ATI Radeon HD 2900 XTリファレンスカードのイメージ
日本時間2007年5月14日1:01PM,AMDは,同社が買収した旧ATI Technologiesの手による,DirectX 10世代のプログラマブルシェーダ4.0仕様(Shader Model 4.0,以下SM4.0)に対応したGPU(グラフィックスチップ),「ATI Radeon HD 2000」シリーズを発表した。すでに4Gamerでは最上位モデル「ATI Radeon HD 2900 XT」のプレビュー記事を掲載しているので,そのポテンシャルを目にした人も多いことだろう。本稿では,そんなATI Radeon HD 2000シリーズのアーキテクチャ,とくに4Gamer読者が最も気になるだろう3D周りのアーキテクチャについて,解説していきたい。
なお,発表に先立ってAMDは,世界中の報道関係者を北アフリカのチュニジアに集めて説明会を行った。今回の記事は,その内容と,国内の報道関係者を対象に別途開催された事前説明会の内容を合わせたものになっている。
 |
 |
左:チュニジアで開催された説明会の開会挨拶をする,AMD(旧ATI Technologies)のRick Bergman(リック・バーグマン)副社長(Senior Vice President, AMD Graphics Products Group, AMD)
右:チュニジアでATI Radeon HD 2000シリーズについての説明を行ったEric Demers(エリック・デマース)氏(Senior Architect, AMD Graphics Products Group, AMD) |
ATI Radeon HD 2000シリーズはDirectX 10世代/SM4.0対応のGPUということで,「統合型シェーダアーキテクチャ」(Unified Shader Architecture)が採用されている。NVIDIAが「GeForce 8800」シリーズを発表したときにも統合型シェーダアーキテクチャの意義を解説したことがあるが,ここでももう一度振り返っておこう。

世界初のプログラマブルシェーダ搭載GPUとして話題になった「GeForce 3」
GPUは2000年のDirectX 8時代に,グラフィックステクノロジをソフトウェア実装するアプローチ「プログラマブルシェーダアーキテクチャ」を獲得し,これを主流として進化してきた。
このときからGPU内部には,頂点単位の処理をするプログラマブル頂点シェーダ(Programmable Vertex Shader,以下 頂点シェーダ),ピクセル単位の処理をするプログラマブルピクセルシェーダ(Programmable Pixel Shader,以下 ピクセルシェーダ),計2種類のプログラマブルシェーダユニットが設けられている。
3Dグラフィックスにおいて,一つのポリゴンが複数のピクセルから構成されて表示されることになるのはだいたい想像がつくはずだ。そうした理由から,(頂点シェーダユニットの数<ピクセルシェーダユニットの数)というバランスでGPUは構成されてきた。

Tom Clancy’s Splinter Cellシリーズで活用されているデプスシャドウ技法の例
だが,プログラマブルシェーダが高度化していくなかで,このバランスに変化が出てきた。
ここで少し,影生成技法について考えてみよう。「DOOM 3」などで活用されているステンシルシャドウボリューム技法では,光源から見て輪郭となる頂点を引き伸ばして影領域(=シャドウボリューム)を生成するので,頂点シェーダユニットに高負荷がかかる。
一方,「Tom Clancy’s Splinter Cell」シリーズで活用されているデプスシャドウ技法(シャドウマップ技法)では,光源から見た遮蔽構造を把握するため,「光源を仮想視点にしたシーン全体の深度値」を大きなサイズのテクスチャにレンダリングするので,ピクセルシェーダへの負荷が高くなる。
