����CineFX3.0�ŁC�Q�[�}�[��p�B��GPU�Ɋ��S���A����
�\�@ShaderModel���Ƃ̖��ߐ����� | ||
| �o�[�W���� | VertexShader | PixelShader |
| 1.1 | 128 | 8 |
| 1.2 | - | 12 |
| 1.4 | - | 14 |
| 2.0 | 256 | 64 |
| 2.0Extended | 256�iLoop�j | 96�`512 |
| 3.0 | 512�` | 512�` |
�@�V�������\���ꂽGeForce 6�V���[�Y�͈��|�I�ȏ������x�Ƒ��ʂȕ\���͂������Ă���BNVIDIA��GeForce 6���Q�[���ȊO�̕���C�܂�}���`���f�B�A�@�\�Ȃǂ̕\���n�@�\�S�ʂɂ����čŋ��̂��̂ƂȂ邱�Ƃ�ڎw���Ă���悤�����C����3D�Q�[���ɑ���D�ʐ��͓ˏo�������̂ƂȂ����B�����ł͂��̍����ƂȂ��Ă���V�@�\�ɂ��Č��Ă��������B
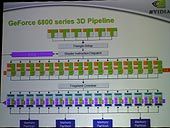
�@GeForce 6�V���[�Y�ł́C�V���ȃV�F�[�f�B���O�A�[�L�e�N�`���Ƃ���CineFX3.0�𓋍ڂ��Ă���B�ڂ����͌�q���邪�CDirectX 9.0c�Ŗ{�i�I�ȃ����[�X�ƂȂ�Shader Model3.0�iSM3.0�j�ɑΉ����C�v���O���}�u�����_�V�F�[�_ 3.0�i�ȉ��CVS3.0�j����уv���O���}�u���s�N�Z���V�F�[�_ 3.0�i�ȉ��CPS3.0�j�����S�T�|�[�g�BVS3.0��PS3.0���ɖ����̒����i�����ɂ�65536���߁j�̃v���O�����ŃR�[�h��������悤�ɂȂ����B�e�N�X�`���G���W����16�r�b�g�iFP16�j��32�r�b�g�iFP32�j�̕��������_�t�H�[�}�b�g�ɑΉ����Ă���C16�{�̓Ɨ������s�N�Z���p�C�v���C���ɂ�32�r�b�g�̃V�F�[�f�B���O�f�[�^���ɓ�����M�ł���B
��16x1/32x0�p�C�v���C���̃����_�����O�G���W��
�@GeForce 6800�́C���㔭�������uDOOM 3�v��C�uHalf-Life 2�v�ȂǍŐV�O���t�B�b�N�X�����������Q�[�����v���C����̂ɍœK�Ȃ̂͊ԈႢ�Ȃ��CCineFX3.0�̂��܂��܂ȋ@�\���V����̃Q�[���^�C�g�����T�|�[�g����B����CineFX�ɑ傫���v�����Ă���̂��C16�{�̃s�N�Z���p�C�v���C�������V�����A�[�L�e�N�`���̃����_�����O�G���W���ł���B
�@���j�^��ɕ\�������s�N�Z���́C�������������N���b�N���ɐ�������ăp�C�v���C����ʉ߂���i�h��ŕ��G�Ȍ��ʂ�\������`��ł́C�����̃p�X�𗘗p���邱�Ƃ�����j�B�p�C�v���C�����́C3D�A�v���P�[�V�����̃{�g���l�b�N�ƌ����Ă��ߌ��ł͂Ȃ��̂��B
�@GeForce 6800��16�{�̃p�C�v���C����ێ����Ă���Ƃ������Ƃ́C�P���Ɍ�����RADEON9800��2�{�CGeForce 5950 Ultra��4�{�̃s�N�Z���������ł���Ƃ������Ƃł���C�����ȃp�t�H�[�}���X�A�b�v���]�߂�BNV35�͓�̃e�N�X�`���ɕ��U�����l�̃s�N�Z�����C1�N���b�N�ɂ�8�����\�������\���ł��������CNV40��16�s�N�Z���ō\�������1���̃e�N�X�`�����C1�N���b�N�ɂ�32�����o�͂����̂��B
��SIMD/MIMD�X�L�[��
�@NV40�ł́CNV3x�n���������C���X�g���N�V�����Z�b�g���T�|�[�g���CMIMD�Ƃ����X�L�[�����A�[�L�e�N�`���ɑg�ݍ���ł���B����܂ŗ��p����Ă���SIMD�́uSame Instruction�CMultiple Data�v�̗��ŁC��̃C���X�g���N�V�����Z�b�g��GPU�ɑ����āC��������܂��܂ȃf�[�^�ɑ��Ď��s���Ă����B
�@�Ⴆ�Γ�̊ȒP�ȃe�N�X�`����\������ꍇ�C�u�e�N�X�`���C�u�����f�B���O�C�e�N�X�`���C�u�����f�B���O�v�ƁC�u�e�N�X�`���C�e�N�X�`���C�u�����f�B���O�C�u�����f�B���O�v�ő���o����ʂ�̃p�^�[��������B���ҋ��ɉ�ʂɕ\������錋�ʂ͓��������C��҂̂ق����C�l�̃I�y���[�V������1�X���b�g�E1�N���b�N�����ŏ����ł���̂Ō����������B�O�҂͎l�̃N���b�N�������K�v�Ȃ̂ŁC���̕����Ԃ��|�����Ă��܂��̂ł���B���ꂪNV3x��NV40�̑傫�ȍ��ق̈���B
�@NV40�́C�X�[�p�[�X�J���v���Z�b�T�ƂȂ邱�ƂŁCSIMD���炳��Ɉ�����ݍ���MIMD�iMultiple Instruction�CMultiple Data�j�����������n�C�u���b�h�^�ɂȂ�C��̃p�C�v���C���ł���̃C���X�g���N�V�������Ɏ��s�ł���悤�ɂȂ����B�Q�[���^�C�g���̃t���[�����[�g�����サ�C���A���^�C�������_�����O�Z�p��CG�f��ɋ߂Â���ł͕K�v�s���Ȏd�l�ł���ƌ����邾�낤�B
 |
 |
|
 |
�@�z�����В����ł��O�������Đ�������_�́CNV30����ł��S�苭���T�|�[�g�������Ă���32�r�b�g�̕��������_���x�iFP32�j�ł���B
�@DirectX 9.0��FP24���T�|�[�g���CATI�Ђ�R300���オFP12�CFP16�CFP24�CFP32�̃s�N�Z���C���v�b�g�����ׂ�FP24�ɕϊ��ł���悤�ȃA�v���[�`�ł���̂ɑ��āC NVIDIA�Ђ�FP12�CFP16�C������FP32���������邽�߂ɕʁX�̃p�C�v���C����p�ӂ��Ă���B���̎�@�ł́CFP12�x�[�X�̃s�N�Z�����g�p���Ă���OpenGL��DirectX 7�����DirectX 8�̃A�v���P�[�V������ϊ����Ȃ������������ɏ����ł�����̂́CDirectX 9.0�ȍ~�ɃT�|�[�g���ꂽFP24�̒��_�V�F�[�_/�s�N�Z���V�F�[�_2.0�ł́CR300�V���[�Y�ɌR�z�������邱�ƂɂȂ�B
�@�z�����В��́C�uFP32��FP24�Ɣ�r���ăp�t�H�[�}���X�ւ̕��S��25%�قǑ傫���B�������C����FP32��"����"�ł��邱�Ƃ�M���Ă��܂����C64�r�b�g�v���Z�b�V���O�̎��オ�������邱�Ƃ��M���Ă��܂��v�Ƙb���B�f����̐��x�����������A���^�C�������_�����O�̎��オ���N��ɓ�������ƂȂ�C�₪�Ă�DirectX��ATI�Ђ�GPU��FP32���T�|�[�g����͕̂K��Ȃ̂ł���B
�@�܂�NV40�ł́C����܂�DirectX 9.0�̋@�\�Ƃ��Ċ܂܂�Ă����ɂ��ւ�炸NVIDIA�Ђ��T�|�[�g���Ă��Ȃ�����HDR�iHigh Dynamic Range�j�����_�����O�����Ɏ��������B �@HDR�����_�����O�́C���ʉf��Ȃǂŕp�ɂɌ�����"�I���̋���ɂ�鎋�o����"�Ɏg�p�ł��CHalf-Life 2�ł��g�~��̉������������i�ȂNJe���Ŏg�p����Ă���B�܂�HDR�����_�����O�ւ̃v���O���}���̑Ή��͓�����̂ł͂Ȃ��̂ŁC���N�̌㔼�����HDR�Ή��Q�[���^�C�g���������Ă��邾�낤�ƌ����܂�Ă���B
�����_�X�g���[���E�t���[�N�G���V�[�i��ʍ��j
�@���_����ǂݍ��ގ��ɁC�����̃I�t�Z�b�g���w�肵�Ď�ނ��ƂɈႤ����ǂݍ��ނ��Ƃ��ł���B
�@�Ⴆ�C�����̒��_�ɑ��ĕ����̍s�Z�Ȃǂ��s���ꍇ�i�`��̕ψڂƃA�j���[�V�����C�n�`�̕ό^�Ȃǁj�C�����̏�����1��̃h���[�R�[���Ŏ��s�ł��邱�ƂɂȂ�B���G�Ȍ`��ł��h���[�R�[��1��ŏ����ł���CGPU�ւ̕��ׂ͏������B����ɂ���đ啝�ȕ��팸���\�ɂȂ��Ă���킯���B
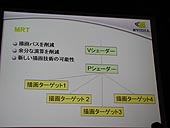
���}���`�����_�����O�^�[�Q�b�g�iMRT�C��ʒ����j
�@1��̃����_�����O�ŕ����̃^�[�Q�b�g�ɑ��ă����_�����O���\�ɂȂ�B
�@�Ⴆ�C�e�N�X�`���G���A�ւ̏������݂ƃt���[���o�b�t�@�ւ̏������݂���x�ɂł���ق��C"�ʂ荞��"�Ȃǂ̃����_�����O���ʂ��e�N�X�`���Ƃ��Ďg�p����ꍇ�ɏ�������������ȂǁC���܂��܂ȉ��p���\�ł���B�t�H�g���A���X�e�B�b�N�ȕ\����Nj����Ă����ƁC�ʂ荞�݂̂悤�ȏ����͕��폈���Ƃ��čs���Ă������Ƃ��l������B�����_�����O�����̌������グ��d�v�ȋ@�\�̈���B
��FP16���K�����j�b�g�i��ʉE�j
�@�x�N�g���̒�����"1"�ɂ��ĒP�ʃx�N�g������鏈�����u���K���v�Ƃ����B���K����3D�ɂ͕K�{�̏����ł���C���̕��ׂ̏d�������ɂȂ��Ă����B����܂ł̓A�N���o�e�B�b�N�ȏ����Ő��K�����s�����肵�Ă����̂����C����͕K�v�Ȃ��B�Ȃ��Ȃ炱�̏����́C�����_�����O�p�C�v���C���̃V�F�[�f�B���O�G���W���ōs�����Ƃ��ł��邩�炾�BGeForce 6�̃����_�����O�p�C�v���C���ɂ�2�̃V�F�[�f�B���O�G���W�������ڂ���Ă���̂ŁC���K�����牉�Z�ցC�Ƃ�������̏�����1�p�X�łł���悤�ɂȂ����B�����������Z�p�́C���`��Ԍ�̃��C�e�B���O�����ȂǂɗL���ł���B
 |
 |
 |
���uNalu�v�i��ʍ���i�j
�@���͂ȃ����_�����O�\�͂��\�t�g�ɕ\�����悤�Ɛ��삳�ꂽ�̂��CGeForce 6�V���[�Y�̐V�}�X�R�b�g�C�uNalu�v�i�i���[�j���B�����ӂ���Ƃ������̖т̃V�F�[�f�B���O�ƁC�̂Ɉڂ�\�t�g�V���h�E�͕K���B�܂��i���[�̔畆�́C�㕔����~�蒍���C����g�ŏ펞�f�t�H�������������̔��˂ɏƂ炳��C�ޏ����j����邽�тɁC�̂┯�̉e�����̂ɓ��e�����悤�ɂȂ��Ă���B
�@�i���[�͑��v30���|���S���قǂō���Ă���C������1���{���x��10�`15�̒��_�ŕ\������Ă���B���̖т̕����ɂ�"�f�B�[�v�V���h�E"�iDeep Shadow�j�Ƃ���CineFX�ŊJ�����ꂽUltra Shadow�U�̋Z�p���K�p����Ă��āC16�i�K�̃V���h�E�}�b�v���s���Ă���B���̖є��̃V�~�����[�V������Δ䂷�邽�߂ɁC�Z���������O�V���[�Y�̊Ŕ��s�N�V�[�Ɣ�r����ƁC���̋Z�p�̐i�������������邾�낤�B
�@�܂��悭����ƁC�C�ʂ���R�ꂽ���ƕ��ˏ�ɍL����GodRay���ʂ��g�ݍ��킳��Ă���̂�������B����͐l���̃V���G�b�g���}�X�N���āC�������琅�ʂ̖͗l����ˏ�Ƀu���[�����������̂��������Ď�������Ă���B
���uClear Sailing�v�i��ʒ�����i�j
�@�uPirates of Caribbean�v�Ŕg�������ɕ\������Ă����̂��L�����Ă���Q�[�}�[�������Ǝv�����C����͂�͂蒸�_�V�F�[�_���T�|�[�g�����n�[�h�E�F�A�ŏ�������̂��]�܂����B
�@���́uClear Sailing�v�Ƃ����f���ł́C�T�C���g��50�������č��ꂽ�C�ʂ����A���^�C���Ƀe�b�Z���[�g����CPer-Vertex�����Per-Pixel�����G�ɍ��������g�����o���Ă���B�Ȃ����ʂ̃��b�V���́i�����ڂ́j�傫���́C���C���[�t���[���\���ɂ��ăJ�������Y�[�����Ă��ω����Ȃ��B��ɍœK�ȑ傫���Ńe�b�Z���[�V�������s���Ă���̂��B
�@�܂��C�ʂ́C�K���I���D�̉e�������C�ʂ̉A�e�ɉe������ȂǁC���͂̊��ɂ���ăV�F�[�f�B���O�����B�q�s����D�����o�����g���C�g�̖@���ɂ���Ē��_�V�F�[�_�����o���B���Ȃ݂ɁC�g���Ԃ��̓X�v���C�g�ɂ����̂ł���B
��Timbury�i��ʉE��i�j
�@�܂�œ����A�j���̂悤�ȕs�v�c��CG���uTimbury�v�i�e�B���o���[�j���B
�@����CG�́C�����w�҂̃e�B���o���[��"�`���̉ߒ��ŐV��̍�����������"�Ƃ����ݒ�̒Z���X�g�[���[�����C���̃N�I���e�B�ŃO���O���ƃJ�����̊p�x��ς��Ȃ��猩����̂��V�N�ŁC�uCG�f����̃��A���^�C�������_�����O�v��n�ōs���f���ł���Ƃ�����B
�@�Ɩ����́CILM�Ђ́uOpenEXR�v�Ƃ���16�r�b�g���������_���Z�p�̃t�H�[�}�b�g�����p����Ă���C�O�����GPU�ł͕s�\������HDR�����_�����O�Z�p���������Ă���B�W���{���������͋C���\�t�g�ŁC�z�m�{�m�Ƃ������ɃJ���J�`���A���܂܂����f�������C�e�B���o���[�̊�̋ؓ��̓�����C�������ዾ�z���̘c�w�i�Ȃǂׂ̍����`�敔�����f���炵���f�L���B
 |
 |
 |
 |
 |
 |
�@NV40�����GPU�́CDirectX 9.0c�ɑΉ����邱�ƂŃv���O���}�u���V�F�[�_3.0���l�C�e�B�u�Ή��ɂȂ�BDirectX 9.0c�́C�ȑO��"DirectX 9.1"�ɂ���ƌv�悳��Ă������CDierctX 8.0����DirectX 8.1�Ɉڍs�����Ƃ��قǑ傫�ȕύX�͂Ȃ��Ƃ������R�ŁCDirectX 9.0�n��Ƃ��ĔF������邱�ƂɂȂ�B�V�F�[�_��1.3����1.4�Ɉڍs����DirectX 8.1�́C�ȑO������I�ɏ��Ȃ��p�X�ŃV�F�[�_�������_�����O�ł���悤�ɂȂ����B�����ăV�F�[�_1.1����1.3�ւ̐i���𐋂���NV30�V���[�Y�Ɣ�ׁC1.3����1.4�v���ȑΉ���������ATI�Ђ�R300�V���[�Y���Ƃ��ɑ傫�ȉ��b���Ă����B
�@Shader Model 3.0�́C���ݏo����Ă���SDK�̃o�O�C���𒆐S�ɁuCentroid Modifier�v�Ȃǂ̋@�\���lj�����C�܂�"Direct3D�ł͂���Ƃ���"�Ƃ��������ɁCHLSL �i���ʃV�F�[�_����j�ł̃V�F�[�_�v���O�������\�ɂ��Ă���B�����̎�����2004�N�Ĕł�SDK�ōs����̂ŁC�{�i�I��Shader Model 3.0�Ή��\�t�g���o���̂́C�����Ă�2004�N�̔N���ȍ~�ɂȂ肻�����B
�@GeForce FX 5950��RADEON 9800XT�Ƃ��������s�̃n�C�G���h���f���ł́C���ꂼ��̃p�C�v���C����ɑ������ꂽ�V�F�[�_���j�b�g���e�N�X�`�����������Ă���B�������C������̃e�N�X�`�����u���ɏ����ł���\�͔͂����Ă��炸�C ������ׂ�CG�f��̃N�I���e�B�̃��A���^�C�������_�����O�͕s�\���i2�N�O�ɂ́CGeForce 3�ŁuFinal Fantasy�FThe Spirit Within�v�̃L�����N�^�[�����A���^�C���œ��삳���鎎�݂��s���Ă����̂��L���ɐV�����j�BNV40�ł�MIMD�A�[�L�e�N�`���ɂ���Ĉ�̃p�C�v���C���ɓ�߂̃V�F�[�_���j�b�g���������Ă���C����͂�萸����CG�O���t�B�b�N�X���Q�[����œ��������߂̈�̕������������Ă���Ƃ�����B
��Centroid Sampling
�@Centroid�i�d�S�j�T���v�����O�́C�s�N�Z���V�F�[�_3.0�̒��ł����M���Ă����ׂ��V�@�\�ł���B
�@���̃T���v�����O�Z�p�́C��N�̉č����牢�Ă̊J���ҒB�̃z�b�g�g�s�b�N�ƂȂ��Ă���C����Valve Entertainment�Ђ��CATI�Ђ���Â����uShader Day�v�Ƃ�����̒��ŁuATI�ЂƂ̘A�g���������邱�Ƃɂ����̂́CNVIDIA�Ђɂ͂Ȃ�Centroid Sampling���n�[�h�E�F�A�Ɏ�������Ă��邩�炾�v�Əq�ׂĂ����B�������uHalf-Life 2�v�̃����[�X��Centroid Sampling�̃T�|�[�g��\�肵�Ă���DirectX 9.0c�Əd�Ȃ�CNVIDIA��NV40�ɑg�ݍ��߂�悤�ɂȂ����B
�@Centroid Sampling�́CMulti-Sample�A���`�G�C���A�V���O���쓮�������Ƃ��Ɂi�Ƃ��Ƀ��C�g�}�b�v���g�p�����Ƃ��Ɂj�N����₷��"�قȂ�e�N�Z���̃T���v�����O"��}���C�K���w�肳�ꂽ�g���C�A���O���̒�����T���v�����O���s����悤�ɂ����Z�p�ł���B
��Dynamic Branching
�@GeForce FX�V���[�Y�̑傫�ȃZ�[���X�|�C���g�������̂��C�s�K�v�ȃC���X�g���N�V�����͔���ĕK�v�ȕ����݂̂����s���邱�ƂŃp�t�H�[�}���X���グ��uDynamic Flow Control�v���B���������i�߂��i���^�̋@�\���uDynamic Branching�v�ŁC����܂ŃV�F�[�_��ʂ��ĕ\������e�N�X�`�����ʂɂ͈���V�F�[�_�v���O�����������Ȃ���Ȃ�Ȃ������̂��C�R�[�h�ɑ��Ĉ��̏ŋN����I�v�V�������u�����`�Ƃ��ĕt���邾���ŁC��̃V�F�[�_�v���O�����ňꊇ�w��ł���悤�ɂȂ����B�O���t�B�b�N�X���\�����C�ނ���v���O���}�̘J�������Ɉ���Ă���B
��Predication
�@Predication�i�������s�j�́C�V�F�[�f�B���O�̃v���Z�X��v���ɂ���@�\�ŁCDynamic Branching�ɕt��������̂ł���B���̋@�\�́C���̃V�[���Ŏg�p�����f�[�^��\�z����GPU�ɑ���̂ł͂Ȃ��C�\�z����邷�ׂĂ̏őz�肳���f�[�^���܂Ƃ߂�GPU�ɑ���̂ŁC�K�v�Ȃ��̂������p�C�v���C����ʂ邱�ƂɂȂ�B����͑�����"���S"�ɂȂ�ƍl���������ŁC�f�[�^���M��������ꍇ�ɐ������f�[�^�𑗂蒼�����������I���Ƃ������_�Ɋ�Â��Ă���B
��Displacement Mapping
�@���XMatrox�Ђ��ŏ��ɍ̗p�����uDisplacement Mapping�v�́CDirectX 9.0�ȍ~�̒��_�V�F�[�_�̋@�\�Ƃ��č̂������Ă���B�x�N�g���𗘗p���ĉ��ʂ��[���I�ɕ\������Bump Mapping�Ɣ�ׂāC���A���^�C���Ƀ}�b�s���O���ꂽ���_�f�[�^�����ꂼ����͂̏Ɩ��ɔ�������悤�ɂȂ�B����ɂ���ĉA�e���Œ肳��Ȃ��Ƃ������A���e�B�ݏo���C�D�ꂽ�n�`��I�u�W�F�N�g�̕\��Ƃ������\�����\�ɂȂ�̂ł���B���̋Z�p��2006�N�ɓo�ꂷ�錩���݂�Unreal 3�G���W���ɂ����p����Ă���C����d�v���������ł��낤���_�V�F�[�_�Z�p�̈�Ƃ�����B
 |
 |
|