GeForce 6800 Ultra(以下6800 Ultra)と比較しながら,GeForce 7800 GTX(以下7800 GTX)の正体を明らかにする話の後編。前編(「こちら」)を踏まえて,続く部分を解説していくことにしよう。
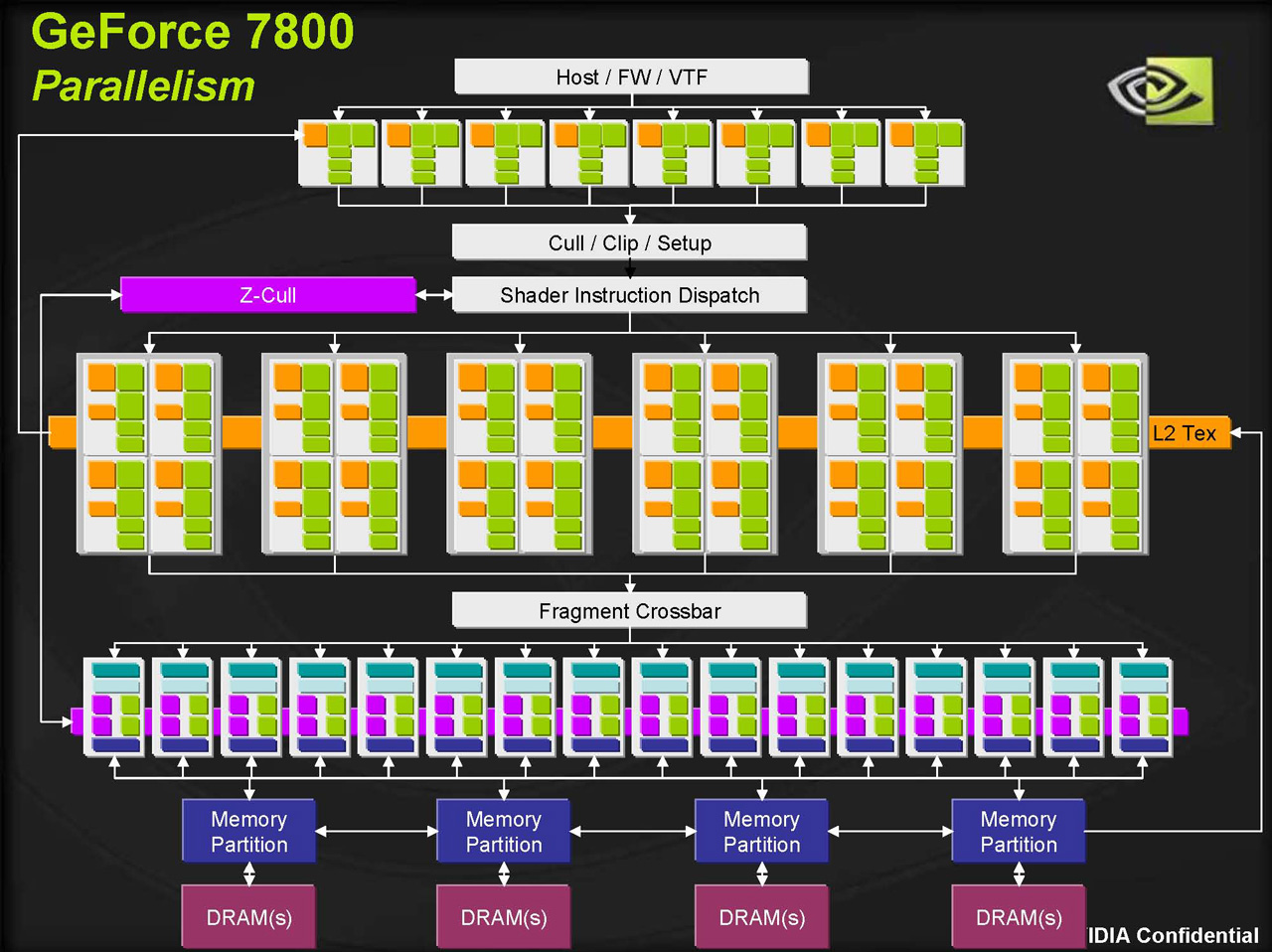
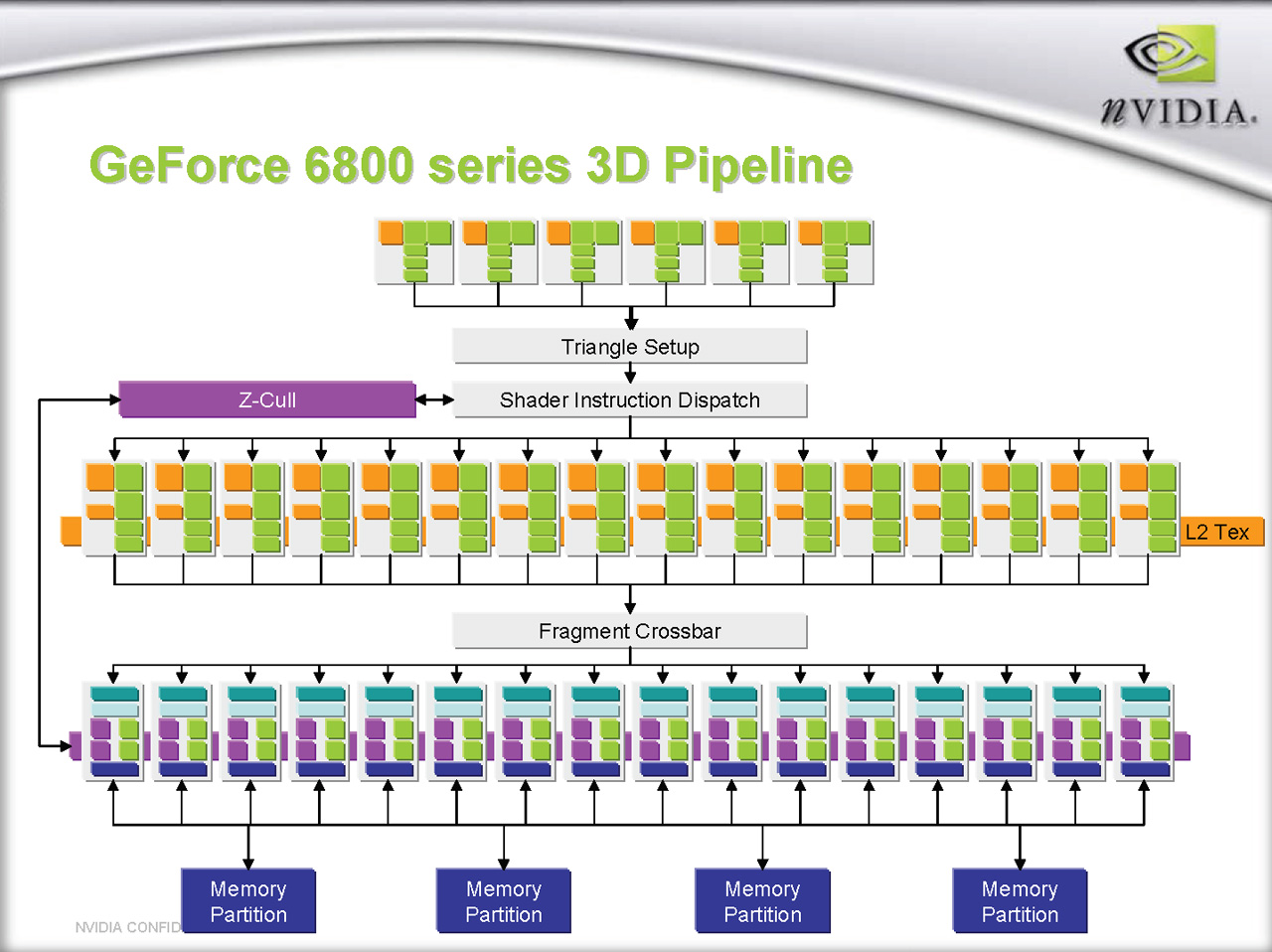
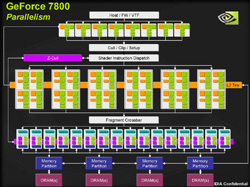
前編でも述べたように,6800 Ultraで16本だったピクセルパイプラインは7800 GTXで8本増の24本となった。コアアーキテクチャのブロック図を以下に示すので,改めて確認しておいてほしい。
 |
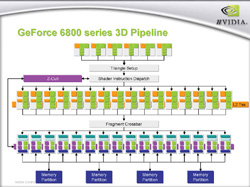 |
| 7800 GTXのブロック図(左)と6800 Ultraのブロック図(右) |
さて,ピクセルレンダリングパイプライン(以下ピクセルパイプライン)が16本から24本になった。これはつまり,単純計算で,同クロックで動作した場合に,ピクセルシェーダユニットの並列度は1.5倍に高められたことになる。
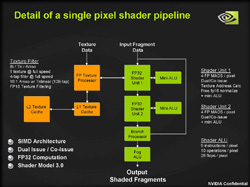
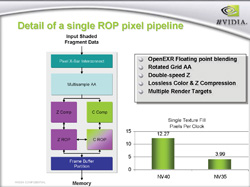
7800 GTXと6800 Ultraが持つピクセルパイプラインのブロック図は以下のとおりだ。
 |
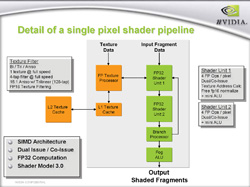 |
| 左から順に,7800 GTX,6800 Ultraのピクセルパイプラインブロック図。一見,7800 GTXにだけ「Mini-ALU」(ALU:Arithmetic and Logical Unit。算術演算や論理演算を行うユニットのこと)があって,これが最大の違いのように感じられるが,実際には6800 Ultraにも用意されているの要注意。ちなみにMini-ALUは,前編,頂点シェーダユニットのところで解説している「FP32 Scalar Unit」と同等のものと考えればいい |
7800 GTX,6800 Ultraも,FP32ベクトル演算器「FP32 Shader Unit」を2基,そして浮動小数点テクスチャ演算器「FP Texture Processor」を1基持つ点では変わらない。FP32ベクトル演算器は,128ビットのSIMD型ベクトル演算器であり,最大で四要素(αRGB)FP32ベクトル(w,x,y,z)同士の演算をこなすことができる。
では何が違うのか。6800 Ultraでは「FP32 Shader Unit 1」では,四要素FP32ベクトルの基本演算のみが可能で,FP32ベクトルの積和演算は「FP32 Shader Unit 2」でしか行えなかった。これに対し,7800 GTXでは,FP32 Shader Unit 1でも積和演算を行えるようになっているのだ。上の図を拡大して,右端をよく見比べてほしい。7800 GTXのスライドでは,各シェーダユニットの説明に「4 FP MADS / pixel」とあるのが分かるだろう。「MAD」は「Multiple ADd」,つまり積和演算の意。「『4』要素『FP』32の『MAD』」ということで複数形のMADSになっている。7800 GTXではFP32 Shader Unit 1/2のいずれも,1ピクセル当たり四要素FP32ベクトルの積和演算を行えるというわけである。これに対して6800 Ultraにおける説明は「4 FP Ops / pixel」。積和演算についてうまくごまかしながら,1ピクセルごとに四要素FP32ベクトル"処理"(OPs:OPerations)を行えると書いてある。
 |
| 1パイプラインあたりの性能差を示すとするNVIDIA提供のグラフ。積和演算ユニット数が2倍になったおかげで,7800 GTXは6800 Ultraの1.2〜1.5倍程度のパフォーマンス向上があったという |
NVIDIAは「GeForce 7800 GTXは,1ピクセルシェーダユニットあたりのFP32ベクトル積和演算性能が6800 Ultraの2倍になった」と,7800 GTXの先進性を強調しているが,この2倍というのは,そういう意味だったわけだ。
ちなみにNVIDIAは,最近の3Dゲームタイトルから約1300のピクセルシェーダプログラムを解析し,1ピクセルシェーダユニットのスループット向上に貢献できるのが積和演算ユニットの追加であることを突き止め,この改良に踏み切ったと説明している。
最先端のピクセルシェーダプログラムでは,ピクセル単位の光源処理,反射ベクトルの計算などといった,ピクセル単位の陰影処理を頻繁に行うことになる。そして,この処理に必要な積和演算の頻度も高くなる。7800 GTXの進化方向は実際のところ,理にかなったものではあるのだ。
頂点パイプラインのときと同様に,7800 GTXも6800 Ultraも,テクスチャ読み込み時に実際のグラフィックスメモリへアクセスする必要が生じて,ピクセルシェーダプログラムの実行が実質的にストールする(止まる)と,そのピクセルシェーダが別のピクセルの処理を行うようにスレッドは切り替えられるとのこと。
ちなみに,スライド左端のテクスチャユニットに大きな変更はない。しかし,テクスチャキャッシュエンジン自体の改良は行われているそうだ。各αRGBが16ビット浮動小数点(FP16)で表される64ビットFPテクスチャ使用時のパフォーマンスが向上しているという。
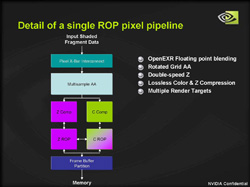
ピクセルパイプラインを通って陰影処理されたピクセルはラスタライズ処理ユニット(Rasterize Operation Unit,以下ROPユニット)で,実際にグラフィックスメモリへ書き込まれることになる。
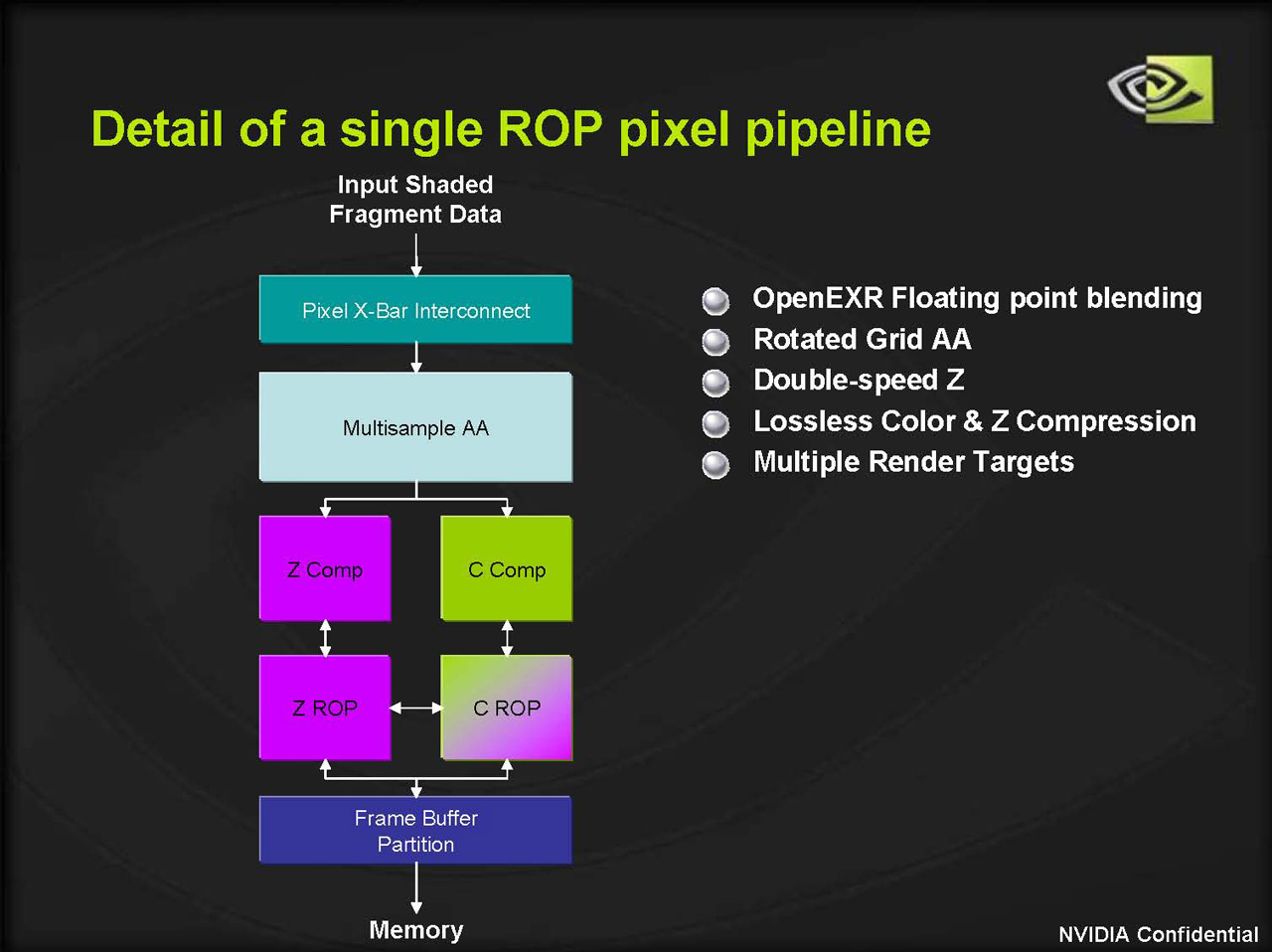
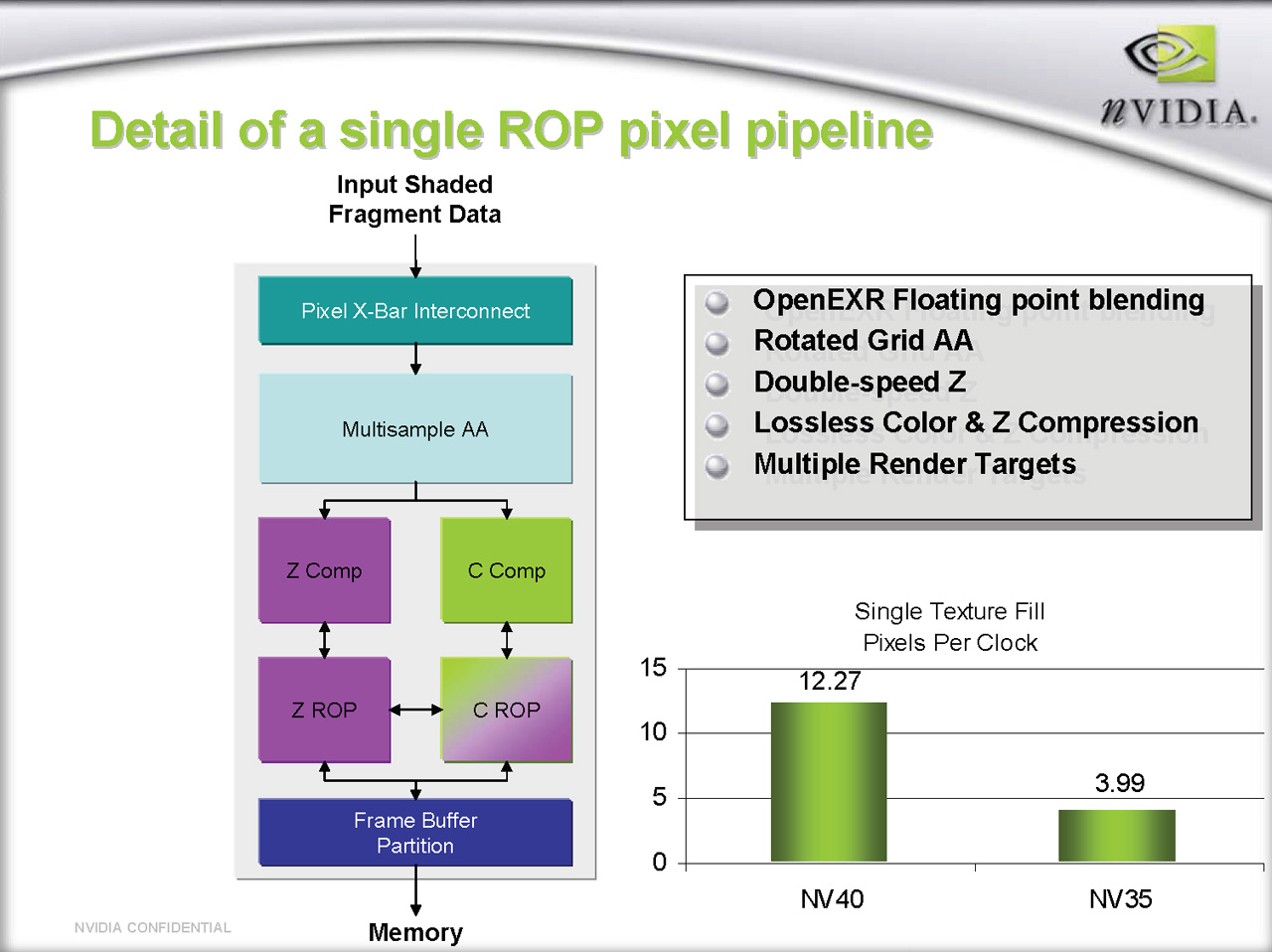
以下は左が7800 GTX,右が6800 UltraのROPユニットブロック図。ごらんのとおり,内部構成には変化なし,だ。
