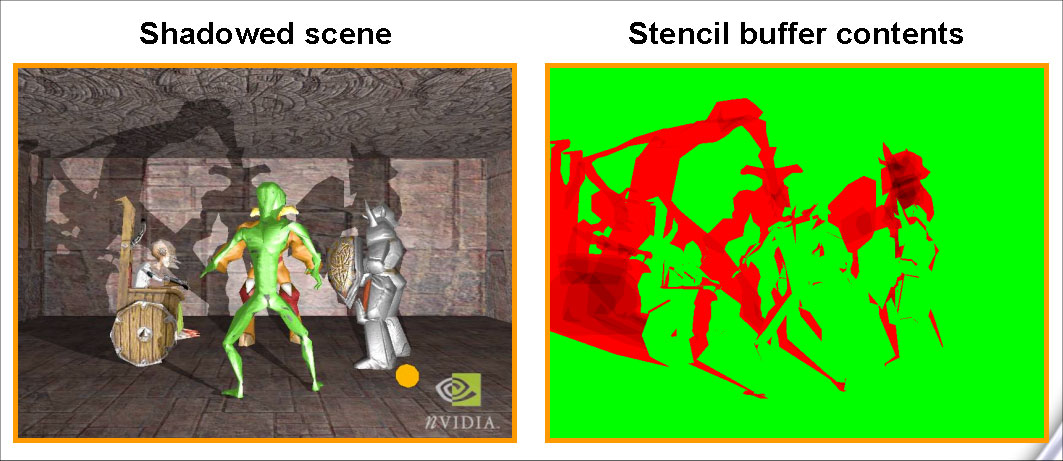
―――最新のFX5900シリーズも含めたGeForce FX全シリーズで,色演算とZバッファ操作を同時に行ったときのスループットが4PPC(*3)ですね(「こちら」のスペック比較表参照)。これを見ると,Zバッファやステンシルバッファなどの操作は,上位のFX5800以上は8PPC,下位のGeForce FX 5600(以下,FX5600)以下では4PPCと,2倍のパフォーマンス格差が与えられています。この「格差」はどのような理由で付けたものなのですか?
Kirk:
そうです。一つ良い例があります。現在劇場公開中の「マトリックス・リローデッド」と,発売中のゲーム「ENTER THE MATRIX」です。
このゲームは,映画用とゲーム用にそれぞれ作成されたCGコンテンツを,お互いに流用しています。もし演算精度が同じならば,このようなことが簡単にできるのです。