















ニュース
NVIDIA,第2世代Kepler「GK110」搭載の「Tesla K20」を正式発表。CUDA Core数は最大2688基に
 |
Tesla K20は第2世代Keplerと呼ばれるGPUコアを採用するため,次世代のGeForce製品を予想するうえでも重要な製品だ。本稿では,ISC12の開催に先立って,アジア太平洋地域の報道関係者を対象に実施された電話会議の内容を基に,Tesla K20シリーズの概要を紹介してみたい。
K20XとK20の2モデルでスタートする新世代Tesla
 |
発表時点におけるTesla K20シリーズのラインナップは「Tesla K20X」「Tesla K20」の2モデル。上位に置かれるTesla K20Xは2688基のCUDA Coreを集積し,235Wの消費電力で,単精度浮動小数点数演算のピーク性能は3.95 TFLOPS,倍精度浮動小数点数演算のピーク性能はその約3分の1となる1.31 TFLOPSを実現できるという。
一方,シリーズ名と同じ“無印”のTesla K20は,2496基のCUDA Coreを集積し,225Wの消費電力で,ピーク時に単精度3.52 TFLOPS,倍精度1.17 TFLOPSの浮動小数点演算性能を持つとされている。
 |
そのほか,公開されている情報を基に,メモリ周りで一部筆者の推測を交えつつまとめたスペックが表である。NVIDIAでTesla部門のゼネラルマネージャーを務めるSumit Gupta(スミット・グプタ)氏は,Tesla K20XとTesla K20のメモリクロックがいずれも2600MHzだと述べていたが,NVIDIAはGDDR5メモリのクロックを実クロックの2倍で示す“クセ”があるので,一般的なグラフィックスカード相当で言えば5.2GHz相当(ビットレート5.2Gbps)ということになるはずだ。メモリインタフェースの値は,その数字を基にしたものとなる。
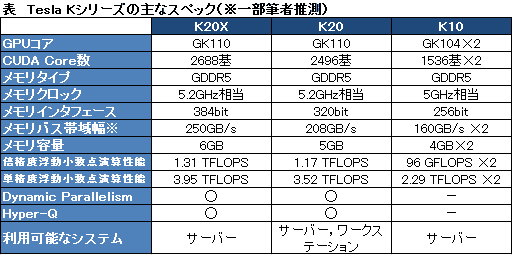 |
さて,概算してみると,フルスペックで1536基のCUDA Coreを搭載するGK104に対し,Tesla K20Xはその1.75倍,Tesla K20は1.625倍のCUDA Coreを備えることになる。
GK104を搭載するTesla K10の単精度浮動小数点数演算のピーク性能はGPU 1基あたり約2.29 TFLOPSだから,それを1.75倍すると約4 TFLOPS,つまりTesla K20Xのピーク性能とほぼ同じ数字だ。
若干の違いが生じているのはGPUコアクロックが異なっているためだと思われるが,いずれにせよこのことから,Tesla K20シリーズにおけるGPUコアの動作クロックはTesla K10とほぼ同程度で,また,単精度浮動小数点演算を実行する演算器の構成はGK104から変わっていないと推測できそうだ。Tesla K20でも,CUDA Core 1基に搭載される単精度の積和演算器と整数演算器は各1基ということになるだろう。
 |
一方,大きく変わるのが倍精度浮動小数点演算周りで,GK104を採用するTesla K10のピーク性能がGPU 1基あたりでわずか96 GLOPS(0.096 TFLOPS)しかなかったものが,Tesla K20Xでは1.31 TFLOPS,Tesla K20でも1.17 TFLOPSと,桁が違うどころの騒ぎではないレベルで高速化が図られている。
Tesla K20シリーズでは,倍精度浮動小数点演算性能が単精度のそれと比べて3分の1に留まっているので,単精度浮動小数点演算器と比べて倍精度浮動小数点演算性能器の数は3分の1になっているものと思われる。
 |
NVIDIAが公開したGK110のダイ写真だと,SMXらしき相似形のブロックを計15個確認できるので,おそらく,歩留まり向上のために,1〜2基のSMX不良を許容しているのだろう。
第1世代Keplerと同じ,28nmプロセス技術を採用することもあって,Tesla K20シリーズ(というかGK110)が,相当に規模の大きいGPUであることに疑いの余地はないのだが,その割に消費電力は抑えられている印象だ。その分GPUクロックが抑えられている可能性はあるので,GK110がそのままの形でゲーマー向けのGPUとして使われる可能性についてはなんとも言えないが,動作クロックや実3D性能を抜きに,225Wという数字だけで判断するなら,問題はないということになる。
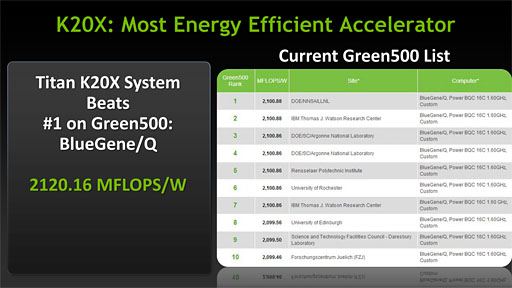
実際,Gupta氏は電話会議のなかで「Tesla K20シリーズの電力効率は,IBMの『BlueGene/Q』を上回る。あちらは1ラックあたり100万ドル(約7940万円)だ」と,その低消費電力性を強調していた。BlueGene/Qは,スーパーコンピュータの電力効率を競う「Green500」において,2012年6月発表の最新ランキングでトップにある製品だが,Tesla K20搭載製品は,そのスコアを上回るとのことだ。
 |
カード単体販売の予定がないことから,参考価格は明らかにされなかったが,Tesla K20無印は,今週中にもNVIDIAのOEMとなるサーバーベンダーに向けて始まる予定とのこと。Tesla K20Xは「向こう数週間以内に」(Gupta氏)出荷が始まるという。
 Tesla K20は今週中にもサーバーベンダー各社へ向けて出荷が始まる見込み。11〜12月中に購入できるようになるとされた |
 Tesla K20シリーズを採用し,30 PFLOPS級の演算性能を実現したスーパーコンピュータが,近々稼働を開始するという |
スパコンの世界でNVIDIAとIntelの全面抗争が始まる?