 |
 |
| ROPユニット内部のブロック図。左が7800 GTX,右が6800 Ultraのものだ |
冒頭に挙げた全体ブロック図を見返してもらうと分かるが,7800 GTXと6800 UltraのROPユニット数に変わりはない。16基のままだ。なんとなく,6800 Ultraと比べて7800 GTXのブロック図は尻すぼみになっているように見える。「ROPブロックがボトルネックになって,フルにパフォーマンスが発揮できないのではないか?」と心配になる人もいるのではなかろうか。
確かに,ピクセルパイプライン本数を24本へと増強したのだから,描画能力をとにかく高速化するのであれば,ここも24基構成にするのが理想だろう。
この設計になった理由は二つほど考えられる。
一つは,現行のメモリ性能から来る制約だ。現在,上位クラスのグラフィックスチップにはグラフィックスメモリとしてGDDR3 SDRAMが組み合わされている。このGDDR3 SDRAM,主流品のスペックは動作クロック600MHz以下,データレート1.2GHz以下であり,実際に6800 Ultraのリファレンスメモリクロックは1.1GHzだった。
7800 GTXではピクセルパイプライン数が1.5倍に増強されたから,単純計算では単位時間あたりにピクセルパイプラインから出てくるピクセルデータも1.5倍に増える。さらに単純計算を続けると,1.1GHzの1.5倍,1.65GHz相当のGDDR3 SDRAMと組み合わせなければ,24本のピクセルパイプラインから出てくるピクセルデータをレイテンシなしに書き出すことはできない。
GDDR3 SDRAMは最近2GHz品が発表され,1.6GHz品の量産が行われているようだが,高クロック品はまだまだ高価。コストとのバランスを考えると,7800 GTXで利用できるGDDR SDRAMは6800 Ultraから100MHzアップの1.2GHzとなる。それが「これではROPユニットの個数が24基あっても無意味」という判断へとつながり,ROPユニット数が据え置かれたのではないか,というわけだ。
