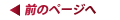ハイエンドのRadeon HD 2900ではメモリインタフェースがリファインされ,512bitのリングバス(Ring Bus)アーキテクチャが採用された。512bitのグラフィックスメモリインタフェースは世界初採用となる。
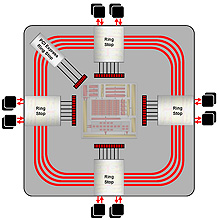
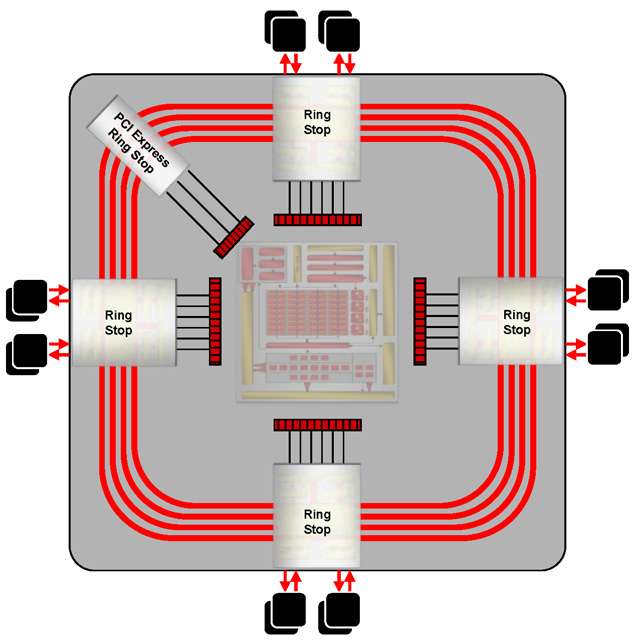
Radeon HD 2900が持つ512bitのリングバスアーキテクチャ
リングバスは,「プレイステーション3」のCPU「Cell」の内部バスにも採用されているアーキテクチャだ。山手線のような環状のバスラインを設け,いくつか“駅”となるところにメモリコントローラを置く。そして,駅と駅の間でデータのバケツリレーを行いながらデータの入出力を行うのが基本概念となる。
駅となるメモリコントローラはリングストップ(Ring Stop)と呼ばれるが,Radeon HD 2900では4個のリングストップが配され,そこから実際のメモリチップに向けてバスラインが伸びるような設計となっている。各リングストップは,前述した4基のレンダーバックエンドのブロックと接続されるイメージだ。
あるメモリアクセスのリクエストが3時方向のリングストップに対して来たものの,当該リングストップに接続されたグラフィックスメモリには希望のデータがなかったとしよう。このときリングバスメモリコントローラは,当該メモリがどのリングストップ管理下にあるのかを見極めて最短経路を割り出し,そのリングストップに対してのリクエストを隣のリングストップに問いかける。12時方向や6時方向のリングストップに希望データがあった場合は隣に問いかけるだけですぐにデータが帰ってくるが,9時方向のリングストップにあった場合,隣のさらに隣のリングストップにまでリクエストをバケツリレーしなければならず,遅延時間が大きくなる。
こう聞くと,あまりよいところが見当たらないリングバスだが,メリットはどこにあるのか。実は,速度だけを求めるなら,中央にメモリコントローラをおいてすべてのメモリチップの制御を行う,(Radeon HD 2600/2400やGeForceが採用する)集中型クロスバーアーキテクチャのほうがいい。
ただし,グラフィックスメモリ搭載量の増加が要求され,より大きな帯域も必要とされると,グラフィックスメモリバス帯域幅を広げる必要が出てくるが,グラフィックスメモリバス帯域幅の拡大は,メモリコントローラチップから膨大な数のピンと配線が伸びることを意味する。ピン配列やそこからの配線といった部分は,いわばアナログ回路的,あるいは物理設計的な世界であり,メモリコントローラチップと基板(=カード)とのボンディング(接着)技術の兼ね合いまで絡めると,この問題はプロセッサのトランジスタシュリンクとはまた別次元の難しさがあるのだ。
メモリコントローラや配線の複雑性などの物理的な問題を回避しつつ最大パフォーマンスを得るには,メモリコントローラに配線を集中させなくてすむリングバスアーキテクチャが都合がいいのである。
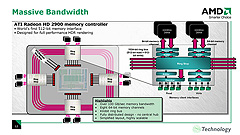
各リングストップの詳細
Radeon HD 2900の各リングバスを結ぶバスラインは左回り256bit×2の512bit,右回り256bit×2の512bit。上り下りで合計1024bitなわけだが,言葉の響きだけをとって1024bitリングバスといわないあたりは潔い(その昔,Matroxは「Parhelia-512」で上り下り各256bitを合計して,“世界初の512bitメモリバス採用GPU”とアピールしたことがあった)。
ところで,リングバスシステムの全体ブロック図の10時方向に,PCI Expressバスのリングストップが用意されていることに気付いただろうか。これは,PCI Expressバスを通じてシステムメモリ(=メインメモリ)にアクセスするためのリングストップになる。もちろん外部バスを通じることになるのでとてつもなく遅いが,グラフィックスメモリが不足した場合には,代替メモリとして利用できるわけだ。
リングバスシステムに組み込まれる形での実装になっているため。メモリ関連のリクエストがグラフィックスメモリ側に対して行われるのか,メインメモリ側に対して行われるのかを,GPUは関知する必要がない。GPUは透過的にメインメモリにもアクセスできるのである。いずれにせよ,ドライバレベル(=ソフトウェアレベル)でつじつまを取るのと比べれば,この仕組みは十分速いといっていいだろう。
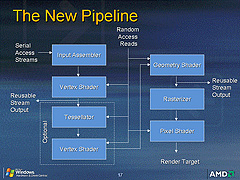
Windows Vista世代のグラフィックスサブシステムを「WGF」(Windows Graphics Foundation)と読んでいた最初期の計画を示したスライド。テッセレータの組み込みが検討されていた
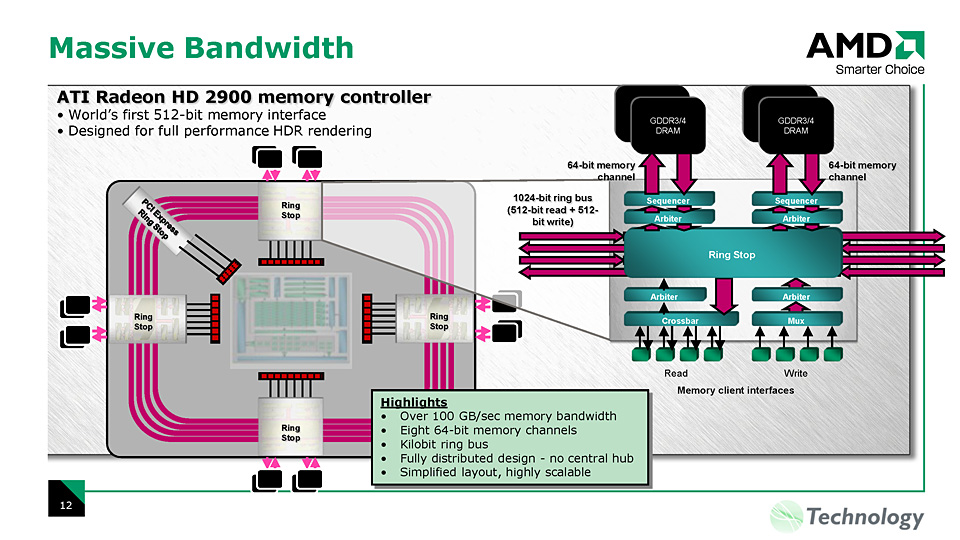
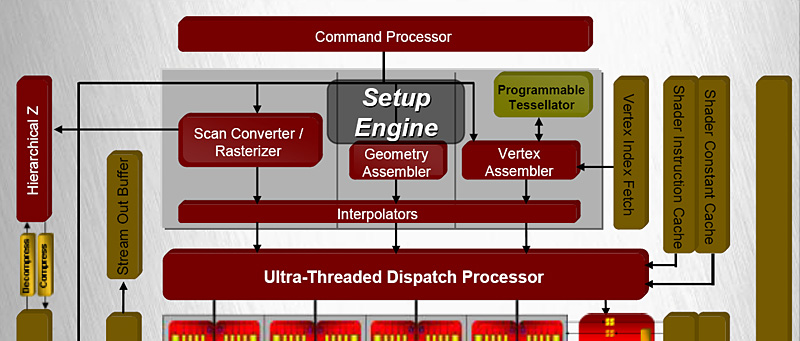
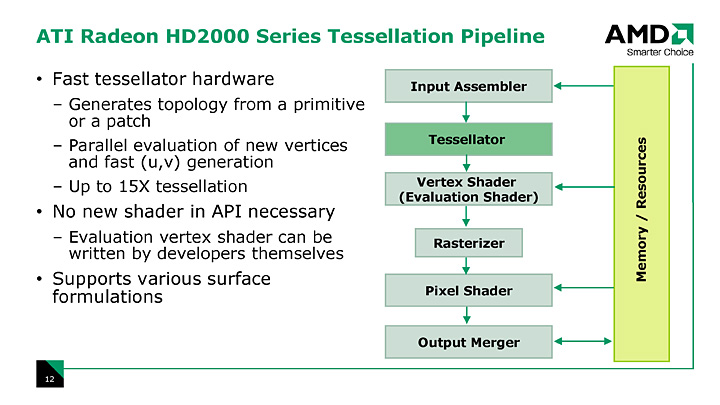
ATI Radeon HD 2000シリーズには,GeForce 8にはない,次世代DirectXの機能を先取りした機能が搭載されている。それが「プログラマブルテッセレーションユニット」(Programmable Tessellation Unit,以下プログラマブルテッセレータ)だ。
DirectX 10計画の初期においては,プログラマブルテッセレータを仕様として組み込むことが検討されていたが,実際には延期され,2007年5月現在では,次世代以降のDirectXで実装されることになっている。筆者の勝手な予想としていわせてもらうと,次のDirectX 10.1はGPU仮想化を中心としたマイナーチェンジ版となるはずなので,実装されるのはDirectX 11以降と考えるのが妥当なのではないだろうか。
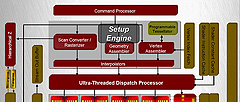
4度登場と相成った,Radeon HD 2900のブロックダイヤグラム最上部。プログラマブルテッセレータは頂点アセンブラの補助ユニット的に実装されている
ところでテッセレータとは,特定のメソッドに従ってポリゴンを分割する機能を果たすユニットだ。「ポリゴンを分割する」と聞くと,「ポリゴンの数を増減できるジオメトリシェーダと何が違うのか?」と疑問を抱く人もいると思うが,テッセレータはポリゴン分割すること“だけ”に機能を絞った専用ユニットである。
ATI Radeon HD 2000シリーズのブロックダイヤグラム全体を改めて見返してみるとよく分かるが,同GPUシリーズにおいて,プログラマブルテッセレータはセットアップエンジンのブロックに実装されている。データ処理的な観点からいうと,入力頂点データ列を加工するような役割を果たすので,頂点アセンブラの補助ユニットのような形での実装が行われているわけだ。
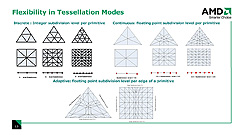
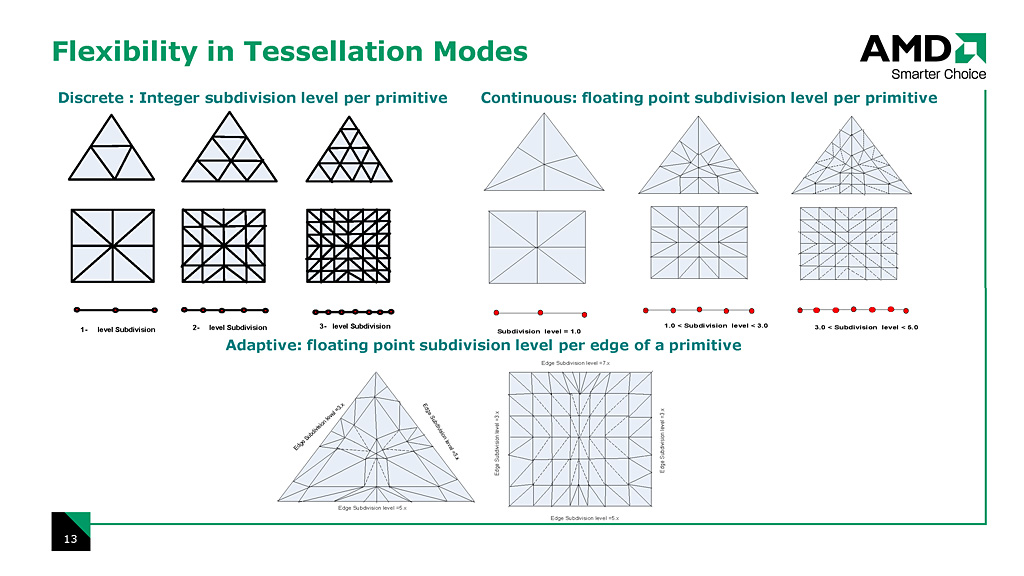
3テッセレーションモードへの対応を謳うスライド
ATI Radeon HD 2000シリーズのプログラマブルテッセレータは,離散型(Discrete),連続型(Continuous),適応型(Adaptive)のすべてのテッセレーションモード(=分割モード)に対応する。同GPUシリーズが搭載するプログラマブルテッセレータ自体は1基のみだが,非常に高速で,ここが頂点スループットのボトルネックになることはまれという。
ポリゴン分割倍率因子は最大で15.0倍までが与えられ,連続型/適応型分割では小数点を含んだ実数倍の分割も可能だ。
ポリゴンの分割メソッドや,あるいは生成した曲面を複数のポリゴンに分割して再現するメソッドは,さまざまなものが考案されている。分割メソッドとして代表的なのは旧ATI時代に「TRUFORM」として実装したことがあるN-Patch法,曲面再現メソッドとしてはベジェ,Bスプライン,NURBSといったものがよく知られている。
ATI Radeon HD 2000シリーズのプログラマブルテッセレータで分割されたポリゴンは,テクスチャ座標(u,v)は生成されるものの,ただ分割されただけの状態だ。希望する,そうした分割メソッドになるようにするには,後処理で頂点シェーダにて頂点座標を変位させる必要が出てくる。
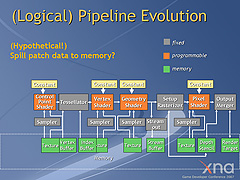
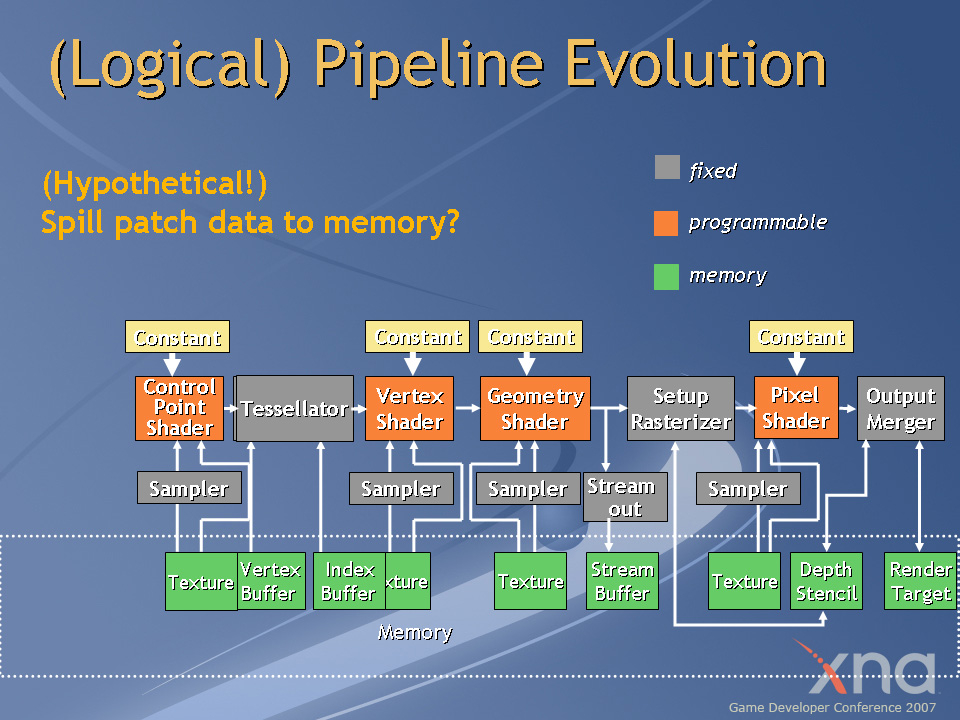
GDC 2007でマイクロソフトが予告した次世代Direct3Dの形。テッセレータが固定ユニットとして実装されている
ATI Radeon HD 2000シリーズで実装されるプログラマブルテッセレータは,将来検討されている次世代DirectXのテッセレータとはかなり違うもののようなのだが,それでもメリットはある。それは,新しいプログラマブルシェーダフェーズが要らないので,互換性を維持したままテッセレータを活用できるという点だ。分割したポリゴンの後処理を頂点シェーダプログラム側に統合できるため,テッセレータを活用できない既存のグラフィックスカードで動作させる場合と,ATI Radeon HD 2000シリーズで動作させる場合とで,ゲームデベロッパが用意する頂点シェーダプログラムは,基本的にテッセレータ後処理のなし/ありの違いを設けるだけで済む。フロー制御で対応できるかもしれない。

ATI Radeon HD 2000シリーズにおけるテッセレーションフェーズの位置付け。頂点シェーダの後処理で分割したポリゴンにポストプロセス処理するようなイメージになる
