















ニュース
NVIDIA,PCI Express x16接続版「Tesla P100」を発表。第4四半期に市場投入
2016年6月20日15:00,NVIDIAは数値演算アクセラレータ「Tesla P100」のPCI Express x16接続版を発表した。
今回の発表は,ドイツ時間6月19日にドイツで開催予定となっているハイパフォーマンスコンピューティング(以下,HPC)関連の国際会議「International Supercomputing Conference 16」(ISC’16)に合わせたもの。Tesla P100の製品ラインアップがようやく出揃ったと同時に,PCI Exprss(以下,PCIe)カード型であるがゆえに,これをベースにしたGeForceの出てくる可能性がゼロではなくなったという記念すべき(?)製品でもあるので,概要を簡単に紹介してみたい。
「GP100」コアを採用するTesla P100がデビューしたのは,今年4月に開催された「GPU Technology Conference 2016」のタイミングだが(関連記事),当時,存在が明らかになったのは,NVIDIA独自の高速インターリンク技術「NVLink」に対応するものだけだった。既存のTesla製品はすべてPCIeインタフェースを採用しているため,NVLink対応版Tesla P100を,従来製品のアップグレードに利用することはできない。
したがって,いずれPCIeベースのTesla P100が登場するというのは容易に予測できることだったのだが,ようやくの正式発表になったというわけである。
NVIDIAによると,バリエーションモデルとしての呼称は「Tesla P100 for PCIe-Based Servers」。今回の発表に合わせて,既存のNVLink対応版Tesla P100には「Tesla P100 for NVLink-enabled Servers」という呼び名も同社は与えている。
明らかになっているスペックは下に示したスライドのみなのだが,PCIe接続版Tesla P100における重要なトピックとしては,NVLink対応版Tesla P100と比べると,演算性能がやや低いことが挙げられるだろう。浮動小数点演算性能は倍精度が4.7 TFLOPS,単精度が9.3 TFLOPS,半精度が18.7 TFLOPSであり,NVLink対応版Tesla P100の約89%というところになる。
GPUの動作クロックが低いのか,シェーダコア数が少ないのか,はたまたその両方なのかといった詳細は明らかになっていない。
もう1つ,上のスライドにも書いてあるのだが,PCIe接続版Tesla P100には,メモリ容量とメモリバス帯域幅の違いで2モデル展開となる点にも注目したい。上位モデルは順に16GB,720GB/sで,下位モデルは12GB,520GB/sとなる。
下位モデルは上位モデルと比べて容量,帯域幅とも25%減ということからすると,下位モデルでは歩留まり対策からHBM2(HBM:High Bandwidth Memory)のメモリチャネル数を削減している可能性が高いと筆者は見ているが,そのあたりの公式な情報も,今のところは未判明だ。
NVIDIAによると,PCIe接続版Tesla P100の登場により,企業や研究機関は,データセンターやHPCにおける大幅なコスト削減と電力効率の向上が可能になるという。
一例として挙がったのが下のスライドで,PCIe接続版Tesla P100を搭載するサーバー1ラック分の性能は,CPUのみで構成したサーバー7ラック分以上の性能に匹敵するとのことだ。同じ性能ならサーバーのラック数が7分の1以下になるので,電力消費やサーバー関連コストの削減になるというわけである。
PCIe接続版Tesla P100は,2016年第4四半期から,OEMや代理店に対する供給が始まるとのこと。いずれ各社から搭載製品などのアナウンスがあるだろう。
いずれにせよ,ゲーマーからすると,まだ見ぬHBM2搭載版GeForceの登場する可能性が出てきたというのが,PCIe接続版Tesla P100登場の意義だろう。
HBM2のコストは(GeForceに採用するにはまだ)高すぎるという話もあるため,Tesla P100がそのまま次世代GeForce GTX TITANになるかというと疑問も残るが,「『GP104』コアより高い性能のGPUがPCIeカードに載った」ことは,「GeForce GTX 1080」より高い性能のGeForceが出る可能性を生んだことと同義でもある。そのあたりはほんのりと期待しておくといいかもしれない。
ISC’16のタイミングでNVIDIAは,開発キット「Deep Learning SDK」のアップデートも発表している。要点は大きく3つだ。
1つは,NVIDIA製GPU向けのディープラーニング学習トレーニングシステム「DIGITS 3」の後継となる最新バージョン「DIGITS 4」の公開について。DIGIT 4では新たにオブジェクト(形状)認識向けの学習機能を追加するという。
2つめは,GPUによる認識をサポートする「GPU Inference Engine」(GIE)のアップデート関連。DIGITS 4による学習を基にしたオブジェクト認識をGIEでもサポートするそうだ。
3つめはCUDAを用いたディープラーニングのフレームワーク「cuDNN」のバージョンアップで,従来の「cuDNN 5」から「cuDNN 5.1」になった。cuDNN 5.1では性能向上を中心とした最適化が進んでいるとのことである。
これらのアップデートはISC’16に合わせてNVIDIAの開発者向けWebページからダウンロード提供が始まる予定なので,興味がある人は,こちらもチェックするといいだろう。
 |
今回の発表は,ドイツ時間6月19日にドイツで開催予定となっているハイパフォーマンスコンピューティング(以下,HPC)関連の国際会議「International Supercomputing Conference 16」(ISC’16)に合わせたもの。Tesla P100の製品ラインアップがようやく出揃ったと同時に,PCI Exprss(以下,PCIe)カード型であるがゆえに,これをベースにしたGeForceの出てくる可能性がゼロではなくなったという記念すべき(?)製品でもあるので,概要を簡単に紹介してみたい。
2モデル展開となるPCIe x16接続版Tesla P100
「GP100」コアを採用するTesla P100がデビューしたのは,今年4月に開催された「GPU Technology Conference 2016」のタイミングだが(関連記事),当時,存在が明らかになったのは,NVIDIA独自の高速インターリンク技術「NVLink」に対応するものだけだった。既存のTesla製品はすべてPCIeインタフェースを採用しているため,NVLink対応版Tesla P100を,従来製品のアップグレードに利用することはできない。
したがって,いずれPCIeベースのTesla P100が登場するというのは容易に予測できることだったのだが,ようやくの正式発表になったというわけである。
NVIDIAによると,バリエーションモデルとしての呼称は「Tesla P100 for PCIe-Based Servers」。今回の発表に合わせて,既存のNVLink対応版Tesla P100には「Tesla P100 for NVLink-enabled Servers」という呼び名も同社は与えている。
明らかになっているスペックは下に示したスライドのみなのだが,PCIe接続版Tesla P100における重要なトピックとしては,NVLink対応版Tesla P100と比べると,演算性能がやや低いことが挙げられるだろう。浮動小数点演算性能は倍精度が4.7 TFLOPS,単精度が9.3 TFLOPS,半精度が18.7 TFLOPSであり,NVLink対応版Tesla P100の約89%というところになる。
GPUの動作クロックが低いのか,シェーダコア数が少ないのか,はたまたその両方なのかといった詳細は明らかになっていない。
 |
もう1つ,上のスライドにも書いてあるのだが,PCIe接続版Tesla P100には,メモリ容量とメモリバス帯域幅の違いで2モデル展開となる点にも注目したい。上位モデルは順に16GB,720GB/sで,下位モデルは12GB,520GB/sとなる。
下位モデルは上位モデルと比べて容量,帯域幅とも25%減ということからすると,下位モデルでは歩留まり対策からHBM2(HBM:High Bandwidth Memory)のメモリチャネル数を削減している可能性が高いと筆者は見ているが,そのあたりの公式な情報も,今のところは未判明だ。
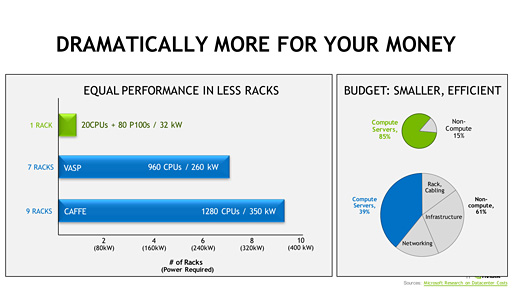
NVIDIAによると,PCIe接続版Tesla P100の登場により,企業や研究機関は,データセンターやHPCにおける大幅なコスト削減と電力効率の向上が可能になるという。
一例として挙がったのが下のスライドで,PCIe接続版Tesla P100を搭載するサーバー1ラック分の性能は,CPUのみで構成したサーバー7ラック分以上の性能に匹敵するとのことだ。同じ性能ならサーバーのラック数が7分の1以下になるので,電力消費やサーバー関連コストの削減になるというわけである。
 |
PCIe接続版Tesla P100は,2016年第4四半期から,OEMや代理店に対する供給が始まるとのこと。いずれ各社から搭載製品などのアナウンスがあるだろう。
いずれにせよ,ゲーマーからすると,まだ見ぬHBM2搭載版GeForceの登場する可能性が出てきたというのが,PCIe接続版Tesla P100登場の意義だろう。
HBM2のコストは(GeForceに採用するにはまだ)高すぎるという話もあるため,Tesla P100がそのまま次世代GeForce GTX TITANになるかというと疑問も残るが,「『GP104』コアより高い性能のGPUがPCIeカードに載った」ことは,「GeForce GTX 1080」より高い性能のGeForceが出る可能性を生んだことと同義でもある。そのあたりはほんのりと期待しておくといいかもしれない。
ディープラーニングSDKのアップデートも発表に
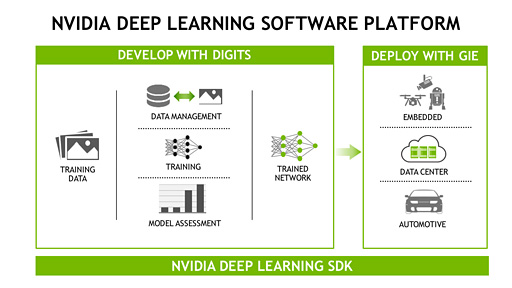
ISC’16のタイミングでNVIDIAは,開発キット「Deep Learning SDK」のアップデートも発表している。要点は大きく3つだ。
1つは,NVIDIA製GPU向けのディープラーニング学習トレーニングシステム「DIGITS 3」の後継となる最新バージョン「DIGITS 4」の公開について。DIGIT 4では新たにオブジェクト(形状)認識向けの学習機能を追加するという。
2つめは,GPUによる認識をサポートする「GPU Inference Engine」(GIE)のアップデート関連。DIGITS 4による学習を基にしたオブジェクト認識をGIEでもサポートするそうだ。
3つめはCUDAを用いたディープラーニングのフレームワーク「cuDNN」のバージョンアップで,従来の「cuDNN 5」から「cuDNN 5.1」になった。cuDNN 5.1では性能向上を中心とした最適化が進んでいるとのことである。
 |
 |
 |
これらのアップデートはISC’16に合わせてNVIDIAの開発者向けWebページからダウンロード提供が始まる予定なので,興味がある人は,こちらもチェックするといいだろう。
NVIDIAのディープラーニング開発者向けページ
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- この記事のURL:
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー