 |
■GeForce 6800のアーキテクチャ
まずハードウェア関係では,RIVA128からGeForce6までの進化の過程について大まかな説明がなされた。従来製品では処理ブロックごとにチップダイ上での区別がついていたものだったが,集積度が上がってくるにつれ混沌としてきて,GeForce 6800ではキャッシュなどは全体に分散され,チップダイを見てもほぼ均一な状態にまでなってきている。
GeForce6800の詳細については,まずトップダウンなハードウェアアーキテクチャ解説が行われた。プロセシングパイプラインはクリーンなところから構築され,処理の最適化を施し全体のスループットを最大にすること,並びに消費電力の低減に重点を置いた設計が行われている。とくに1Wあたりの処理性能にこだわっていることを強調していた。
また全体にスケーラブルな設計となっており,PixelShaderは4〜16,VertexShaderについても可変数な構成でシステムを構築できる。これは基本的に同一チップで機能を制限してということらしい。製品が違っても基本的に同一のものなので,完全な互換性が実現できているという。16パイプを4パイプにまで落としても十分に高速で,GeForce FX 5950と同程度の性能は発揮できるという。
GeForce 6800 Ultraの電源コネクタ2個問題で"電力大食い"と思われがちなGeForce6シリーズだが,駆動電圧や動作クロックの引き下げなどにより,GeForce FXシリーズと比べてさほど消費電力が上がっているわけではないという。それでいて浮動小数点演算性能は数十倍に向上しており,むしろ1Wあたりの性能は格段に向上している。これにより,モバイルプロダクトでも低消費電力で高性能なものを期待できそうな状況になってきている。現在ノートPCなどのグラフィックアクセラレータではATI製品のほうが広く使われているわけだが,GeForce6世代では状況は変わってくるのかもしれない。
 |
■必要な浮動小数点演算演算精度は?
GeForce6ではフレームバッファなどを16ビット浮動小数点型のデータ形式で実現し,演算には32ビット精度の機構を用意している。GPUの内部処理にどれくらいのビット数が適当かというのは,演算精度とどれくらい容量を食うかに切り分けて考えなければならない。通常のアプリケーションで使われるのは倍精度浮動小数点演算で,80ビットないし64ビット(CPUの種類によっては96ビット)の精度で演算を行うのだが,リアルタイムゲームでは100万倍ズーム機能でもつけない限りそんな精度は要求されない。
一般的なShader部分の計算では,32ビット精度程度の演算が必要と思われる。これは一般に単精度浮動小数点演算といわれるもので,倍精度よりは精度は落ちるものの,まずまず十分な精度は持っている。頂点操作やテクスチャ内の座標計算などではなるべく高い精度が望ましく,32ビット精度はShader3.0の要件としてマイクロソフトも認めているものである。
しかし単精度とはいえ,すべてをその精度でやると記憶領域を多く使い,転送時の帯域も多く使いすぎて効率が悪くなる。たとえば,RGBAのフレームバッファコンポーネントで32ビット精度を採用すると,1ピクセルあたり128ビット,8ビット整数でやっていた時代の4倍のメモリ帯域が確保できないと同じ速度で処理できないことになる。GDDR3メモリを使うGeForce 6800の理論上の最大メモリ帯域幅は35.2GB/secとなっているのに対し,1クロックで32テクスチャへのアクセスを行う400MHzのGPU本体部分は,最大102GB/secの帯域を必要とする(16ビット精度時)。グラフィック処理の大半がメモリ速度ボトルネックとなっている現状では,これ以上多くの帯域を使う処理は避けたいところだろう。
NVIDIAではテクスチャフィルタリングやフレームバッファのブレンディングなどにはコンポーネントごとに16ビットの演算精度で十分であると考えてるようだ。その根拠として,人間の目が感じるダイナミックレンジとほぼ同等であること,Pixarなどで使っているのがコンポーネント16ビットの形式であることなどを挙げている。「ジョージ・ルーカスが大丈夫だといってるなら,リアルタイムグラフィックでも大丈夫」ということらしい。半面,演算部用には32ビット精度を用意し(RGBA32ビットごとのフォーマットもサポートされているがフィルタリングやブレンディングはサポートされていない),シャドウマッピング用にのみ24ビット精度のバッファを用意している。
ATIでは,格納・演算などをまとめて24ビット精度でやっている。NVIDIAがいうように人間の目のダイナミックレンジが16ビットなら,演算時の精度落ちを考慮して多少多めに桁を取るというのも正しい判断ではある。ただ,以前はコンポーネント8ビットごとの1600万色が人間の目の判別できる色範囲とか語られていたわけで,現実問題として画像の劣化が問題になるような精度落ちが発生する可能性はかなり低いといえる。一般ユーザーにとっては,どっちでもかまわないレベルの問題でしかないだろう。個人的には,別にHDRレンダリングのサンプルで整数精度でのバンディング発生画像を見ても,言われなければどこが問題なのかも気にすることはないのだが……。
■ShaderModel 3.0,DirectX 9.0cの利点
GeForce 6800の最大の特徴はShaderModel 3.0,DirectX 9.0cを先取りしたGPUであるということなのだが,その利点は「これまでできなかったことができる」わけではなく,「これまでよりも簡単に高速にできる」というところに意味があるという。実際,Shaderの基本部分はできあがっているので,2.x相当の仕様でもマルチパスレンダリングを使えば,時間はかかるがたいていの処理は実現できないわけではない。しかし,ShaderModel 3.0やDirectX 9.0cを使うことで大幅な高速化が期待できる部分もある。
より簡単にという面では,Shaderプログラミングに動的な分岐命令が追加されたことによるメリットは計り知れないものがある。これまでの「分岐なし」あるいは「ループのみ」といった制約下では複雑な処理の記述はほとんど不可能だといってもよいかもしれない。
GeForce 6800のデモで使用された人魚Naluの肌表現など,多彩な処理を単一のShaderプログラムで実現できる。
また,複数のShaderプログラムに分けた場合よりもパフォーマンスも期待できる。その場で行われたNVIDIAのデモでは,動的分岐を使用した場合と使用しない場合でフレームレートで倍近い差が出ていた。
技術的なトピックは,Naluのデモを例に解説が行われた。Naluの髪の毛などにはDeepShadowというPixarが提唱している多段階シャドウマッピングテクノロジーが使われている。劇場映画クオリティで使われるCG技術を取り込むことには積極的で,DeepShadow以外にもHDRなどがあり,NVIDIAではこういったアプローチで技術開発が行われることが多いようだ。
ShaderModel 3.0に対応したものとして具体的な名前が出てきた作品は以下のとおり。既発売のものは,パッチ対応になる模様。
FarCry
Grafan
Lord of the Rings:Battle For Middle-Earth
Madden 2005
Painkiller
STALKER:Shadow of Chernobyl
Tiger Woods 2005
Unreal Engine 3
Vampire Bloodlines
FarCryはShaderを多用した最先端のゲームとして知られているが,ライバルとなるATI X800との比較ベンチマークで大差をつけられている数少ないゲームのひとつでもある。この状況は,FarCryのShaderModel 3.0対応パッチで格段に改善されるという(現状ではバグのためリリースが遅れている模様)。
■ジオメトリインスタンシング
さらにDirectX 9.0cで可能になってくるのが,ジオメトリのインスタンシングである。「クラス」「インスタンス」といって意味の理解できる人ならきっとご想像通りの機能なのだが,オブジェクト指向の考え方に馴染みのない人のために噛み砕いて説明しておこう。
ゲームなどでたくさんのオブジェクトを表示するときに,実はまったく違う形状のモデルを大量に使うということは稀である。実際には,人いっぱいの乱闘シーンなど,同一ないし似た形のモデリングデータのオブジェクトが大量に使用されているというケースがほとんどだ。そういった場合,基本的な部分は共通化して,違う部分は個別にパッチ当てしてやったほうが効率がよくなる。昨今ではキャラクターデータなどもポリゴン数が激増し,同時に表示させる物体数も激増していく傾向にある。しかし,人体データなどでは9割程度は共通化できる場合も多いのだ。たとえば,1万ポリゴンのモデリングデータを100体表示するときに,10000×100のデータを扱うより,10000×1の基本データと1000ポリゴン程度の差分データ×100個を扱うほうが断然効率がいい。たくさんのモデルを定義して転送する必要がなくなるのだ。
このときの雛形(クラスという)になるデータから作られて,実際に使用されるオブジェクトのことを「インスタンス」と呼ぶ。また雛形から現物を作るときに,雛形にかぶせものをするような感じで個別に変化をつけることも可能だ(オーバーライドという)。戦争ゲームなどで兵士一人一人を別モデルでデザインしたり表示管理したりするのは大変だが,1人分の基本クラスを作っていて,それをもとにすれば歩幅を変えたり,服装を変えたりといったバリエーションを自在に作り出せる。これによりゲームの制作効率が非常に向上するほか,多くのオブジェクトが出てくるシーンではパフォーマンスもかなり向上させることができる。DirectX 9.0cで期待すべき新機能である。
こういった機能は現状のDirectX 9.0bではサポートされていないのだが,DirectX 9.0cに変更することにより,従来のアプリでもこういった恩恵を受けられるようになる可能性もあるという。とくにマイクロソフト標準のShaderモデル言語であるHLSL(High-Level Shader Language)を使用している場合の移行はスムーズだという。
 |
 |
|
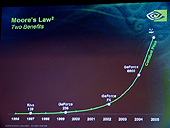 |
今後のシリーズ展開についてだが,GeForce 6800については,現状かなり保守的なクロックから始めていることと,GeForce FXの例を挙げて5700と5950では約2倍の性能向上が行われていることなどから,高性能版の発売はごく自然なものとして語られていた。さらにはモバイル製品の開発,統合チップセットへの組み込みなどが検討されているようだ。
来年には,NV50が当然のように予定されている。もちろん,その詳細についてはまったく明らかにされなかったが,プレゼンのグラフによれば現状のGeForce 6800と同価格できっちり倍の性能のところにプロットされている。半年で性能倍というGPUレースにしては,ちょっと控えめな感じではある。
■余談:PixelShader 3.0でのサポート命令数
PixelShader 3.0でのサポート命令数は多くの資料では「65535」となっている。プログラムカウンタ16ビットであると考えれば,普通「65536」命令であろうと思うのがPC業界の人だろう。
GeForce 6800の発表会のときに「65536の間違いではないのか?」と聞いたところ「そうだ。65536だ」という回答を得た。今回の資料でも56635になっていたので念のために再度確認したところ,65535(64K-1)であるということだった。ユーザー側の使い勝手や性能にはほぼ関係のない違いではあるが,なんとも不自然な仕様ではある(プログラムサイズのオーバーフローチェック用?)。
 |
PCI ExpressはAGPに代わる次期主力ビデオバスだが,NVIDIA製品はPCI Express対応策として,AGP8X→PCI Expressブリッジチップを開発している。ビデオカードでAGPバスがそれ以前のPCIバス接続のものより多くなったのは,実は2003年になってからのことだったそうだ。今後PCI Expressへの移行にも相当の時間がかかってくるだろう。そういったことを考えると,AGPからのブリッジというのもリーズナブルな選択かもしれない。しかし今年後半に発売される製品に関しては,PCI Expressネイティブで実装されたものになると予想されているとのこと。ロードマップによれば,ローエンド製品までPCI Express対応のものが予定されている。
なお,PCI Expressの効用を確認するにはどんなアプリケーションが適しているのかと聞いたところ,答えは明解で「ない」とのことだった。ただ,現状では唯一,HDTV用のビデオ編集ソフトでのみAGPとの差を体感できることが確認されているという。「ぜひ1年後にまた同じ質問をしてくれ」と,Kirk氏は今後ゲームなどでどんどん広帯域を使ったものが出てくることを示唆していた。
■余談:工業用製品などへの進出
写真はポルシェのデザインをしている会社で使われてるNVIDIA製品による超高精度ポリゴン画像。設計したモデルの精密な3D表示を行っている。内装の超拡大部分を見ると,素材の精密なシェーディングやレザーの縫い目の一つ一つまでがきっちり作り込まれていることが見て取れる。そのほか,素材ごとに色を変えてトゥーンシェーディングすることで簡単にマニュアル用画像を作成したりすることにも使用されているという。
 |
 |
 |
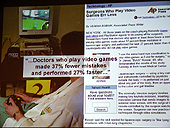 |
話の途中で,ゲームをしている医者はしていない医者よりも37%ミスが少なく,27%仕事が速いことを示す記事が示された。ゲームをすると手術がうまくなるのか,手術のうまい医者はゲームも好きなのかは不明だが,Kirk氏も最近盲腸の手術を行ったそうだが,執刀医も麻酔医もゲームをやるということで安心して手術に望めたそうだ。この話がどこまで信用できるかはさておき,医者選びというのは客観的なデータでは示しにくいものだ。知り合いの医者の話では世の中の名医リストは飛躍的に精度が上がってきたものの,まだ「新庄の打率程度」(注:どこでやっても二割五分)だそうだ。しかし将来的にはゲームのうまさで客観的に医者を選ぶようなこともあるのかもしれない。(aueki)
→「GeForce6シリーズ」の当サイトの記事一覧は,「こちら」