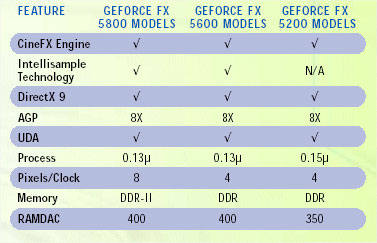
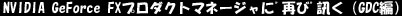善:
GeForce FXが将来を見据えたGPUなのは分かりました。しかし私自身は,今年はDirectX 8円熟期だと思っていて,これから出てくるゲームは,しばらくの間DirectX 8世代テクノロジベースだと思うんです。
GB:
GeForce FXはDirectX 8世代テクノロジベースのアプリケーションも高速に動きますから,大丈夫ですよ(笑)。
善:
ええ,そうだと思います。ですから,GeForce FXは"高速なDirectX 8GPU"として活用するべきなのではないか,と。
例えば,プログラマブルシェーダ2.0を使って長いシェーダを書いたとしたら,GeForce FXではリアルタイムに処理できないのではないでしょうか。
GB:
確かに,すべてのピクセルに対して,プログラマブルシェーダ2.0仕様の限界命令数に近い,長いシェーダプログラムでレンダリングしたら,高フレームレートは出ないでしょうね。その意味では,まだ開発者はパフォーマンスとクオリティのトレードオフを考える必要があると思います。
ただ,そういった高度なシェーダプログラムで構成された3Dアプリケーションを開発し始めることは,絶対無駄にはならないはずです。
 |
| センセーショナルに公開された次期GeForce FX(NV35)のデモンストレーション。妖精Dawnが4人同時に踊っても,フレーム落ちしなかった |
善:
いずれ出てくる新世代GPUでは,リアルタイムに動かせるようになるかもしれないからですね。
GB:
そうです。GeForce FXは開発者に新しい技術,そして手段を提供したという意味において革新的なのです。
FX5600/FX5200発表会の最後に,次期GeForce FX(NV35)のショートデモを特別に見せました。あれではDawnが4人登場していたでしょう? つまり次期GeForce FX(NV35)は,プログラマブルシェーダ2.0を駆使して表現しているDawnを4人出しても遅くならないパフォーマンスをもっているわけですね。プログラマブルシェーダ2.0ベースの技術を磨けば,将来的には絶対役に立つのです。
|