また,ATI Radeon HD 2000シリーズのプログラマブルテッセレータは,Xbox 360-GPUに内蔵されているそれとほぼ同一のものなので,テッセレーションを採用したXbox 360用タイトルのPC移植版を,より高い再現性を持って動かすことも期待できる。
というわけで,相応に魅力的な機能ではあるのだが,競合と足並みの揃わなかった機能でメジャーとなったものは少ない。実際のPCゲームで活用される機会はほとんどないと思われる。
GeForce 8800の登場が2006年11月だったので,AMDは6か月遅れたことになったが,今回の発表ではデスクトップ&モバイルをハイエンドからローエンドまで一気に発表してきたので,(最大限甘めに採点すれば)「“出遅れた感”は最小限に食い止めた」と言えなくもない。むしろ,ハイエンド製品を必ずしも重視していない人達からすると,DirectX 10世代/SM4.0対応GPU戦争は,むしろ「今やっとスタートした」というイメージかもしれない。
「今世代で,総合的にどちらが優れているのか」ということは,まだすべてが出揃ったわけではないこのタイミングでは結論を下しようがないが,少なくとも今回の発表において,AMDが(かつてのATI時代とは異なり),「競合のハイエンドモデルの性能をこれだけ上回った」というようなアピールをしてこなかったことは憶えておきたい。
チュニジアの事前説明会においても,Radeon HD 2900 XTとベンチマークスコアで比較されたのは,同価格帯の「GeForce 8800 GTS」だった。なぜ「GeForce 8800 GTX」と比較しなかったのかについては,説明会のQ&Aセッションでも当然ツッコまれていたわけだが,AMDはこれについて「ATI Radeon HD 2000シリーズは“価格対性能”(コストパフォーマンス)を重視している」とだけ回答しており,これまでのがむしゃらハイエンド性能競争を敬遠した節がある。どうやらAMDは,GPUの最高性能追求については2チップ以上,すなわちCrossFireソリューションで目指す戦略に切り換えてきたようだ。
なお,チュニジアでは詳細に関してノーコメントを貫いたものの,「次世代CrossFire」の存在をほのめかすコメントもあった。もしかすると,NVIDIAの“GX2”的なCrossFireソリューションへの対応を計画しているのかもしれない。

![[西川善司の3Dゲームエクスタシー]「ATI Radeon HD 2000」シリーズのGPUアーキテクチャ徹底解説](img/title.jpg)