










ニュース
デイビッド・カーク氏来日,CUDAカンファレンス2008開催
 |
NVIDIAからは,”GPUの父”ことチーフサイエンティストDavid Kirk(デイビッド・カーク)氏が来日して講演を行ったほか,GDCでも紹介したプロメテックソフトウェアのパーティクル,長崎大学の多体問題,慶応大学の分子力学など,日本で実際に研究されているCUDAの活用事例についての紹介が行われた。
なんでも,CUDAでの最初の事例は日本から報告された経緯もあるそうで,わざわざ御大デイビッド・カーク氏が訪れるあたり,NVIDIAが日本でのCUDA展開に力を入れていることが分かる。
 |
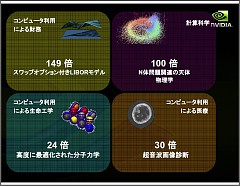 |
CUDAを使ったアプリケーションはすでに実用化されており,膨大な数に及ぶ投資情報をリアルタイムで処理したり,テラバイト/ペタバイト単位のデータを使った人工地震波の油田開発での利用や超音波画像診断処理などに成果を挙げているという。これまで一晩かかっていた処理が10分程度でできるようになると,作業の内容そのものが変わってくる。GPUコンピューティングは,すでに一部の産業を変えつつある。
 |
 |
次いで国内の各講演者によるCUDAの活用事例紹介が行われた。長崎大学の濱田剛氏は,単純な処理なら500GFLOPSを超える処理が可能なことをデモで示した。演算内容が複雑になると処理効率は落ちるとことわりは入ったものの,それでも多くの実例ではCPU処理の10倍から100倍以上の性能を発揮していることが示された。
 |
 |
長崎大学工学部工業情報システム工学科濱田剛氏のプレゼンより,CPUとGPUでの多体問題シミュレーション例。CPU(1コア)では0.5GFLOPS程度,GPUでは250GFLOPS程度の速度が出ていることが分かる
扱う星の数を増やすと演算部分の割合が増え,さらにFLOPSが上がる。650GFLOPS程度まで確認できるという
物理演算関係のデモを行ったプロメテック・ソフトウェアによれば,運動の自由度の高いパーティクルベースの処理は,現状で一番複雑な物理シミュレーションに属するという。CPUとの速度比は示されなかったものの,複数のGPUを使用することで,(拘束の多い)布などの物理シミュレーションであれば,さらに効率的に処理できるとしている。つまりは,ほとんどの物理シミュレーションはリアルタイム処理が可能ということだ。
一方で,GPUの演算性能は1年間で2倍に進化すると明言されている。ムーアの法則の2倍のペースである。ただ,最近は隔年ごとに「GX2」でお茶を濁されている感はあるのだが,今年の冬あたりは,2TFLOPSクラスのGPUが出てこなければならないはず。CUDA関係者も期待していることだろう。
今回のカンファレンスの主題は,マルチGPUへの最適化だ。CUDAを使って並列演算を行う場合,1GPUで演算を行うことでもかなり並列度を上げることができる。しかし,GPUに内蔵された演算器の個数には限度があり,大規模な処理では複数のGPUを使った並列演算が必要になってくる。1GPUでは,それぞれの演算器は独立していても,グラフィックスカード上では共通にメモリをアクセスできるので,データのやり取りは比較的楽に行えるのだが,複数のGPUではそれぞれのグラフィックスカードに搭載されたメモリを相互に参照させることは難しい。単独のGPUのときとはまた違った最適化が必要になるわけだ。
実例として紹介されたさまざまな事例では,どのような条件でマルチGPUが効果を発揮するのか(スレッド数が10000以上が望ましいらしい),GPU間でデータをやり取りする際はどのような処理になるのかなどが紹介された。
東京大学/プロメテック・ソフトウェアの原田隆宏氏/政家一誠氏のデモより,GPU数による処理の比較。順にGPU1個,2個。4個でのパーティクル処理を行っている
慶応義塾大学理工学部機械工学科成見哲氏/坂牧隆司氏のプレゼンより,分子運動シミュレーションの例。これは食塩の結晶を加熱したときの様子。融点を超えると液状化し,温度が下がると再結晶していく様子がシミュレートされている
 |
CUDAは,GPUでのプログラムをC言語で記述できるようにする環境である。加えて,マルチGPUでの処理にも簡単に対応できる。最近はゲームにおいても物理演算は重要なトピックとなっており,ゲームの処理でCUDAが使われていく可能性も無視はできないだろう。将来的には,演算用のGPUとレンダリング用のGPUを使うようなことも,当たり前になってくるのかもしれない。
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー