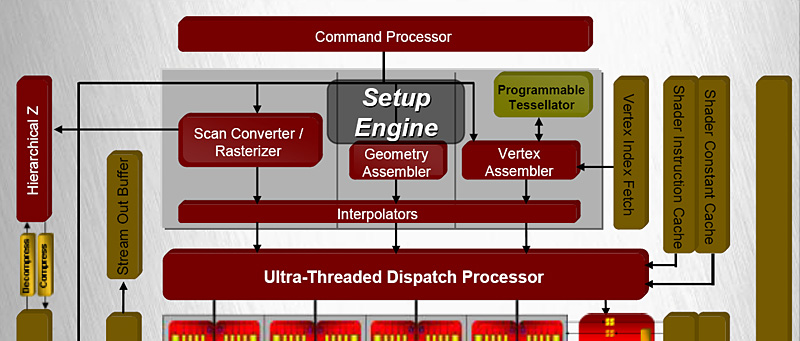
ブロックダイアグラムの最上段にあるのが「コマンドプロセッサ」(Command Processor)だ。
コマンドプロセッサ自体は,旧ATI時代の「ATI Radeon 9700」から搭載されているもので,簡単にいえば,その役割は「ドライバソフトウェアとGPUコアの橋渡しを行う存在」ということになる。
1ページめの冒頭で紹介したAMDのDemers氏によると,ATI Radeon HD 2000シリーズのコマンドプロセッサは「x86プロセッサではないが,メモリからマイクロコードを読んでプログラムを実行するCPU的なフルスペックプロセッサと思ってもらいたい」そうで,いわばGPUを制御するサブCPU的なものになっている。
前ページで紹介したRadeon HD 2900のブロックダイアグラム最上部を再掲
要するにPCI Expressバスを通じてドライバから送られてきたコマンドを処理するプロセッサなのだが,これまでの3Dグラフィックスにおいて,「アプリケーションから依頼されたタスクを,GPUが実行すべきコマンドに変換する」処理は,GPUではなく,ドライバソフトウェア,つまりシステムに搭載されたCPUが実行していた。ATI Radeon HD 2000シリーズのコマンドプロセッサは,これまでCPUで処理されていた,このドライバソフトウェアのタスク(のかなりの部分)を肩代わりする。
これにより,実際のアプリケーション実行時において,(ドライバによる)CPU負荷が従来のATI Radeonと比較して平均30%も低減されたとのことだ。
個々のコマンドプロセッサはもちろんGPU側にあるため,GPUコア側のステータスチェックがリアルタイムに行える。GPUの現状ステータスに都合のいい,換言すれば最大パフォーマンスが得られやすいコマンド発行のスイッチングまでが可能になるというわけ。
あえていうならば,この新コマンドプロセッサのおかげでATI Radeon HD 2000シリーズのドライバは,AI的な適応型の処理が行えるようになったのである。
ブロックダイアグラムでコマンドプロセッサの下にあるのが「セットアップエンジン」(Setup Engine)だ。
1ページめで紹介したRadeon HD 2900のブロックダイアグラム最上部を再び
セットアップエンジンというと,従来のGPUでは,ポリゴンからピクセル単位のタスクに分解するトライアングルセットアップを行う存在,すなわちラスタライザ(=ラスタライジングユニット)を連想するが,統合型シェーダアーキテクチャのGPUでは,“シェーダ”セットアップエンジンともいうべき多様な仕事が任されるようになっている。
実際のGPUにおいては,これ以降のフェーズにおいて汎用シェーダユニットが頂点/ジオメトリ/ピクセルいずれかのシェーダユニットとして起用され,実際に仕事をするのだが,そのために必要なデータを揃えてやるのがこのセットアップエンジンの役割だ。
セットアップエンジンには大別して三つのユニットがある。一つめは「頂点アセンブラ」(Vertex Assembler)。これは頂点シェーダが必要とする頂点バッファやインデックスバッファのアドレスデータをまとめる仕事をこなす。また,そのサブユニットとして,ポリゴンを分割するATI Radeon HD 2000シリーズのオリジナル機能「プログラマブルテッセレーションユニット」(Programmable Tessellation Unit)が必要に応じて活用される(同機能については後述)。
二つめは「ジオメトリアセンブラ」(Geometry Assembler)だ。これはジオメトリシェーダが必要とする複数頂点情報のまとめを担当する。
そして三つめは「スキャンコンバータ/ラスタライザ」(Scan Converter/Rasterizer)で,ポリゴン情報からピクセルシェーダ単位の処理に分解する仕事がここで処理される。これは,昔ながらのイメージのセットアップエンジンといえるトライアングルセットアップに相当する部分である。
1ページめで紹介したRadeon HD 2900のブロックダイヤグラム最上部を三度。結果として地味なページ展開になってしまっているが,説明の都合上必要なので,ご容赦いただきたし
ブロックダイアグラムでは味気のない横長のブロックになっているが,実際には統合型シェーダアーキテクチャのキモとなっているのが,セットアップエンジンの次に用意される「ウルトラスレッド・ディスパッチプロセッサ」(Ultra-Threaded Dispatch Processor,以下ディスパッチプロセッサ)だ。
言ってしまえば,汎用シェーダユニット(=ストリーミングプロセッシングユニット)を絶え間なく活用するために,どの汎用シェーダユニットを何々シェーダユニット(頂点/ジオメトリ/ピクセルのいずれかのシェーダ)として起用するかを制御するブロックである。
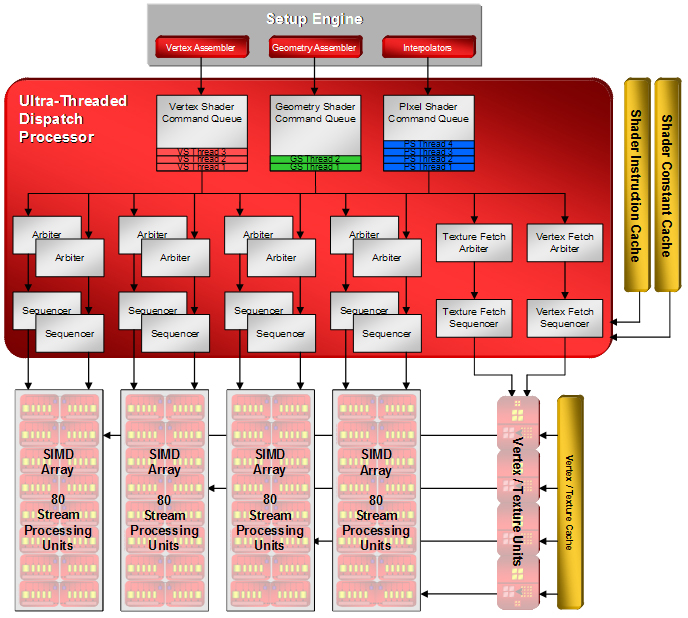
下がウルトラスレッド・ディスパッチプロセッサの詳細を示したブロック図なので,細かく見てみよう。セットアップエンジンから送り込まれた頂点タスク,ジオメトリ(プリミティブ)タスク,ピクセルタスクは「処理キュー」(Command Queue)に積まれ,実際に処理が行われるのを待つことになる。
この処理キューの状況や汎用シェーダユニットの空き状況を見て,実際に汎用シェーダを何々シェーダユニットとして起用するのが「調停ユニット」(Arbiter:アービター)だ。
ATI Radeon HD 2000アーキテクチャでは,汎用シェーダユニット5基を1単位として制御する構成が採用されている。これをAMDではSIMD(Single Instruction, Multiple Data)と呼び,さらに16単位を一つにまとめたものを「SIMDアレイ」(SIMD Array)と呼んでいる。SIMDの用法がコンピュータ用語一般とは違ったものになっている点は注意したい。
ちなみにRadeon HD 2900の場合,このSIMDアレイは4ブロック用意されている。SIMDアレイあたり80基(5×16)なので,汎用シェーダユニットの数は(2007年5月14日の記事でもお伝えしているように)320基というわけである。
ATI Radeon HD 2000シリーズのアーキテクチャにおいて,この調停ユニットは,1単位のSIMDアレイごとに2基割り当てられる設計になっている。2基の調停ユニットは異なるスレッドを管理し,1単位のSIMDアレイで異なる2スレッドを実行させる。このあたりはCPUのHyper-Threadingに代表される同時マルチスレッディング(SMT:Simultaneous Multi-Threading)に近い発想だ。
「汎用シェーダユニットでは“何々シェーダユニット”として起用され処理が始まるものの,例えばテクスチャユニットへのテクスチャ読み出しのような重いタスクが発生して,そのシェーダユニットが担当しているシェーダプログラムの実行がストールしてしまう」なんてことがある。その場合,調停ユニットは,「当該汎用シェーダユニットが現在実行しているスレッドを眠らせて,新たに別スレッドを持ち出して汎用シェーダユニットに別スレッドを実行させる」ようなことまでを行う。
接続されたキャッシュシステムなどもうまく活用し,スレッド切り替えを積極的に行って,極力メモリの読み書きのレイテンシを隠蔽しようとするウルトラスレッド・ディスパッチプロセッサ。ある意味,統合型シェーダシステムの司令塔のような役割を果たしているといっていいだろう。
なお,ブロック図に戻ると,テクスチャ読み出し順序を統括管理する「テクスチャ読み出し調停ユニット」(Texture Fetch Arbiter)や頂点読み出し順序を統括管理する「頂点読み出し調停ユニット(Vertex Fetch Arbiter)なども,このウルトラスレッド・ディスパッチプロセッサに内包されているのが分かる。このほか,調停ユニットとSIMDアレイの間には「シーケンサユニット」(Sequencer)があるが,これは各スレッドのシェーダプログラムの実行位置(=プログラムカウンタ)を統括管理するユニットである。
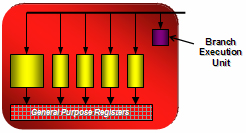
ストリーミングプロセッシングユニットのブロック図。5個の黄色いブロックがそれで,赤い枠はSIMDを示す
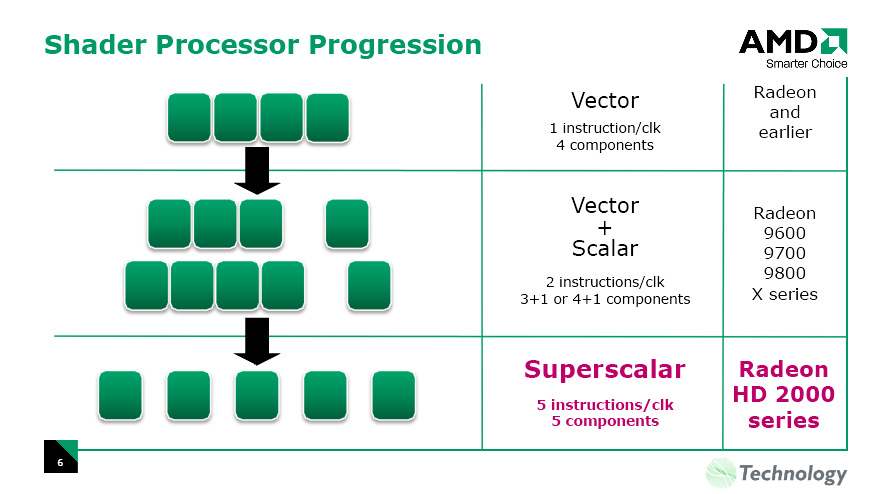
繰り返しになるが,SIMDアレイ1ブロックは16単位のSIMDからなる。また,SIMD一つ一つは5基の汎用シェーダユニット(=ストリーミングプロセッシングユニット)――正確を期すと,それらに加えて1基の「分岐実行ユニット」(Branch Execution Unit)も含まれる――からなっている。一つ一つの汎用シェーダユニットはスカラシェーダユニットだ。このあたりはNVIDIAのGeForce 8800シリーズが持つスカラシェーダユニットと大体同じような機能を果たせると考えていいだろう。ただし,1単位のSIMDを5ウェイのスーパースカラシェーダ(5-Way Superscaler Shader)ユニットとして機能させられるようになっているのがATI Radeon HD 2000シリーズの特徴だ。
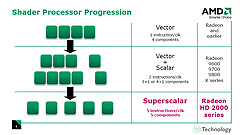
ATI Radeon HD 2000シリーズで5ウェイのスーパースカラシェーダユニットとして機能できるようになった
ATI Radeon X1000シリーズ以前は,「1スカラ演算を行える演算器+4要素ベクトル積和算をこなせる演算器」を「1シェーダユニット」としていた(頂点シェーダの場合)。これに対して今回のATI Radeon HD 2000シリーズでは,演算粒度を高めてスーパースカラ性能を上げるために,4要素ベクトル積和算器を4基のスカラ演算器に分解したようなイメージになる。
もう少し具体的に言い換えると,ATI Radeon X1000シリーズ以前においては,最大演算性能を出そうとすると,“1スカラ+4ベクタ”の形で演算を行わせるようにシェーダプログラムを工夫しなければならなかった(ピクセルシェーダの場合は1スカラ+3ベクタ)。一方ATI Radeon HD 2000シリーズではそうした制限が取り払われ,5基のスカラユニットの範囲で任意の要素数のベクトル演算とスカラ演算の組み合わせを同時実行できるようになったというわけだ。
さて,ストリーミングプロセッシングユニットのブロック図を見ると左端の汎用シェーダユニットだけ大きいが,これは1基だけ特別な機能が与えられていることを意味している。この“大柄な”汎用シェーダユニットにだけ,指数,対数,三角関数などといった複雑な超越関数(Transcendental Function)計算能力が与えられているのだ。なお,32bit浮動小数点演算精度,整数計算,論理演算,比較演算といった機能については5基の共通仕様。こんな仕様の固まりが,一つの“何々シェーダユニット”として起用され,実際の計算をこなすことになる。
計算結果は「汎用レジスタ」(General Purpose Registers)にストアされて次の命令実行に移るが,汎用レジスタには,レイテンシ隠蔽のため(ウルトラスレッド・ディスパッチプロセッサによって)眠らされたスレッドの実行途中のデータも保持される。要するにレジスタファイル,換言すれば一時メモリ的なブロックであり,ブロック図では小さく表現されているものの,実際には汎用シェーダユニットより何倍も大きい面積を占めている。汎用レジスタの割り当ては動的に行われるため,汎用レジスタがいっぱいにならない限り,複数のスレッドを取り扱い可能だ。

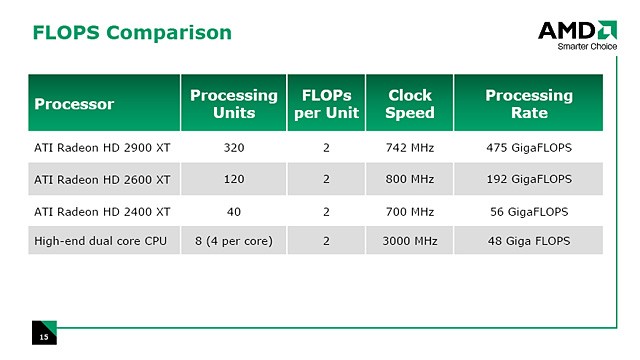
ストリーミングプロセッシングユニットとFLOPsの関係を示したスライド
ATI Radeon X1000のように,「最大何スレッドを取り扱えるか」というスペック値は公表されていないが,とにもかくにも汎用シェーダユニット数はRadeon HD 2900で320基。Radeon HD 2600シリーズでは3SIMDアレイが用意されるものの,1SIMDアレイを構成するSIMDの数が8単位となるため,5汎用シェーダ×8SIMD×3ブロック=120基となる。Radeon HD 2400シリーズだとSIMD 4単位で1SIMDアレイになり,2SIMDアレイ用意されるため,“5×4×2”で40基だ。
この計算式からも想像がつくように,汎用シェーダユニットの個数そのものはGeForce 8ファミリーと比べて多いものの,数=パフォーマンスとはならない。汎用シェーダユニット=ストリーミングプロセッシングユニット単体の能力の違いは無視するにせよ――ATI Radeon HD 2000シリーズもGeForc 8シリーズも,単体のストリーミングプロセッシングユニット/ストリーミングプロセッサが1クロックで浮動小数点の積和算をこなせる点は同じである――ATI Radeon HD 2000シリーズでは5基で1組となるうえ,GeForce 8800シリーズだと汎用シェーダユニットが1GHzを大きく超える高いクロックで動作するためだ(「GeForce 8800 Ultra」だと1.5GHz駆動)。実際の性能については,掲載されているプレビュー記事を参照してほしい。

![[西川善司の3Dゲームエクスタシー]「ATI Radeon HD 2000」シリーズのGPUアーキテクチャ徹底解説](img/title.jpg)