二つめは「ピクセルスループット性能はいまや必要十分で,それほど重要ではなくなってきたから」というもの。
近年の先進的な3Dゲームは,目標フレームレートを60fps程度にして,あとは1ピクセルの陰影処理のほうに注力するようになってきている。ピクセルスループット性能をフル活用して100fpsや200fpsといった景気のいいフレームレートを出すよりも,複雑高度化したピクセルシェーダプログラムを高速に動かしたい,というニーズの方が高くなってきているというわけだ。
つまり,7800 GTXの設計において,「ピクセルパイプラインから出てきたピクセルデータの処理性能は6800 Ultra程度で十分」という判断のもと,設計リソースをピクセルシェーダユニットの性能向上のほうに割いた,というふうに考えられるのである。
1600×1200ドットや,フルハイビジョンの1920×1080ドットといった解像度で現実的なフレームレートを出せるROP処理ブロックが実現できていれば,現実問題として,それ以上のROP性能向上は確かに不要といえるかもしれないのだ。
そしてもしかすると,こうした「ピクセルパイプラインの本数(≒ピクセルシェーダユニット数)>ROPユニット数」というアーキテクチャは,今後のグラフィックスチップ設計の基本形になるかもしれない。
最後に「なぜ『NV47』は『G70』と開発コードネームが改められたのか」そして「『GeForce 7800 Ultra』は出るのか」についてフォローアップしておこう。
2004年春に「GeForce 6800 Ultra」として発表されたグラフィックスチップ「NV40」(開発コードネーム)は,発表当時,世界初のSM3.0仕様準拠のGPUとしてセンセーショナルに登場したが,製造上の歩留まりが悪く,実際の市場投入がNVIDIAの思いどおりには行かなかった。
ベンチマーク記事は各メディアに上がる一方,どこにも売ってないといういびつな状況にあったことを覚えている読者も多いだろう。"ちゃんと"流通したといえるのは,より低クロックで動作する「GeForce 6800 GT」と,パイプラインを削減した「GeForce 6800」で,それも数としては多くなかった。実際に「GeForce 6」シリーズ普及の立役者は,あきらかに下位モデル「GeForce 6600」(開発コードネーム「NV43」)だった。
AGP−PCI Expressバス変換チップ「HSI」(High-Speed Interconnect)を1パッケージにした「NV45」(開発コードネーム)も発表はされたものの,実際に店頭へ並んだ例は少なく,この1年半あまりの間,NVIDIAのウルトラハイエンドグラフィックスチップは実質的に不在だったといっていいだろう。そして,このNV40/45系のマイナスイメージは,NVIDIAのOEMとなるグラフィックスカードベンダーの不信を招いたのである。
結局のところ,開発コードネームがNV47ではなくG70となったのは,「単なるNV40/45のリファイン版」というイメージ打破のためなのだ。実際にNVIDIA関係者も「リニューアル感の演出」については暗に認めている。なお,NVIDIAは今後,開発コードネームを"Gxx"に統一するようで,「開発コードネーム仕切り直し」の意味も含んでいると見られる。
ちなみに,グラフィックスカードベンダーなどには,今後のロードマップについての説明がすでに行われており,「NV46」=「G72」,「NV49」=「G71」という対応が示されているとのこと。G72はGeForce 6600シリーズの後継となり,順当に行けば「GeForce 7600」シリーズとして発表されるだろう。スペック的には,メモリバスがGeForce 7800 GTXの半分,128ビット接続になる以外,現時点では明らかにされていない。G71は同様に「GeForce 7200」シリーズになると思われ,GeForce 6200シリーズで採用された「TurboCache」技術を組み込んでくる可能性が高い。
最後に「GeForce 7800 Ultra」(以下7800 Ultra)登場の可能性だが,かなり高いといっていい。