 |
たとえば,Tesla K20Xの採用がかねてより明らかになっている米オークリッジ国立研究所のスーパーコンピュータ「Titan」(タイタン)は,スーパーコンピュータの性能ランキング「TOP500」で使用されるベンチマークテスト「Linpack Benchmark」において17.59 PFLPSを達成しているそうだ。このスコアは,執筆時点におけるTOP500のナンバーワンである,米ローレンス・リバモア国立研究所のBlueGene/Qを上回る。
TOP500は,ISC12のタイミングで最新のリストが公開される予定になっているため,おそらくはTitanがトップの座につくこととなりそうだ。
 |
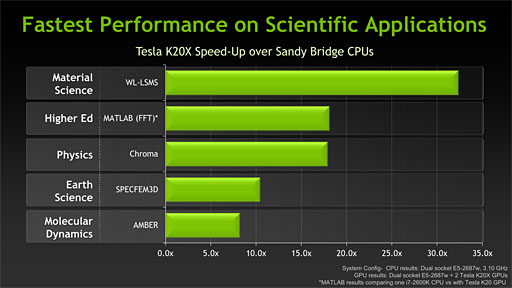
実アプリケーションを前にしたときの例では,「Sandy Bridge世代のXeonプロセッサに対し,同一のアプリケーションで最大30倍以上もの性能を叩き出せる」というグラフが示されている。
 |
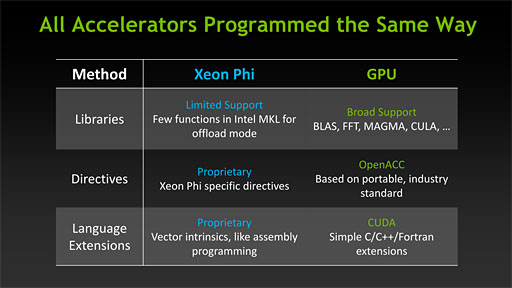
そんな科学技術計算のことを言われても関係ないよという読者は多いと思うが,実のところTesla K20の登場は,「NVIDIA対Intel」の戦いという観点から,非常に重要なものである可能性が高い。というのも,Intelは2012年6月にMICアーキテクチャに基づくスーパーコンピュータ向けアクセラレータ「Xeon Phi」を発表済みで,NVIDIAと同様,ISC12において何らかの発表を行う可能性が高いからだ。
Xeon Phiは,かつて「Larrabee」(ララビー)という開発コードネームで呼ばれていたGPUに端を発する製品だ。Intelはグラフィックス向けGPUとしてのLarrabeeを断念し,「Many Integrated Core Architecture」(MICアーキテクチャ)と名付けてスーパーコンピュータ向けに舵を切ったのだが,Xeon PhiはそんなMICアーキテクチャに基づく最初の製品である。
興味深いのは,電話会議において,Gupta氏が,Xeon Phiについてかなり辛辣な言葉を並べながらその存在意義に疑問を呈していたことだ。いわく「GPU向けにはすでに1000を超えるアプリケーションがあるが,Xeon Phiにはまだ何もない」とか,「Xeon Phiのコアは20年前のPentiumで,現在のSandy Bridgeと比べて性能は10分の1もない。彼らはそんなものをアクセラレータと称している(笑)」といった具合だ。
Intelに対し「あらゆる面で我々にアドバンテージがある」と断言するGupta氏だが,厳しい言葉の裏を返すと,それだけXeon Phiを意識しているということなのだろう。ISC12はNVIDIAとIntelという業界の両雄が激突する場になる可能性があるわけだ。今後の動向に気を配っておくと楽しめるかもしれない。
 |
NVIDIAのTesla製品情報ページ
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- この記事のURL:
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー