|
NVIDIA,新世代GPU「GeForce 8800」ファミリーを発表
NVIDIAから,開発コードネーム「G80」こと「GeForce 8800 GTX」,「GeForce 8800 GTS」の2製品が発表された。この製品群(以下GeForce 8)は,GeForce 6でのShader Model 3.0対応以来久々の,全面的に新しいアーキテクチャでの新製品となる。パフォーマンスや新アーキテクチャなどトピックは多いのだが,最も重要なのは,これがDirextX 10対応のGPUであるということだ。
今後のDirectXでは,DirectX 10で要求される機能をすべて満たしたハードウェアのみがDirectX 10対応を謳うことができる。これまでのようにサポートされてない機能があっても新しいドライバが出てくれば対応できるといったことはなくなる。
また,DirectX 10用のゲームは,DirectX 10対応GPUでしか動かない。当面は,Windows XP用にDirectX 9で作られたバージョンも併売されるとは思われるものの,DirectX 10での拡張部分は非常に大きく,最新ゲームを本来の姿で楽しみたいなら,DirectX 10対応のグラフィックスカードは必須となる。繰り返すが,既存のどんなにハイエンドな製品であってもDirectX 9世代のカードではまったく対応できない。
Windows VistaとDirectX 10で,ゲーム環境は大きく変わっていく。今後のグラフィックスカード選びで注目せざるをえないのが,世界初となるDirectX 10対応GPU,GeForce 8ファミリーである。
■NVIDIA史上,最大の飛躍を達成したGPU
NVIDIAチーフサイエンティストDavid Kirk氏
 |
NVIDIAチーフサイエンティストDavid Kirk氏(すべてのNVIDIA製GPUを設計した,GPUの神様といってよい人)は,プレス向けの説明会でGeForce 8シリーズの概要を解説した。
曰く,今回の製品は4年の歳月と400億円以上をかけて開発されており,NVIDIAの製品史上でも最大規模のパフォーマンスアップを実現しているということだ。
簡単に特徴をまとめると,以下のようになる。
・DirectX 10対応
・ジオメトリシェーダ
・統合型シェーダアーキテクチャ
・超高画質指向
それぞれについては後述するとして,手っ取り早く最終的な性能から見ていこう。
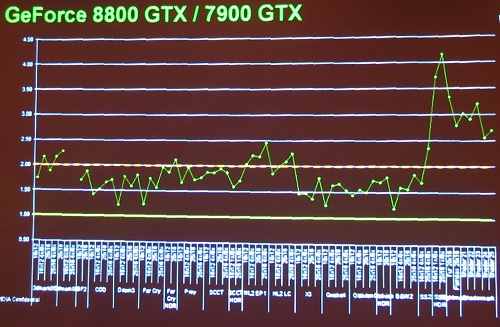
この業界では,新製品が毎年2倍の性能になっているのは恒例のことではあるのだが,数字上のスペックは2倍になっても,実際のゲームでの性能比はさほど上がっていたわけではないのも事実である。各種アプリケーションベンチでの結果を,昨年の状況と比較しよう。
GeForce 8では,全体に1.5〜2.0倍の範囲にプロットが集まっているのが分かる。
GeFoece6からGeFoece7における性能向上グラフの縦軸の目盛りが0.2倍ずつ上がっているのに対し,今回のグラフは最低目盛りが0.5刻みであることに注意していただきたい。また,6→7の比較が1600×1200 4x/8xという当時のハイエンド環境のみでの比較であるのに対し,7→8のグラフは多彩なモードでベンチマークが取られている。見ると,伸び率が落ち込んでいる部分は,各ゲームで負荷の低い設定であって(それでも以前のハイエンド設定だが),高負荷設定になるほど性能差が広がっている傾向が見える。つまり,実質の性能伸び率はかなり高くなっており,現世代のゲームの1600×1200 4x/8x程度では,すでに飽和傾向にあるということである。
スペック上で性能を2倍にしたり,3DMarkなど,GPU負荷の非常に高いベンチで性能を2倍にすることはさほど難しくはない。実際のゲームでは,CPUがボトルネックとなりがちで,GPUの性能アップだけではそう簡単に2倍になることはない。ほぼ2倍近いフレームレートが達成されているというのは,実に驚くべきことだ。GeForce 8では,実際のゲームベンチレベルでもかなり大きな性能向上を果たしており,余裕すら感じさせる。まさに次世代ゲームのためのGPUというにふさわしい仕上がりといえるだろう。
■GeForce 8の構成
では,少しずつ詳細を見ていこう。GeForce 8800 GTXのスペックは以下のようになっている。
コアクロック 575MHz
ストリーミングプロセッサ数 128
シェーダクロック 1350MHz
メモリバス幅 384bit
メモリ方式 GDDR3(768MB)
メモリクロック 900MHz
予想価格 599ドル(約7万2000円)
ここで「ストリーミングプロセッサ」と書かれているものが,従来のシェーダユニットに相当するものだ。GeForce 8では,統合型シェーダ(Unified Shader)方式が採用されており,それぞれのストリーミングプロセッサが,従来のピクセルシェーダとして使われたり,頂点シェーダとして使われたりすることになる。これが128基も用意されており,詳細は後述するが,莫大な演算パワーの源となっている。
メモリバス幅はGeForce 8800 GTXが384bit,GeForce 8800 GTSでは320bitとなっている。これまでのGPUに慣れていると,なにやら半端なビット数に思えるのだが,これは,メモリを64bit×6バンクないし64bit×5バンクとして使用しているためだ。これまでの64bit×4のような,2のべき乗数と比較すると,複雑というか,アドレス空間がどのような配置になっているのか想像しにくいのだが,どのバンクも機能の違いはなく,同列にアクセスされているようだ。
グラフィックスメモリにはGDDR3メモリが採用されている。低電圧かつ高速なGDDR4メモリは,コスト高で採用が見送られたという。とはいえ,GeForce 7世代で使われていたものより高速なチップが採用されており,メモリ帯域幅は計算上,GeForce 7900比で70%程度増えることになる。
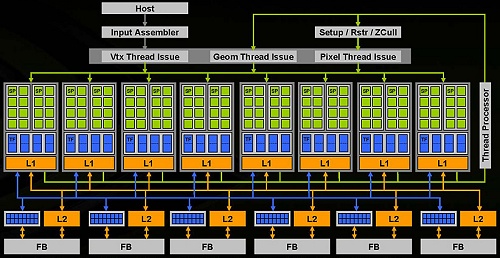
GeForce 8800 GTXのブロックダイアグラム
 |
|
|
DirectX 10での3D処理の流れ
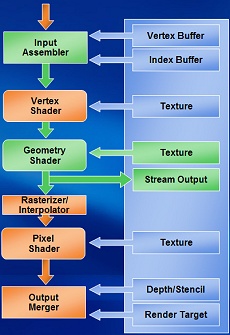 |
DirectX 10の処理の流れ(右)と見比べつつ,ブロック図(上)を見てみよう。
データアセンブラから入った処理は,まず頂点シェーダ部分が処理される。頂点処理のスレッドが発行され(Vtx Thread Issue),シェーダユニット群に渡される。シェーダでは,ストリーミングプロセッサ(図中SP)がまず頂点シェーダとして使われる。このとき必要があれば,グラフィックスメモリ(=フレームバッファ:図中FB)側からデータを取り込んで参照する。データは,L1,L2キャッシュを介して接続されていることが分かる。なお,これまでのGPUでもL1,L2キャッシュは使用されていたのだが,ブロックダイアグラムには明記されていなかった。今回は,それだけ重要な位置にあるということだろう。
頂点シェーダの処理が終わると,処理はジオメトリ処理,ピクセル処理に移行する。このあたりはスレッドプロセッサが管理して,それぞれの処理のスレッドを発行している。上半分を何周か処理が回っている感じだ。
下半分で,TFとあるのは,テクスチャフィルタである。L2キャッシュと併記されているのはROPユニット(あるいはそのようなもの)で,6バンクのグラフィックスメモリに対し16個ずつの四角形で示されている。
テクスチャフィルタでは,通常1クロックあたり32ピクセル分のアドレスを同時に扱うようになっているのだが,2xの異方性フィルタリングやFP16バッファでのフルスピードテクスチャリングを実行するため,1クロックあたり64ピクセルのバイリニア処理を可能としている。
ROP部では,1クロックあたり96個の色情報と96個のZ情報を同時にサンプリングし,1クロックあたりでは最大24ピクセル分のアンチエイリアシング処理を実現している。これで最終的な描画が完成する。
ブロックダイアグラム中で下半分のシステムをNVIDIAでは,ルミネックスエンジン(Luminex Engine)と呼んでいる。フィルタリング処理を,ほとんどペナルティなしで実行し,さらに,かなりの高画質化も図られているという。このエンジンでは,128bitでのHDR(High Definition Dynamic Rendering)処理,16xアンチエイリアス処理,そしてHDRバッファでのアンチエイリアス処理を実現している。
David Kirk氏曰く,これまでのGPUでは,このあたりの画質が低くてクレームがあったらしいのだが(ついぞ聞いたことはないのだが,NVIDIAが最近手を染めている医療系や映画関係からだろうか?),今回のエンジンではそのあたりも万全であると自信を見せていた。
■新世代のアーキテクチャはどこが変わったのか?
GeForce 8で気をつけるべき点は,とにかくこれまでとは,まったくアーキテクチャが異なるという点だ。統合型シェーダになったのだから当然という話もあるが,そういったレベルではなく,処理の方法がまったく変わっている。むしろ,同じ「シェーダ」という単語を使用しているのが紛らわしいくらいである。
以下では,キーとなる概念を紹介してみよう。
●統合型シェーダ
前述のとおり,汎用のユニットでさまざまなシェーダの演算を行う方式である。Xbox 360でも採用されているアーキテクチャだ。
これまでのGPUでは,頂点シェーダとピクセルシェーダが固定数で用意されていた。頂点シェーダ5基とピクセルシェーダ12基とか,そういった具合だ。だが,ゲームによっては頂点シェーダを多用するものもあれば,ピクセルシェーダを多用するものもある。これは同一ゲーム内のシーンでも変わってくる。
例えば,右手に頂点シェーダで枝を揺らしまくっている森があって,左手に複雑な映り込みでピクセルシェーダを使いまくっている水面があるといったシーンでは,右を向くと頂点シェーダが,左を向くとピクセルシェーダがボトルネックになる可能性がある。
また,新しく加わるジオメトリシェーダについては,まったく使用されないシーンもあると思われるので,専用ユニットを用意するのは無駄が大きい。こういったものを動的に負荷分散できれば,GPUの使用効率を大きく上げ,ゲームの品質も高く維持できるわけだ。これが統合型シェーダの利点である。
DirectX 10では,シェーダごとの機能差を意識せずにシェーダプログラムを書けるようになっており,汎用のユニットで対応するのは合理的である。ただ,DirectX 10対応だからといって,必ずしも統合型アーキテクチャである必要はない。というか,DirectX 10では統合型シェーダに移行する予定だったマイクロソフトに対し,NVIDIAが難色を示したため,マイクロソフトが譲歩して統合型でない実装も許容とされたという経緯があったように思うのだが,結局のところ,NVIDIAも統合型シェーダに落ち着いている。
●Shader Model 4.0(SM4.0)
SM4.0は,SM3.0の純粋な拡張といえるだろう。多くの命令が追加された結果,一般的なCPUに近くなり,シェーダユニットでより一般的なプログラムが実行できるようになった。もちろん,より自由度の高いシェーダプログラムを書けるということでもあるが,シェーダ以外のプログラムが作りやすくなった。命令数制限も撤廃され,これからのGPUは,いままで以上にさまざまな用途で使用されていくことになるだろう。
●固定機能の廃止
プログラマブルシェーダ登場以前のグラフィックス描画は,すべてさまざまな「固定機能」を利用していた。固定機能とはすなわちプログラマブルシェーダでないもの,言い換えるとDirextX 7までにサポートされていたすべての機能が含まれ,フォグや頂点ブレンディングなど多くのものがある。
DirectX 10世代のGPUでは,固定機能は廃止され,すべてプログラマブルシェーダで置換される。従来,かなりのシリコン面積を占めていた固定機能がなくなったことで,グラフィックスパイプラインは身軽になり,より多くのユニットを搭載できるようにもなっている。シェーダプログラムへの置き換えで,専用回路に比べて,局所的に遅くなる部分も出る可能性はあるが,全体的な性能向上分から考えると,旧世代のプログラムを動かして遅くなるようなことはまったく考えられないといっていいだろう。
ジオメトリシェーダなどを駆使した滝のデモ
 |
●ジオメトリシェーダ
これまでは,
頂点シェーダ
ピクセルシェーダ
といったプログラマブルシェーダユニットが内蔵されており,描画時にポリゴンの頂点の位置や向き,そして色を変化させることができた。形状や質感を変化させることができるようになったとはいえ,物体のポリゴン数自体は変化しないのが基本である。
ジオメトリシェーダとは,描画処理の途中でGPU内から一度頂点情報を吐き出し,それをまた入力できるようにするものである。これにより,GPUでの処理の途中で頂点を増やしたり減らしたりということが自由にできるようになる。DirectX 9では,一応,N-Patchモードでポリゴンの内部分割が用意されていたほか,マルチパスレンダリングで処理すれば不可能ではなかったのだが,正式にレンダリングパイプラインに組み込まれ,1パスで無駄なく処理できるようになった。自由度はN-Patchよりも大きい。
ジオメトリシェーダの役目は非常に多い。拡大時のテッセレーションや,メタボール,ベジエ曲面,NURVSなどの自由曲面の処理や,描画時のオブジェクトの生成や分割もできる。これまでも全然扱えないわけではなかったのだろうが,処理がGPU側だけで完結するというのは大きな違いである。CPU側で行っていた処理の多くをGPU上に持ち込むことが可能となり,結果としてゲームをより快適にすることもできる。
ただし,GPUが物体の大きな変形や生成まで行うと,例えばポリゴンの衝突判定などはCPU側からはまったく手の出ないものとなってしまう。GPUにとっては,より多くの処理を抱え込まなければならなくなり,より計算力を要求されることにもなる。
ちなみに「Shader」は陰影を付けるものという意味である。頂点情報を操作するものを頂点シェーダと読んだ時点でかなりおかしかったのだが,今回のジオメトリシェーダも違和感があるので,なんとかならないのかとDavid Kirk氏に聞いてみた。「私もそう思う(笑)。プロセッサと呼ぶほうがいいんだけどね」と語っていたので,今後はもっと適切な用語が登場してくることを祈りたい。
●ストリームアウト機能
頂点シェーダで行われる処理が基本的に「変形」処理なのに対し,ジオメトリシェーダでは「造形」が行われると考えてよい。これは途中でデータが増えるわけで,ジオメトリシェーダを本格的に使うには,途中で生成されたデータをどこかに保存しておく仕組みが必要となる。このための機能がストリームアウトだ。作成されたものは一度メモリ上に出力(ストリームアウト)され,それを再度読み込んで描画処理が行われる。
NVIDIAの水の流れを表すデモでは,岩に当たった水の処理から水しぶきを発生させて描画している。また,割れたりする物体は,分割アルゴリズムさえしっかりできれば,ジオメトリシェーダとストリームアウト機能でかなり省力化されるはずだ。
●インスタンシングの拡張
複雑なモデリングデータを画面に多数表示するのは,最新GPUにとってもそう楽なことではない。しかし,同じ形状をしたデータであれば,「インスタンス」を作ることによってかなり負荷を軽減できる。MMORPGをやっている人は「インスタンスダンジョン」とかで聞いたことがある単語かもしれない。オブジェクト指向プログラミングをかじったことのある人ならお分かりのように(そういう人にしか分からないと思うが),クラスとなるモデリングデータからインスタンスを作り出すわけだ。クラスをオーバーライドすれば,同じ形状をもとにしながら,ちょっとずつ違ったデータを表示することもできる。もちろん,それぞれのインスタンスデータはそれぞれ独立で動作可能だ。
これはDirectX 9cで実装されていた機能ではあるが,DirectX 10になって大幅に拡張されている。これを受けてGeForce 8でのインスタンシングサポート機能も強化されたわけだ。DirectX 10世代では,画面を埋め尽くすような大量のキャラクターを扱うゲームも珍しくなくなるだろう。
パーティクルによる流体シミュレーションをほぼGPUだけで行ったデモ。岩の表面をにょきにょきと根が伸びていったり,水に濡れると岩の表面が変色したり,水が滝に当たるとしぶきが散ったりと芸が細かい。周囲には大量のトンボが空中を周回している
 |
 |
 |
■ストリーミングプロセッサの性能は?
統合型シェーダアーキテクチャによって,シェーダ処理はすべてストリーミングプロセッサで行われることになった。この新しいストリーミングプロセッサは,スカラ演算器による構成となっている。
コンピュータ用語では,値を一つずつ渡して結果が一つずつ返ってくるような演算をスカラ演算と呼んでいる。データをどさっと渡して,結果がどさっと返ってくるような演算はベクトル演算と呼ばれる。GeForce 7までのシェーダユニットには,行列をまとめて渡して,まとめて演算するベクトルユニットが搭載されていたのだが,GeForce 8では,搭載は見送られている。
では,GeForce 8で従来のような処理をする場合は,複数の単純なユニットを組み合わせて使うのかと聞いてみたのだが,そうではなくて,複雑な処理は一つのユニットで(プログラムによって)時間をかけて処理する方針のようだ。その代わり,演算ユニットは128個並列で動作する。おまけにこの部分はほかの部分に比べて2倍速での駆動となっている。一つの処理あたりでは,従来よりステップ数が多くなったとしても,十分カバーできるという見通しなのだろう。
さて,では新しいストリーミングプロセッサは,どの程度の性能なのだろうか? ピクセルシェーダ部分について見てみよう。ここではFP32の積和演算性能を取り上げて試算してみる。並行して行われる細かい演算まで入れると煩雑すぎることと,NVIDIAの言では,ピクセルシェーダでは積和演算性能が非常に重要となっており,実際その部分のチューンでシェーダ性能を改善してきた実績があるからである。新しいスカラ演算ユニットでの性能評価の焦点は,従来の,いわゆる「vec4 MAD(4ベクトル積和演算)」といった演算をどのように代替できるかに尽きるといっていいだろう。
GeForce 8のストリーミングプロセッサの動作予想図。こういう動作なら非対称でも納得できる?
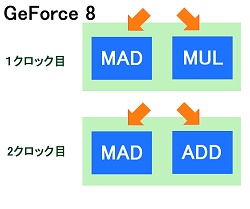 |
GeForce 7のベクトル演算ユニットは,4個の浮動小数点数演算を一度に行うものであったので(ピクセルシェーダでは,それを2基搭載),これが単一の演算しかできないものになってしまうと,シェーダ一つあたりの積和演算性能はかなり落ちることになる。単純計算で1/8だ。
ただし,ストリームプロセッサの演算ユニットはスカラ演算器とはいえ,事実上スーパースカラ構造となっていると思われる。同時に実行できるFP32演算は2個。クロック周波数が2倍強であることから考えて,GeFoece7でのベクトル演算ユニット1基が4個の演算をまとめて行う間に,小刻みに同等の演算を実行できるだけの性能を持っていると考えてよい。
「FP32演算を2個」とはいうものの,片方の演算器では積和演算ができないという噂もある(国内発表会では明らかにされていなかった)。確かに「FP32MAD+FP32MULのような2スレッドの演算が可能だ」と説明されただけなので,積和演算2個を同時実行できるとは語られていない。その場合は,積和処理に2クロックが必要となり,性能は半分になると考えればよい(最悪,乗算専用ユニットが付いてるだけって可能性もあるのだが)。とりあえず,GeForce 8の積和演算性能は,GeForce 7のピクセルシェーダ換算では48基分だと思っておけばよいだろう(全ユニットをピクセルシェーダに使用した場合)。
GeForce 7:4個のMADを1クロックで実行
GeForce 8:2+1個のMADを2クロックで実行?(ただし倍速動作)
かつて「GeForce 7900のピクセルシェーダは,ATIの2倍の演算性能があるので,ATI換算だと48基相当」という言い方がされたのだが,同じ理屈でATI換算すると96基分の積和演算性能となる。
頂点シェーダを含んだGPU全体で比較すると,GeForce 7が1秒あたり24.94G回の積和演算を行えたのに対し,GeForce 8では64.8G回の演算を実行できる計算となる。2.6倍程度の性能比だ。
なお,数字的に積和演算性能を叩き出すには,vec4 MADが効率よいのだが,色要素の演算などは3要素単位で行われることが多い。実質的にvec3 MADで十分とするならば,2クロック(従来のベクトル演算器の1クロック相当の時間)で,片方のスレッドで2個,もう片方で1個,合計3個の積和演算を完了できるという構成は,実用上必要十分な設計のかもしれない。
GeForce 7からGeForce 8への転換は,ピクセルパイプラインに高度に最適化されたピクセルシェーダから,シンプルな汎用シェーダ(多少効率は落ちるが,やたらと速い)に置き換えることで行われたと考えていいだろう。CPUでいえば,CISCからRISCへ切り換えられたような感じだ。
汎用ユニットであってもピクセルシェーダとして十分高速であることは以上に示したとおりだ。さらに,シェーダプログラムのすべてがベクトル演算可能というわけではない。物理演算などではGeForce 7のピクセルシェーダはあまり効率がよくなかったわけだが(むしろ演算器を持て余していたと思われる),ベクトル演算を使わない処理については,クロックとユニット数から単純計算すると,14倍以上の高速化が見込まれる。
■スレッドプロセッサとギガスレッド
GeForce 8のストリーミングプロセッサがなかなか強力で,しかも多数用意されているというイメージはなんとなく理解いただけたと思う。
統合型シェーダでは,これらのユニットを必要に応じて必要なだけ割り当てる。頂点シェーダが酷使される部分では多くが頂点シェーダとして働き,ピクセルシェーダが酷使される部分では,多くがピクセルシェーダとして使用される。新しくピクセルパイプラインに加わったジオメトリシェーダも同様である。それぞれの処理はスレッドとしてGPUに入力され,新しく加わったスレッドプロセッサが管理している。ピクセル処理,頂点処理,ジオメトリ処理と区別してスレッドが発行されるようだ。それぞれの負荷によって使用ユニット数を調整するものと思われる。これにより,プログラマは,ユニット数などを気にせずシェーダプログラムを作成しても十分なパフォーマンスを引き出せるようになる。
Direct3Dでは,コマンドバッファに命令とデータ列を溜め込み,一気にGPUに渡してやるような方式が方式が基本で,プリミティブ(基本図形)単位で小分けに描画することもできたものの,小分けにしすぎると劇的にパフォーマンスが低下するという問題があったため,一つの描画処理自体は複雑になりがちだった。DirectX 9までは,描画コマンドの実行単位(スレッド)が長めで,さほど積極的にスレッド化されていたわけではない。DirectX 10では,描画コマンド単位にスレッド化され,かなり積極的にマルチスレッド化が進められている。膨大なスレッドを管理するのがスレッドプロセッサであり,その関連技術をNVIDIAは「ギガスレッド(Giga Thread)」テクノロジーと名付けている。
一般に,スレッド単位が細かくなれば,処理ユニットに余力がある場合は,ユニットを効率よく使うことができる。重い処理で特定のユニットだけが酷使されていて,ほかのユニットが遊んでいるという状況が少なくなるわけだ。スレッド管理部分が適切に動作すれば,全体のパフォーマンス向上にもつながる。仕様が1種類しかないゲーム機なら,この部分を省略しても(プログラマが死ぬ思いをすれば)なんとかなるのだが,PCゲームの場合,1種類のチップだけに最適化することはできないので,必須の機構ではある。
■物理演算・ビデオ支援など,その他の機能
前述のように,ストリーミングプロセッサがこれだけの演算力を持っているとなると,物理演算などへの応用も期待できる。NVIDIAでは,GeForce 8での物理演算支援のための技術をQuantum Effectと名付けている。どこまでハードウェアによるものか詳細は不明だが,主に流体や特殊効果系物理を扱うためのものだと思われる。
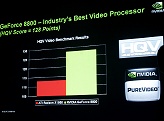
また,動画再生支援のPureVideo HDはリファインされたものが搭載されており,業界の標準的な画質テストであるHQVで,ほぼ満点のレベルにまで画質を引き上げている。David Kirk氏は「もっと難しいテストを作ってもらわないと困る」と笑っていた。
発表会冒頭でDavid Kirk氏が絶大な自信を持って紹介していたように,GeForce 8はほとんど死角のないプロセッサに仕上がっていると見ていいようだ。
■デモで見るGeForce 8の表現力
GeForce 8800概要はすでに解説したとおりだが,発表会で公開されていたデモを紹介しよう。
まず,以前のニュースでも紹介していたAdrianne Curryさんのバーチャルモデルのデモから。これは実在のファッションモデルをリアルタイム3DCGで再現しようという試みである。精密に再構成されたモデリングデータとモーションキャプチャデータによって,水着の美女が画面内でウォーキングを見せる。
個人的な感想としては,正面からのライティングがフラットすぎてリアリティが損なわれている気がしないでもないが,とくに顔の部分は非常によく作り込まれている。
日本国内の内覧会で公開されたバージョンが最終版とは限らないのだが,髪型が結い上げた形であったのは,ちょっと意外であった。Nalu以降,(無重力状態限定ではあるものの)長髪の動きのシミュレーションをデモでアピールしていたので,今回は重力下での毛髪シミュレーションを行うと予想していたのだが。
とはいっても,髪の毛ポリゴンにマッピングを施したものではない(今回の内容ならそれでも実現できただろうが)。ワイヤーフレームを見ると,髪の毛は1本1本作られていることが分かる。ただ,ワイヤーフレームを見る限り,全体のポリゴン数はこれまでのデモと比べて,さほど増えてもいないように思われる。やはり,高精度のマッピングとシェーダ処理が今回のデモの主眼なのであろう。
目の下あたりを拡大してみると,非常に細かな皺の流れや毛穴まで見える。一律のテクスチャを貼り付けているのではなく,顔の各部を忠実に再現していることが分かる。テクスチャだけならまだしも,ちゃんと凹凸として再現されている。どうやってあんな細かいデータを取ったのかと感嘆するほどである。高精度レーザー計測だろうか? このレベルでデータを取って,それを忠実に再現してあるのなら本物の写真と見分けがつかなくても当然かもしれない。
昨今は,データさえあれば,ノーマルマッピングでリアルな造形を実現できる。これはさほど驚くには当たらない。ここまで細かくデータを取ったということが驚きである。
リアルな肌の表現で欠かせない表面下散乱などは,Naluなどの以前のデモでも手をつけられていた部分であるが,より作り込まれたものになっている。
ただ,バーチャルファッションショウなら,髪型や衣装を変えてもっと変化のあるデモにしてほしかったところだ。
David Kirk氏に,誰がデモのモデルとしてAdrianne Curryさんを選んだのかと聞いてみたところ,ちょっと面白い話が聞けたので紹介しておこう。
かつてNVIDIAのマーケティング部門で働いていた社員で,子役などでテレビに出演していたりと芸能界に縁のあった人がいたそうで,なんとその人の奥さんがAdrianne Curryさんなのだそうだ。
NVIDIAは実際の人体を3Dモデリングで再現するために,美人で,3DCGに理解があって,そういったデータを提供してもよいという人を探していたの。Adrianne Curryさんは,本職のモデルで,Reality Showというテレビ番組などにも出演している。ご夫婦揃って,3DCGに興味を持っているということで,条件にぴったり当てはまる人は意外と身近にいたようだ。
GeForce 8ファミリーの2製品は,圧倒的なパフォーマンスと次世代ゲームのための必須アイテムを満載して登場した。現状では「ものすごく速いグラフィックスカード」でしかないが,Windows Vista=DirectX 10の登場とともに重要性をさらに増していくことになるだろう。今回発表されたのは,ハイエンド寄りの製品群だが,普及価格帯の製品が追って投入されるのも間違いない。今後の製品展開にも期待したい。(aueki)
|
|
|
|