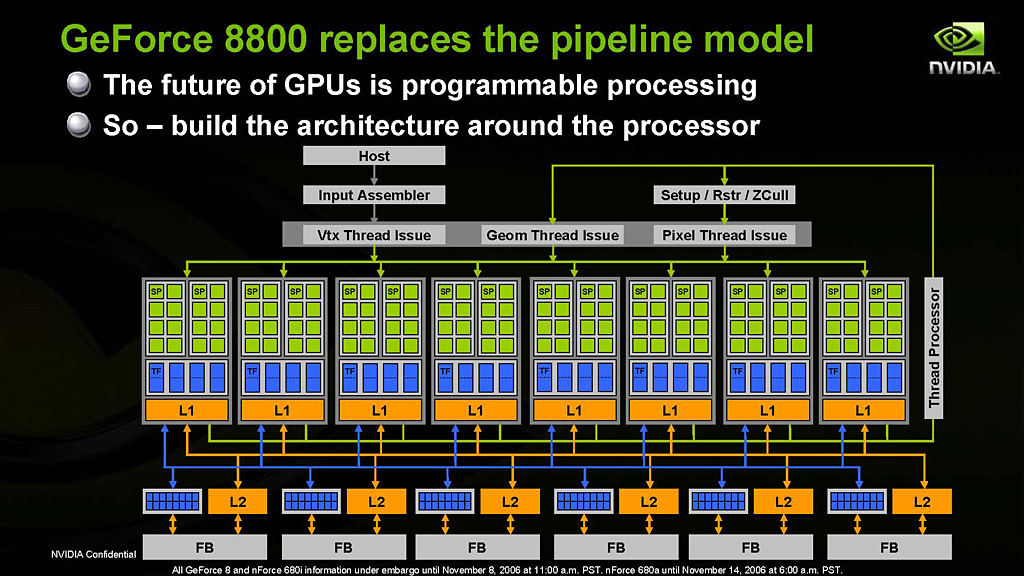
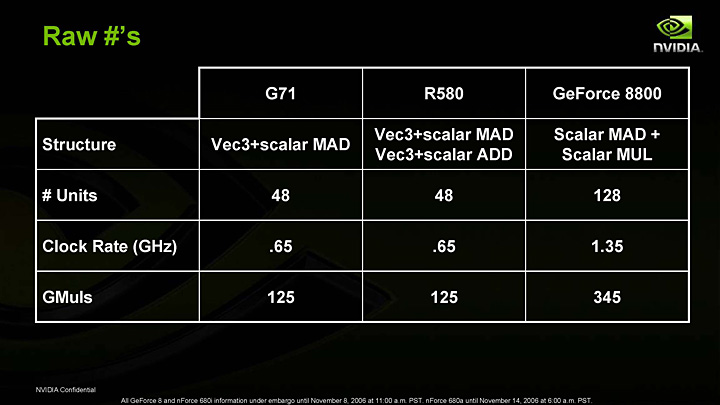
大まかに概要をつかんだところで,もう少し掘り下げてみよう。まず,GeForce 8800(GeForce 8800 GTX)のブロックダイアグラムは,下のような形になる。
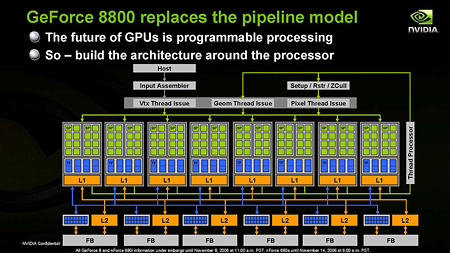
GeForce 8800 GTXのブロックダイアグラム
入力を[HOST]システムから[Input Assembler]を介してレンダリングパイプラインへ受け入れる。ここまではこれまでのGPUと同じだ。
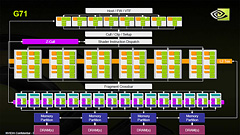
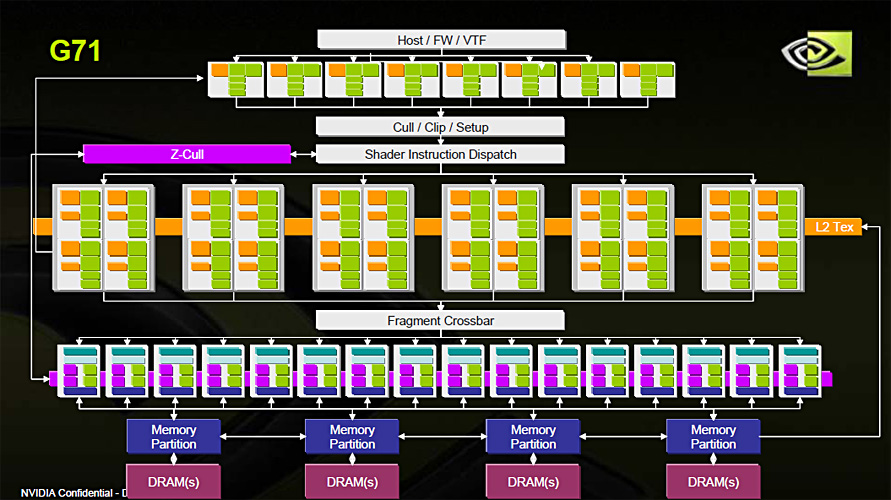
(参考)前のページでも掲載した,GeForce 7900 GTXのブロックダイアグラム。「Host/FW/VTF」の下に8個並んでいるのが頂点シェーダ,中央に24個並んでいるのがピクセルシェーダだ。ちなみに黄緑がシェーダユニット,橙がテクスチャユニットを示す。両ユニットがペアになっているのが分かるだろう
これまでのGPUと違うのは,その先に頂点シェーダユニットのブロックがないところ。その下にはシェーダブロック8個が横に並んでいる。
シェーダブロックの中には,「SP」と書かれた黄緑のブロックが16個見えるが,これはストリーミングプロセッサ(Streaming Processor)。それぞれは2命令同時発行型(Dual Issue Type)のスカラ浮動小数点演算器だ。正確には,積算と積和算が同時に行えるスカラ浮動小数点演算器となっており,これが16(基)×8(シェーダブロック)=128個あるのが分かる。
ストリーミングプロセッサの下には青いブロックで表される「TF」,テクスチャフィルタ(Texture Filter)が1ブロックあたり8個用意されている。
テクスチャフィルタは,言ってしまえばテクスチャユニットのこと。テクスチャを読み出してフィルタリングまでを行う機能ブロックだ。

ストリーミングプロセッサとテクスチャフィルタ部を拡大してみた。[L1]とあるのはL1キャッシュ
特徴的なのは,GeForce 7以前においてシェーダユニットとテクスチャユニットがペアになっていたのに対し,GeForce 8800では,8個のテクスチャフィルタが,16個のストリーミングプロセッサに共有されるデザインになっている点である。
NVIDIAはこの理由を「処理スレッドの細分化を推し進めた結果,このほうが効率的と判断したため」と説明している。要するに,GeForce 8800では複数のストリーミングプロセッサによって各種シェーダユニットが形成されるが,そのシェーダユニットが必ずしもテクスチャ参照を行うとは限らないからこうなっているというわけだ。
例えば,GeForce 8800シリーズにおいても頂点シェーダからテクスチャを参照するVTF(Vertex Texture Fetching)機能は当然サポートされるものの,実際のところ,対応ゲームタイトルの数は非常に少ないため,使用頻度は低い。こういった場合,統合型シェーダアーキテクチャでは,テクスチャユニットは使いたいときに使えるようにしておいたほうが,ハードウェア上の無駄を少なくできるのである。
話を元に戻すと,通常,[HOST]から入力されるデータは頂点データなので,これは複数個のストリーミングプロセッサを起用して形成される即席の頂点シェーダユニットによって処理される。
即席頂点シェーダユニットからの出力はスレッドプロセッサ([Thread Processor])に戻される。その出力データを元にトライアングルセットアップとラスタライズを行って,ピクセルタスクに分解する場合は[Setup/Rstr/ZCull]に実行が移る,という流れだ。
なお,頂点シェーダの出力からジオメトリシェーダを利用して頂点を増減させる処理を行う場合は,複数のストリーミングプロセッサを起用してジオメトリシェーダを形成し,そちらに処理を移すことになる。
スレッドプロセッサ(あるいは[Setup/Rstr/ZCull])のあとは,複数のストリーミングプロセッサを起用してやはり即席のピクセルシェーダユニットを形成し,ピクセル単位の陰影処理を行う。
こう説明すると想像がつくと思うが,キーポイントとなるのはスレッドプロセッサだ。現在,どのシェーダタイプの仕事が忙しいのかを見極めて,その負荷に応じてどのシェーダをいくつ形成するのかを,リアルタイムかつ動的に決定している。
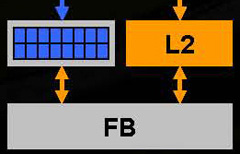
こちらはROPユニット周辺の拡大。[L2]とあるのはL2キャッシュである
さて,ダイアグラム下部にある,各ブロック16個の青いブロックは,従来のGPUでいうところのROPユニットに相当する。つまりは,ピクセルやテクセルのグラフィックスメモリの書き出しを担当するところだ。
前のページでも軽く触れたように,このROPユニットも,統合型シェーダアーキテクチャの採用の影響でずいぶんと構造が変わっている。
グラフィックスメモリブロックはGeForce 8800 GTXで6個,GTSで5個。それぞれのメモリブロックはROPユニットのブロックと64bitバス接続されている。だからGeForce 8800 GTXはグラフィックスメモリバスが64bit×6で384bit,同様にGeForce 8800 GTSは64bit×5の320bitになっているのだ。
ブロックごとのROPユニット数は16基だが,これらがすべて同時にグラフィックスメモリにアクセスすることはできない(と思われる)。後述する,内部マルチスレッド化技術の影響で,出力ができる状態になったROPから順次出力されるような仕組みになっているようだ。
ちなみに,ダイアグラム最下部の[FB]はフレームバッファ(Frame Buffer)を表している。要は,グラフィックスメモリのことである。
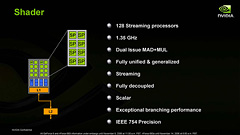
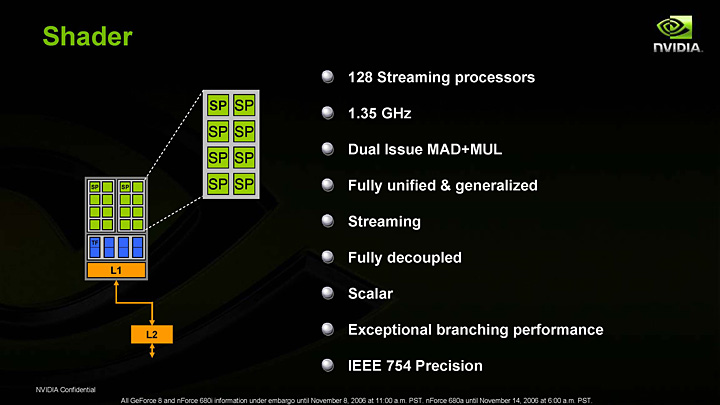
ストリーミングプロセッサ周りの特徴を説明するスライド
GeForce 8800のアーキテクチャにおいて,さまざまな誤解を招きそうなのが,右のスライドで説明されている「128 Streaming processors」というスペック表記だろう。
NVIDIA側も,GeForce 7900 GTXの4倍にシェーダユニットが増えたように見える“都合のいい誤解”をユーザーにアピールするためか,128という数字を強調しているが,前のページで説明したように,実際はそうではない。「128のシェーダ」と言えば,たしかに間違いではないが,1基1基のストリーミングプロセッサは1度に一つの数字しか扱えないスカラプロセッサなのだ。つまり,単体ではベクトル演算を行えないのである。
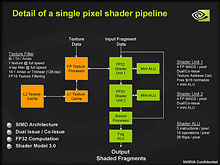
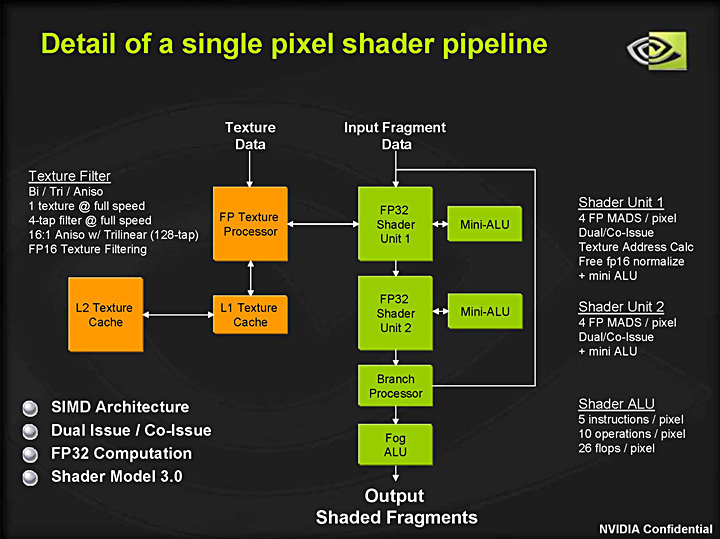
GeForce 7900 GTXが持つピクセルシェーダユニットのブロックダイアグラム
GeForce 7900 GTXの例を左に示したが,DirectX 9までのGPUでは,シェーダユニットで3要素ベクトル(Vec3)演算とスカラ演算を1クロック同時に行える設計となっていた。これに対して,ストリーミングプロセッサで同じことをしようとすると,4個同時に駆動させるか,1個を4回駆動させる必要がある。
ということは,従来のGPUの最大演算性能を128SPで再現しようとすると,128÷4=32シェーダユニット相当といえるわけで,このうち8基分を頂点シェーダユニットに割くとすると,ピクセルシェーダに割けるのは24基分。これが前ページで示したスペック表における仮定の根拠だ。なお、GeForce 7のピクセルシェーダは4要素ベクトルの積和算が行えるベクトル演算器を二つ持っているので,GeForce 7相当のピクセルシェーダユニットはGeForce 8800シリーズのストリーミングプロセッサ8基分ということになる。つまり,GeForce 8800シリーズのストリーミングプロセッサをGeForce 7のピクセルシェーダ換算すると128÷8=16基となってしまうのだ。
とはいえ,残念がることもない。GeForce 7では,実行する命令の出現順序などに依存して常に,二つのベクトル演算器がフル可動できるわけではない。臨機応変に必要な演算を必要な個数(あるいは回数)起用して実行できるGeForce 8800シリーズの仕組みのほうが,実行効率に優れることは間違いないのである。
また,動作クロックは正真正銘1.35GHzなので,GeForce 7900 GTXのほぼ2倍。“GeForce 7換算”を行っても,GeForce 8800 GTXに劣ることはないはずだ。
ところで,GeForce8800シリーズがSIMD型ベクトルプロセッサではなく,FP32スカラプロセッサを多数実装したのには理由がある。
SM4.0では多様なスカラ整数演算命令などが追加され,CPU的なプログラムをシェーダプログラムとして実行できるようになっている。さらに統合型シェーダアーキテクチャにより,“○○シェーダユニット”という決まった役割がなくなっているため,GPU内部ではベクトル演算だけでなくスカラ演算も頻発し,さらにベクトル演算にしても2要素,3要素,4要素と多様なベクトルサイズの演算が発生する可能性も強まってきた。そんななかで,3要素ベクトル+1スカラのスタイルに固執したシェーダユニットを多数設けるのは得策でない。……NVIDIAの開発陣は,こう判断したのだろう。
たしかに,128 Shader processorsという表記はずるい。しかし,アーキテクチャ革新の方向性としては,実に理にかなっているのである。
 |
 |
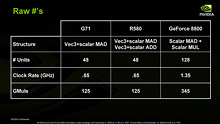
| Radeon X1000ファミリーで,ATIはピクセルシェーダにおいてスカラ演算&スカラ演算,Vec3演算&スカラ演算,Vec3演算,Vec2演算といったバリエーションのユニット活用を許容していた。逆にいうと,2命令同時実行は前者2パターンに限られていたが,NVIDIAはGeForce 6800以降で,これらに加えてVec2&Vec2演算を許容。そしてGeForce 8800においては演算の組み合わせによって“使われない演算器”が生じるというムダがなくなった |
なお,実行中のシェーダプログラムがテクスチャアクセスに遭遇すると,当然のことながらその実行のためにテクスチャフィルタ(=テクスチャユニット)の起用が発動させられる。
テクスチャアクセスはメモリアクセスなので,シェーダユニットによる計算の数倍から数十倍の待ち時間が発生するが,このとき,シェーダユニットがただ待つだけでストールしていては非効率的なので,別のピクセルスレッドの実行に切り換わるようになっている。この仕組み自体は,GeForce 6〜7世代でも搭載されており,“やっていること”に大きな差はないのだが,GeForce 8800ではこの“内部スレッド切り替え機構”について,「GIGA Thread」という,しゃれたテクノロジー名が与えられた。
なお,記憶力のいい読者は覚えていると思うが,ATIはこれを「Ultra-Threading」と名づけている。

ストリーミングプロセッサとテクスチャフィルタを完全分離化することで利用効率を上げたGeForce 8800。しかし,こうした動的な割り当てロジックは実際には相当複雑な構造になっている。やっと実現できた構造なのだ
GeForce 8800シリーズでは,テクスチャユニットをシェーダユニット(前のページで説明したように,GeForce 8800では「テクスチャフィルタ」と説明されている)から完全分離した。これは,SM4.0世代の長いシェーダプログラムにおいて,演算とテクスチャアクセスが必ずしもペア,あるいは交互で行われるとは限らないため。複数のストリーミングプロセッサが演算目的ごとに多様なかたちで起用されることまで考えると,テクスチャユニットがストリーミングプロセッサとペアになっているよりは,必要なときに呼び出される分離型のほうが,「テクスチャユニットの使われ方」としては断然効率がいいのである。
