















連載
西川善司の3DGE:「Ryzen」は何が新しくなったのか。そのマイクロアーキテクチャに迫る
2017年3月3日,AMDが,新世代CPU「Ryzen」(ライゼン)を正式発表した。2月22日掲載の記事で,AMDは最上位モデル「Ryzen 7」のラインナップと価格,発売日を告知済みだが,今回の正式発表にあたっては,下位モデルの存在,そして最も気になる「Zen」マイクロアーキテクチャの詳細が明らかになっている。
ラインナップ紹介は別途掲載したまとめ記事に任せ,本稿ではZenマイクロアーキテクチャ,そしてRyzenの技術面にフォーカスして,解説を行ってみたい。
なお,Ryzenのマイクロアーキテクチャに関する解説は,報道関係者向け技術解説イベント「Tech Day」において,AMDシニアフェローのMichael Clark(マイケル・クラーク)氏が担当した。氏は基本的に,スライドに書いてある内容を読み上げる形で話を進めたので,以下紹介する内容は,それを要約のうえ,筆者なりの考察を交えたものになることを,あらかじめお断りしておく。
いきなりだが,下に示したのは,開発コードネーム「Summit Ridge」(サミットリッジ)と呼ばれていたRyzenの命令実行部をブロック図化したものだ。
前世代のマイクロアーキテクチャ「Bulldozer」(ブルドーザ)だと,2基の整数演算ユニットで1基の浮動小数点演算ユニットを共有する,モジュール設計となっていた。それがZenマイクロアーキテクチャでは刷新され,CPUコアごとに整数演算ユニットと浮動小数点演算ユニットを統合する構成となっている。
対応命令セットはIntelのCoreプロセッサ準拠だが,「AVX-512」には対応しない。もっともAVX-512はHPC向けの512bit幅SIMD命令で,「Xeon Phi」など一部のプロセッサが対応するのみなので,ここは対応する必要がないという判断が入ったのだろう。GPGPUが浸透し,GPUもAPUも持つAMDとしては,「512bit幅のSIMD命令をCPUで実行させる旨味がない」と判断した可能性もある。
さて,各CPUコアは,物理的な1コアを論理的に2コアに見せかけることで,内部に抱える実行ユニットの実行効率の向上を図るSMT(Simultaneous Multithreading,サイマルテイニアス マルチスレッディング)に対応する。
ここで基礎知識を整理しておこう。
命令セットアーキテクチャには大別すると「CISC」(シスク,Complex Instruction Set Computer)と「RISC」(リスク,Reduced Instruction Set Computer)がある。前者は,複雑な命令セットで一連の処理を済ませ,命令の回数を減らすことで性能向上を図る方式,後者は簡単な命令セットを高速に動かすことで性能向上を図る方式だ。
先ほどRyzenはCoreプロセッサ準拠と述べたが,厳密にはx86アーキテクチャ互換のプロセッサであり,x86はCISCを採用している。ただし,CISCでは命令語のバイナリが可変長構造になったり,命令実行にかかる時間がまちまちになったりして,多段パイプラインでの実行が難しい。そのため最近のx86プロセッサでは「表向きはCISCだが,内部の実行スタイルはRISC」といった感じで,「メモリから読み出して演算し,メモリに書き込む」といったCISC命令語を,「メモリからの読み出し」「演算」「メモリへの書き込み」といったRISCスタイルに変換するのが主流となっている。
というわけで本題だが,先に示したRyzen命令実行部のブロック図における最上段は,まさにこの「CISC命令を内部RISC命令に変換する流れ」を示している。内部RISC命令のことを今回AMDは「Micro-Op」(Micro Operation,マイクロオプ)と呼んでいるが,Ryzenでは,1クロックで,CISC命令語の単位で言うところの4命令を一度にデコード(decode,復号化)して,複数のMicro-Opへ分解できるようになっている。そして,「Micro-Op Que」(マイクロオプ キュー)が,1クロックあたり最大6個のMicro-Opを,この先にある内部演算ユニットに対して発行可能だ。
ちなみにBulldozer世代だとクロックあたりのMicro-Op同時発行数は4だったから,Ryzen(≒Zen世代)では先代比1.5倍へ拡張を果たしたことになる。
デコーダを示す「Decode」の上に見える「64K I-Cache 4 Way」は容量64KBの命令キャッシュだ。「4 Way」は,「4-wayのセットアソシエイティブキャッシュである」という意味で,言い換えると,アドレスの一部を「タグID」(Tag ID,キャッシュメモリ上における管理番号のようなもの)に活用するキャッシュシステムにおいて,4つのアドレスバリエーションまでキャッシュできるということである。
また,Micro-Op Queの右上にある「Op Cache」は,CISC命令から分解したMicro-Opを(発行まで一時的に)保持しておくためのキャッシュメモリだ。容量は未公開だが,AMDは「とても大きい」としている。これは,Bulldozer系にはなかった要素だという。
最後に「Branch Prediction」(ブランチプレディクション)は分岐予測ユニットだ。ここでAMDが「Neural Net Prediction」(ニューラルネットプレディクション)技術を採用していることは本連載のバックナンバー「AMDの次世代CPU,製品名は『Ryzen』に決定! 性能向上を支える5つの要素も明らかに」で紹介済みのため,本稿では割愛する。
