














ニュース
NVIDIA,DirectX 11世代の次世代GPU「Fermi」を予告〜30億トランジスタ,512シェーダプロセッサ!
 |
ちなみに,このFermiという名称は,イタリア生まれのノーベル物理学賞受賞者,Enrico Fermi(エンリコ・フェルミ)氏の名から取られたもの。原子番号100の放射元素「Fermium」(フェルミウム)も,氏の名前に由来している。
本稿では,速報として,要点だけをシンプルに伝えることにしたい。
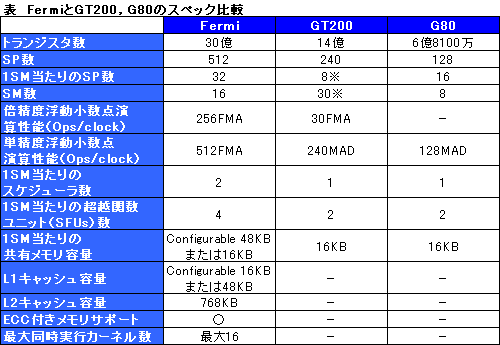
次世代NVIDIA GPUは総トランジスタ数30億!
シェーダプロセッサ総数512基の大艦巨砲型
Fermiは,40nmプロセス技術を採用して製造されるGPUで,総トランジスタ数は驚きの30億超。9月23日に発表された,AMDの「ATI Radeon HD 5800」シリーズが20億トランジスタなので,規模は1.5倍ということになる。
従来,「Streaming Processor」あるいは「Processor Core」と呼ばれていたシェーダプロセッサは,今回「CUDA Core」に名称が改められたが,その数は512基だ。GT200コアを採用していた「GeForce GTX 280」(や「GeForce GTX 285」)だと240基だったので,2倍以上(2.13倍)である。最終製品のコアクロックやシェーダクロックは,現在のところ明らかになっていない。
ブロックダイアグラムは下に示したとおりだ。
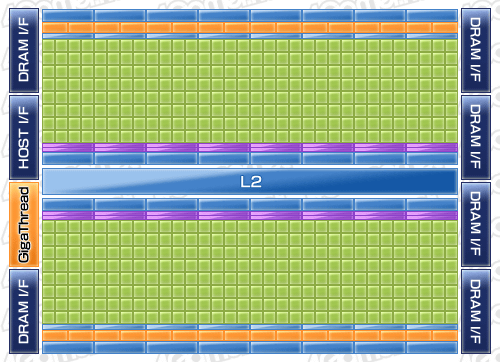 |
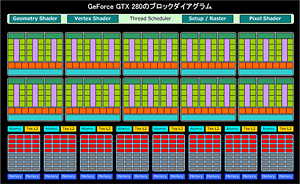 |
しかし今回のFermiでは,アーキテクチャに大きな変更があるのだ。GTX 200シリーズでは,
- 1基の命令デコードユニット(IU:Instruction Unit)
- 8基のシェーダプロセッサ(SP:Streaming Processor)
- 1基のLocal Memory(LM)
を,「Streaming Multi-Processor」(SM)とし,さらにSMを3基集めたものを「Thread Processor Cluster」(TPC)としていた。
これに対しFermiでは,まず,TPCという階層が排除されている。これはTPCとSM,それぞれの役割を統合して,上層の制御をシンプルにするためだろう。
さらにFermiでは,1基のSMに,GeForce GTX 200シリーズ比で4倍となる32基ものシェーダプロセッサ(以下便宜的にSPと表記)を内包するようにし,しかもIUは“2発式”を組み込んだ。さらに,LMはL1キャッシュ兼用の64KBとなっている。GTX 200時代は,8基のSP(=1基のSM)当たり16KBのLMが割り当てられていたので,単純な等分計算で考えると,L1キャッシュを兼用する分だけ,Fermiで1基当たりのLM量は減ったことにになるが,これは「実際のCUDAアプリケーションやグラフィックスアプリケーションにおけるLMの使われ方に対応させたリファイン」という見方が正しいようだ。
なおFermiでは,容量64KBのLM兼L1キャッシュについて,動作させるアプリケーションに応じて,「L1キャッシュ16KB+LM 48KB」「L1キャッシュ48KB+LM 16KB」の2モードを選択的に利用できるようになった。各CUDA CoreがLMを介して高度な連携を図る必要のあるGPGPUアプリケーションでは,LM容量重視で前者,逆にメモリへの局所アクセスが頻発するグラフィックス処理では,キャッシュ容量重視の後者が適合すると推察される。
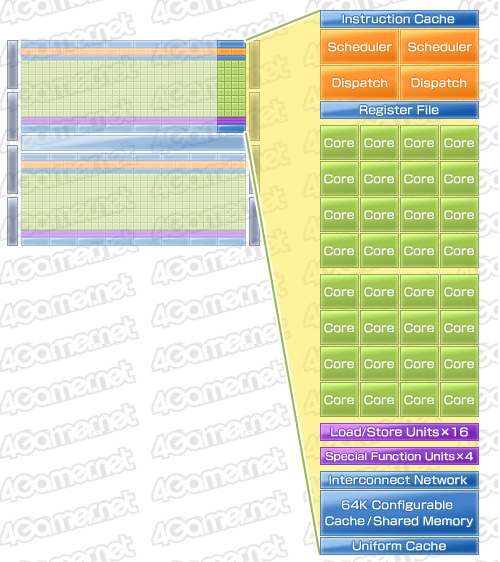 |
まとめると,Fermiでは,
という構造になっている。そしてFermi全体でのSM総数は16基なので,
ということなのだ。やや繰り返し気味になるが,GTX 200シリーズだと,TPCが10基,SP総数は240基だった。
GPGPU向けに大きく拡張された演算ユニット
メモリはついにGDDR5採用へ
各CUDA Coreには,1基の32bit浮動小数点(FP32)スカラ演算器,32bit整数(Int32)スカラ演算器が内包される。メモリアクセスを司るロード/ストアユニット(Load/Store Unit)はSM当たり16基,超越関数ユニット(Special Function Unit,指数,対数,三角関数などを取り扱うユニット)は4基で,これらは1基のSMを構成する32基のSP達で共用される格好だ。
一方,GTX 200シリーズで内包されていた,1SM当たり1基の64bit浮動小数点(FP64)スカラ演算器は,Fermiで姿を消している。その代わり,Fermiでは各SP内のFP32スカラ演算器が2クロックを要して(≒ループして)FP64演算をこなすようになった。専用演算器はなくなったが,SPが大幅に増加しているので,トータル的にFP64パフォーマンスは向上するという理屈である。
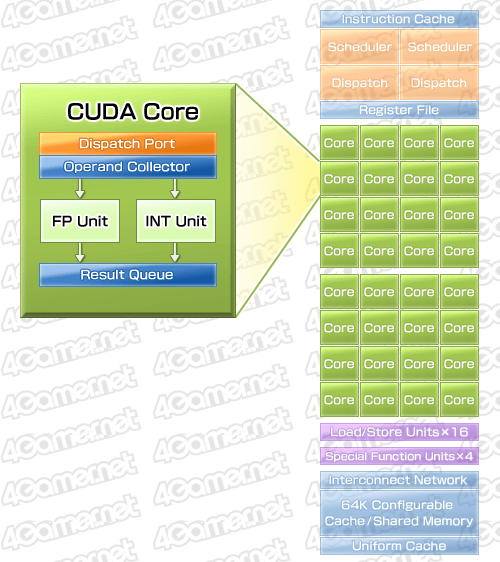 |
各SP内のFP32スカラ演算器は,Int32スカラ演算器と並列に動作できる。また,その演算精度はIEEE 754-2008準拠となり,さらにFP32,FP64両対応のFused Multiply Add(FMA)命令にも対応する。各SPはアドレス空間の64bitアドレッシングが可能となったとのことだが,これは,GPGPU向けの拡張だと見ていいだろう。
ところでIEEE 754-2008とは,浮動小数点演算における誤差の丸め方の規定,計算時の例外処理事例などを,近代のHPC環境に合わせて規定した規格。FMAとは,厳格な精度規定がなされた積和算手法のことだ。
Fermiのキャッシュ関連のアーキテクチャでGTX 200シリーズから大きく変わった点としては,もう一つ,大容量768KBのL2キャッシュ搭載が挙げられる。これは,16基のSM(≒512基のSP)すべてから共用されるキャッシュメモリである。
FermiベースのGeForceでいうとグラフィックスメモリに当たるメモリには,駆動クロックの4倍のデータレートのメモリ帯域幅が得られる,GDDR5が採用される。GeForceファミリーの中上位モデルでは,コスト的な理由を掲げて,長らくGDDR3を採用し続けてきたが,ついにFermi世代ではGDDR5が採用されるわけだ。
FermiベースのHPC向けGPGPU製品では,メモリシステムにECC(Error Checking and Correcting)が組み込まれるとのこと。これはデータ信頼性が重視されるHPCに配慮した仕様だろう。
メモリクロックは未公開だが,メモリバス幅は384bitと発表されている。64bit×6ブロックで384bitという構成になるはずなので,ROP(Rendering Output Pipeline)ユニットは6基ということになるはずだ。
ただし,NVIDIAのROPユニットは1クロックで複数ピクセルの出力を行うので,実際のクロック当たりピクセルスループットは不明。仮に,GTX 200から変わらず,ROPユニット1基の出力が1クロック当たり4ピクセル+4Zの出力だったとすると,24基(=4ピクセル×6ROPs)相当ということになり,GTX 280比でスペックダウンとなるが,ここについては,最終的な仕様を見てみるまで判断できない。
 |
実際の製品発表はいつか?
GTC期間中の続報にも期待
今回,次世代GPUについて情報公開を許可されたのは,このあたりまで。
米国時間9月30日から10月2日までの日程で,NVIDIAは,自社製GPU技術を広く活用していくための技術交流会議「GPU Technology Conference 2009」(GTC 2009)を開催中だが,今回の発表が,このイベントを盛り上げるための話題作りであることは明白。その意味では,Fermiベースとなる実際のGeForce製品やGPGPU製品についての詳細,もしくは何らかの続報が,会期中に公開される可能性についても期待は高まるところだ。
続報があり次第,お届けしよう。
- 関連タイトル:
 GeForce GTX 400
GeForce GTX 400 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation

4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー