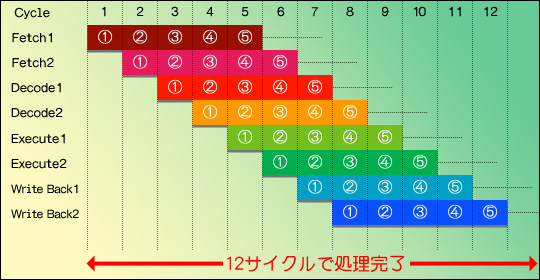
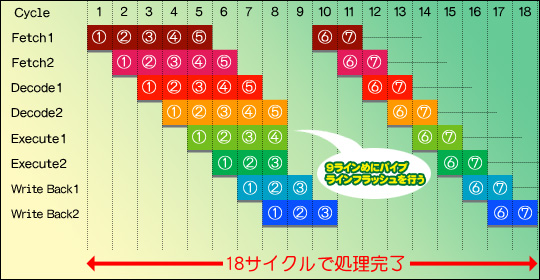
ところで今回の話は,CPU一般というより多少「x86」(エックスハチロク)系CPUに特化した話になっている。x86の概要についてここで深く述べることは避けるが,現在,エンドユーザー(=本誌読者)が使うPC用として流通しているIntelやAMDのCPUはすべてx86系CPUである。
一般にx86系CPUと呼ばれるものは,1995年に登場したIntel製CPU「Intel 80386」がもとになっている。ただそのIntel 80386は,もともと1978年にIntelが発表した「Intel 8086」の上位互換を保っており,このIntel 8086のおおもとになったのが,1968年に登場し,世界最初のマイクロプロセッサと呼ばれている「Intel 4004」である。
いきなり歴史の話を持ってきて何がいいたいかというと,現在のx86系CPUは,こうした大昔の設計を引きずっている関係で,(プログラムの書きやすさ/書きにくさはともかく)ハードウェア的には非常に高速化しにくい命令体系となっているのである。メイドさんが実は全員外国人で,「いつものアレ」とご主人様が日本語で言ってもさっぱり分からない,といった具合。執事は「いつものアレ」を「ワインセラーから○○というワインを出して,栓を抜いてワイングラスに注いで持ってこい」と言い換えなければ,用件はまったく伝わらないのだ。
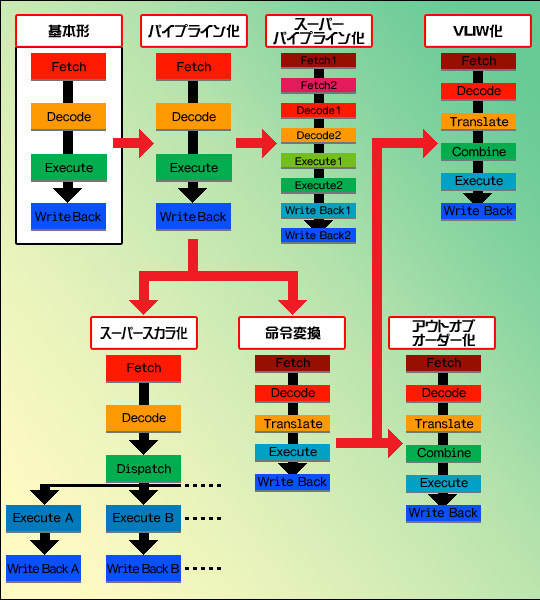
これが実際の大邸宅だと「ちゃんと言葉のわかるメイドを用意しろ」という,至極もっともな話になるが,CPUの世界では,実は「命令変換」(図3中央下で,デコードとエグゼキュートの間に挟まっているトランスレート(Translate)がそれだ)という形で翻訳してあげたほうが効率がよかったりする。なんというか,言葉が分かるメイドさんはいずれも鈍重で,分からないメイドさんは機敏に動くから,翻訳の手間をかけても機敏に動くメイドさんを使ったほうがトータルでは早いという感じだろうか※2。
※2だんだん設定がわけ分からなくなってきた。メイドさんを出したのは失敗だったか?
ちなみにCPUの世界では,前者(言葉のわかる鈍重なメイドさん)を「CISC(Complex Instruction Set Computer,複合命令セットコンピュータ)」,後者(言葉のわからない機敏なメイドさん)を「RISC(Reduced Instruction Set Computer,縮小命令セットコンピュータ)」と呼ぶ。なぜRISCが高速かというと,大きな要因は,処理する命令を単純なものに限ることで,デコードを高速に行えるようになっている点にある。複雑な命令を解釈できるようにすると,どうしても回路規模は大きく複雑になり,結果としてメイドさんはいちいち辞書を引きながら命令を解釈しなければならないから,機敏に動けなくなる。だから,執事側で翻訳して命令を簡潔にしてやればすぐ理解できて動けるというのは,メイドさんもCPUも同じなのである(本当か?)。
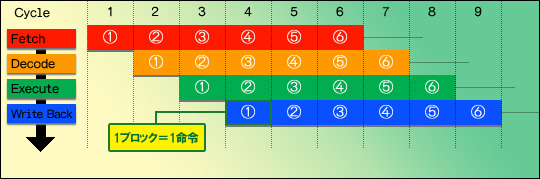
この翻訳に合わせて,「アウトオブオーダー実行」(Out of order execution,以下アウトオブオーダー,図3右下)と呼ばれるメカニズムも導入された。ここまで説明してきた方式はいずれも「インオーダー実行」(In order Execution,以下インオーダー)と呼ばれており,「結果が出てから次の処理に取りかかる」を原則としている。メイドさんに皿洗いと掃除と洗濯をさせる場合,まず「皿洗いをしろ」と命じ,「皿洗い終わりました〜」の報告を受けて「次は掃除を行え」と命令,その完了報告を受けて次に洗濯の命令という具合で,毎回毎回,処理がちゃんと終るのを待って次の命令を下すやり方がインオーダーだ。これに対しアウトオブオーダーでは,「皿洗いと掃除と洗濯をやれ」とまとめて命じておき,それをどういう順番で処理するかはメイドさん任せになる。
ここで応用が利かないメイドさんの場合,素直に皿洗いをして,終ったら掃除をして,それが終ったら洗濯にかかるという具合で,スピードアップの効果はない。しかし,応用が利くメイドさんなら,まず洗濯機を動かしておき,洗濯&ゆすぎが終るまでの間に皿洗いなり掃除なりを並行して行えるだろう。洗濯物が大量にあって,何回かに分けて洗う必要があれば,まず洗濯機を動かしながら皿洗いをし,次に今度は洗濯機を動かしながら掃除といった感じで,完全に並行して行える。
このように,複数の処理を同時に行えるのがスーパースカラである。このとき,執事は後で「皿洗いと掃除と洗濯終りました〜」とまとめて報告を受けるようになっており,それがどういう順で行われたかに関与する必要はない。
もっとも,前述したように,メイドさんの手際が悪いと,かえって時間が掛かってしまうから,利用するさいにはうまく並行処理できるような命令を与えてやる必要がある。そういうわけでx86ではたいてい,アウトオブオーダーはスーパースカラや命令変換と一緒に利用される。
ちなみにこの命令変換効率を徹底して追求したのが,Transmeta(トランスメタ)製CPU「Crusoe」(クルーソー)「Efficeon」(エフィシオン)である。こちらは独自の「CMS(Code Morphing Software)」という仕組みでx86命令を独自命令に変換したうえ,さらに「VLIW」(Very Long Instruction Word,図3右上)と呼ばれる方式を使って高効率化の実現に成功した。ただ,これに続くメーカーはまったくなく,かつTransmeta自体がビジネスの方向性を転換。CPU事業のほとんどを香港のCulture.com Technologyに売却することを決定してしまっている。実際には,一部のメーカーに対してEfficeonの提供を続けていくが,本誌読者としては,もはや追いかける必要はないだろう。