新情報としては,Bulldozerだと,分岐予測が外れた場合のペナルティが20クロックあったのに対し,Ryzenではこれが3クロックへと大幅な低減を果たしたことが挙げられよう。
Ryzenでは,分岐命令自体のアドレスから予測した分岐先アドレスを格納しておくバッファである「Branch Target Buffer」(ブランチターゲットバッファ)において,1エントリあたり分岐先を2つまで格納しておけるよう改良が入っている。
発行されたMicro-Op(※複数形では「Micro-Ops」)は,整数系命令か,浮動小数点系命令かによって,図中の赤エリアで実行先が分かれる。図では左が整数演算系パイプライン,右が浮動小数点系パイプラインだ。
x86命令セット,というか正確にはその64bit版であるAMD64(x64)命令セット上だが,仕様上,そこにはレジスタが16個しかない――汎用レジスタが8個と,セグメントレジスタが6個,フラグレジスタと命令ポインタが各1個――ため,コンパイラは,この16個のレジスタで表現できる範囲で変数を取り扱ってアセンブリコードを吐き出す。
問題は,x86命令の少ないレジスタ数が原因となり,命令間の依存関係が生じてしまうことで,これはMicro-OpベースのRISC的な処理にあたって大きなハードルとなる。そこで最近のx86互換CPUでは,内部にある大量の内部レジスタに「x86命令セット互換CPUとしての,16個しかないレジスタ」を適切に割り振って,仕様制限により生じる依存関係を解消する技術「レジスタリネーミング」(Register Renaming)を採用するようになっている。
Ryzenにおけるレジスタリネーミングは168個と,Bulldozer世代の96個から1.75倍になった。つまり,プログラムのより広い範囲で,x86命令間の依存関係解消を図ることができるようになるわけだ。
このレジスタリネーミングを行うのが,ブロック図中にある「Integer Rename」(整数リネーム)と「Floating Point Rename」(浮動小数点リネーム)である。
それらの下にある「Scheduler」(スケジューラ)は,整数系パイプラインだと後段の「ALU」(Arithmetic and Logic Unit,演算ユニット)と「AGU」(Address Generation Unit,メモリアクセス用のアドレス生成ユニット),浮動小数点パイプラインでは「MUL」(MULtiply,乗算ユニット),「ADD」(加算ユニット)に対して,「Schedulerが溜め込んでいるMicro-Opのうち,どの実行を仕掛けるか」を決定するユニットだ。
ALUは4基,AGUとMUL,ADDは2基ずつある。
Schedulerは,その後段にあるALU,AGU,MUL,ADD各実行ユニットの空き具合に応じて,命令実行の依存関係が破壊されない範囲において,並列(Superscalar,スーパースケーラ)実行を仕掛ける。もちろん,場合によっては順不同(Out-of-order,アウトオブオーダ―)実行も行う。
たとえば整数演算パイプラインでLoad命令の実行によるメモリの読み出しが2件発生したとしよう。この場合,AGUに空きはなくなってしまうが,このときALUが空いているなら,Schedulerによって待機させられていた(≒溜め込んでいた)Micro-Opのうち,「2件のメモリ読み出し実行」と依存関係のない命令なら,最大4つをALUに対して仕掛けることができる。これがSchedulerの仕事だ。
以下,本稿では整数パイプラインに流れたMicro-Opを「整数命令」,浮動小数点パイプラインに流れたMicro-Opを「浮動小数点命令」と呼ぶが,RyzenのSchedulerは,整数と浮動小数点それぞれのパイプラインにおいて,整数命令なら84個,浮動小数点命令なら96個まで溜め込んだうえでのスケジューリングを行える。ちなみに,Bulldozer系のSchedulerは整数命令が40個,浮動小数点命令が60個だった(※先ほど示した写真「Ryzenの進化ポイント,コアエンジン編」にある整数命令48個というのは誤り)。
さて,順不同実行において,プログラム登場順で一番新しい命令がすでに実行完了していても,それよりも古い命令の実行が終わっていない,専門用語でいうところの「Retireしていない」場合,その新しい命令を完了扱い(=Retire扱い)にすることはできない。
古い命令の実行を終えられない原因には「依存関係にある命令の実行が終わってない」などいくつかあるが,この順不同実行の結果の反映(=Retire処理)が手一杯になっている場合にも起こりうる。
Ryzenでは,この点でも改善が入っており,Retire処理の同時実行数を,Bulldozer世代比で2倍の8 Micro-Opsへ拡大したとのことだ。
命令実行部の後段にある「Load/Store Queues」は,いわゆるメモリの読み出し(ロード)/書き込み(ストア)命令発行ユニットになり,その実行サイクルは1クロックあたり2読み出し,1書き込みとなる。
またRyzenでは,72個分のメモリ読み出しおよび44個分のメモリ書き出しを順不同で実行できる順不同処理に対応しているのも特徴だ。そして,順不同で行ったメモリアクセスのRetire処理は192個まで同時に行える。
ここで言う「順不同のメモリアクセス」とは,メモリアクセスを行うMicro-Op実行にあたって,当該メモリアクセスに伴った実行依存関係を破壊しない限り,キャッシュに載ったメモリアクセスを先行させる処理系のことである。
Ryzen 7では,CPUコアあたりのL1データキャッシュが容量32KB,L2キャッシュが容量512KB,それとは別に,総容量16MBのL3キャッシュと統合しており,基本的にCPUコアから近い順に早くアクセスが完了する。メインメモリが一番遠くて遅いことは衆知の事実だろう。
Ryzenでは,こうした順不同のメモリアクセスを許容することにより,ベストケースではメインメモリアクセス待ち時間の隠蔽を行えることになる。
早期に実行完了したメモリアクセスに依存した演算命令が,次のサイクルでこれまた順不同に実行できたり,あるいは他命令と同時実行できれば,クロックあたりの命令実行数は向上するというわけだ。
Ryzenのフロントエンドを図解したものが下の画像だ。なお,フロントエンドとは,CPUが命令を実行するにあたっての「始まり」の部分である。「どのアドレスの命令の実行を仕掛けるか」を決定するプログラムカウンタ(Program Counter)更新部分と言ってもいいだろう。
図には仮想アドレスから物理アドレスへ変換するためのキャッシュメモリ的な「TLB」(Translation Lookaside Buffer,トランスレーションルックアサイドバッファ)や,分岐先アドレスを予測する「BTB」(Branch Target Buffer,ブランチターゲットバッファ)が描かれているのを見て取れる。
ちなみにこの図だと,分岐先アドレスを予測する分岐先予測は,「Neural Network」(ニューラルネットワーク)だ。
ここで注意が必要なのは,前出のBranch Predictionは分岐予測,フロントエンド部のBTBが分岐先予測をそれぞれ担当するということだ。分岐予測は「分岐するかしないかを予測するもの」,分岐先予測は「分岐する先のアドレスを予測する」部分である。
もちろん,分岐予測と分岐先予測は関係が深く,分岐予測の結果を踏まえて分岐先アドレスを選択することになるのだが。
その分岐先アドレスのキャッシュ場所であるBTBは,容量こそ非公開ながら,「L1,L2の2レベル構造で,とても大きいものになっている」とAMDは述べている。
また,1つの分岐命令から複数の分岐先アドレスを予測して発行できるとのことで,これは完全な失敗に終わる投機実行の数を低減させる効果にに結びつくはずだ。
SMTの実行形態についても触れておこう。
Ryzenでは,このフロントエンドが,スレッド割り込みレベル優先順位の制御を受けながら,独立した2つの論理CPUコアとして振る舞って,後段の実行ユニットを駆動する。
そして実行ユニットのほぼすべては,2つの論理CPUコアのスレッドによって奪い合う形で実行が仕掛けられる。つまり,2つの論理CPUコアが,1基のCPUコアに対して,早い者勝ちで空いている実行ユニットを起用し,2スレッドで実行していくということだ。
いま「ほぼすべて」と述べたのは例外があるからで,実行ユニット段にあるMicro-Op QueueとRetire Queue,Store Queueの3ユニットは,SMTにおける2つのスレッド分,つまり2つある。
AMDは,Zenマイクロアーキテクチャにおいて,4コア8スレッドを1つのCPUモジュールとして構成し,それに「Core Complex」という名を与えている。公式略称は「CCX」だ。
本稿では以下CCXと表記するが,その全体像は以下の図で示すことができる。
4コアが1つのCCXを構成するので,8コアCPUであるRyzen 7は2基のCCXを1パッケージに実装したものということになる。Ryzen 5とRyzen 3でどのようなパッケージレイアウトを採用するかAMDは明言していないが,筆者の独自取材によれば,(少なくとも発売当初は)いずれも2基のCCXを統合することになるようだ。
CCXのブロック図を見ながらあらためてキャッシュ周りの確認だが,L2キャッシュは1コアあたり512KBの8-wayアソシエイティブ(※1)仕様で,L2キャッシュの内容はL1命令キャッシュおよびL1データキャッシュの内容と重複することを許容する設計だ。キャッシュされるデータ長は,L1,L2,L3の全キャッシュで統一して32B(バイト)となっている。
L3キャッシュは8MBの16-wayアソシエイティブ仕様で,こちらは4コアすべて,すなわちCCX全体で共有する構造となる。
CCX全体図を見て気付いた読者もいると思うが,L3キャッシュは4スライス(4つのブロック)構成だ。なぜ4スライスかというと,キャッシュメモリアクセスを分散させるため。言い換えれば,L3キャッシュは4chのインタリーブアクセスを行う設計になっているのである。
具体的にはアドレスの最下位2bitでチャンネルを指定するLow-order Address Interleave(ローオーダーアドレスインタリーブ)仕様になっているそうだ。
AMDは,「L3キャッシュの内容はL2キャッシュの内容と被らないような振る舞いを心がけているが,完璧ではなく,多少は重複することもある」としていた。
Ryzen 7は,1モジュールあたり4コアCPUの形態をとるCCXを2基まとめることで8コア/16スレッドCPUとなっているが,2基あるCCX同士を接続する内部バスには「Infinity Fabric」(インフィニティファブリック)という名前が付いている。
Infinity Fabric技術について解説したのは,この機能の実質的な設計者であるMark Papermaster(マーク・ペーパーマスター)上級副社長兼CTOだ。
Infinity Fabricは,物理仕様は一種類ながら,種別上は「Scalable Control Fabric」(スケーラブルコントロールファブリック,以下 SCF)と「Scalable Data Fabric」(スケーラブルデータファブリック,以下 SDF)の2つに分類される。
SCFは,プロセッサ内でやりとりするデータを伝送するためのバスで,たとえばAMDプロセッサ内に他社,それこそARMなどのIP(Intellectual Property,知的財産)コアを組み込んだ場合でも,SDFによりデータをやり取りできるようになる。また詳細は後述するが,CPU内にあるセンサーの情報共有にもSCFを用いる。
SDFは,メモリやほかのAMD製プロセッサを相互接続してデータをやりとりするためのバスだ。たとえばRyzen 7の場合,CCX同士を接続するのにSDFを使っている。
Ryzenというより,Zenマイクロアーキテクチャベースのサーバー用CPUが出てきたときには,「複数のソケットに差さったAMD製CPU同士の接続」にもSDFを用いることになるだろう。
少々余談になるが,Papermaster氏によれば,Infinity Fabricに対応した最初のGPUは,2017年第2四半期のデビューが予定されている「Vega」(開発コードネーム)になるとのことだ。
PCI Express接続型のグラフィックスカードだと,Infinity Fabricはあまり関係ないが,Zen世代のCPUコアとVega世代のGPUコアを統合する次世代APU「Raven Ridge」(レイヴンリッジ,開発コードネーム)では,Infinity Fabricの本領が発揮となることだろう。
もう1つ,Zenマイクロアーキテクチャで気になる重要なポイントである電力性能については,コーポレートフェローのSam Naffziger(サム・ナッフィチガー)氏が物理設計ともども解説した。
いわく,同じ14nmプロセス技術世代のCPUでも,IntelのKaby Lakeコアと比べた場合,チップ面積利用効率の観点から見て,Ryzenのほうが物理レイアウトは約10%優れているとのことだ。
また,2016年12月のタイミングでもレポートしているが,Ryzenは,AMDが「SenseMI Technology」と呼ぶ,CPU内部のそこかしこに配したさまざまなセンサーから情報を得て,プロセッサ自体の動作を最適化させる仕組みを搭載している。
そして今回明らかになったのは,そのなかでも省電力制御を行う機能「Pure Power」についてで,内部にある1300個以上のセンサーがもたらす情報を基に,プロセッサを制御しているのだという。1300以上あるセンサーのうち,48個は給電監視センサー,20個は温度センサー,9個は電圧センサーだそうだ。
先ほど後述するとしたが,この1300以上ものセンサーから情報を得るにあたっては,Infinity Fabricが活用されている。
従来のCPU設計だと,こうした「プロセッサ内部でやりとりする,用途の限定された情報」の伝送には,設計部門ごとに独自バスを引いたりすることがあったという。それをZenマイクロアーキテクチャでは見直し,何から何まで一貫したInfinity Fabricを利用することにしたというわけだ。「物理レイアウトで競合より10%優れている」のも,このような,徹底的に無駄を省いた設計思想が功を奏したからに違いない。
いかがだっただろうか。
Ryzenの設計には妥協点がなく,また,あらゆる新要素の実現にとにかく新技術を採用するといったあたりに,AMDの本気度を窺い知ることができるのではないかと思う。明らかになっているとおり,価格設定もかなり戦略的になっているため,性能重視のゲームPC(やハイエンド志向のデスクトップPC,シングルCPUワークステーション)を手に入れたい人の中で,Ryzen 7が大きな注目を集めるであろうことは想像に難くない。
あえて弱点を探すとすると,AMDが競合と位置づけるCPUのうち,Broadwell-Eコアのものは,CPU側に40レーンのPCI Express 3.0リンクを持つ点が挙げられるだろう。24レーンに留まるRyzenはここが負い目となり得る。
ただ,突っ込まれるのを見越していたAMDは,この点について「我々が評価する限り,(グラフィックスカードを2枚差しての)4Kレンダリング実行時に,8レーン×2で帯域幅が不足することはなかった」「AM4プラットフォームはRyzenだけでなくAPUとの兼用プラットフォームということもあり,24レーンを超えるPCI Expressリンクの実装は難しい」と述べているので,この点は書いておきたいと思う。
なお,Tech Dayには,ミスターRadeonとでも呼ぶべき,Radeon Technologies Groupの総帥,Raja Koduri(ラジャ・コドゥリ)氏も登場。「業界は速いCPUを待ち望んでいた」というテーマで,自ら主演するルポ番組タッチ長編動画「Raja & Friends」を上演して,来場者に見せつけていた。
さらにKoduri氏は「もうRyzenの発売が待てない」とCPU部門のスタッフに詰め寄り,500ドルを手渡してRyzen 7 1800Xをフライングゲットするという,コメディタッチのやりとりも披露。このあたりのお茶目さと陽気さはAMD独特の文化と言ったところである。
さて,そんな気になるRyzen 7から,4GamerではKoduri氏も手に入れたRyzen 7 1800Xを入手し,テストしている。その実力が気になる人は,そちらもぜひチェックしてほしいと思う。
 |
ラインナップ紹介は別途掲載したまとめ記事に任せ,本稿ではZenマイクロアーキテクチャ,そしてRyzenの技術面にフォーカスして,解説を行ってみたい。
 |
Ryzenのマイクロアーキテクチャ(1)命令デコード部から発行部まで
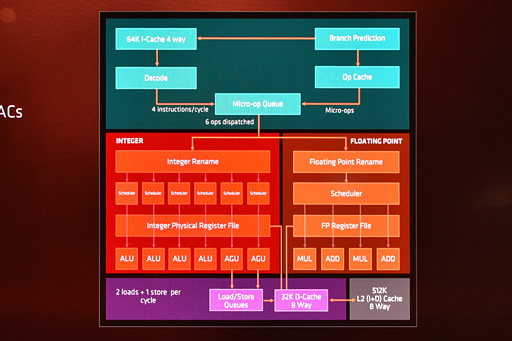
いきなりだが,下に示したのは,開発コードネーム「Summit Ridge」(サミットリッジ)と呼ばれていたRyzenの命令実行部をブロック図化したものだ。
 |
 |
 |
対応命令セットはIntelのCoreプロセッサ準拠だが,「AVX-512」には対応しない。もっともAVX-512はHPC向けの512bit幅SIMD命令で,「Xeon Phi」など一部のプロセッサが対応するのみなので,ここは対応する必要がないという判断が入ったのだろう。GPGPUが浸透し,GPUもAPUも持つAMDとしては,「512bit幅のSIMD命令をCPUで実行させる旨味がない」と判断した可能性もある。
さて,各CPUコアは,物理的な1コアを論理的に2コアに見せかけることで,内部に抱える実行ユニットの実行効率の向上を図るSMT(Simultaneous Multithreading,サイマルテイニアス マルチスレッディング)に対応する。
ここで基礎知識を整理しておこう。
命令セットアーキテクチャには大別すると「CISC」(シスク,Complex Instruction Set Computer)と「RISC」(リスク,Reduced Instruction Set Computer)がある。前者は,複雑な命令セットで一連の処理を済ませ,命令の回数を減らすことで性能向上を図る方式,後者は簡単な命令セットを高速に動かすことで性能向上を図る方式だ。
先ほどRyzenはCoreプロセッサ準拠と述べたが,厳密にはx86アーキテクチャ互換のプロセッサであり,x86はCISCを採用している。ただし,CISCでは命令語のバイナリが可変長構造になったり,命令実行にかかる時間がまちまちになったりして,多段パイプラインでの実行が難しい。そのため最近のx86プロセッサでは「表向きはCISCだが,内部の実行スタイルはRISC」といった感じで,「メモリから読み出して演算し,メモリに書き込む」といったCISC命令語を,「メモリからの読み出し」「演算」「メモリへの書き込み」といったRISCスタイルに変換するのが主流となっている。
 |
ちなみにBulldozer世代だとクロックあたりのMicro-Op同時発行数は4だったから,Ryzen(≒Zen世代)では先代比1.5倍へ拡張を果たしたことになる。
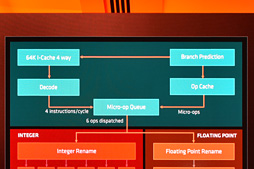
デコーダを示す「Decode」の上に見える「64K I-Cache 4 Way」は容量64KBの命令キャッシュだ。「4 Way」は,「4-wayのセットアソシエイティブキャッシュである」という意味で,言い換えると,アドレスの一部を「タグID」(Tag ID,キャッシュメモリ上における管理番号のようなもの)に活用するキャッシュシステムにおいて,4つのアドレスバリエーションまでキャッシュできるということである。
また,Micro-Op Queの右上にある「Op Cache」は,CISC命令から分解したMicro-Opを(発行まで一時的に)保持しておくためのキャッシュメモリだ。容量は未公開だが,AMDは「とても大きい」としている。これは,Bulldozer系にはなかった要素だという。
最後に「Branch Prediction」(ブランチプレディクション)は分岐予測ユニットだ。ここでAMDが「Neural Net Prediction」(ニューラルネットプレディクション)技術を採用していることは本連載のバックナンバー「AMDの次世代CPU,製品名は『Ryzen』に決定! 性能向上を支える5つの要素も明らかに」で紹介済みのため,本稿では割愛する。
新情報としては,Bulldozerだと,分岐予測が外れた場合のペナルティが20クロックあったのに対し,Ryzenではこれが3クロックへと大幅な低減を果たしたことが挙げられよう。
Ryzenでは,分岐命令自体のアドレスから予測した分岐先アドレスを格納しておくバッファである「Branch Target Buffer」(ブランチターゲットバッファ)において,1エントリあたり分岐先を2つまで格納しておけるよう改良が入っている。
Ryzenのマイクロアーキテクチャ(2)命令実行部
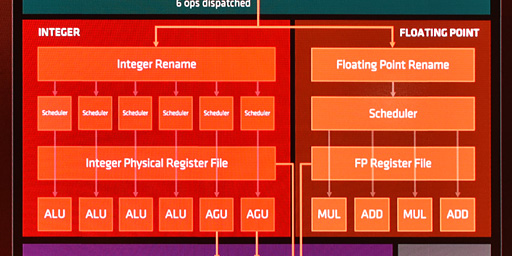
発行されたMicro-Op(※複数形では「Micro-Ops」)は,整数系命令か,浮動小数点系命令かによって,図中の赤エリアで実行先が分かれる。図では左が整数演算系パイプライン,右が浮動小数点系パイプラインだ。
 |
x86命令セット,というか正確にはその64bit版であるAMD64(x64)命令セット上だが,仕様上,そこにはレジスタが16個しかない――汎用レジスタが8個と,セグメントレジスタが6個,フラグレジスタと命令ポインタが各1個――ため,コンパイラは,この16個のレジスタで表現できる範囲で変数を取り扱ってアセンブリコードを吐き出す。
 |
Ryzenにおけるレジスタリネーミングは168個と,Bulldozer世代の96個から1.75倍になった。つまり,プログラムのより広い範囲で,x86命令間の依存関係解消を図ることができるようになるわけだ。
このレジスタリネーミングを行うのが,ブロック図中にある「Integer Rename」(整数リネーム)と「Floating Point Rename」(浮動小数点リネーム)である。
それらの下にある「Scheduler」(スケジューラ)は,整数系パイプラインだと後段の「ALU」(Arithmetic and Logic Unit,演算ユニット)と「AGU」(Address Generation Unit,メモリアクセス用のアドレス生成ユニット),浮動小数点パイプラインでは「MUL」(MULtiply,乗算ユニット),「ADD」(加算ユニット)に対して,「Schedulerが溜め込んでいるMicro-Opのうち,どの実行を仕掛けるか」を決定するユニットだ。
ALUは4基,AGUとMUL,ADDは2基ずつある。
Schedulerは,その後段にあるALU,AGU,MUL,ADD各実行ユニットの空き具合に応じて,命令実行の依存関係が破壊されない範囲において,並列(Superscalar,スーパースケーラ)実行を仕掛ける。もちろん,場合によっては順不同(Out-of-order,アウトオブオーダ―)実行も行う。
たとえば整数演算パイプラインでLoad命令の実行によるメモリの読み出しが2件発生したとしよう。この場合,AGUに空きはなくなってしまうが,このときALUが空いているなら,Schedulerによって待機させられていた(≒溜め込んでいた)Micro-Opのうち,「2件のメモリ読み出し実行」と依存関係のない命令なら,最大4つをALUに対して仕掛けることができる。これがSchedulerの仕事だ。
以下,本稿では整数パイプラインに流れたMicro-Opを「整数命令」,浮動小数点パイプラインに流れたMicro-Opを「浮動小数点命令」と呼ぶが,RyzenのSchedulerは,整数と浮動小数点それぞれのパイプラインにおいて,整数命令なら84個,浮動小数点命令なら96個まで溜め込んだうえでのスケジューリングを行える。ちなみに,Bulldozer系のSchedulerは整数命令が40個,浮動小数点命令が60個だった(※先ほど示した写真「Ryzenの進化ポイント,コアエンジン編」にある整数命令48個というのは誤り)。
さて,順不同実行において,プログラム登場順で一番新しい命令がすでに実行完了していても,それよりも古い命令の実行が終わっていない,専門用語でいうところの「Retireしていない」場合,その新しい命令を完了扱い(=Retire扱い)にすることはできない。
古い命令の実行を終えられない原因には「依存関係にある命令の実行が終わってない」などいくつかあるが,この順不同実行の結果の反映(=Retire処理)が手一杯になっている場合にも起こりうる。
Ryzenでは,この点でも改善が入っており,Retire処理の同時実行数を,Bulldozer世代比で2倍の8 Micro-Opsへ拡大したとのことだ。
Ryzenのマイクロアーキテクチャ(3)ロード/ストア実行部
命令実行部の後段にある「Load/Store Queues」は,いわゆるメモリの読み出し(ロード)/書き込み(ストア)命令発行ユニットになり,その実行サイクルは1クロックあたり2読み出し,1書き込みとなる。
またRyzenでは,72個分のメモリ読み出しおよび44個分のメモリ書き出しを順不同で実行できる順不同処理に対応しているのも特徴だ。そして,順不同で行ったメモリアクセスのRetire処理は192個まで同時に行える。
 |
ここで言う「順不同のメモリアクセス」とは,メモリアクセスを行うMicro-Op実行にあたって,当該メモリアクセスに伴った実行依存関係を破壊しない限り,キャッシュに載ったメモリアクセスを先行させる処理系のことである。
 |
Ryzenでは,こうした順不同のメモリアクセスを許容することにより,ベストケースではメインメモリアクセス待ち時間の隠蔽を行えることになる。
早期に実行完了したメモリアクセスに依存した演算命令が,次のサイクルでこれまた順不同に実行できたり,あるいは他命令と同時実行できれば,クロックあたりの命令実行数は向上するというわけだ。
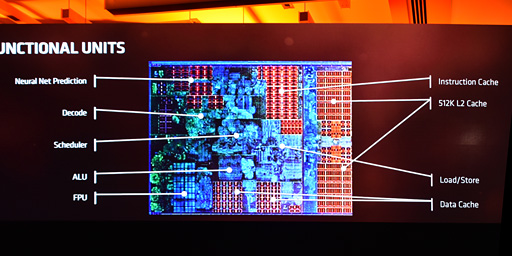 |
Ryzenのマイクロアーキテクチャ(4)フロントエンド
Ryzenのフロントエンドを図解したものが下の画像だ。なお,フロントエンドとは,CPUが命令を実行するにあたっての「始まり」の部分である。「どのアドレスの命令の実行を仕掛けるか」を決定するプログラムカウンタ(Program Counter)更新部分と言ってもいいだろう。
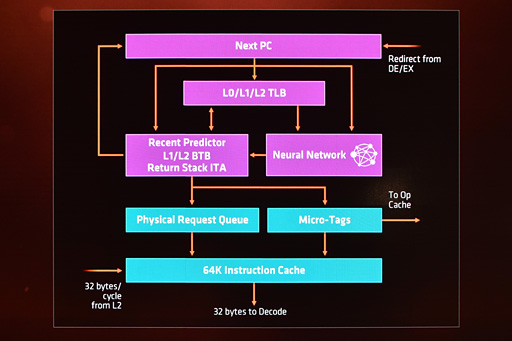 |
図には仮想アドレスから物理アドレスへ変換するためのキャッシュメモリ的な「TLB」(Translation Lookaside Buffer,トランスレーションルックアサイドバッファ)や,分岐先アドレスを予測する「BTB」(Branch Target Buffer,ブランチターゲットバッファ)が描かれているのを見て取れる。
ちなみにこの図だと,分岐先アドレスを予測する分岐先予測は,「Neural Network」(ニューラルネットワーク)だ。
ここで注意が必要なのは,前出のBranch Predictionは分岐予測,フロントエンド部のBTBが分岐先予測をそれぞれ担当するということだ。分岐予測は「分岐するかしないかを予測するもの」,分岐先予測は「分岐する先のアドレスを予測する」部分である。
もちろん,分岐予測と分岐先予測は関係が深く,分岐予測の結果を踏まえて分岐先アドレスを選択することになるのだが。
その分岐先アドレスのキャッシュ場所であるBTBは,容量こそ非公開ながら,「L1,L2の2レベル構造で,とても大きいものになっている」とAMDは述べている。
また,1つの分岐命令から複数の分岐先アドレスを予測して発行できるとのことで,これは完全な失敗に終わる投機実行の数を低減させる効果にに結びつくはずだ。
 |
Ryzenでは,このフロントエンドが,スレッド割り込みレベル優先順位の制御を受けながら,独立した2つの論理CPUコアとして振る舞って,後段の実行ユニットを駆動する。
そして実行ユニットのほぼすべては,2つの論理CPUコアのスレッドによって奪い合う形で実行が仕掛けられる。つまり,2つの論理CPUコアが,1基のCPUコアに対して,早い者勝ちで空いている実行ユニットを起用し,2スレッドで実行していくということだ。
いま「ほぼすべて」と述べたのは例外があるからで,実行ユニット段にあるMicro-Op QueueとRetire Queue,Store Queueの3ユニットは,SMTにおける2つのスレッド分,つまり2つある。
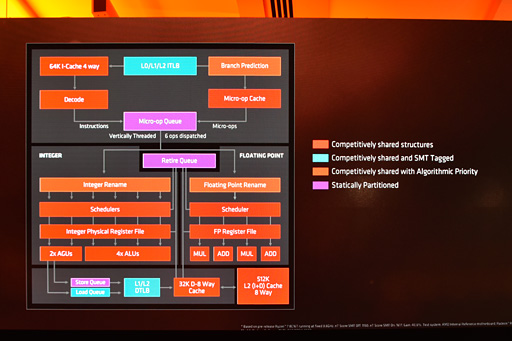 |
Ryzenのマイクロアーキテクチャ(5)全体像とキャッシュ周り
AMDは,Zenマイクロアーキテクチャにおいて,4コア8スレッドを1つのCPUモジュールとして構成し,それに「Core Complex」という名を与えている。公式略称は「CCX」だ。
本稿では以下CCXと表記するが,その全体像は以下の図で示すことができる。
 |
4コアが1つのCCXを構成するので,8コアCPUであるRyzen 7は2基のCCXを1パッケージに実装したものということになる。Ryzen 5とRyzen 3でどのようなパッケージレイアウトを採用するかAMDは明言していないが,筆者の独自取材によれば,(少なくとも発売当初は)いずれも2基のCCXを統合することになるようだ。
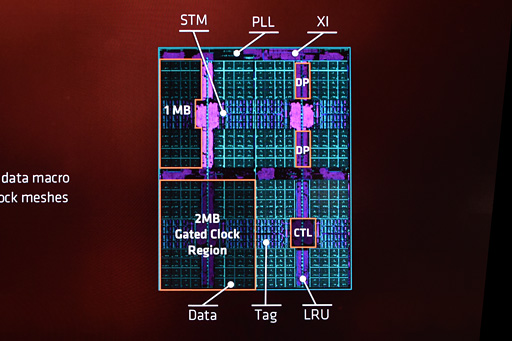
CCXのブロック図を見ながらあらためてキャッシュ周りの確認だが,L2キャッシュは1コアあたり512KBの8-wayアソシエイティブ(※1)仕様で,L2キャッシュの内容はL1命令キャッシュおよびL1データキャッシュの内容と重複することを許容する設計だ。キャッシュされるデータ長は,L1,L2,L3の全キャッシュで統一して32B(バイト)となっている。
 |
 |
※1 メインメモリに存在するデータを「キャッシュライン」へ格納して,メモリアクセスの高速化を図るときに使うのがキャッシュメモリだ。ここでは「キャッシュラインに格納しているデータのアドレス」の情報が必要になるが,アドレスをいちいちデータとセットで保存していると,キャッシュにデータが存在するかどうかを検索するのに時間がかかってしまう難点がある。そのため,アドレスの一部を検索タグとして使い,検索速度を高めるわけだが,そのときタグとキャッシュラインを1対1の対応にしてしまうと,同一のタグを生成しているアドレスのキャッシュ同士が衝突してしまい,キャッシュを効率的に使えなくなる。そこで,1つのタグに対してn個のキャッシュラインを対応させる(n-way)構造が登場した。これがn-wayアソシエイティブだ。
 |
CCX全体図を見て気付いた読者もいると思うが,L3キャッシュは4スライス(4つのブロック)構成だ。なぜ4スライスかというと,キャッシュメモリアクセスを分散させるため。言い換えれば,L3キャッシュは4chのインタリーブアクセスを行う設計になっているのである。
具体的にはアドレスの最下位2bitでチャンネルを指定するLow-order Address Interleave(ローオーダーアドレスインタリーブ)仕様になっているそうだ。
AMDは,「L3キャッシュの内容はL2キャッシュの内容と被らないような振る舞いを心がけているが,完璧ではなく,多少は重複することもある」としていた。
 |
Ryzenのアーキテクチャ(6)そのほかRyzenを支える技術達
 |
Infinity Fabric技術について解説したのは,この機能の実質的な設計者であるMark Papermaster(マーク・ペーパーマスター)上級副社長兼CTOだ。
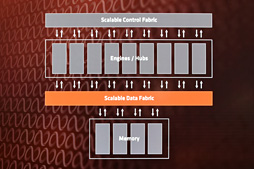
Infinity Fabricは,物理仕様は一種類ながら,種別上は「Scalable Control Fabric」(スケーラブルコントロールファブリック,以下 SCF)と「Scalable Data Fabric」(スケーラブルデータファブリック,以下 SDF)の2つに分類される。