NVIDIAのチーフサイエンティストを務め,「GeForceの父」の異名を取るDavid Kirk氏は,Ultraの存在について「ノーコメント」としながらも「G70チップにはかなりのパフォーマンスヘッドルームがあり,より高いクロックでの動作も可能だ」と述べている。
G70をベースにしプレイステーション3専用グラフィックスチップ「RSX」の動作クロックが550MHzということもあって(あちらのプロセスルールは90nmだが),一説にG70は500MHz近い高クロック動作が可能ともいわれている。ではなぜ7800 GTXのコアクロックは430MHz動作止まりなのか。これは,先ほどのROPユニット数にも関係してくるわけだが,組み合わせるのGDDR3 SDRAMの主流品が1.2GHzデータレート製品以下となるため,これとバランスの取れた動作クロックとして決定されたと見られている。
無駄にコアクロックだけ引き上げても,パフォーマンスがグラフィックスメモリ性能で頭打ちとなってしまっては意味がない。なので,1.6GHz版のGDDR3グラフィックスメモリの値段が下がってくるころには,より高クロック動作するG70コアと組み合わせられ,それが"Ultra"になるというシナリオは十分に考えられる。
グラフィックスカードベンダには,すでにGeForce 7800 Ultraのリファレンスカードデザインが提示されているといわれ,「ヒートシンクは6800 Ultra同様の2スロット占有タイプ」「冷却システムにヒートパイプを採用」という情報も筆者のところへは流れてきている。ただ,「製造プロセスが90nmになるのか」「だとしたらROPユニットの個数は増えるのか」「それともただの『G70の高クロックコア+高クロックメモリの組み合わせ』になるのか」といった詳細情報はいまだ不明。登場時期も未定だ。とはいえ,完成の遅れが伝えられているATI Technologiesの次世代グラフィックスチップ「R520」(開発コードネーム)の発表に合わせ,反撃の手段としてNVIDIAが準備していることだけは間違いないだろう。(トライゼット 西川善司)