3Dグラフィックスとは直接の関係はないものの,Avivo Technology(以下Avivo)をシリーズ全モデルで採用したのもRadeon X1000シリーズの特徴だ。
|