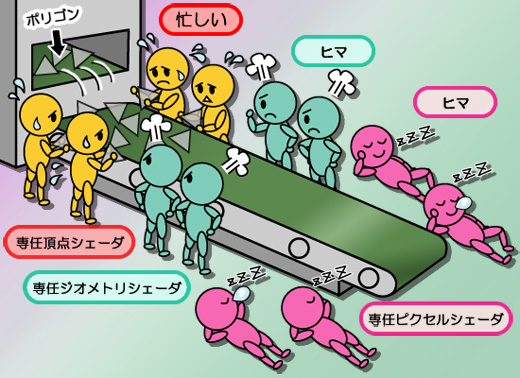
何がいいたいかというと,実際にプレイヤーの眼前に展開される1枚のシーンは,さまざまな負荷特性を持ったシェーダプログラムが複数実行されて作り上げられるので,局面局面に応じて頂点シェーダとピクセルシェーダにかかる負荷は随時変化するということだ。つまり,個数が固定的に実装された頂点シェーダユニットやピクセルシェーダユニットにシェーダプログラムを実行させると,どちらかのユニットがヒマでどちらかが忙しいという状況に必ずなる。それを示したのが
図1だ。
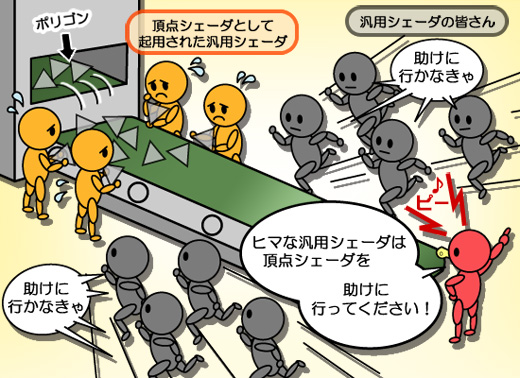
頂点シェーダにしろピクセルシェーダにしろ,シェーダユニットという演算器に着目すると,計算の意味は異なっても,実行される計算内容に大差はないどころかほとんど同じ。それなら,汎用のプログラマブルシェーダユニットを多数実装し,負荷バランスに応じて動的に,頂点シェーダユニットとして起用したり,ピクセルシェーダユニットとして起用したりするほうが処理は効率的に行えるはず――その流れで考案されたのが,図2に示した統合型シェーダアーキテクチャというアイデアになる。
実は,旧ATI Technologies(以下 旧ATI)は,この統合型シェーダアーキテクチャというものに,NVIDIAよりも前から慣れ親しんでいる。
そう,開発コードネーム「Xenos」こと「Xbox 360-GPU」だ。
Xbox 360-GPUは,DirectX 9世代/プログラマブルシェーダ3.0対応GPUであると同時に,世界初の統合型シェーダアーキテクチャ採用GPUでもあった。4Gamer読者であればご存じの人も多いと思うが,これは旧ATIによって設計されたGPUである。
ATI Radeon HD 2000は,そんなXbox 360-GPUの経験をベースとした,旧ATIにとっては第2世代の統合型シェーダアーキテクチャ採用GPUということになる。
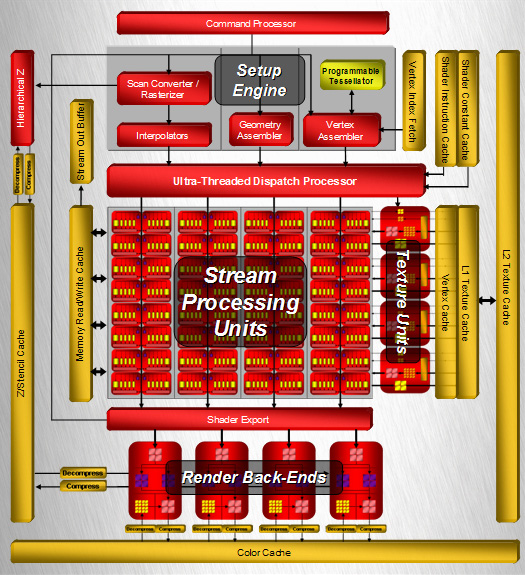
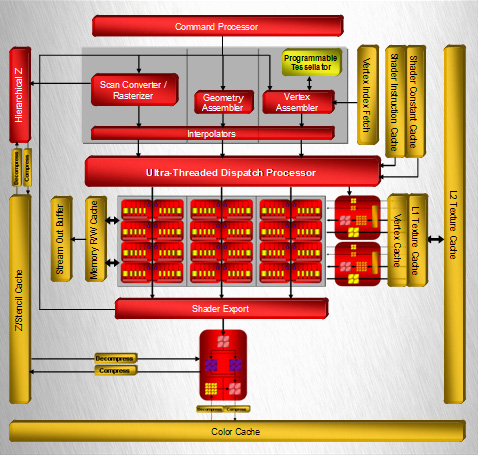
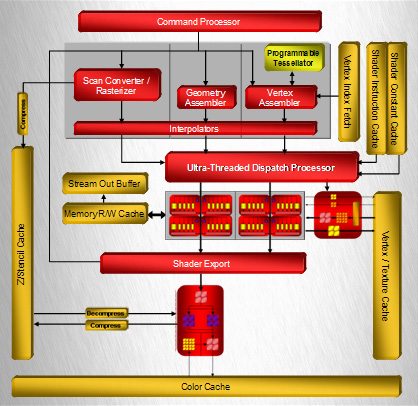
では,それはどんな思想に基づいたGPUなのだろうか。以下,ATI Radeon HD 2900 XT(以下Radeon HD 2900)のブロックダイヤグラムを中心に,「ATI Radeon HD 2600」(以下Radeon HD 2600)「ATI Radeon HD 2400」(以下Radeon HD 2400)のそれも並べてみた。基本的な構造は同じで,上位モデルになればなるほど汎用シェーダユニット=ストリーミングプロセッシングユニット(Streaming Processing Unit,NVIDIAのいう「ストリーミングプロセッサ」とほぼ同じ意味)の数,テクスチャユニット(Texture Unit)の数,そしてレンダーバックエンド(Render Back-Ends)の数が多くなっているのが分かると思う。
さらに細かく見ていくと,上位2モデルだと用意されている「頂点キャッシュ」(Vertex Cache)と「L1テクスチャキャッシュ」(L1 Texture Cache),「L2テクスチャキャッシュ」(L2 Texture Cache)が,Radeon HD 2400だと「頂点/テクスチャ兼用キャッシュ」(Vertex/Texture Cache)に統合されてしまっている。
この図で全体的なイメージを掴んでもらって,次ページからは実際の3Dグラフィックス処理が行われていく順に,各ブロックの詳細について見ていくことにしよう。