テクニカルガイダンス会場の様子
コンシューマ向けWindows Vistaの発売を2007年1月に控える2006年11月9日(北米時間8日),NVIDIAは新型GPU(グラフィックスチップ)「GeForce 8800」を発表した。
開発コードネーム「G80」として知られていたGeForce 8800は,DirectX 10(正確にはDirect3D 10),そしてプログラマブルシェーダ4.0(Shader Model 4.0,以下SM4.0)への対応が行われており,ホットなトピックが満載。今回は,2006年10月18日に世界中の報道関係者を集めて極秘裏に開催された「テクニカルガイダンス」の内容を中心に,この新型GPUについて,じっくりと見ていくことにしたい。

従来のGPUレンダリングパイプラインの簡略図。プログラマブルシェーダになってプログラマビリティを獲得したGPUだが,機能役割分担は固定的だった
2001年に発表されたGeForce3でプログラマブルシェーダアーキテクチャが初めて採用されてから,GPUは長らく,個数の固定された「頂点シェーダユニット」(Vertex Shader Unit)と「ピクセルシェーダユニット」(Pixel Shader Unit)によって構成されてきた。
複数個の頂点が三角形(ポリゴン)を形成し,それらがさらに膨大な数のピクセルへと変換されるため,処理負荷は「頂点シェーダユニット<ピクセルシェーダユニット」となるのが一般的。そこで,基本的にはピクセルシェーダユニットの個数が頂点シェーダユニットの個数を上回るようになっていた。
 |
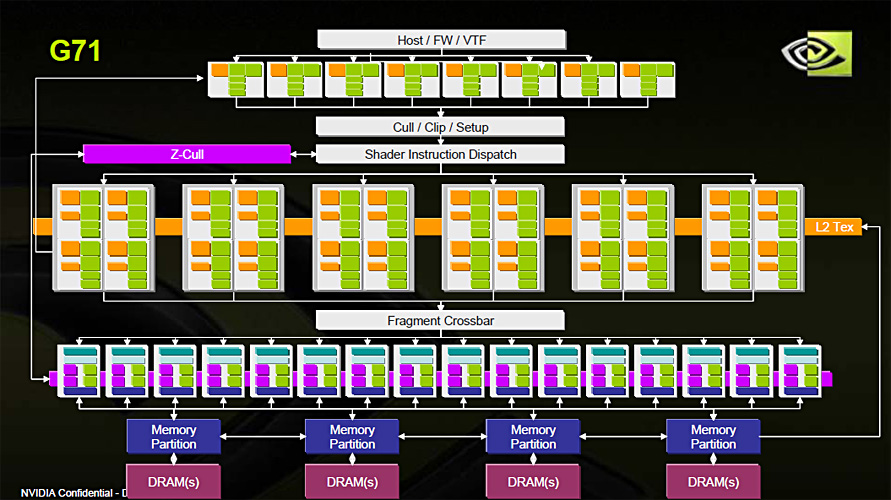
G71(=GeForce 7900 GTX)のブロックダイアグラム。一般にピクセル負荷のほうが高いという“常識”があって,「頂点シェーダ<ピクセルシェーダ」の関係はこれまで維持されてきた |

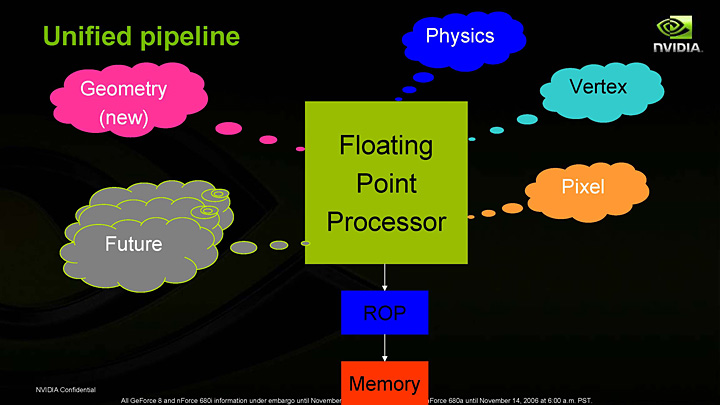
統合型シェーダアーキテクチャであることを訴えたスライド。ちなみに,筆者を含め,多くのテクニカルアナリストは「NVIDIAが90nmプロセスで来る」と掴んでいたため,NVIDIAのDirectX 10世代GPUは“既存シェーダ増強&ジオメトリシェーダ追加”と予想していた
ところが,何度もレンダリングパイプラインを回すようなマルチパスレンダリングが主流となり,なおかつ複雑なシェーダプログラムが実行されるようになってきた近年,このアーキテクチャですべての状況に対応できなくなってきている。
例えばピクセルシェーダユニットが高負荷になれば,ここがボトルネックとなり,頂点シェーダユニットは次の頂点処理に進めなくなってしまう。GPUに限らず,CPUなどを含めたプロセッサでは,ヒマな機能ブロックやボトルネックが発生する設計は好ましくない。すべての機能ブロックが常にフル回転し,最大性能が得られるような設計が理想なのだ。
そこで考え出されたのが,「統合型シェーダ」(Unified Shader)と呼ばれるアーキテクチャである。
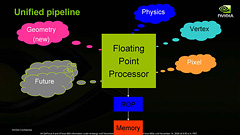
プログラマブルシェーダの使われ方が多様化し,GPUに汎用性が求められるこれからの時代には,演算パワーの機能配分を可変とした方が効率的と判断されたのだ
頂点シェーダユニットの仕事は頂点処理で,ピクセルシェーダユニットの仕事はピクセル処理。内容は当然異なるが,そこで行われる計算に着目すると,ベクトルや行列の演算などが主体であり,ほとんど変わらなかったりする。入ってくるデータと算出するデータの“意味”が異なるだけだ。
ならば,汎用のシェーダユニットをたくさん用意して,状況に応じて頂点シェーダユニット用として起用したり,ピクセルシェーダユニット用として起用したりすれば,効率よく処理できるのではないか。GPU業界はこう考えた。
このアイデアこそが,統合型シェーダということになる。
統合型シェーダアーキテクチャでは,あるシェーダ処理にボトルネックが発生すると,動的にそのタイプのシェーダユニットを起用してボトルネック解消に乗り出す。先ほど述べた,ピクセルシェーダユニットにボトルネックが発生した例で行けば,汎用シェーダユニットをピクセルシェーダユニットとして多数起用してボトルネック解消を試みるのだ。
もちろんこのとき,ほかのシェーダユニットの数は減るが,ボトルネック発生中は,ほかのシェーダユニットの仕事量も減っているので,実害はない。
イメージとしては,「ある仕事に詰まっているチームがあったら,臨機応変に人員を増員するシステム」といった感じだろうか。
 |
 |
| 例えば,頂点シェーダユニット4基,ピクセルシェーダ8基というアーキテクチャがあると,負荷(Workload)バランスが崩れたときに,まったく動作できない演算ブロックができてしまっていた(左)。一方,12基の汎用シェーダユニットなら,負荷バランスに応じて,常に演算パワーをフルに活用できる(右)というわけだ |
今回発表されたGeForce 8800は,NVIDIA初の統合型シェーダアーキテクチャ採用GPUだ。PC向けという限定条件を付ければ,GeForce 8800は世界初の統合型シェーダアーキテクチャ採用GPUといえる。
余談になるが,プラットフォームを問わなければ,世界初の統合型シェーダアーキテクチャ採用GPUはAMD(当時はATI Technologies,以下便宜的にATIと表記する)の「Xbox 360-GPU」だ。詳細は後述するが,実際,Xbox 360-GPUとGeForce 8800には,アーキテクチャ的に似た部分が多い。
さて,GeForce 8800の総トランジスタ数は6億8100万で,ダイサイズは450mm2。製造プロセスルールは90nmで,台湾TSMCで製造される。

Tony Tamasi氏(Vice President of Technical Marketing, NVIDIA)。元3dfx Interactiveコアメンバーで,無類のPCゲーム好きとしても有名
左の写真は,テクニカルガイダンスで紹介されたGeForce 8800のウェハで,持つのはお馴染み(?),GeForceシリーズの技術面における詳細仕様をNVIDIA社内で一番よく知る人物である,テクニカルマーケティング担当副社長 Tony Tamasi(トニー・タマシ)氏だ。
同じ90nmプロセスで製造されるGeForce 7900 GTXが2億7800万トランジスタ,ダイサイズ190mm2なので,GeForce 8800 GTXでは約2.5倍の規模になったことになる。まさにモンスター級といってよく,コンシューマ向けプロセッサとして世界最大級,最大規模であることは間違いない。
 |
 |
| GeForce 8800のウェハのイメージ(左)と実物(右) |
今回発表されたのは,最上位の「GeForce 8800 GTX」と,それに続く「GeForce 8800 GTS」の2モデル。“GTS”は,製品名としてはGeForce2以来の復活となる。いずれもハイエンド向けとなり,ミドルレンジ以下のモデルについてのアナウンスは,今回はない。
両モデルの概要(正確にはリファレンスカードの概要)は以下のとおりだ。
コンシューマ向けグラフィックスカードのグラフィックスメモリ容量が,標準で512MBを超えてくる時代がとうとう訪れたことは感慨深い。
本連載で何度かとりあげているが,HDR(High-Dynamic Range)レンダリングにおいては,浮動小数点バッファや浮動小数点テクスチャを多用することになる。とくに2006年時点では,浮動小数点テクスチャを圧縮するメソッドがなく,グラフィックスメモリの消費量は膨大になってきており,グラフィックスメモリ容量増加の傾向は,今後も続くだろう。
グラフィックスメモリに関して続けると,GDDR4 SDRAMを採用しなかった点も興味深い。
GDDR4 SDRAMの特徴については,ATIが世界初の対応GPUとして「Radeon X1950 XTX」を発表したときに
詳しく説明しているが,駆動電圧が低いことと,同じ動作クロックで比較したときにバースト転送時のデータ転送速度がGDDR3 SDRAMの2倍になるのが,大きな特徴だ。

GeForce 8800の拡大写真
では,なぜNVIDIAはGDDR4を採用しなかったのか?
NVIDIAは,その最大の理由として,入手性とコストバランスを挙げている。「現状だと,GDDR4はまだ安定的に供給されておらず,同時に高価なので,GeForce 8800世代ではGDDR3で十分」という判断が働いたようだ。
NVIDIAは,GeForce FXが大失敗してから,,新しいアーキテクチャを採用するGPUを投入するときには,冒険する部分と,冒険しないで妥協する部分を使い分けている。GeForce 8800だと,冒険した部分は「大規模チップ」「統合型シェーダ」になり,妥協した部分は「プロセスルール」「採用グラフィックスメモリ」といった感じになるだろうか。
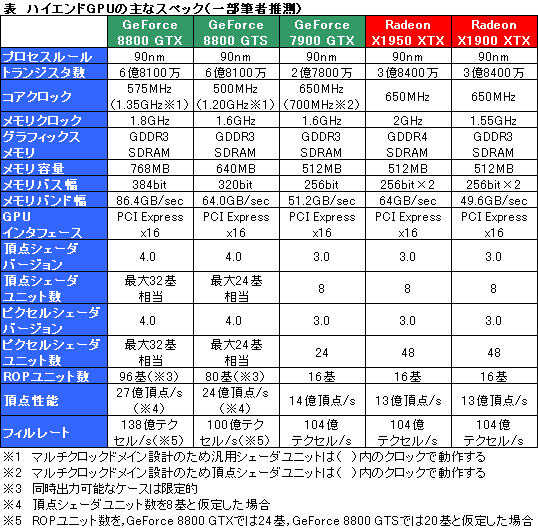
というわけで,ここで従来製品とスペックを比較してみたいと思うが,統合型シェーダアーキテクチャとそうでないアーキテクチャを直接比較するのは難しいので,従来のGPUの仕様に無理矢理置き換えて考えてみることにする。
GeForce 8800シリーズには,128基のストリーミングプロセッサがあるが,1基1基は32bit浮動小数点の積和算と積算を同時実行可能なスカラプロセッサだ。つまり,これまでの「3要素ベクトル演算(Vec3)+スカラ演算」のプログラマブルシェーダユニットと同等の演算能力を形成しようとすると,4基必要になる。つまり,128÷4=32基の汎用プログラマブルシェーダユニットがあると仮定可能だ。
また,ROP(Rasterise OPeration)ユニットも,統合型シェーダアーキテクチャになったことで,役割が複雑になり,汎用のメモリのロード/ストアユニットの意味合いが強くなっている。
ただ,GeForce 8800とGeForce 7900 GTXでは,対応するグラフィックスメモリが同じ。1メモリブロック(=メモリパーティション)ごとのメモリバス幅も64bit幅で同じまま,パーティションがGeForce 8800 GTXで2ブロック,GeForce 8800 GTSで1ブロック増えた格好なので,“GeForce 7換算”すれば,ROPユニットは24基,もしくは20基相当になる。
こういった仮定を行い,フィルレートの算出に当たっては,頂点シェーダユニットの個数をGeForce 7900 GTXと同じ8基と仮定するなどして,まとめたのが下の表だ。いずれ,すべてのGPUが統合型シェーダとなったときには,別の表記方法を検討する必要があると思われる。
以上,概要をまとめてみた。次のページ以降では,各部をもう少し掘り下げてみよう。