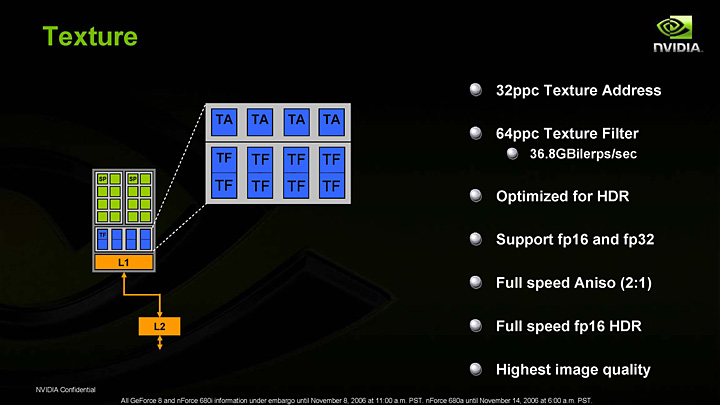
テクスチャユニットの構造は下に示したとおり。16個のストリーミングプロセッサに共有される形で,4基のテクスチャアドレス計算ユニット(TA),8基のテクスチャフェッチ(読み出し)ユニット(TF)が実装されている。GeForce 8800 GTXではトータル,32基のTA,64基のTFが存在する計算だ。
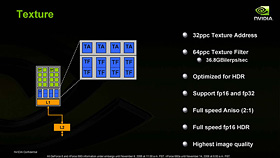 |
GeForce 8800におけるテクスチャユニットのブロックダイアグラム |
GeForce6800以降では,RGBαが各16bit浮動小数点(FP16)で表されたFP16-64bitテクスチャや,RGBα各32bit浮動小数点(FP32)で表されたFP32-128bitテクスチャがアクセスできるようになり,さらには異方性テクスチャフィルタリングもサポートされた。ただし,FP16-64bit以上のテクスチャのフィルタリング付きフェッチが遅く,3Dゲームグラフィックスには荷が重いとされてきた。結果として,HDRレンダリングパイプラインを実装する3Dゲームエンジンでも,テクスチャは従来の32bit整数のLDRテクスチャ(Low-Dynamic Range)を用いて,疑似HDRの仕組みを採用するものが少なくない。
GeForce 8800では,このテクスチャユニットを改良し,実質的には個数も増やすことで,この弱点を克服している。GeForce 8800 GTXのテクスチャフェッチユニットは64基,対してGeForce 7900 GTXだと24基なので,単純な個数比較でも2.6倍に増えており,高い性能が想像できよう。
実際,GeForce 8800だと,FP16-64bitテクスチャに対し,2x異方性テクスチャフィルタリングまでならば1サイクルで処理できるようになっている。FP16-64bitテクスチャにおいて2x異方性フィルタリングが性能低下なしで使えるというのは,頂点テクスチャリング(Vertex Texture Fetching)はもちろん,ジオメトリシェーダにおけるテクスチャ活用において多大なポテンシャルと高品位な表現を支援してくれるはずだ(異方性テクスチャフィルタリングの詳細は,
連載のバックナンバーを参照のこと)。
ちなみにFP32-128bitテクスチャだと,バイリニアまではパフォーマンス低下なしだが,2x異方性フィルタリングを利用してしまうと,まだパフォーマンス低下が存在する。
ただし,依然としてHDRテクスチャの圧縮法の標準化が登場していないことは,フルHDRレンダリングをゲームエンジンに実装するうえで障害になっている。この部分は今後の課題といえるだろう。