SCFは,プロセッサ内でやりとりするデータを伝送するためのバスで,たとえばAMDプロセッサ内に他社,それこそARMなどのIP(Intellectual Property,知的財産)コアを組み込んだ場合でも,SDFによりデータをやり取りできるようになる。また詳細は後述するが,CPU内にあるセンサーの情報共有にもSCFを用いる。
 |
 |
SDFは,メモリやほかのAMD製プロセッサを相互接続してデータをやりとりするためのバスだ。たとえばRyzen 7の場合,CCX同士を接続するのにSDFを使っている。
Ryzenというより,Zenマイクロアーキテクチャベースのサーバー用CPUが出てきたときには,「複数のソケットに差さったAMD製CPU同士の接続」にもSDFを用いることになるだろう。
 |
 |
 |
 |
少々余談になるが,Papermaster氏によれば,Infinity Fabricに対応した最初のGPUは,2017年第2四半期のデビューが予定されている「Vega」(開発コードネーム)になるとのことだ。
PCI Express接続型のグラフィックスカードだと,Infinity Fabricはあまり関係ないが,Zen世代のCPUコアとVega世代のGPUコアを統合する次世代APU「Raven Ridge」(レイヴンリッジ,開発コードネーム)では,Infinity Fabricの本領が発揮となることだろう。
 |
 |
いわく,同じ14nmプロセス技術世代のCPUでも,IntelのKaby Lakeコアと比べた場合,チップ面積利用効率の観点から見て,Ryzenのほうが物理レイアウトは約10%優れているとのことだ。
 |
また,2016年12月のタイミングでもレポートしているが,Ryzenは,AMDが「SenseMI Technology」と呼ぶ,CPU内部のそこかしこに配したさまざまなセンサーから情報を得て,プロセッサ自体の動作を最適化させる仕組みを搭載している。
そして今回明らかになったのは,そのなかでも省電力制御を行う機能「Pure Power」についてで,内部にある1300個以上のセンサーがもたらす情報を基に,プロセッサを制御しているのだという。1300以上あるセンサーのうち,48個は給電監視センサー,20個は温度センサー,9個は電圧センサーだそうだ。
 |
従来のCPU設計だと,こうした「プロセッサ内部でやりとりする,用途の限定された情報」の伝送には,設計部門ごとに独自バスを引いたりすることがあったという。それをZenマイクロアーキテクチャでは見直し,何から何まで一貫したInfinity Fabricを利用することにしたというわけだ。「物理レイアウトで競合より10%優れている」のも,このような,徹底的に無駄を省いた設計思想が功を奏したからに違いない。
最新技術てんこ盛り。妥協のないプロセッサに仕上がったRyzen
いかがだっただろうか。
Ryzenの設計には妥協点がなく,また,あらゆる新要素の実現にとにかく新技術を採用するといったあたりに,AMDの本気度を窺い知ることができるのではないかと思う。明らかになっているとおり,価格設定もかなり戦略的になっているため,性能重視のゲームPC(やハイエンド志向のデスクトップPC,シングルCPUワークステーション)を手に入れたい人の中で,Ryzen 7が大きな注目を集めるであろうことは想像に難くない。
あえて弱点を探すとすると,AMDが競合と位置づけるCPUのうち,Broadwell-Eコアのものは,CPU側に40レーンのPCI Express 3.0リンクを持つ点が挙げられるだろう。24レーンに留まるRyzenはここが負い目となり得る。
ただ,突っ込まれるのを見越していたAMDは,この点について「我々が評価する限り,(グラフィックスカードを2枚差しての)4Kレンダリング実行時に,8レーン×2で帯域幅が不足することはなかった」「AM4プラットフォームはRyzenだけでなくAPUとの兼用プラットフォームということもあり,24レーンを超えるPCI Expressリンクの実装は難しい」と述べているので,この点は書いておきたいと思う。
 |
 |
 |
 |
なお,Tech Dayには,ミスターRadeonとでも呼ぶべき,Radeon Technologies Groupの総帥,Raja Koduri(ラジャ・コドゥリ)氏も登場。「業界は速いCPUを待ち望んでいた」というテーマで,自ら主演するルポ番組タッチ長編動画「Raja & Friends」を上演して,来場者に見せつけていた。
 |
 |
 |
 |
さらにKoduri氏は「もうRyzenの発売が待てない」とCPU部門のスタッフに詰め寄り,500ドルを手渡してRyzen 7 1800Xをフライングゲットするという,コメディタッチのやりとりも披露。このあたりのお茶目さと陽気さはAMD独特の文化と言ったところである。
 |
 |
 |
さて,そんな気になるRyzen 7から,4GamerではKoduri氏も手に入れたRyzen 7 1800Xを入手し,テストしている。その実力が気になる人は,そちらもぜひチェックしてほしいと思う。
「Ryzen 7 1800X」レビュー。「買える値段の8コアCPU」はゲーマーに何をもたらすのか?
いよいよ発売。Ryzen 7と対応チップセットのスペックを総まとめ
AMD公式Webサイト
- 関連タイトル:
 Ryzen(Zen,Zen+)
Ryzen(Zen,Zen+) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー